 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Label fusion and training methods for reliable representation of inter-rater uncertainty
Feb 26, 2022

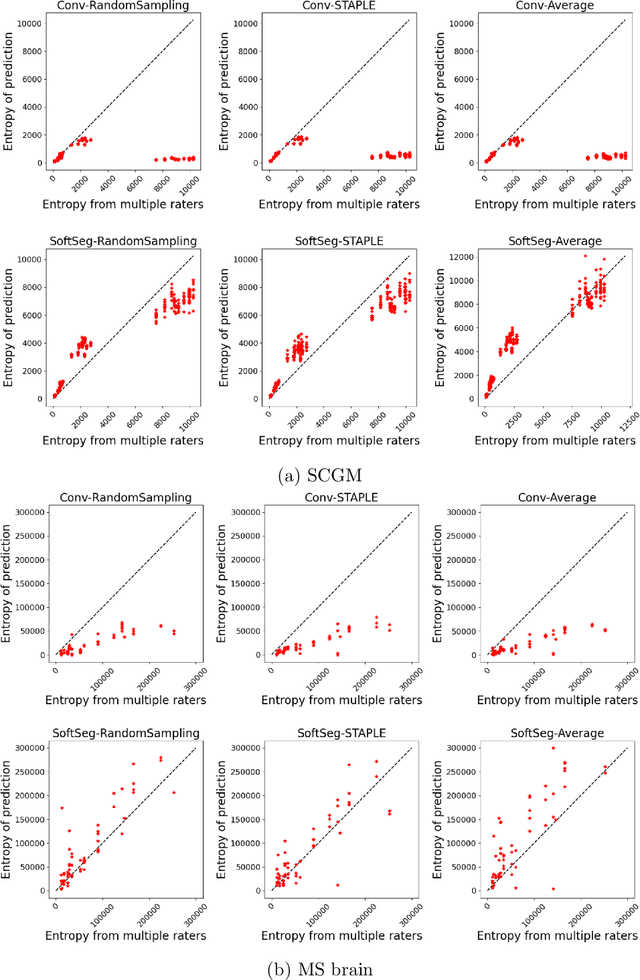
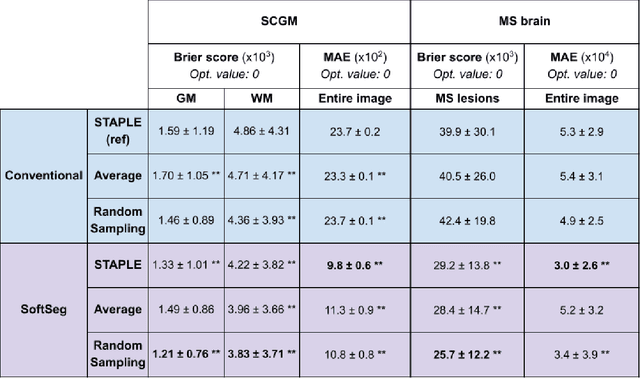
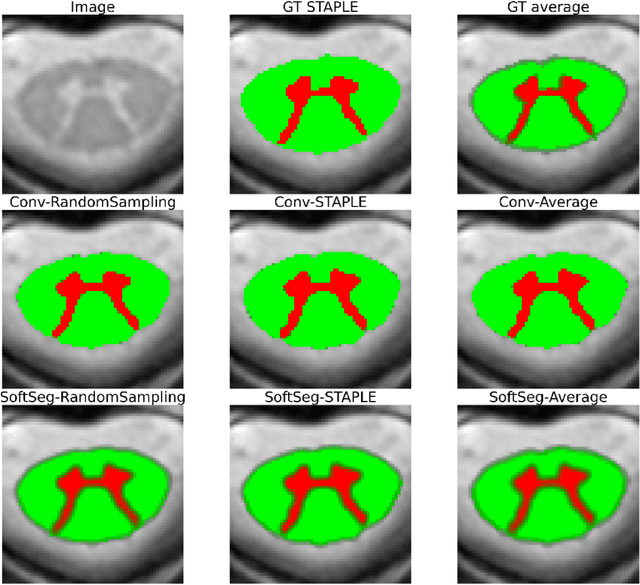
Medical tasks are prone to inter-rater variability due to multiple factors such as image quality, professional experience and training, or guideline clarity. Training deep learning networks with annotations from multiple raters is a common practice that mitigates the model's bias towards a single expert. Reliable models generating calibrated outputs and reflecting the inter-rater disagreement are key to the integration of artificial intelligence in clinical practice. Various methods exist to take into account different expert labels. We focus on comparing three label fusion methods: STAPLE, average of the rater's segmentation, and random sampling of each rater's segmentation during training. Each label fusion method is studied using both the conventional training framework and the recently published SoftSeg framework that limits information loss by treating the segmentation task as a regression. Our results, across 10 data splittings on two public datasets, indicate that SoftSeg models, regardless of the ground truth fusion method, had better calibration and preservation of the inter-rater rater variability compared with their conventional counterparts without impacting the segmentation performance. Conventional models, i.e., trained with a Dice loss, with binary inputs, and sigmoid/softmax final activate, were overconfident and underestimated the uncertainty associated with inter-rater variability. Conversely, fusing labels by averaging with the SoftSeg framework led to underconfident