 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Predictive Beamforming for Integrated Sensing and Communication in Vehicular Networks: A Deep Learning Approach
Feb 08, 2022
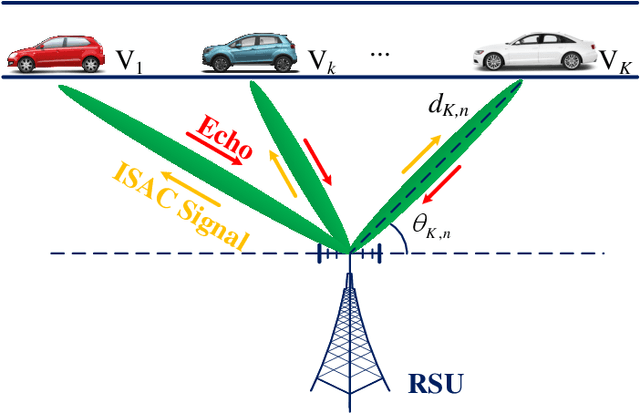
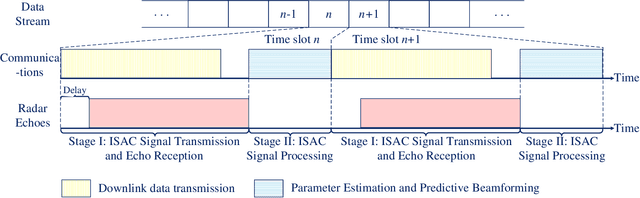
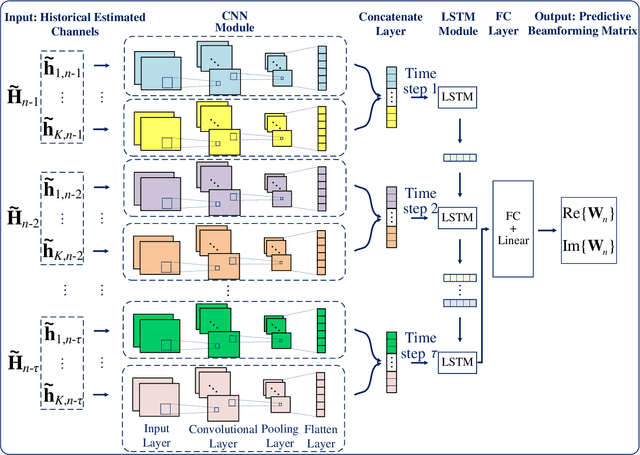
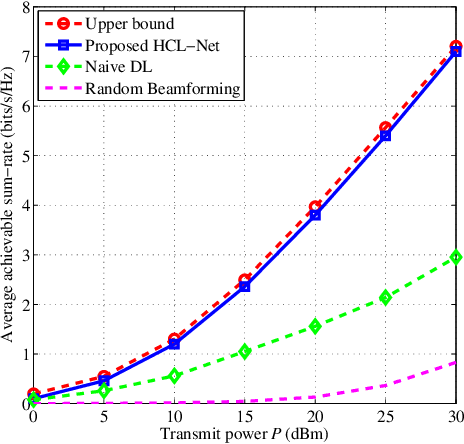
The implementation of integrated sensing and communication (ISAC) highly depends on the effective beamforming design exploiting accurate instantaneous channel state information (ICSI). However, channel tracking in ISAC requires large amount of training overhead and prohibitively large computational complexity. To address this problem, in this paper, we focus on ISAC-assisted vehicular networks and exploit a deep learning approach to implicitly learn the features of historical channels and directly predict the beamforming matrix for the next time slot to maximize the average achievable sum-rate of system, thus bypassing the need of explicit channel tracking for reducing the system signaling overhead. To this end, a general sum-rate maximization problem with Cramer-Rao lower bounds-based sensing constraints is first formulated for the considered ISAC system. Then, a historical channels-based convolutional long short-term memory network is designed for predictive beamforming that can exploit the spatial and temporal dependencies of communication channels to further improve the learning performance. Finally, simulation results show that the proposed method can satisfy the requirement of sensing performance, while its achievable sum-rate can approach the upper bound obtained by a genie-aided scheme with perfect ICSI available.
