 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign Challenges for a Multi-Perspective Search Engine
Paper and Code

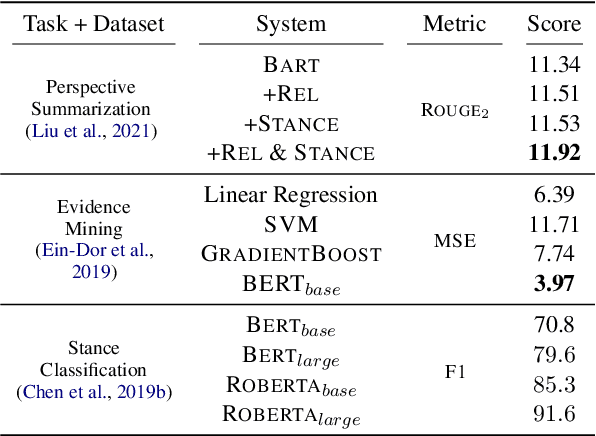
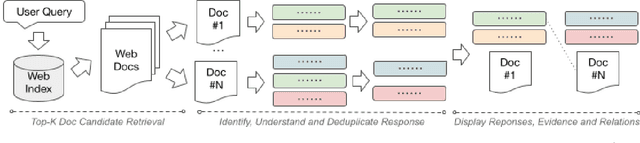

Many users turn to document retrieval systems (e.g. search engines) to seek answers to controversial questions. Answering such user queries usually require identifying responses within web documents, and aggregating the responses based on their different perspectives. Classical document retrieval systems fall short at delivering a set of direct and diverse responses to the users. Naturally, identifying such responses within a document is a natural language understanding task. In this paper, we examine the challenges of synthesizing such language understanding objectives with document retrieval, and study a new perspective-oriented document retrieval paradigm. We discuss and assess the inherent natural language understanding challenges in order to achieve the goal. Following the design challenges and principles, we demonstrate and evaluate a practical prototype pipeline system. We use the prototype system to conduct a user survey in order to assess the utility of our paradigm, as well as understanding the user information needs for controversial queries.