 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Augmenting Neural Differential Equations to Model Unknown Dynamical Systems with Incomplete State Information
Aug 20, 2020
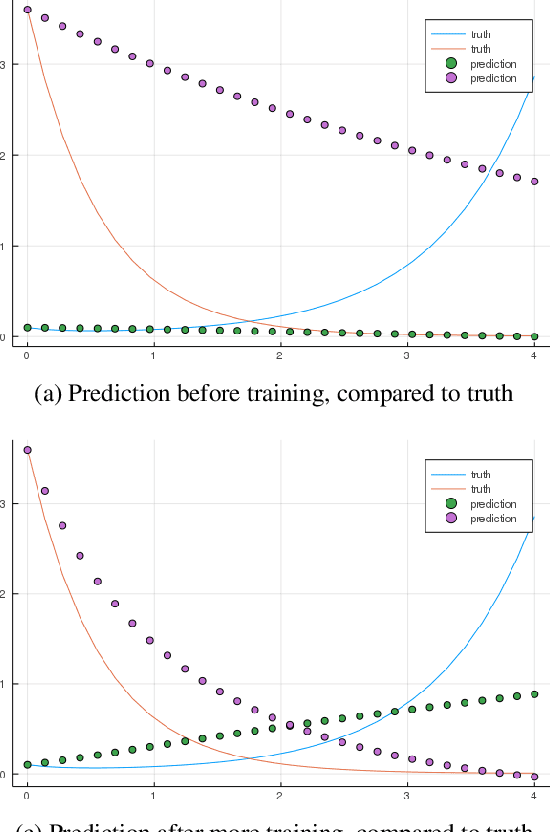
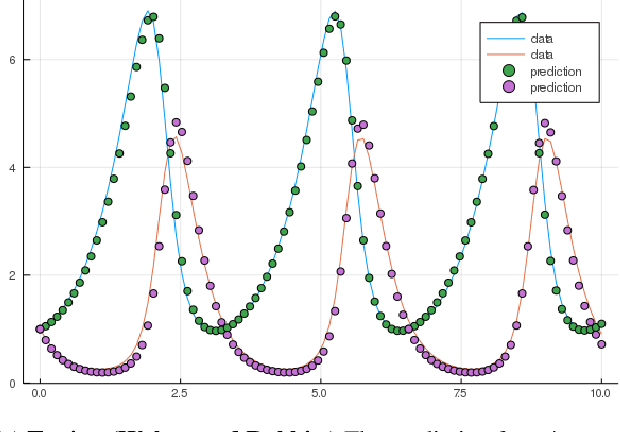
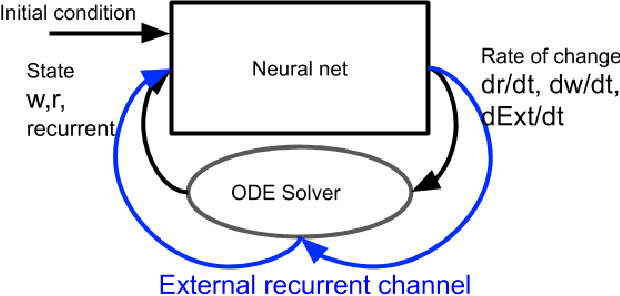
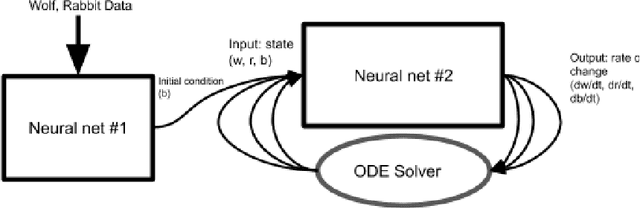
Neural Ordinary Differential Equations replace the right-hand side of a conventional ODE with a neural net, which by virtue of the universal approximation theorem, can be trained to the representation of any function. When we do not know the function itself, but have state trajectories (time evolution) of the ODE system we can still train the neural net to learn the representation of the underlying but unknown ODE. However if the state of the system is incompletely known then the right-hand side of the ODE cannot be calculated. The derivatives to propagate the system are unavailable. We show that a specially augmented Neural ODE can learn the system when given incomplete state information. As a worked example we apply neural ODEs to the Lotka-Voltera problem of 3 species, rabbits, wolves, and bears. We show that even when the data for the bear time series is removed the remaining time series of the rabbits and wolves is sufficient to learn the dynamical system despite the missing the incomplete state information. This is surprising since a conventional ODE system cannot output the correct derivatives without the full state as the input. We implement augmented neural ODEs and differential equation solvers in the julia programming language.