Differential Modulation in Massive MIMO With Low-Resolution ADCs
Nov 09, 2021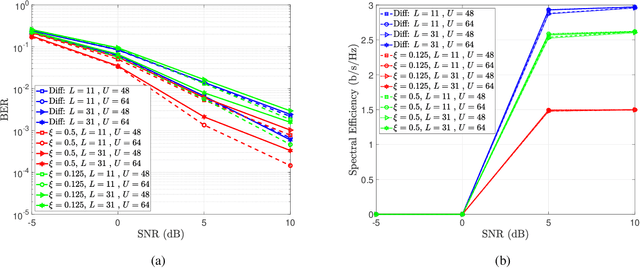
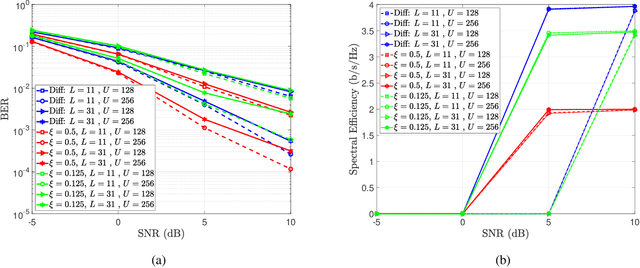
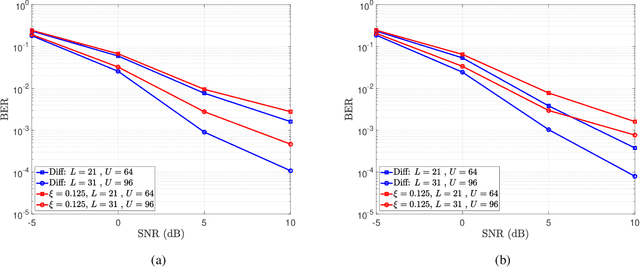
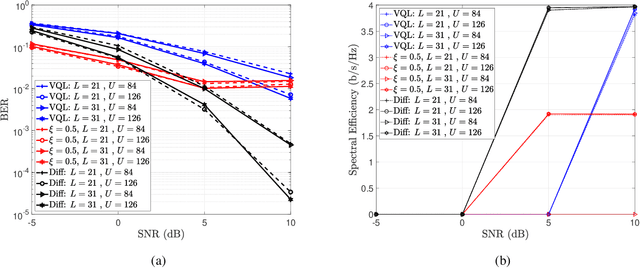
In this paper, we present a differential modulation and detection scheme for use in the uplink of a system with a large number of antennas at the base station, each equipped with low-resolution analog-to-digital converters (ADCs). We derive an expression for the maximum likelihood (ML) detector of a differentially encoded phase information symbol received by a base station operating in the low-resolution ADC regime. We also present an equal performing reduced complexity receiver for detecting the phase information. To increase the supported data rate, we also present a maximum likelihood expression to detect differential amplitude phase shift keying symbols with low-resolution ADCs. We note that the derived detectors are unable to detect the amplitude information. To overcome this limitation, we use the Bussgang Theorem and the Central Limit Theorem (CLT) to develop two detectors capable of detecting the amplitude information. We numerically show that while the first amplitude detector requires multiple quantization bits for acceptable performance, similar performance can be achieved using one-bit ADCs by grouping the receive antennas and employing variable quantization levels (VQL) across distinct antenna groups. We validate the performance of the proposed detectors through simulations and show a comparison with corresponding coherent detectors. Finally, we present a complexity analysis of the proposed low-resolution differential detectors
Improving Lyrics Alignment through Joint Pitch Detection
Feb 03, 2022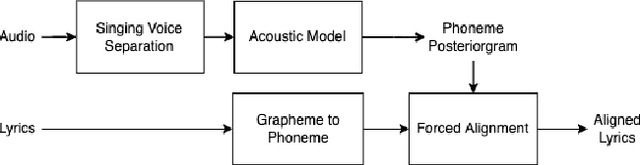
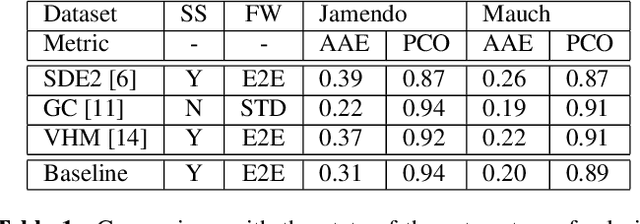
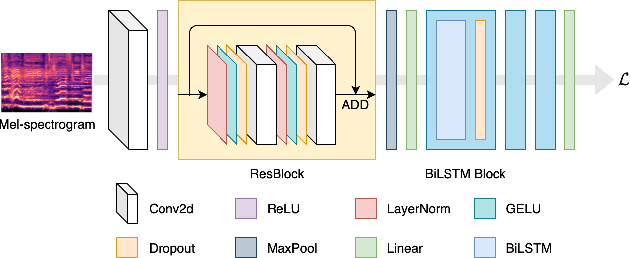