outputs and overestimation of the rater disagreement. In terms of segmentation performance, the best label fusion method was different for the two datasets studied, indicating this parameter might be task-dependent. However, SoftSeg had segmentation performance systematically superior or equal to the conventionally trained models and had the best calibration and preservation of the inter-rater variability.
Minimizing Entropy to Discover Good Solutions to Recurrent Mixed Integer Programs
Feb 07, 2022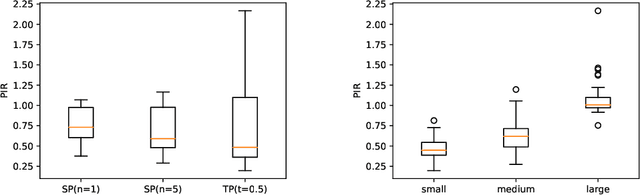
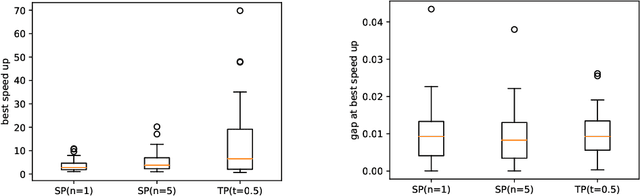
Current state-of-the-art solvers for mixed-integer programming (MIP) problems are designed to perform well on a wide range of problems. However, for many real-world use cases, problem instances come from a narrow distribution. This has motivated the development of specialized methods that can exploit the information in historical datasets to guide the design of heuristics. Recent works have shown that machine learning (ML) can be integrated with an MIP solver to inject domain knowledge and efficiently close the optimality gap. This hybridization is usually done with deep learning (DL), which requires a large dataset and extensive hyperparameter tuning to perform well. This paper proposes an online heuristic that uses the notion of entropy to efficiently build a model with minimal training data and tuning. We test our method on the locomotive assignment problem (LAP), a recurring real-world problem that is challenging to solve at scale. Experimental results show a speed up of an order of magnitude compared to a general purpose solver (CPLEX) with a relative gap of less than 2%. We also observe that for some instances our method can discover better solutions than CPLEX within the time limit.
