 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForecasting inflation using disaggregates and machine learning
Aug 22, 2023This paper examines the effectiveness of several forecasting methods for predicting inflation, focusing on aggregating disaggregated forecasts - also known in the literature as the bottom-up approach. Taking the Brazilian case as an application, we consider different disaggregation levels for inflation and employ a range of traditional time series techniques as well as linear and nonlinear machine learning (ML) models to deal with a larger number of predictors. For many forecast horizons, the aggregation of disaggregated forecasts performs just as well survey-based expectations and models that generate forecasts using the aggregate directly. Overall, ML methods outperform traditional time series models in predictive accuracy, with outstanding performance in forecasting disaggregates. Our results reinforce the benefits of using models in a data-rich environment for inflation forecasting, including aggregating disaggregated forecasts from ML techniques, mainly during volatile periods. Starting from the COVID-19 pandemic, the random forest model based on both aggregate and disaggregated inflation achieves remarkable predictive performance at intermediate and longer horizons.
Forecasting Large Realized Covariance Matrices: The Benefits of Factor Models and Shrinkage
Mar 22, 2023We propose a model to forecast large realized covariance matrices of returns, applying it to the constituents of the S\&P 500 daily. To address the curse of dimensionality, we decompose the return covariance matrix using standard firm-level factors (e.g., size, value, and profitability) and use sectoral restrictions in the residual covariance matrix. This restricted model is then estimated using vector heterogeneous autoregressive (VHAR) models with the least absolute shrinkage and selection operator (LASSO). Our methodology improves forecasting precision relative to standard benchmarks and leads to better estimates of minimum variance portfolios.
The Proper Use of Google Trends in Forecasting Models
Apr 10, 2021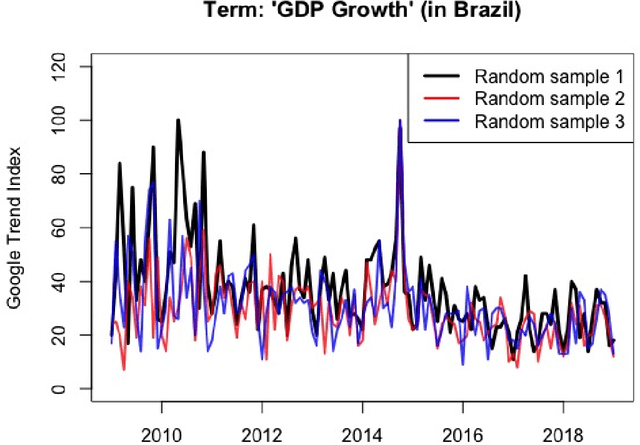
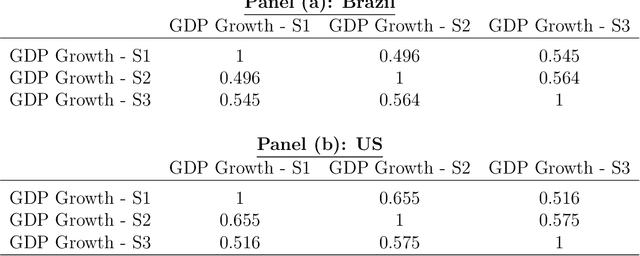
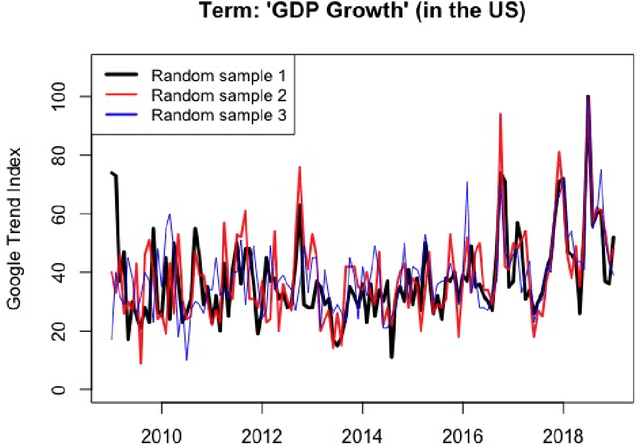
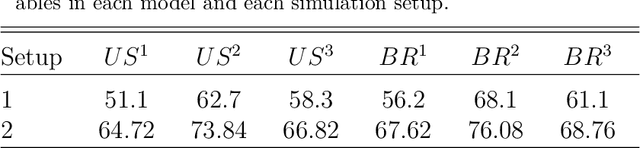
It is widely known that Google Trends have become one of the most popular free tools used by forecasters both in academics and in the private and public sectors. There are many papers, from several different fields, concluding that Google Trends improve forecasts' accuracy. However, what seems to be widely unknown, is that each sample of Google search data is different from the other, even if you set the same search term, data and location. This means that it is possible to find arbitrary conclusions merely by chance. This paper aims to show why and when it can become a problem and how to overcome this obstacle.