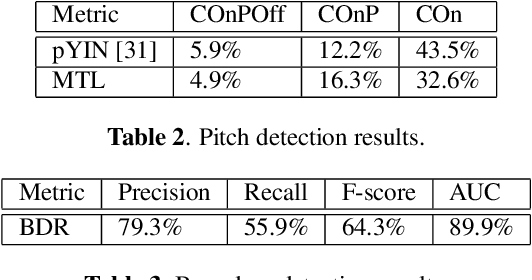
In recent years, the accuracy of automatic lyrics alignment methods has increased considerably. Yet, many current approaches employ frameworks designed for automatic speech recognition (ASR) and do not exploit properties specific to music. Pitch is one important musical attribute of singing voice but it is often ignored by current systems as the lyrics content is considered independent of the pitch. In practice, however, there is a temporal correlation between the two as note starts often correlate with phoneme starts. At the same time the pitch is usually annotated with high temporal accuracy in ground truth data while the timing of lyrics is often only available at the line (or word) level. In this paper, we propose a multi-task learning approach for lyrics alignment that incorporates pitch and thus can make use of a new source of highly accurate temporal information. Our results show that the accuracy of the alignment result is indeed improved by our approach. As an additional contribution, we show that integrating boundary detection in the forced-alignment algorithm reduces cross-line errors, which improves the accuracy even further.
Interpolation-based Contrastive Learning for Few-Label Semi-Supervised Learning
Feb 24, 2022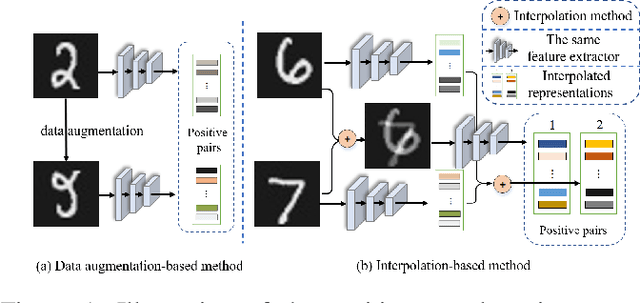

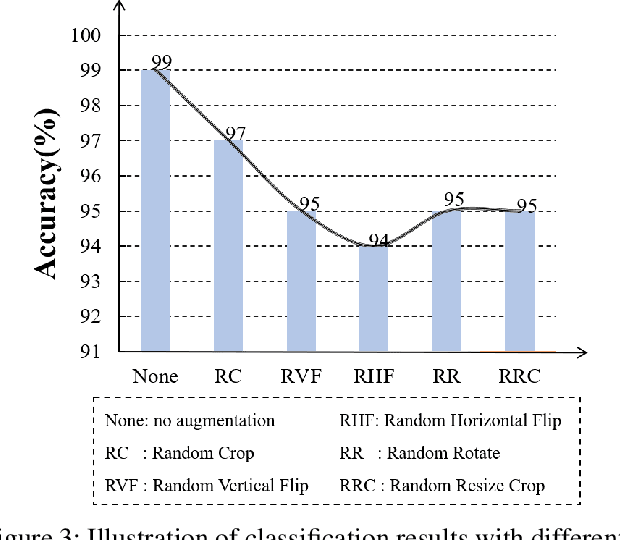
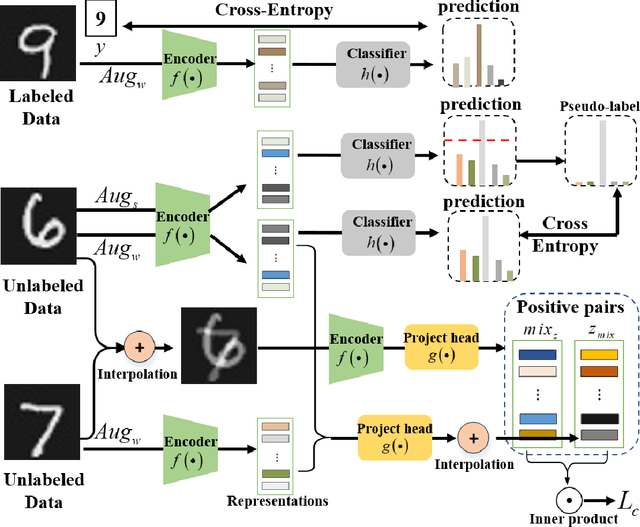
Semi-supervised learning (SSL) has long been proved to be an effective technique to construct powerful models with limited labels. In the existing literature, consistency regularization-based methods, which force the perturbed samples to have similar predictions with the original ones have attracted much attention for their promising accuracy. However, we observe that, the performance of such methods decreases drastically when the labels get extremely limited, e.g., 2 or 3 labels for each category. Our