 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning Advances for Time Series Forecasting
Jan 18, 2021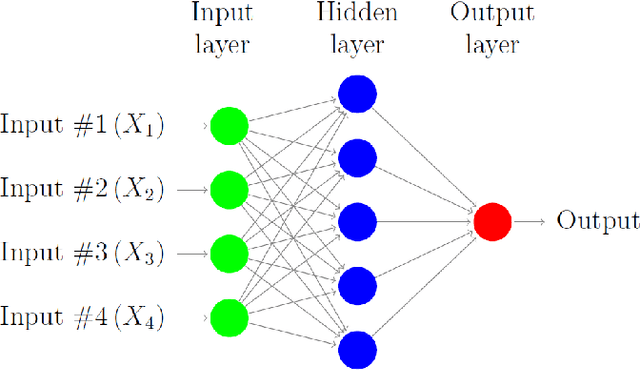
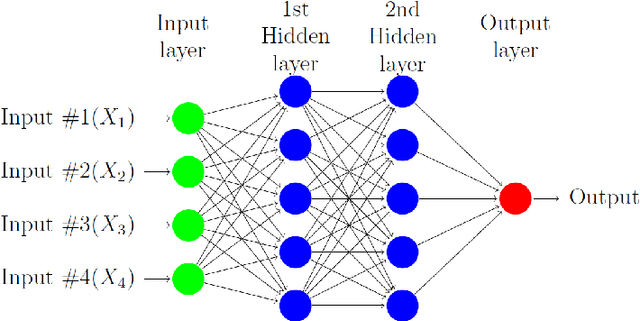
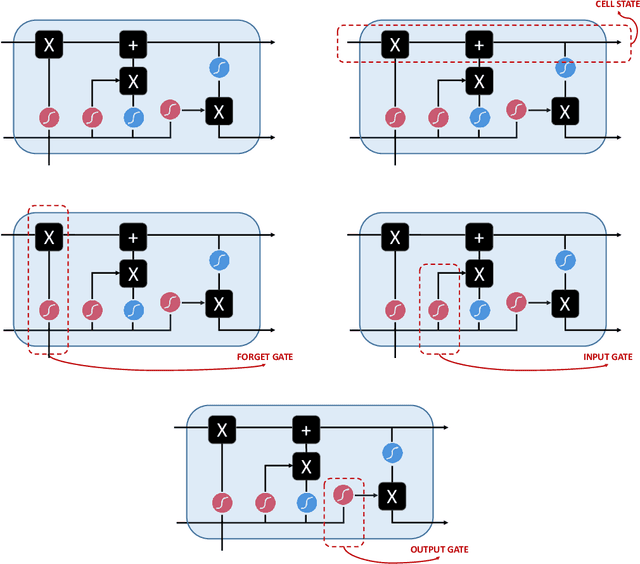
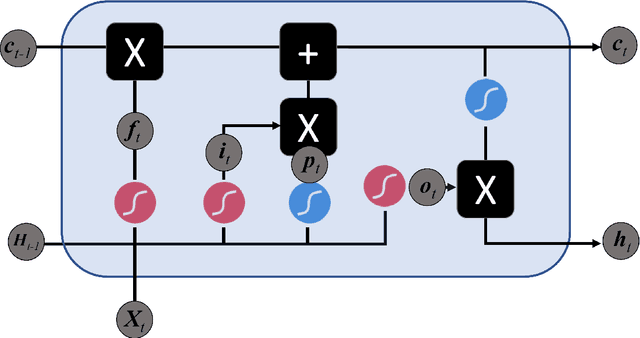
In this paper we survey the most recent advances in supervised machine learning and high-dimensional models for time series forecasting. We consider both linear and nonlinear alternatives. Among the linear methods we pay special attention to penalized regressions and ensemble of models. The nonlinear methods considered in the paper include shallow and deep neural networks, in their feed-forward and recurrent versions, and tree-based methods, such as random forests and boosted trees. We also consider ensemble and hybrid models by combining ingredients from different alternatives. Tests for superior predictive ability are briefly reviewed. Finally, we discuss application of machine learning in economics and finance and provide an illustration with high-frequency financial data.