Deep Decoding of $\ell_\infty$-coded Light Field Images
Jan 24, 2022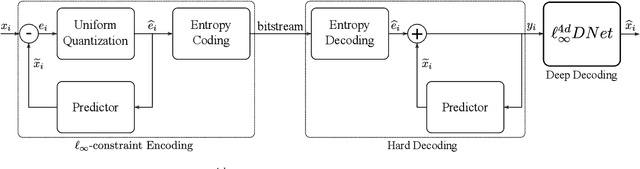
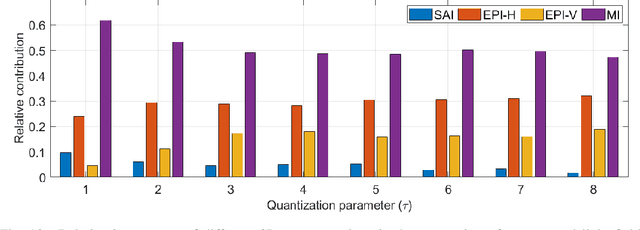
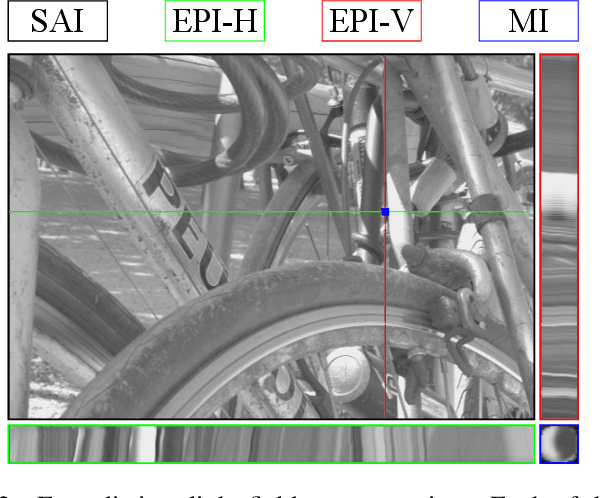
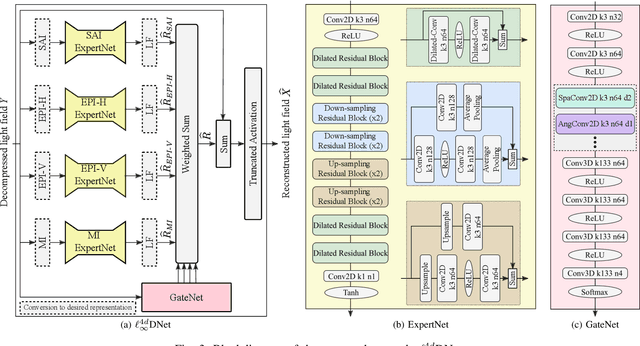
To enrich the functionalities of traditional cameras, light field cameras record both the intensity and direction of light rays, so that images can be rendered with user-defined camera parameters via computations. The added capability and flexibility are gained at the cost of gathering typically more than $100\times$ greater amount of information than conventional images. To cope with this issue, several light field compression schemes have been introduced. However, their ways of exploiting correlations of multidimensional light field data are complex and are hence not suited for inexpensive light field cameras. In this work, we propose a novel $\ell_\infty$-constrained light-field image compression system that has a very low-complexity DPCM encoder and a CNN-based deep decoder. Targeting high-fidelity reconstruction, the CNN decoder capitalizes on the $\ell_\infty$-constraint and light field properties to remove the compression artifacts and achieves significantly better performance than existing state-of-the-art $\ell_2$-based light field compression methods.