empirical study finds that the main problem lies with the drifting of semantic information in the procedure of data augmentation. The problem can be alleviated when enough supervision is provided. However, when little guidance is available, the incorrect regularization would mislead the network and undermine the performance of the algorithm. To tackle the problem, we (1) propose an interpolation-based method to construct more reliable positive sample pairs; (2) design a novel contrastive loss to guide the embedding of the learned network to change linearly between samples so as to improve the discriminative capability of the network by enlarging the margin decision boundaries. Since no destructive regularization is introduced, the performance of our proposed algorithm is largely improved. Specifically, the proposed algorithm outperforms the second best algorithm (Comatch) with 5.3% by achieving 88.73% classification accuracy when only two labels are available for each class on the CIFAR-10 dataset. Moreover, we further prove the generality of the proposed method by improving the performance of the existing state-of-the-art algorithms considerably with our proposed strategy.
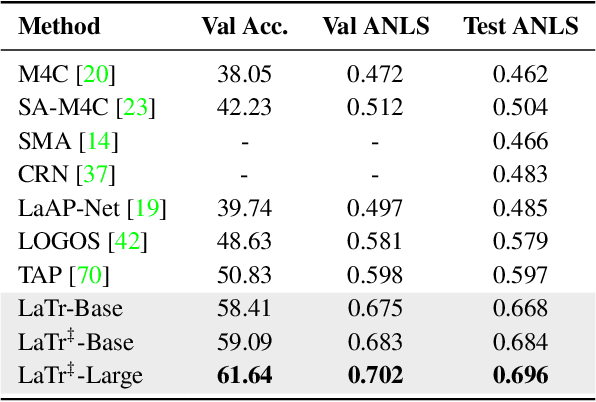
LaTr: Layout-Aware Transformer for Scene-Text VQA
Dec 24, 2021
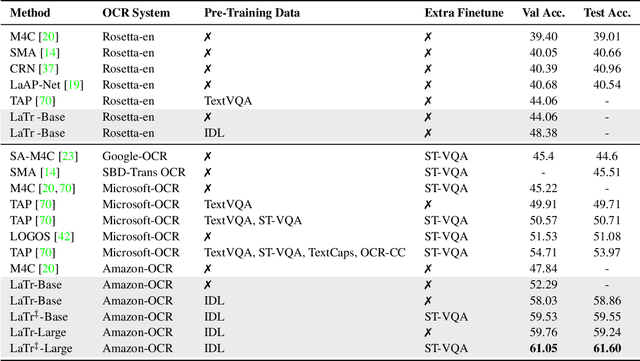
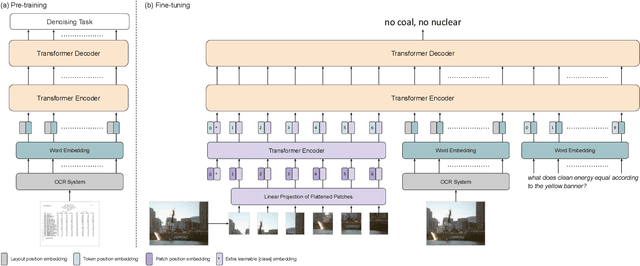
We propose a novel multimodal architecture for Scene Text Visual Question Answering (STVQA), named Layout-Aware Transformer (LaTr). The task of STVQA requires models to reason over different modalities. Thus, we first investigate the impact of each modality, and reveal the importance of the language module, especially when enriched with layout information. Accounting for this, we propose a single objective pre-training scheme that requires only text and spatial cues. We show that applying this pre-training scheme on scanned