Machine Learning Advances for Time Series Forecasting
Jan 18, 2021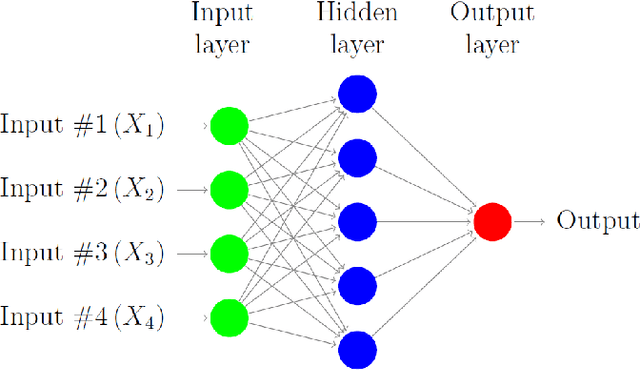
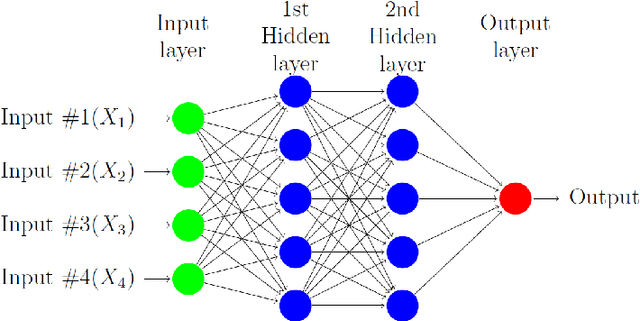
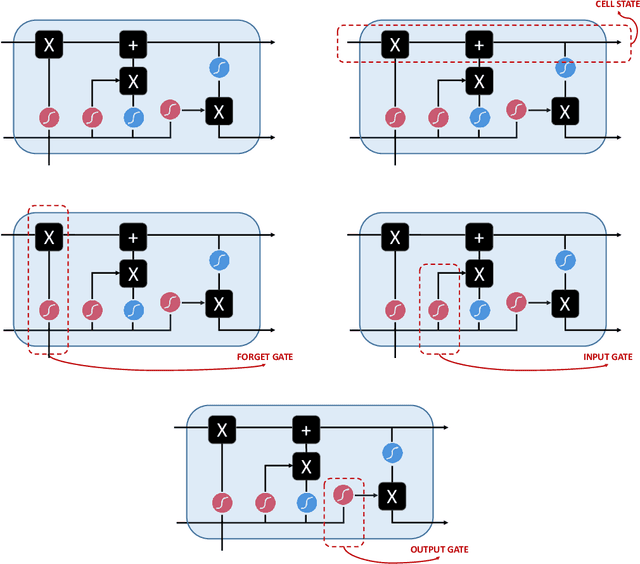
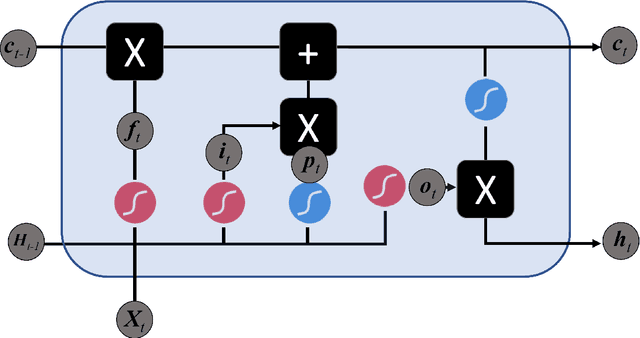
In this paper we survey the most recent advances in supervised machine learning and high-dimensional models for time series forecasting. We consider both linear and nonlinear alternatives. Among the linear methods we pay special attention to penalized regressions and ensemble of models. The nonlinear methods considered in the paper include shallow and deep neural networks, in their feed-forward and recurrent versions, and tree-based methods, such as random forests and boosted trees. We also consider ensemble and hybrid models by combining ingredients from different alternatives. Tests for superior predictive ability are briefly reviewed. Finally, we discuss application of machine learning in economics and finance and provide an illustration with high-frequency financial data.