Multi-Modal Temporal Attention Models for Crop Mapping from Satellite Time Series
Dec 14, 2021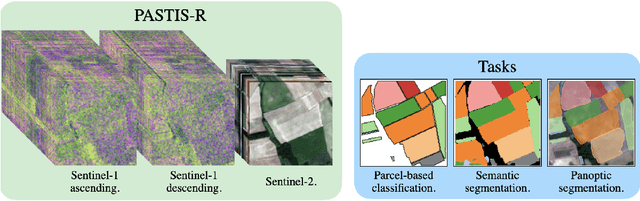
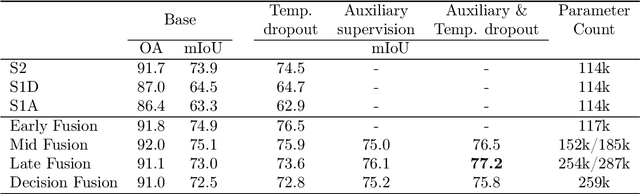
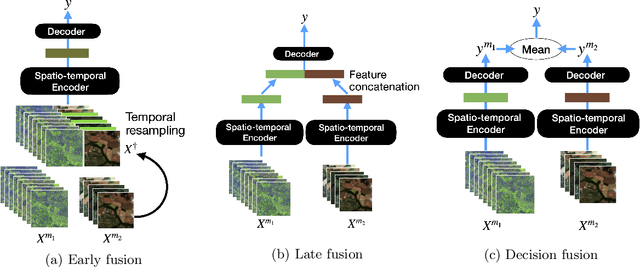
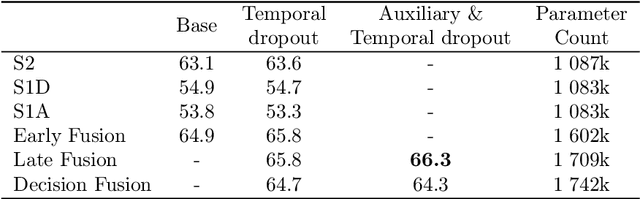
Optical and radar satellite time series are synergetic: optical images contain rich spectral information, while C-band radar captures useful geometrical information and is immune to cloud cover. Motivated by the recent success of temporal attention-based methods across multiple crop mapping tasks, we propose to investigate how these models can be adapted to operate on several modalities. We implement and evaluate multiple fusion schemes, including a novel approach and simple adjustments to the training procedure, significantly improving performance and efficiency with little added complexity. We show that most fusion schemes have advantages and drawbacks, making them relevant for specific settings. We then evaluate the benefit of multimodality across several tasks: parcel classification, pixel-based segmentation, and panoptic parcel segmentation. We show that by leveraging both optical and radar time series, multimodal temporal attention-based models can outmatch single-modality models in terms of performance and resilience to cloud cover. To conduct these experiments, we augment the PASTIS dataset with spatially aligned radar image time series. The resulting dataset, PASTIS-R, constitutes the first large-scale, multimodal, and open-access satellite time series dataset with semantic and instance annotations.