documents has certain advantages over using natural images, despite the domain gap. Scanned documents are easy to procure, text-dense and have a variety of layouts, helping the model learn various spatial cues (e.g. left-of, below etc.) by tying together language and layout information. Compared to existing approaches, our method performs vocabulary-free decoding and, as shown, generalizes well beyond the training vocabulary. We further demonstrate that LaTr improves robustness towards OCR errors, a common reason for failure cases in STVQA. In addition, by leveraging a vision transformer, we eliminate the need for an external object detector. LaTr outperforms state-of-the-art STVQA methods on multiple datasets. In particular, +7.6% on TextVQA, +10.8% on ST-VQA and +4.0% on OCR-VQA (all absolute accuracy numbers).
A Novel Deep Parallel Time-series Relation Network for Fault Diagnosis
Dec 03, 2021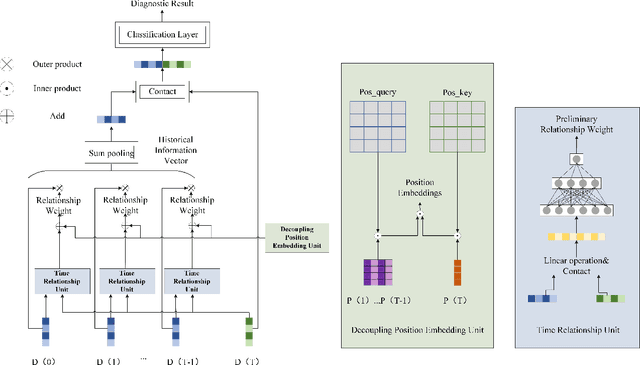

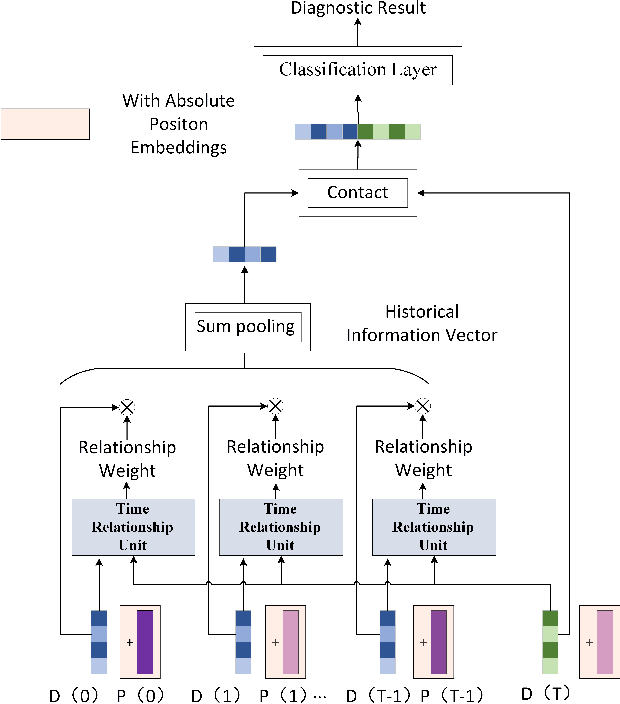

Considering the models that apply the contextual information of time-series data could improve the fault diagnosis performance, some neural network structures such as RNN, LSTM, and GRU were proposed to model the industrial process effectively. However, these models are restricted by their serial computation and hence cannot achieve high diagnostic efficiency. Also the parallel CNN is difficult to implement fault diagnosis in an efficient way because it requires larger convolution kernels or deep structure to achieve long-term feature extraction capabilities. Besides, BERT model applies absolute position embedding to introduce contextual information to the model, which would bring noise to the raw data and therefore cannot be applied to fault diagnosis directly. In order to address the above problems, a fault diagnosis model named deep parallel time-series relation network(\textit{DPTRN}) has been proposed