RePaint: Inpainting using Denoising Diffusion Probabilistic Models
Feb 07, 2022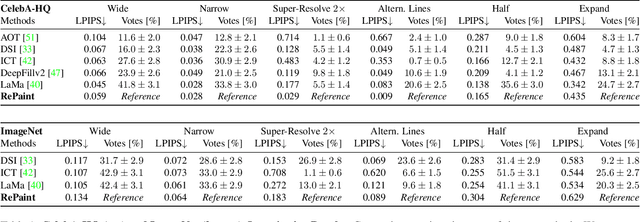
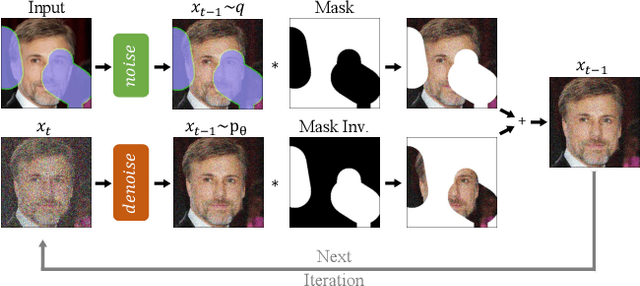


Free-form inpainting is the task of adding new content to an image in the regions specified by an arbitrary binary mask. Most existing approaches train for a certain distribution of masks, which limits their generalization capabilities to unseen mask types. Furthermore, training with pixel-wise and perceptual losses often leads to simple textural extensions towards the missing areas instead of semantically meaningful generation. In this work, we propose RePaint: A Denoising Diffusion Probabilistic Model (DDPM) based inpainting approach that is applicable to even extreme masks. We employ a pretrained unconditional DDPM as the generative prior. To condition the generation process, we only alter the reverse diffusion iterations by sampling the unmasked regions using the given image information. Since this technique does not modify or condition the original DDPM network itself, the model produces high-quality and diverse output images for any inpainting form. We validate our method for both faces and general-purpose image inpainting using standard and extreme masks. RePaint outperforms state-of-the-art Autoregressive, and GAN approaches for at least five out of six mask distributions. Github Repository: git.io/RePaint
Do We Exploit all Information for Counterfactual Analysis? Benefits of Factor Models and Idiosyncratic Correction
Nov 08, 2020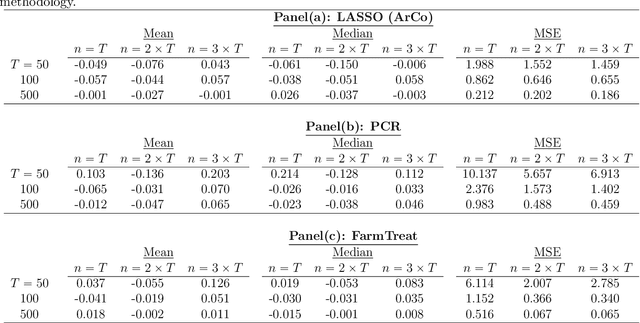
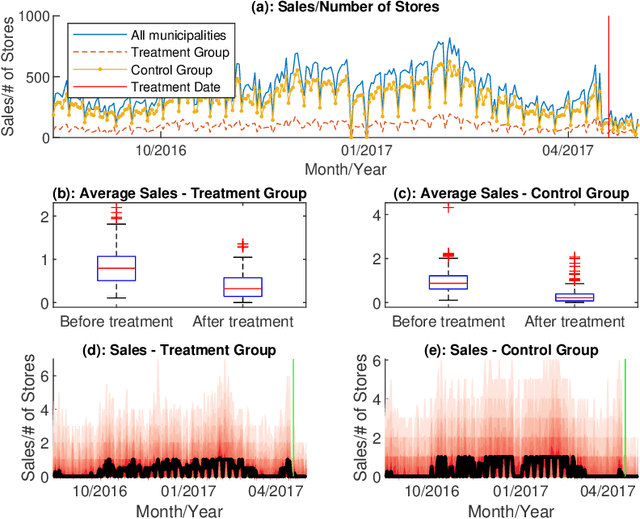
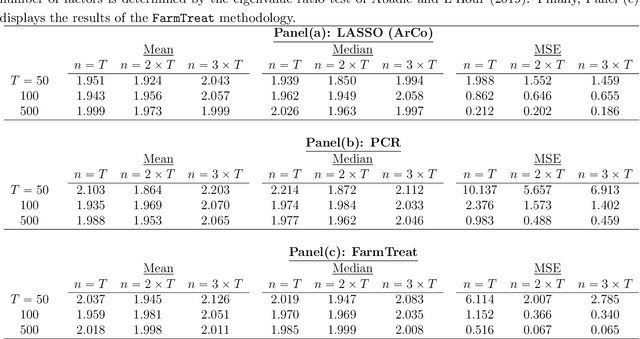
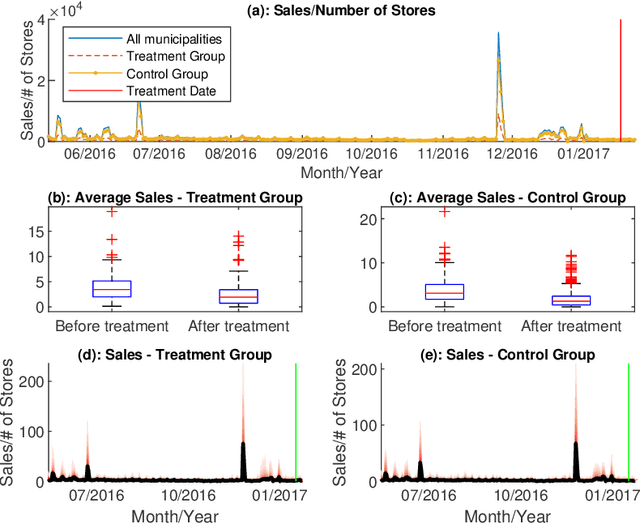
The measurement of treatment (intervention) effects on a single (or just a few) treated unit(s) based on counterfactuals constructed from artificial controls has become a popular practice in applied statistics and economics since the proposal of the synthetic control method. In high-dimensional setting, we often use principal component or (weakly) sparse regression to estimate counterfactuals. Do we use enough data information? To better estimate