YOLO-Z: Improving small object detection in YOLOv5 for autonomous vehicles
Dec 23, 2021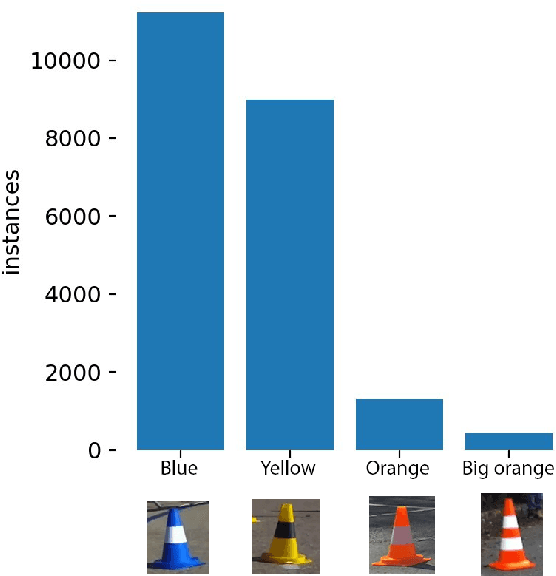


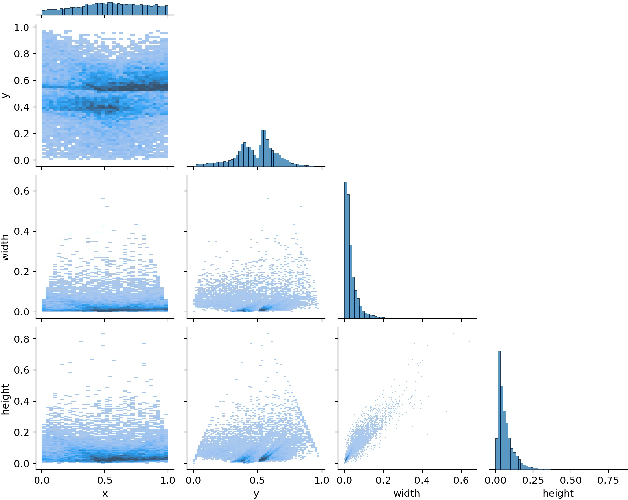
As autonomous vehicles and autonomous racing rise in popularity, so does the need for faster and more accurate detectors. While our naked eyes are able to extract contextual information almost instantly, even from far away, image resolution and computational resources limitations make detecting smaller objects (that is, objects that occupy a small pixel area in the input image) a genuinely challenging task for machines and a wide-open research field. This study explores how the popular YOLOv5 object detector can be modified to improve its performance in detecting smaller objects, with a particular application in autonomous racing. To achieve this, we investigate how replacing certain structural elements of the model (as well as their connections and other parameters) can affect performance and inference time. In doing so, we propose a series of models at different scales, which we name `YOLO-Z', and which display an improvement of up to 6.9% in mAP when detecting smaller objects at 50% IOU, at the cost of just a 3ms increase in inference time compared to the original YOLOv5. Our objective is to inform future research on the potential of adjusting a popular detector such as YOLOv5 to address specific tasks and provide insights on how specific changes can impact small object detection. Such findings, applied to the broader context of autonomous vehicles, could increase the amount of contextual information available to such systems.
Early Detection of Security-Relevant Bug Reports using Machine Learning: How Far Are We?
Dec 19, 2021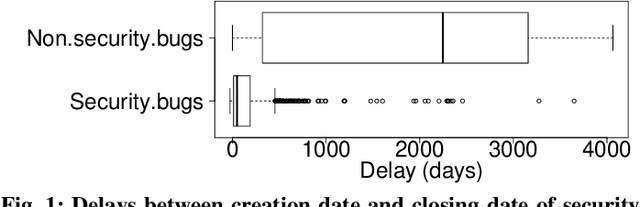


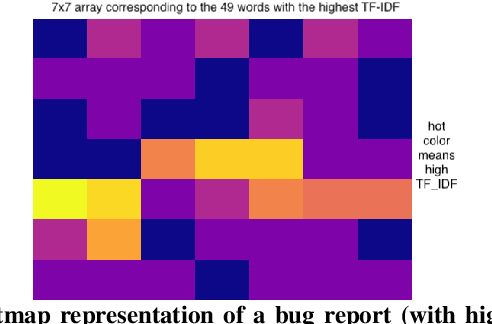
Bug reports are common artefacts in software development. They serve as the main channel for users to communicate to developers information about the issues that they encounter when using released versions of software programs. In the descriptions of issues, however, a user may, intentionally or not, expose a vulnerability. In a typical maintenance scenario, such security-relevant bug reports are prioritised by the development team when preparing corrective patches. Nevertheless, when security relevance is not immediately expressed (e.g., via a tag) or rapidly identified by triaging teams, the open security-relevant bug report can become a critical leak of sensitive information that attackers can leverage to perform zero-day attacks. To support practitioners in triaging bug reports, the research community has proposed a number of approaches for the detection of security-relevant bug reports. In recent years, approaches in this respect based on machine learning have been reported with promising performance. Our work focuses on such approaches, and revisits their building blocks to provide a comprehensive view on the current achievements. To that end, we built a large experimental dataset and performed extensive experiments with variations in feature sets and learning algorithms. Eventually, our study highlights different approach configurations that yield best performing classifiers.