in this paper. There are mainly three advantages for DPTRN: (1) Our proposed time relationship unit is based on full multilayer perceptron(\textit{MLP}) structure, therefore, DPTRN performs fault diagnosis in a parallel way and improves computing efficiency significantly. (2) By improving the absolute position embedding, our novel decoupling position embedding unit could be applied on the fault diagnosis directly and learn contextual information. (3) Our proposed DPTRN has obvious advantage in feature interpretability. Our model outperforms other methods on both TE and KDD-CUP99 datasets which confirms the effectiveness, efficiency and interpretability of the proposed DPTRN model.
Scale-arbitrary Invertible Image Downscaling
Feb 08, 2022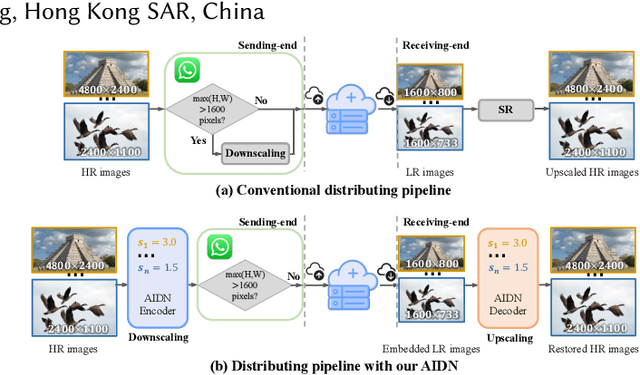
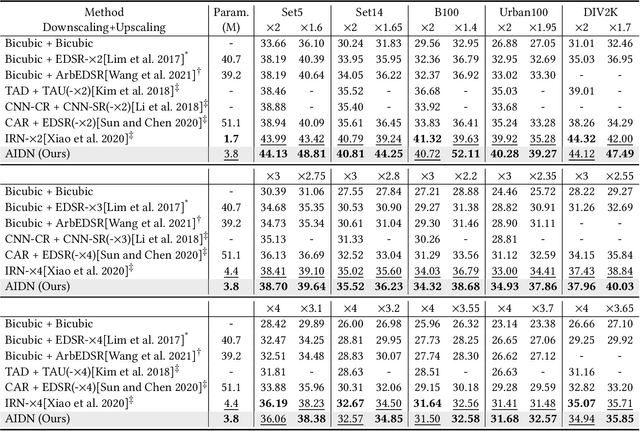
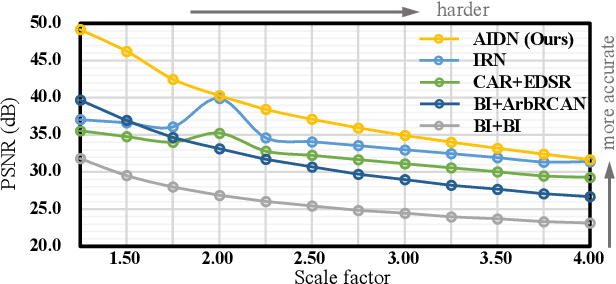
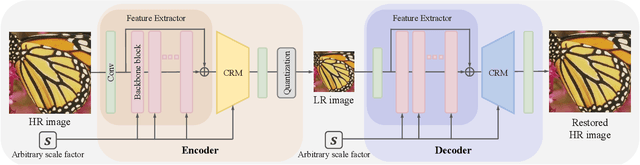
Downscaling is indispensable when distributing high-resolution (HR) images over the Internet to fit the displays of various resolutions, while upscaling is also necessary when users want to see details of the distributed images. Recent invertible image downscaling methods jointly model these two problems and achieve significant improvements. However, they only consider fixed integer scale factors that cannot meet the requirement of conveniently fitting the displays of various resolutions in real-world applications. In this paper, we propose a scale-Arbitrary Invertible image Downscaling Network (AIDN), to natively downscale HR images with arbitrary scale factors for fitting various target resolutions. Meanwhile, the HR information is embedded in the downscaled low-resolution (LR) counterparts in a nearly imperceptible form such that our AIDN can also restore the original HR images solely from the LR images. The key to supporting arbitrary scale factors is our proposed Conditional