the effects of price changes on the sales in our case study, we propose a general framework on counterfactual analysis for high dimensional dependent data. The framework includes both principal component regression and sparse linear regression as specific cases. It uses both factor and idiosyncratic components as predictors for improved counterfactual analysis, resulting a method called Factor-Adjusted Regularized Method for Treatment (FarmTreat) evaluation. We demonstrate convincingly that using either factors or sparse regression is inadequate for counterfactual analysis in many applications and the case for information gain can be made through the use of idiosyncratic components. We also develop theory and methods to formally answer the question if common factors are adequate for estimating counterfactuals. Furthermore, we consider a simple resampling approach to conduct inference on the treatment effect as well as bootstrap test to access the relevance of the idiosyncratic components. We apply the proposed method to evaluate the effects of price changes on the sales of a set of products based on a novel large panel of sale data from a major retail chain in Brazil and demonstrate the benefits of using additional idiosyncratic components in the treatment effect evaluations.
Selective Inverse Kinematics: A Novel Approach to Finding Multiple Solutions Fast for High-DoF Robotic
Feb 16, 2022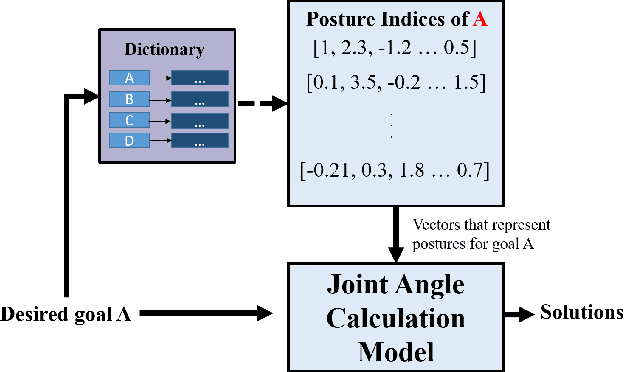
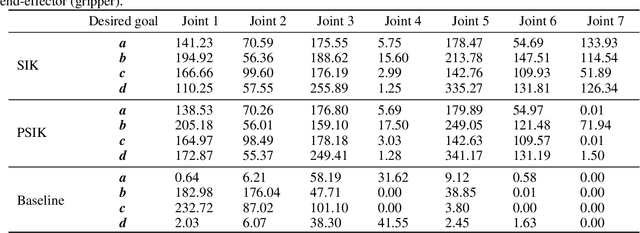
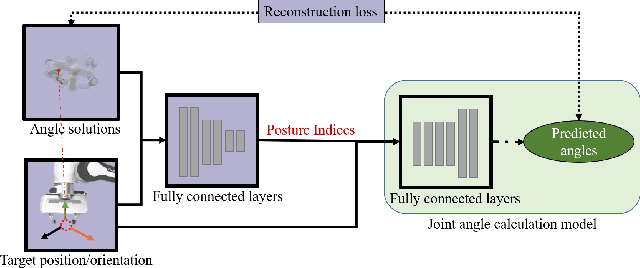

Inverse Kinematics (IK) solves the problem of mapping from the Cartesian space to the joint configuration space of a robotic arm. It has a wide range of applications in areas such as computer graphics, protein structure prediction, and robotics. The problem is commonly solved analytically based on the structure of the robotic arm or numerically by approximation through recursive methods, e.g., Jacobian-based methods. Over the past decade, data-driven methods have also been exploited. Unfortunately, these approaches to IK become inadequate for high Degree-of-Freedom (DoF) robotic arms. Theoretically, the