Multi-scale Graph Convolutional Networks with Self-Attention
Dec 04, 2021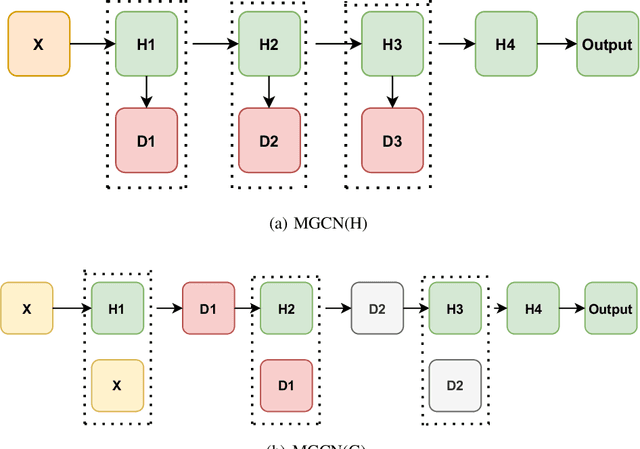

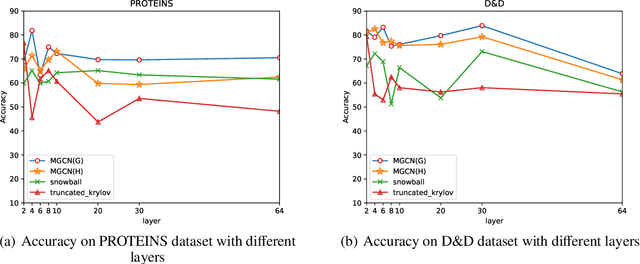
Graph convolutional networks (GCNs) have achieved remarkable learning ability for dealing with various graph structural data recently. In general, deep GCNs do not work well since graph convolution in conventional GCNs is a special form of Laplacian smoothing, which makes the representation of different nodes indistinguishable. In the literature, multi-scale information was employed in GCNs to enhance the expressive power of GCNs. However, over-smoothing phenomenon as a crucial issue of GCNs remains to be solved and investigated. In this paper, we propose two novel multi-scale GCN frameworks by incorporating self-attention mechanism and multi-scale information into the design of GCNs. Our methods greatly improve the computational efficiency and prediction accuracy of the GCNs model. Extensive experiments on both node classification and graph classification demonstrate the effectiveness over several state-of-the-art GCNs. Notably, the proposed two architectures can efficiently mitigate the over-smoothing problem of GCNs, and the layer of our model can even be increased to $64$.