Resampling Module (CRM) that conditions the downscaling/upscaling kernels and sampling locations on both scale factors and image content. Extensive experimental results demonstrate that our AIDN achieves top performance for invertible downscaling with both arbitrary integer and non-integer scale factors.
FedNI: Federated Graph Learning with Network Inpainting for Population-Based Disease Prediction
Dec 19, 2021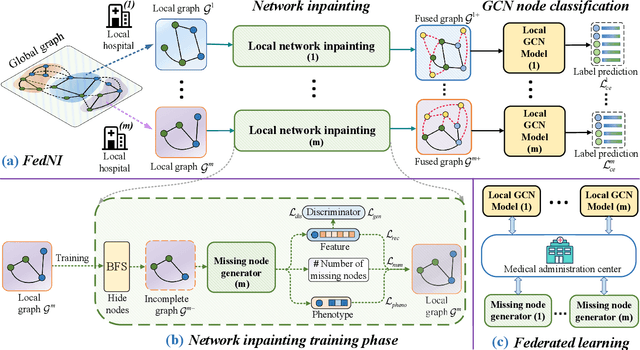
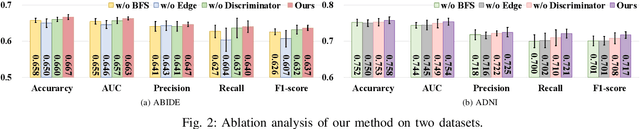
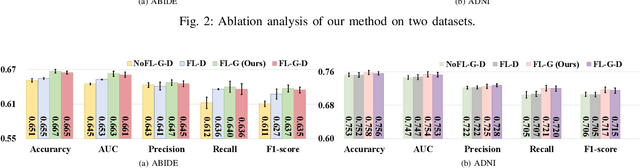

Graph Convolutional Neural Networks (GCNs) are widely used for graph analysis. Specifically, in medical applications, GCNs can be used for disease prediction on a population graph, where graph nodes represent individuals and edges represent individual similarities. However, GCNs rely on a vast amount of data, which is challenging to collect for a single medical institution. In addition, a critical challenge that most medical institutions continue to face is addressing disease prediction in isolation with incomplete data information. To address these issues, Federated Learning (FL) allows isolated local institutions to collaboratively train a global model without data sharing. In this work, we propose a framework, FedNI, to leverage network inpainting and inter-institutional data via FL. Specifically, we first federatively train missing node and edge predictor using a graph generative adversarial network (GAN) to complete the missing information of local networks. Then we train a global GCN node classifier across institutions using a federated graph learning platform. The novel design enables us to build more accurate machine learning models by leveraging federated learning and also graph learning approaches. We demonstrate that our federated model outperforms local and baseline FL methods with significant margins on two public neuroimaging datasets.