redundant DoFs of such robotic arms can provide an infinite number of solutions to IK for reaching a given target position. The huge solution space could be exploited for more flexible operations of high-DoF robotic arms. The problem is that existing approaches are confined and normally produce only one joint solution for a target position. This paper presents the first work that solves high-DoF IK by generating multiple distinct joint solutions to reach any given target position in the working space. The proposed data-driven approach can be applied to any robotic arms without knowing detailed kinematics information. It not only obtains multiple distinct joint solutions for a target position, but also solves the high-DoF IK problem within a millisecond and achieves subcentimeter distance errors with very sparse training data.
ASR-Aware End-to-end Neural Diarization
Feb 02, 2022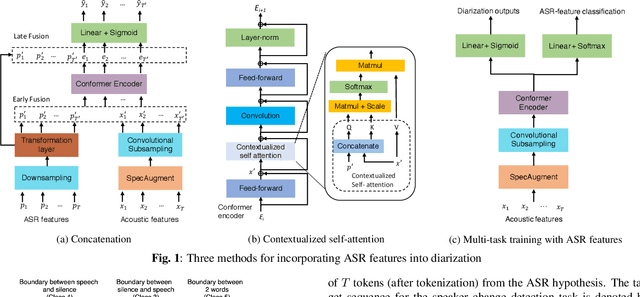
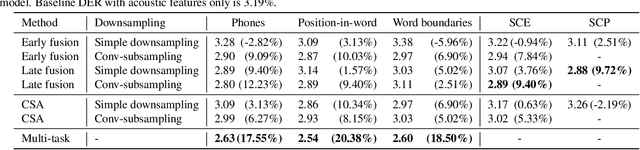
We present a Conformer-based end-to-end neural diarization (EEND) model that uses both acoustic input and features derived from an automatic speech recognition (ASR) model. Two categories of features are explored: features derived directly from ASR output (phones, position-in-word and word boundaries) and features derived from a lexical speaker change detection model, trained by fine-tuning a pretrained BERT model on the ASR output. Three modifications to the Conformer-based EEND architecture are proposed to incorporate the features. First, ASR features are concatenated with acoustic features. Second, we propose a new attention mechanism called contextualized self-attention that utilizes ASR features to build robust speaker representations. Finally, multi-task learning is used to train the model to minimize classification loss for the ASR features along with diarization loss. Experiments on the two-speaker English conversations of Switchboard+SRE data sets show that multi-task learning with position-in-word information is the most effective way of utilizing ASR features, reducing the diarization error rate (DER) by 20% relative to the baseline.