Who will Leave a Pediatric Weight Management Program and When? -- A machine learning approach for predicting attrition patterns
Feb 03, 2022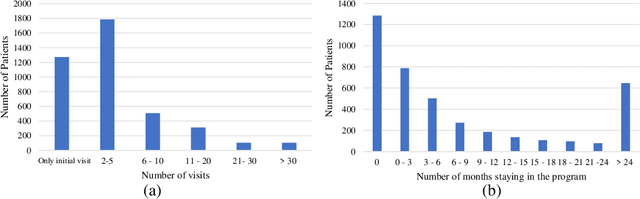
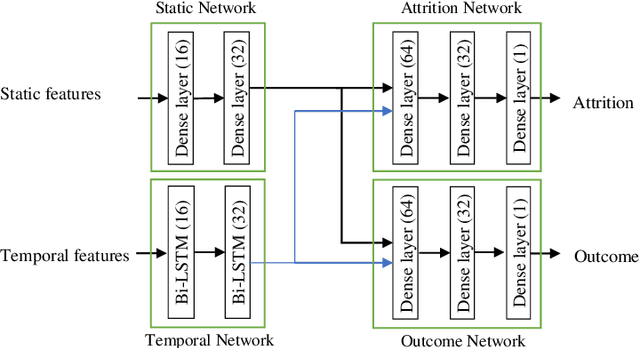
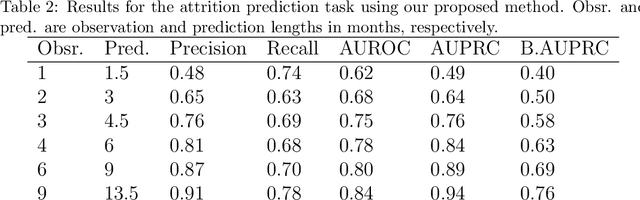
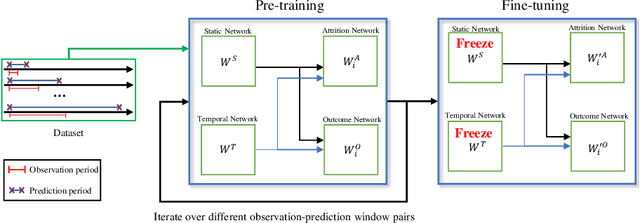
Childhood obesity is a major public health concern. Multidisciplinary pediatric weight management programs are considered standard treatment for children with obesity and severe obesity who are not able to be successfully managed in the primary care setting; however, high drop-out rates (referred to as attrition) are a major hurdle in delivering successful interventions. Predicting attrition patterns can help providers reduce the attrition rates. Previous work has mainly focused on finding static predictors of attrition using statistical analysis methods. In this study, we present a machine learning model to predict (a) the likelihood of attrition, and (b) the change in body-mass index (BMI) percentile of children, at different time points after joining a weight management program. We use a five-year dataset containing the information related to around 4,550 children that we have compiled using data from the Nemours Pediatric Weight Management program. Our models show strong prediction performance as determined by high AUROC scores across different tasks (average AUROC of 0.75 for predicting attrition, and 0.73 for predicting weight outcomes). Additionally, we report the top features predicting attrition and weight outcomes in a series of explanatory experiments.
Cross-Modality Fusion Transformer for Multispectral Object Detection
Dec 01, 2021
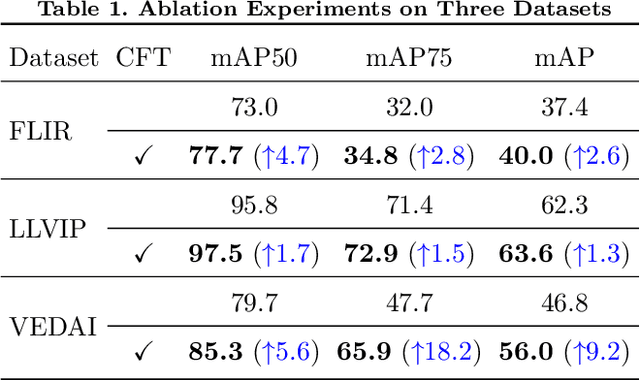
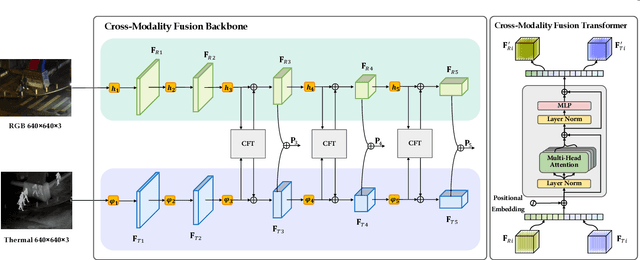
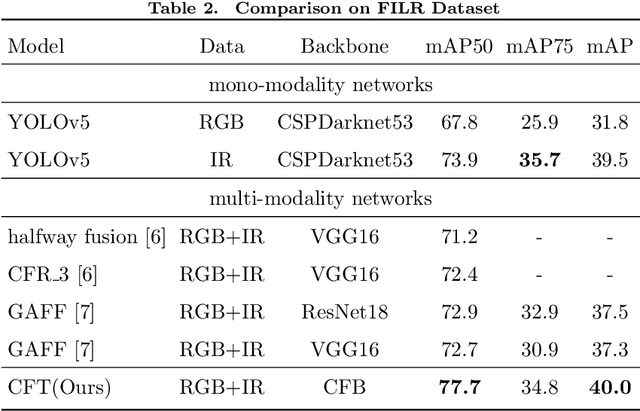