Do We Exploit all Information for Counterfactual Analysis? Benefits of Factor Models and Idiosyncratic Correction
Nov 08, 2020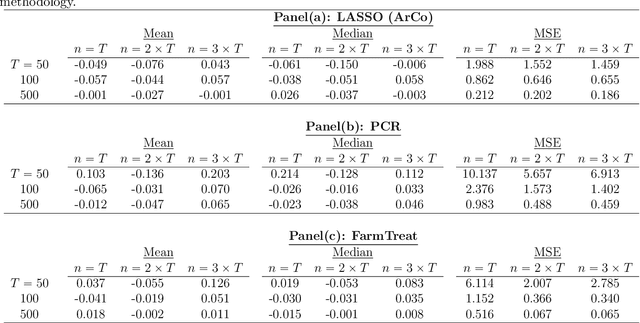
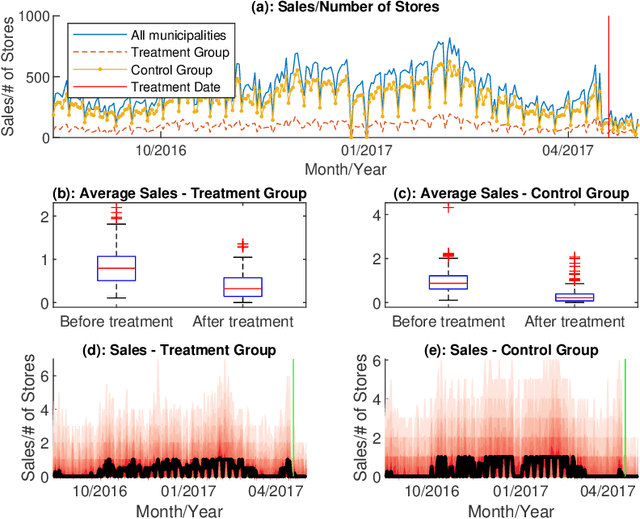
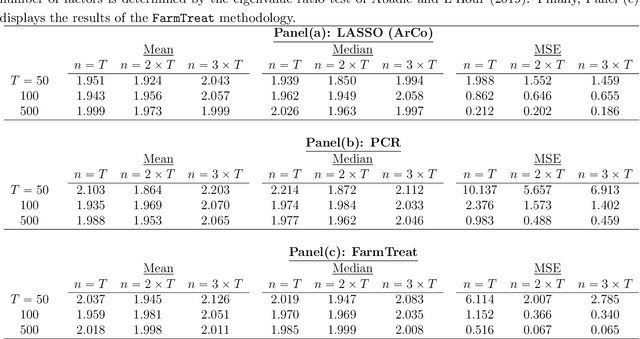
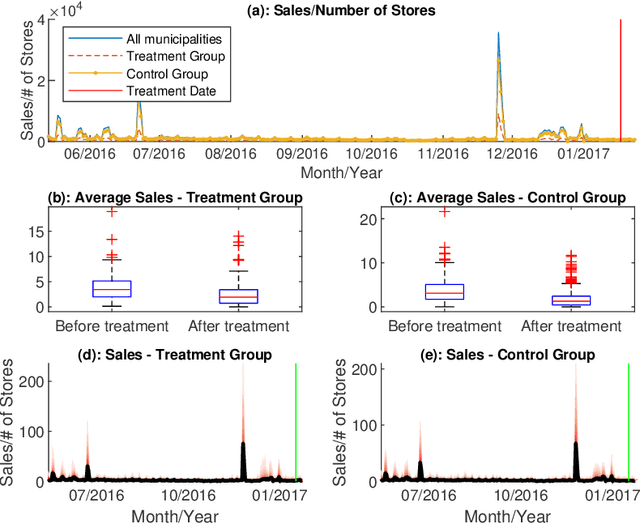
The measurement of treatment (intervention) effects on a single (or just a few) treated unit(s) based on counterfactuals constructed from artificial controls has become a popular practice in applied statistics and economics since the proposal of the synthetic control method. In high-dimensional setting, we often use principal component or (weakly) sparse regression to estimate counterfactuals. Do we use enough data information? To better estimate the effects of price changes on the sales in our case study, we propose a general framework on counterfactual analysis for high dimensional dependent data. The framework includes both principal component regression and sparse linear regression as specific cases. It uses both factor and idiosyncratic components as predictors for improved counterfactual analysis, resulting a method called Factor-Adjusted Regularized Method for Treatment (FarmTreat) evaluation. We demonstrate convincingly that using either factors or sparse regression is inadequate for counterfactual analysis in many applications and the case for information gain can be made through the use of idiosyncratic components. We also develop theory and methods to formally answer the question if common factors are adequate for estimating counterfactuals. Furthermore, we consider a simple resampling approach to conduct inference on the treatment effect as well as bootstrap test to access the relevance of the idiosyncratic components. We apply the proposed method to evaluate the effects of price changes on the sales of a set of products based on a novel large panel of sale data from a major retail chain in Brazil and demonstrate the benefits of using additional idiosyncratic components in the treatment effect evaluations.
Regularized Estimation of High-Dimensional Vector AutoRegressions with Weakly Dependent Innovations
Dec 19, 2019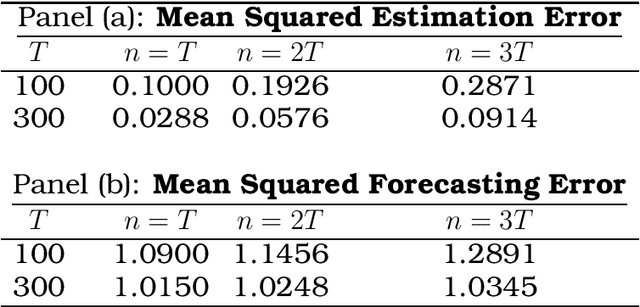
There has been considerable advance in understanding the properties of sparse regularization procedures in high-dimensional models. Most of the work is limited to either independent and identically distributed setting, or time series with independent and/or (sub-)Gaussian innovations. We extend current literature to a broader set of innovation processes, by assuming that the error process is non-sub-Gaussian and conditionally heteroscedastic, and the generating process is not necessarily sparse. This setting covers fat tailed, conditionally dependent innovations which is of particular interest for financial risk modeling. It covers several multivariate-GARCH specifications, such as the BEKK model, and other factor stochastic volatility specifications.