 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEM: Sparse Embedding Modulation for Post-Hoc Debiasing of Vision-Language Models
Mar 19, 2026Models that bridge vision and language, such as CLIP, are key components of multimodal AI, yet their large-scale, uncurated training data introduce severe social and spurious biases. Existing post-hoc debiasing methods often operate directly in the dense CLIP embedding space, where bias and task-relevant information are highly entangled. This entanglement limits their ability to remove bias without degrading semantic fidelity. In this work, we propose Sparse Embedding Modulation (SEM), a post-hoc, zero-shot debiasing framework that operates in a Sparse Autoencoder (SAE) latent space. By decomposing CLIP text embeddings into disentangled features, SEM identifies and modulates bias-relevant neurons while preserving query-relevant ones. This enables more precise, non-linear interventions. Across four benchmark datasets and two CLIP backbones, SEM achieves substantial fairness gains in retrieval and zero-shot classification. Our results demonstrate that sparse latent representations provide an effective foundation for post-hoc debiasing of vision-language models.
Classifier-to-Bias: Toward Unsupervised Automatic Bias Detection for Visual Classifiers
Apr 29, 2025A person downloading a pre-trained model from the web should be aware of its biases. Existing approaches for bias identification rely on datasets containing labels for the task of interest, something that a non-expert may not have access to, or may not have the necessary resources to collect: this greatly limits the number of tasks where model biases can be identified. In this work, we present Classifier-to-Bias (C2B), the first bias discovery framework that works without access to any labeled data: it only relies on a textual description of the classification task to identify biases in the target classification model. This description is fed to a large language model to generate bias proposals and corresponding captions depicting biases together with task-specific target labels. A retrieval model collects images for those captions, which are then used to assess the accuracy of the model w.r.t. the given biases. C2B is training-free, does not require any annotations, has no constraints on the list of biases, and can be applied to any pre-trained model on any classification task. Experiments on two publicly available datasets show that C2B discovers biases beyond those of the original datasets and outperforms a recent state-of-the-art bias detection baseline that relies on task-specific annotations, being a promising first step toward addressing task-agnostic unsupervised bias detection.
Early Detection of Security-Relevant Bug Reports using Machine Learning: How Far Are We?
Dec 19, 2021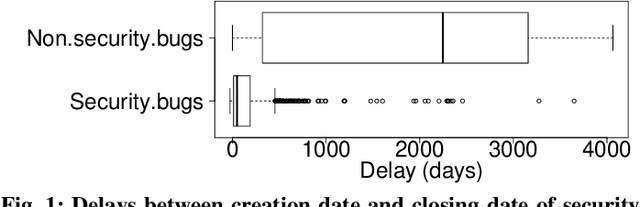


Bug reports are common artefacts in software development. They serve as the main channel for users to communicate to developers information about the issues that they encounter when using released versions of software programs. In the descriptions of issues, however, a user may, intentionally or not, expose a vulnerability. In a typical maintenance scenario, such security-relevant bug reports are prioritised by the development team when preparing corrective patches. Nevertheless, when security relevance is not immediately expressed (e.g., via a tag) or rapidly identified by triaging teams, the open security-relevant bug report can become a critical leak of sensitive information that attackers can leverage to perform zero-day attacks. To support practitioners in triaging bug reports, the research community has proposed a number of approaches for the detection of security-relevant bug reports. In recent years, approaches in this respect based on machine learning have been reported with promising performance. Our work focuses on such approaches, and revisits their building blocks to provide a comprehensive view on the current achievements. To that end, we built a large experimental dataset and performed extensive experiments with variations in feature sets and learning algorithms. Eventually, our study highlights different approach configurations that yield best performing classifiers.