Multispectral image pairs can provide the combined information, making object detection applications more reliable and robust in the open world. To fully exploit the different modalities, we present a simple yet effective cross-modality feature fusion approach, named Cross-Modality Fusion Transformer (CFT) in this paper. Unlike prior CNNs-based works, guided by the transformer scheme, our network learns long-range dependencies and integrates global contextual information in the feature extraction stage. More importantly, by leveraging the self attention of the transformer, the network can naturally carry out simultaneous intra-modality and inter-modality fusion, and robustly capture the latent interactions between RGB and Thermal domains, thereby significantly improving the performance of multispectral object detection. Extensive experiments and ablation studies on multiple datasets demonstrate that our approach is effective and achieves state-of-the-art detection performance. Our code and models are available at https://github.com/DocF/multispectral-object-detection.
Machine unlearning via GAN
Nov 22, 2021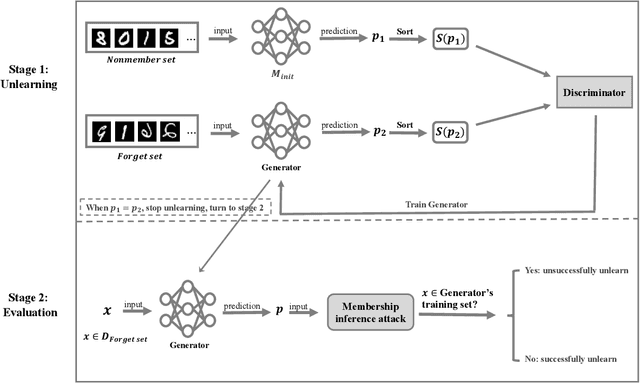

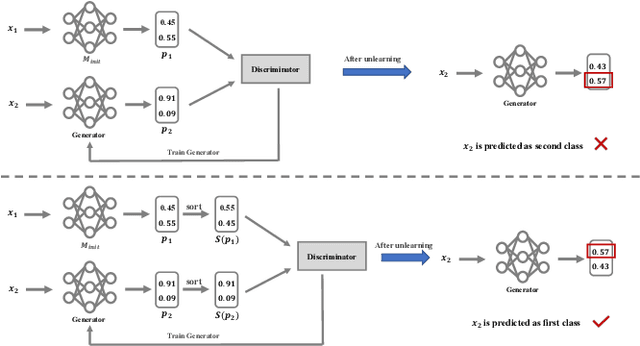
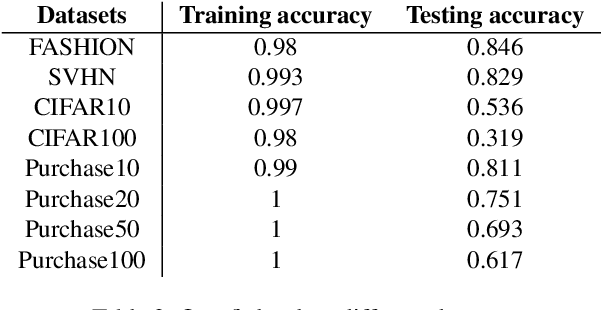
Machine learning models, especially deep models, may unintentionally remember information about their training data. Malicious attackers can thus pilfer some property about training data by attacking the model via membership inference attack or model inversion attack. Some regulations, such as the EU's GDPR, have enacted "The Right to Be Forgotten" to protect users' data privacy, enhancing individuals' sovereignty over their data. Therefore, removing training data information from a trained model has become a critical issue. In this paper, we present a GAN-based algorithm to delete data in deep models, which significantly improves deleting speed compared to retraining from scratch, especially in complicated scenarios. We have experimented on five commonly used datasets, and the experimental results show the efficiency of our method.