Design Theory to improve health evidence retrieval
Nov 10, 2021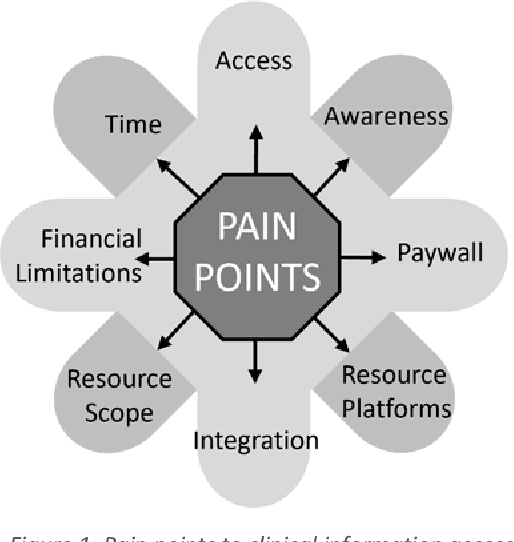
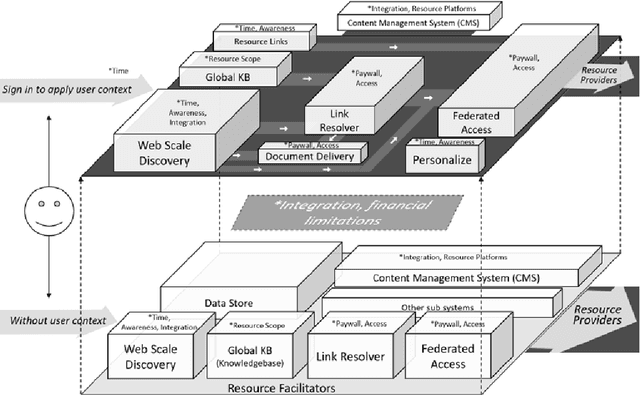
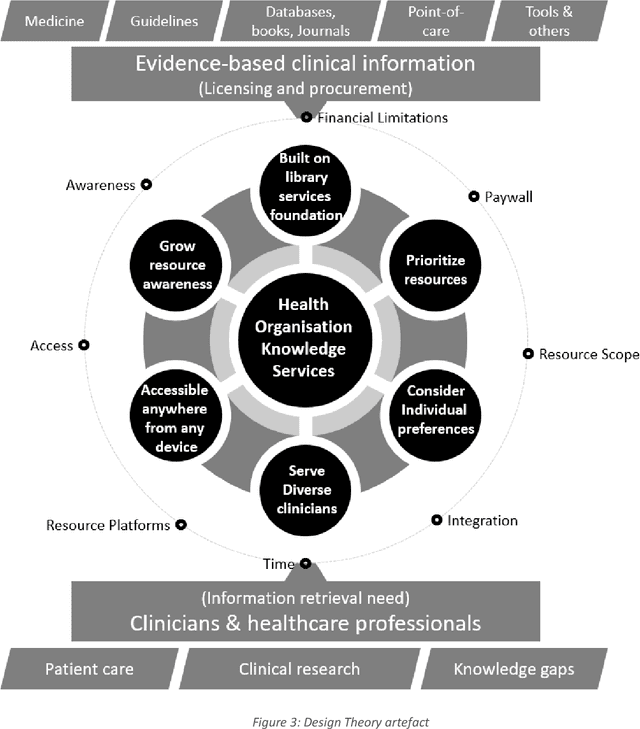
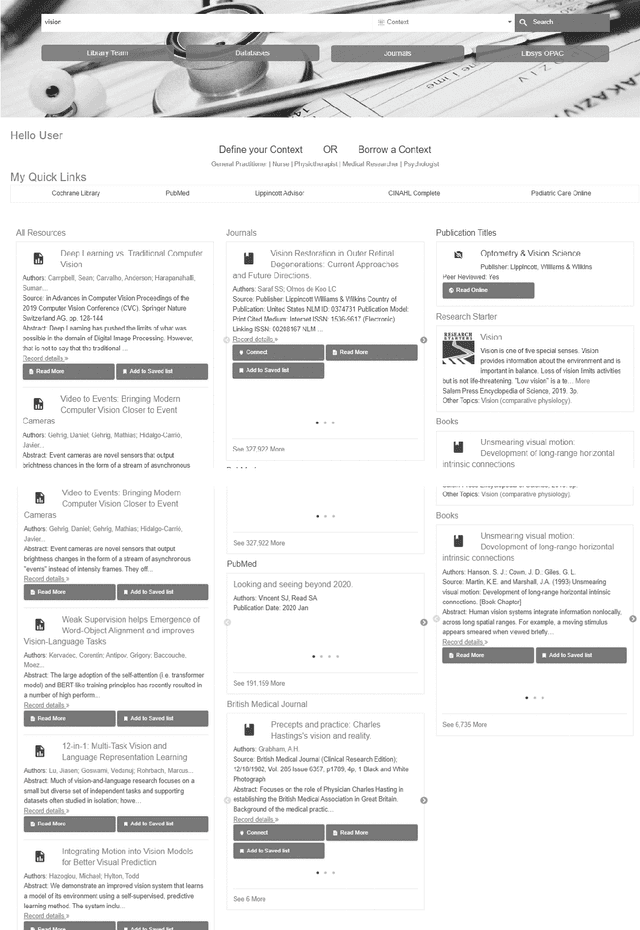
Objective: Our study objective is to design a feasible technology solution for health organizations to remove barriers to evidence-based clinical information retrieval, and improve Evidence-Based Practice. Methods: Literature from 2010 to 2020 was reviewed to define problems in evidence-based clinical information retrieval with recommendations from literature used to define solution objectives. Design Science Research is used to complete three projects in a research stream using cloud services such as Web-Scale Discovery, Content Management System, Federated Access, Global Knowledgebase, and Document Delivery. Design thinking, systems thinking, and user-oriented theory of information need are adopted to construct a design theory. Results: The research stream produced three novel and innovative artefacts: a contextual model, a unified architecture, and a context-aware unified architecture which we evaluate as part of academic reviews, scholarly publications, and conference proceedings in various research stream stages. A fourth artefact or design theory is presented to generalize results as mature knowledge.
Policy Optimization for Stochastic Shortest Path
Feb 07, 2022Policy optimization is among the most popular and successful reinforcement learning algorithms, and there is increasing interest in understanding its theoretical guarantees. In this work, we initiate the study of policy optimization for the stochastic shortest path (SSP) problem, a goal-oriented reinforcement learning model that strictly generalizes the finite-horizon model and better captures many applications. We consider a wide range of settings, including stochastic and adversarial environments under full information or bandit feedback, and propose a policy optimization algorithm for each setting that makes use of novel correction terms and/or variants of dilated bonuses (Luo et al., 2021). For most settings, our algorithm is shown to achieve a near-optimal regret bound. One key technical contribution of this work is a new approximation scheme to tackle SSP problems that we call \textit{stacked discounted approximation} and use in all our proposed algorithms. Unlike the finite-horizon approximation that is heavily used in recent SSP algorithms, our new approximation enables us to learn a near-stationary policy with only logarithmic changes during an episode and could lead to an exponential improvement in space complexity.