Detection of Correlated Alarms Using Graph Embedding
Jan 17, 2022
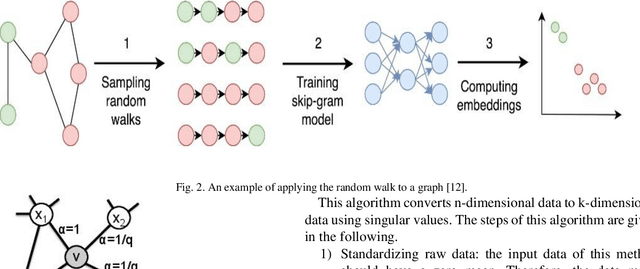
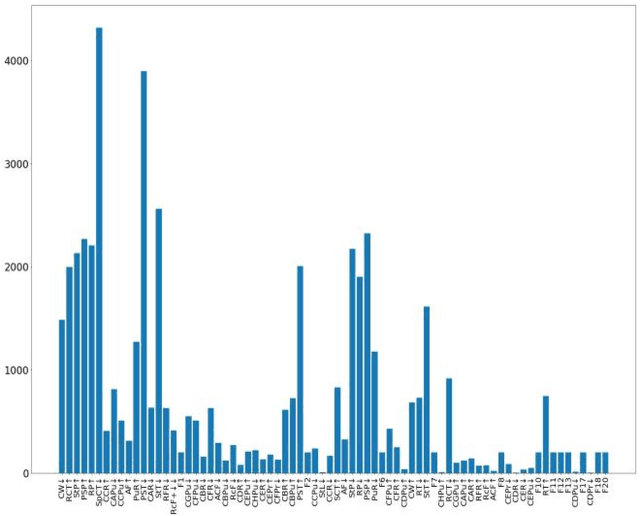
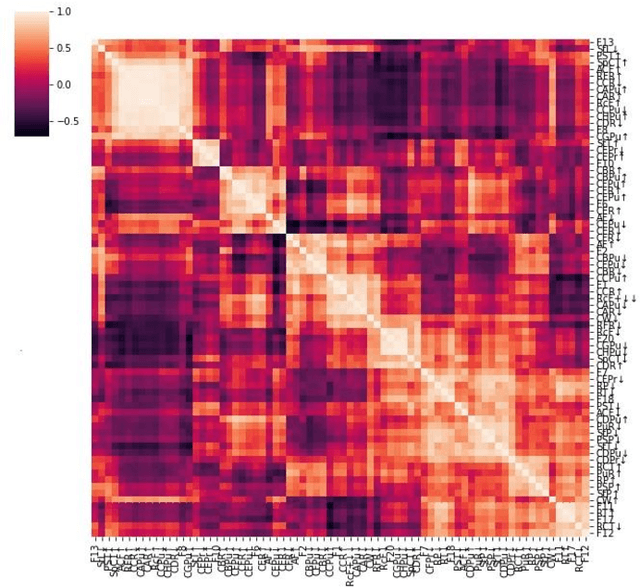
Industrial alarm systems have recently progressed considerably in terms of network complexity and the number of alarms. The increase in complexity and number of alarms presents challenges in these systems that decrease system efficiency and cause distrust of the operator, which might result in widespread damages. One contributing factor in alarm inefficiency is the correlated alarms. These alarms do not contain new information and only confuse the operator. This paper tries to present a novel method for detecting correlated alarms based on artificial intelligence methods to help the operator. The proposed method is based on graph embedding and alarm clustering, resulting in the detection of correlated alarms. To evaluate the proposed method, a case study is conducted on the well-known Tennessee-Eastman process.
SAM: A Self-adaptive Attention Module for Context-Aware Recommendation System
Oct 01, 2021



Recently, textual information has been proved to play a positive role in recommendation systems. However, most of the existing methods only focus on representation learning of textual information in ratings, while potential selection bias induced by the textual information is ignored. In this work, we propose a novel and general self-adaptive module, the Self-adaptive Attention Module (SAM), which adjusts the selection bias by capturing contextual information based on its representation. This module can be embedded into recommendation systems that contain learning components of contextual information. Experimental results on three real-world datasets demonstrate the effectiveness of our proposal, and the state-of-the-art models with SAM significantly outperform the original ones.