 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Code Smells: A Taxonomy and Detection Approach
May 21, 2026Large Language Models (LLMs) are increasingly integrated into software systems for diverse purposes, due to their versatility, flexibility, and ability to simulate human reasoning to some extent. However, poor integration of LLM inference in source code can undermine software system quality. Therefore, inadequate LLM integration coding practices must be documented to help developers mitigate such issues. Following our earlier work on LLM code smells, this paper consolidates and refines the concept by presenting a self-contained taxonomy and a catalog of nine LLM code smells. We also create SpecDetect4LLM, a static source code analysis tool for their detection, and conduct extensive empirical evaluations of its detection effectiveness (precision and recall) as well as the prevalence of LLM code smells across 692 open-source software projects (171,194 source files). Our results show that LLM code smells affect 73.5% of the analyzed systems, with a detection precision of 91.3% and a recall of 71.8%.
DynamicsLLM: a Dynamic Analysis-based Tool for Generating Intelligent Execution Traces Using LLMs to Detect Android Behavioural Code Smells
Apr 12, 2026Mobile apps have become essential of our daily lives, making code quality a critical concern for developers. Behavioural code smells are characteristics in the source code that induce inappropriate code behaviour during execution, which negatively impact software quality in terms of performance, energy consumption, and memory. Dynamics, the latest state-of-the-art tool-based method, is highly effective at detecting Android behavioural code smells. While it outperforms static analysis tools, it suffers from a high false negative rate, with multiple code smell instances remaining undetected. Large Language Models (LLMs) have achieved notable advances across numerous research domains and offer significant potential for generating intelligent execution traces, particularly for detecting behavioural code smells in Android mobile applications. By intelligent execution trace, we mean a sequence of events generated by specific actions in a way that triggers the identification of a given behaviour. We propose the following three main contributions in this paper: (1) DynamicsLLM, an enhanced implementation of the Dynamics method that leverages LLMs to intelligently generate execution traces. (2) A novel hybrid approach designed to improve the coverage of code smell-related events in applications with a small number of activities. (3) A comprehensive validation of DynamicsLLM on 333 mobile applications from F-DROID, including a comparison with the Dynamics tool. Our results show that, under a limited number of actions, DynamicsLLM configured with 100% LLM covers three times more code smell-related events than Dynamics. The hybrid approach improves LLM coverage by 25.9% for apps containing few activities. Moreover, 12.7% of the code smell-related events that cannot be triggered by Dynamics are successfully triggered by our tool.
Specification and Detection of LLM Code Smells
Dec 19, 2025

Large Language Models (LLMs) have gained massive popularity in recent years and are increasingly integrated into software systems for diverse purposes. However, poorly integrating them in source code may undermine software system quality. Yet, to our knowledge, there is no formal catalog of code smells specific to coding practices for LLM inference. In this paper, we introduce the concept of LLM code smells and formalize five recurrent problematic coding practices related to LLM inference in software systems, based on relevant literature. We extend the detection tool SpecDetect4AI to cover the newly defined LLM code smells and use it to validate their prevalence in a dataset of 200 open-source LLM systems. Our results show that LLM code smells affect 60.50% of the analyzed systems, with a detection precision of 86.06%.
Early Detection of Security-Relevant Bug Reports using Machine Learning: How Far Are We?
Dec 19, 2021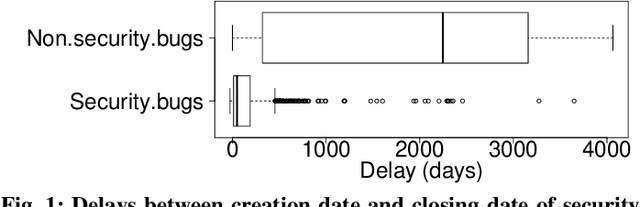


Bug reports are common artefacts in software development. They serve as the main channel for users to communicate to developers information about the issues that they encounter when using released versions of software programs. In the descriptions of issues, however, a user may, intentionally or not, expose a vulnerability. In a typical maintenance scenario, such security-relevant bug reports are prioritised by the development team when preparing corrective patches. Nevertheless, when security relevance is not immediately expressed (e.g., via a tag) or rapidly identified by triaging teams, the open security-relevant bug report can become a critical leak of sensitive information that attackers can leverage to perform zero-day attacks. To support practitioners in triaging bug reports, the research community has proposed a number of approaches for the detection of security-relevant bug reports. In recent years, approaches in this respect based on machine learning have been reported with promising performance. Our work focuses on such approaches, and revisits their building blocks to provide a comprehensive view on the current achievements. To that end, we built a large experimental dataset and performed extensive experiments with variations in feature sets and learning algorithms. Eventually, our study highlights different approach configurations that yield best performing classifiers.