Do We Exploit all Information for Counterfactual Analysis? Benefits of Factor Models and Idiosyncratic Correction
Nov 08, 2020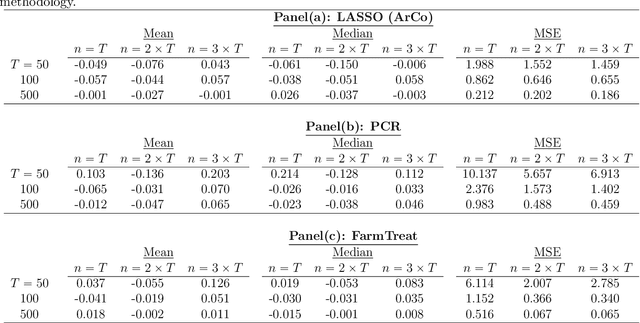
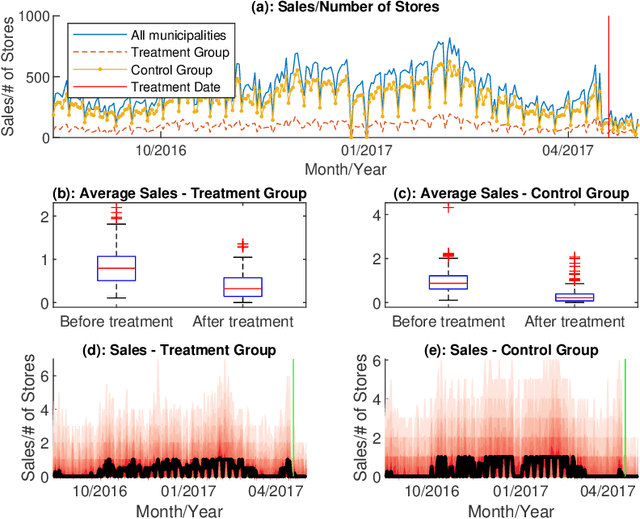
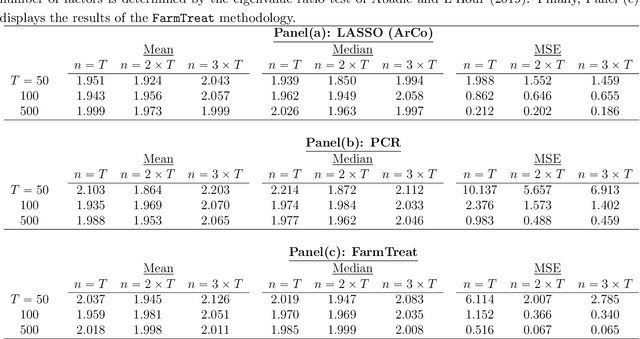
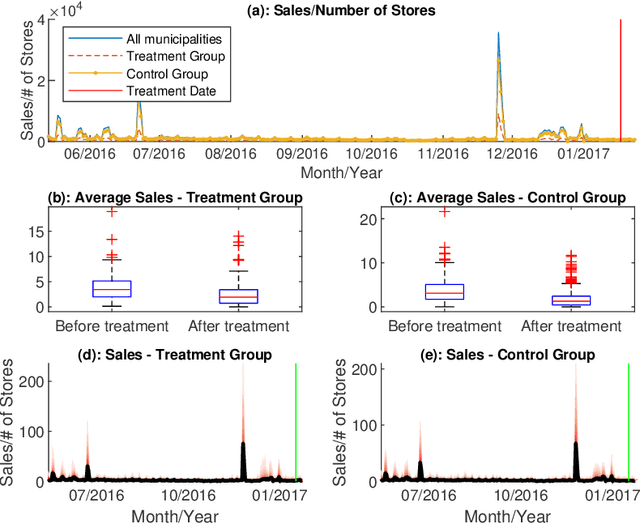
The measurement of treatment (intervention) effects on a single (or just a few) treated unit(s) based on counterfactuals constructed from artificial controls has become a popular practice in applied statistics and economics since the proposal of the synthetic control method. In high-dimensional setting, we often use principal component or (weakly) sparse regression to estimate counterfactuals. Do we use enough data information? To better estimate the effects of price changes on the sales in our case study, we propose a general framework on counterfactual analysis for high dimensional dependent data. The framework includes both principal component regression and sparse linear regression as specific cases. It uses both factor and idiosyncratic components as predictors for improved counterfactual analysis, resulting a method called Factor-Adjusted Regularized Method for Treatment (FarmTreat) evaluation. We demonstrate convincingly that using either factors or sparse regression is inadequate for counterfactual analysis in many applications and the case for information gain can be made through the use of idiosyncratic components. We also develop theory and methods to formally answer the question if common factors are adequate for estimating counterfactuals. Furthermore, we consider a