Modeling Spatio-Temporal Dynamics in Brain Networks: A Comparison of Graph Neural Network Architectures
Dec 08, 2021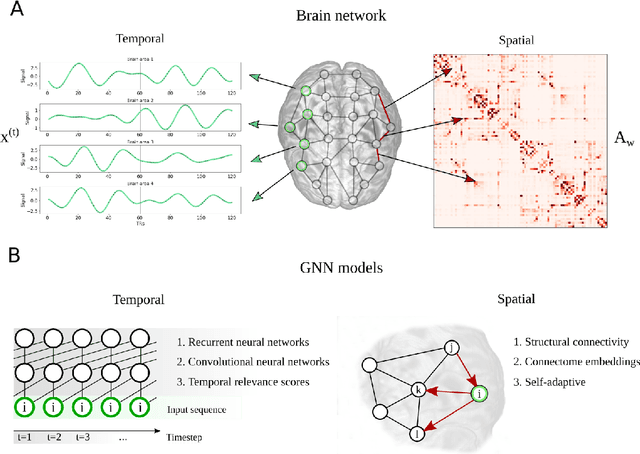

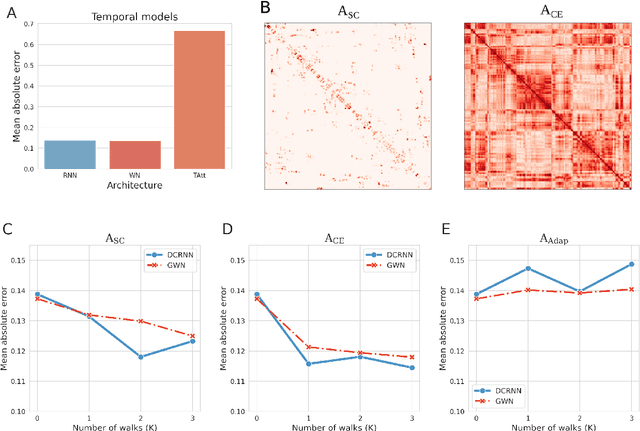
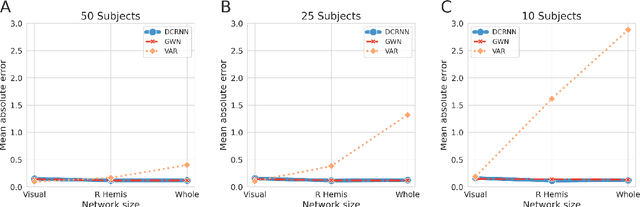
Comprehending the interplay between spatial and temporal characteristics of neural dynamics can contribute to our understanding of information processing in the human brain. Graph neural networks (GNNs) provide a new possibility to interpret graph structured signals like those observed in complex brain networks. In our study we compare different spatio-temporal GNN architectures and study their ability to replicate neural activity distributions obtained in functional MRI (fMRI) studies. We evaluate the performance of the GNN models on a variety of scenarios in MRI studies and also compare it to a VAR model, which is currently predominantly used for directed functional connectivity analysis. We show that by learning localized functional interactions on the anatomical substrate, GNN based approaches are able to robustly scale to large network studies, even when available data are scarce. By including anatomical connectivity as the physical substrate for information propagation, such GNNs also provide a multimodal perspective on directed connectivity analysis, offering a novel possibility to investigate the spatio-temporal dynamics in brain networks.
Towards a General Deep Feature Extractor for Facial Expression Recognition
Jan 19, 2022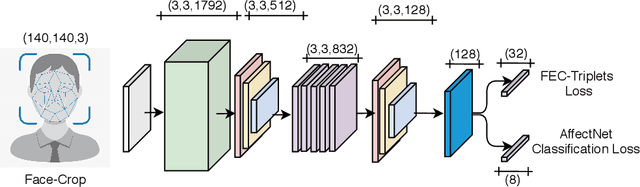



The human face conveys a significant amount of information. Through facial expressions, the face is able to communicate numerous sentiments without the need for verbalisation. Visual emotion recognition has been extensively studied. Recently several end-to-end trained deep neural networks have been proposed for this task. However, such models often lack generalisation ability across datasets. In this paper, we propose the Deep Facial Expression Vector ExtractoR (DeepFEVER), a new deep learning-based approach that learns a visual feature extractor general enough to be applied to any other facial emotion recognition task or dataset. DeepFEVER outperforms state-of-the-art results on the AffectNet and Google Facial Expression Comparison datasets. DeepFEVER's extracted features also generalise extremely well to other datasets -- even those unseen during training -- namely, the Real-World Affective Faces (RAF) dataset.
* Published in: 2021 IEEE International Conference on Image Processing (ICIP). arXiv admin note: text overlap with arXiv:2103.09154