Full-Duplex Non-Coherent Communications for Massive MIMO Systems with Analog Beamforming
Jan 29, 2022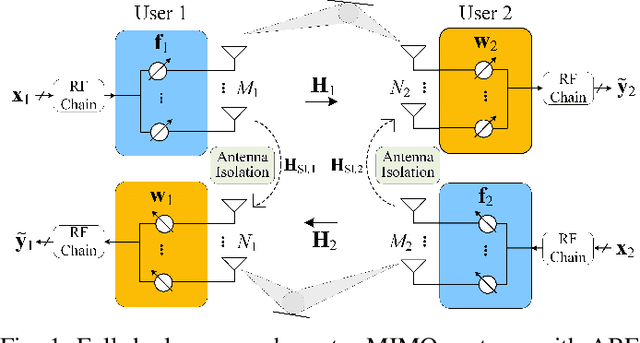
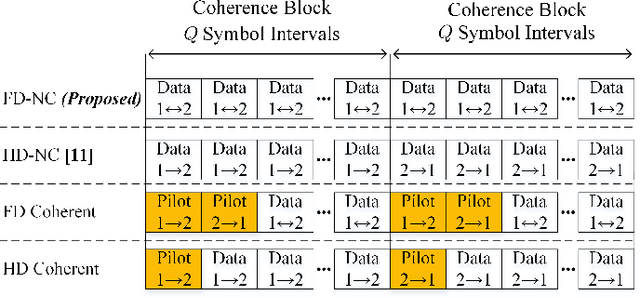
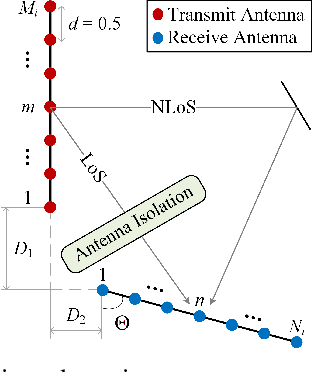
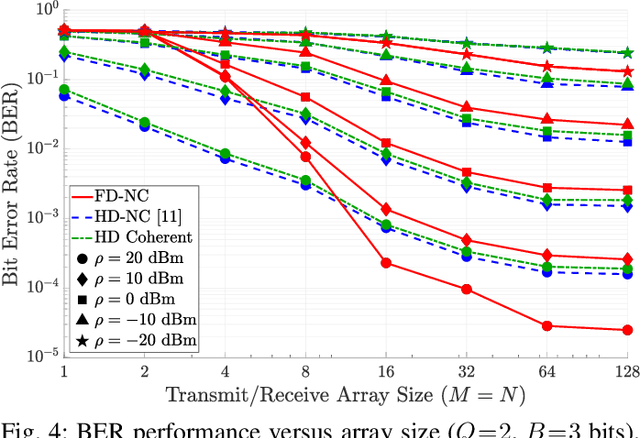
In this paper, a novel full-duplex non-coherent (FD-NC) transmission scheme is developed for massive multiple-input multiple-output (mMIMO) systems using analog beamforming (ABF). We propose to use a structured Grassmannian constellation for the non-coherent communications that does not require channel estimation. Then, we design the transmit and receive ABF via the slow time-varying angle-of-departure (AoD) and angle-of-arrival (AoA) information, respectively. The ABF design targets maximizing the intended signal power while suppressing the strong self-interference (SI) occurred in the FD transmission. Also, the proposed ABF technique only needs a single transmit and receive RF chain to support large antenna arrays, thus, it reduces hardware cost/complexity in the mMIMO systems. It is shown that the proposed FD-NC offers a great improvement in bit error rate (BER) in comparison to both half-duplex non-coherent (HD-NC) and HD coherent schemes. We also observe that the proposed FD-NC both reduces the error floor resulted from the residual SI in FD transmission, and provides lower BER compared to the FD coherent transmission.