simple resampling approach to conduct inference on the treatment effect as well as bootstrap test to access the relevance of the idiosyncratic components. We apply the proposed method to evaluate the effects of price changes on the sales of a set of products based on a novel large panel of sale data from a major retail chain in Brazil and demonstrate the benefits of using additional idiosyncratic components in the treatment effect evaluations.
Online Action Learning in High Dimensions: A New Exploration Rule for Contextual $ε_t$-Greedy Heuristics
Sep 29, 2020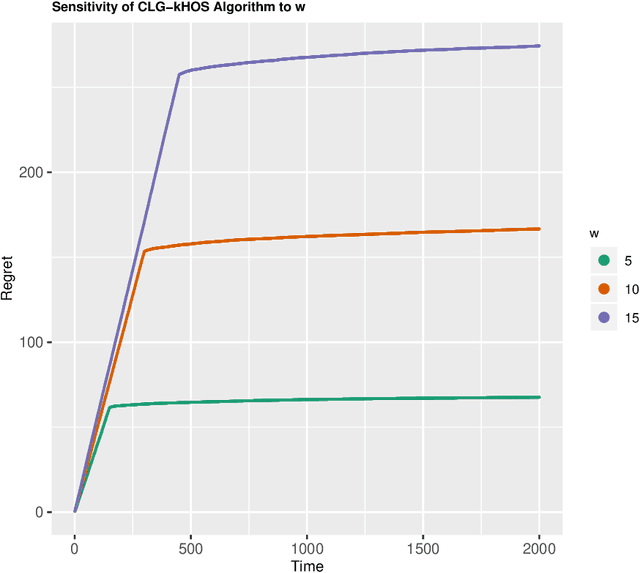
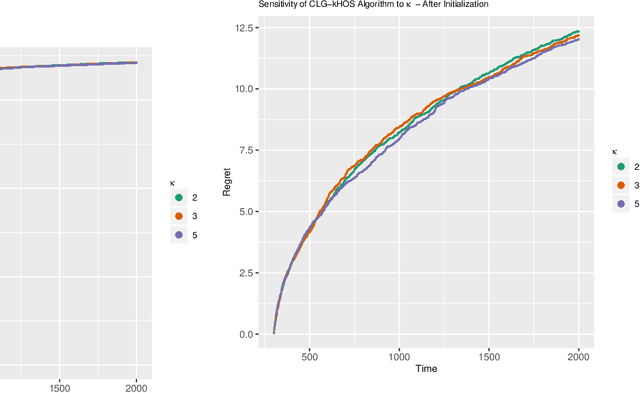
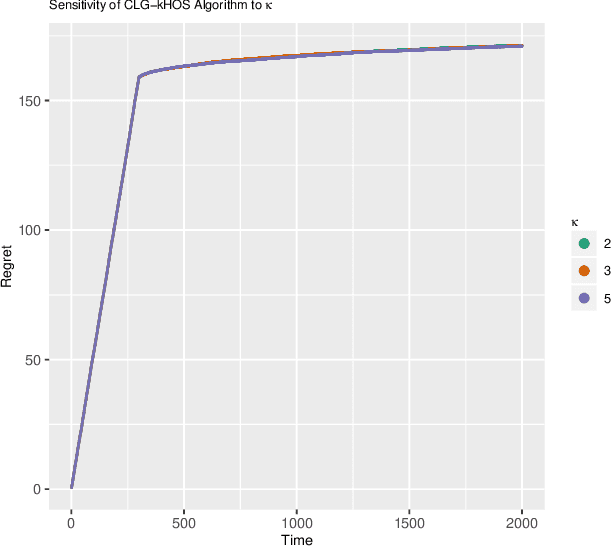
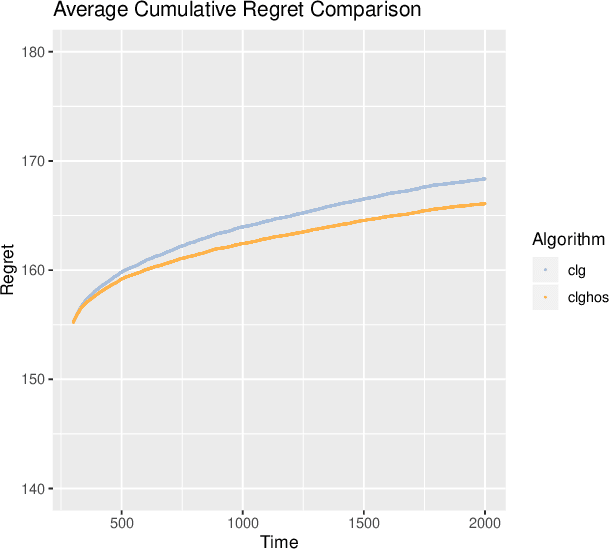
Bandit problems are pervasive in various fields of research and are also present in several practical applications. Examples, including dynamic pricing and assortment and the design of auctions and incentives, permeate a large number of sequential treatment experiments. Different applications impose distinct levels of restrictions on viable actions. Some favor diversity of outcomes, while others require harmful actions to be closely monitored or mainly avoided. In this paper, we extend one of the most popular bandit solutions, the original $\epsilon_t$-greedy heuristics, to high-dimensional contexts. Moreover, we introduce a competing exploration mechanism that counts with searching sets based on order statistics. We view our proposals as alternatives for cases where pluralism is valued or, in the opposite direction, cases where the end-user should carefully tune the range of exploration of new actions. We find reasonable bounds for the cumulative regret of a decaying $\epsilon_t$-greedy heuristic in both cases and we provide an upper bound for the initialization phase that implies the regret bounds when order statistics are considered to be at most equal but mostly better than the case when random searching is the sole exploration mechanism. Additionally, we show that end-users have sufficient flexibility to avoid harmful actions since any cardinality for the higher-order statistics can be used to achieve an stricter upper bound. In a simulation exercise, we show that the algorithms proposed in this paper outperform simple and adapted counterparts.
Regularized Estimation of High-Dimensional Vector AutoRegressions with Weakly Dependent Innovations
Dec 19, 2019
There has been considerable advance in understanding the properties of sparse regularization procedures in high-dimensional models. Most of the work is limited to either independent and identically distributed setting, or time series with independent and/or (sub-)Gaussian innovations. We extend current literature to a broader set of innovation processes, by assuming that the error process is non-sub-Gaussian and conditionally heteroscedastic, and the generating process is not necessarily sparse. This setting covers fat tailed, conditionally dependent innovations which is of particular interest for financial risk modeling. It covers several multivariate-GARCH specifications, such as the BEKK model, and other factor stochastic volatility specifications.