 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
FairPrune: Achieving Fairness Through Pruning for Dermatological Disease Diagnosis
Mar 04, 2022
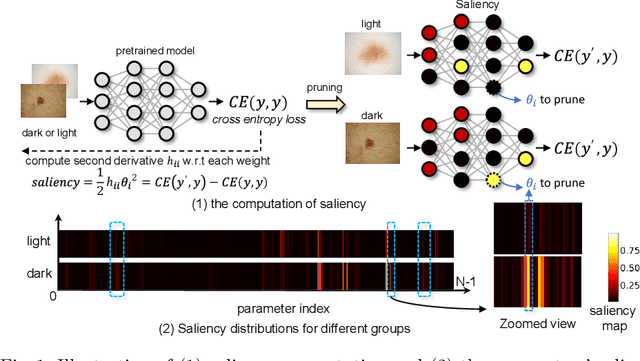
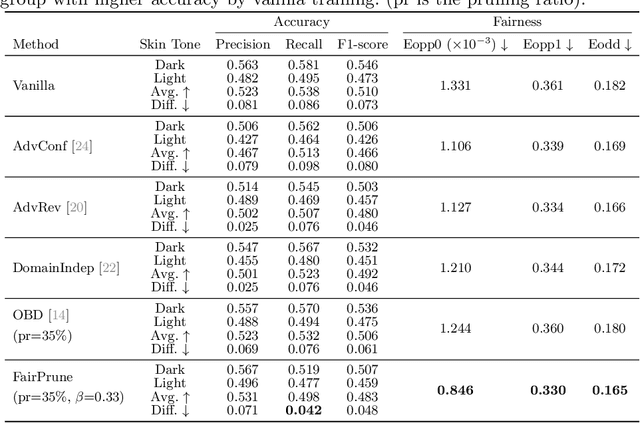
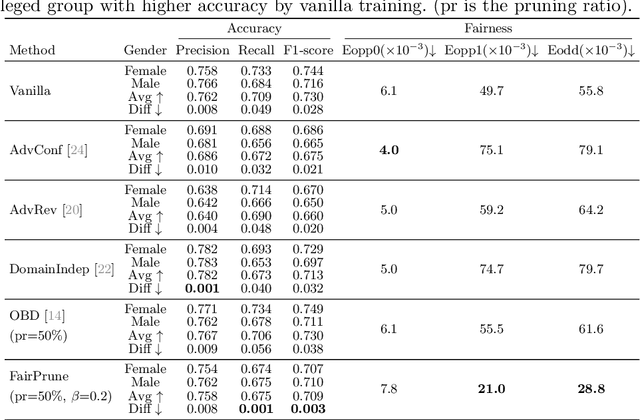
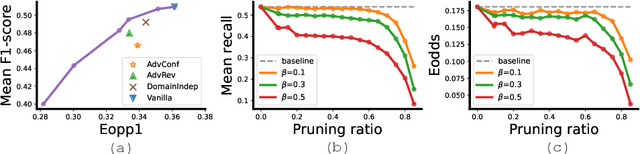
Many works have shown that deep learning-based medical image classification models can exhibit bias toward certain demographic attributes like race, gender, and age. Existing bias mitigation methods primarily focus on learning debiased models, which may not necessarily guarantee all sensitive information can be removed and usually comes with considerable accuracy degradation on both privileged and unprivileged groups. To tackle this issue, we propose a method, FairPrune, that achieves fairness by pruning. Conventionally, pruning is used to reduce the model size for efficient inference. However, we show that pruning can also be a powerful tool to achieve fairness. Our observation is that during pruning, each parameter in the model has different importance for different groups' accuracy. By pruning the parameters based on this importance difference, we can reduce the accuracy difference between the privileged group and the unprivileged group to improve fairness without a large accuracy drop. To this end, we use the second derivative of the parameters of a pre-trained model to quantify the importance of each parameter with respect to the model accuracy for each group. Experiments on two skin lesion diagnosis datasets over multiple sensitive attributes demonstrate that our method can greatly improve fairness while keeping the average accuracy of both groups as high as possible.
Non-Linear Spectral Dimensionality Reduction Under Uncertainty
Feb 09, 2022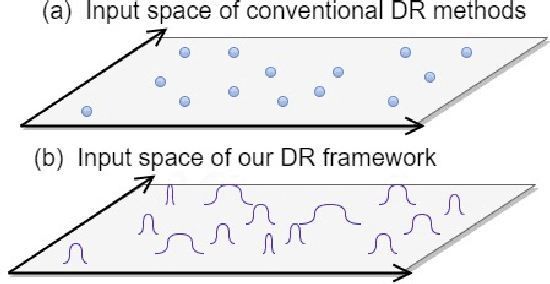
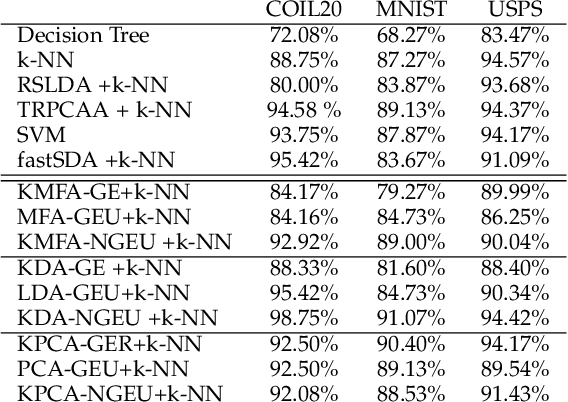
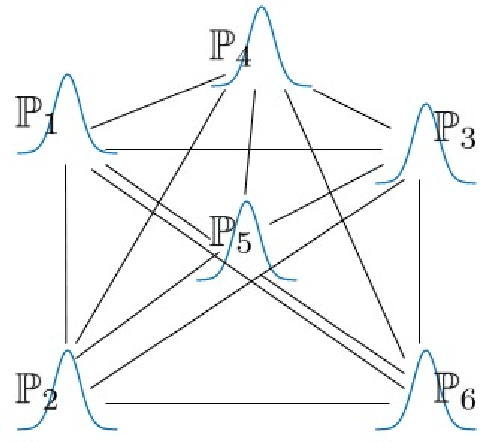
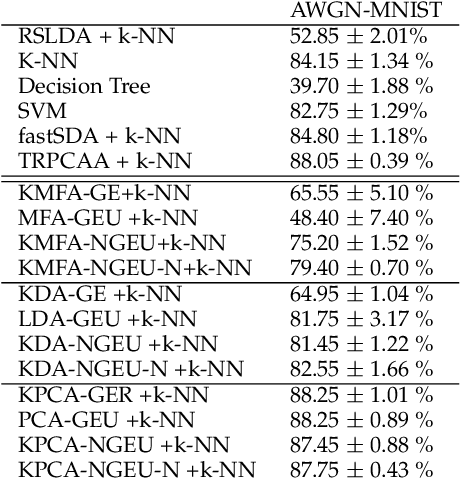
In this paper, we consider the problem of non-linear dimensionality reduction under uncertainty, both from a theoretical and algorithmic perspectives. Since real-world data usually contain measurements with uncertainties and artifacts, the input space in the proposed framework consists of probability distributions to model the uncertainties associated with each sample. We propose a new dimensionality reduction framework, called NGEU, which leverages uncertainty information and directly extends several traditional approaches, e.g., KPCA, MDA/KMFA, to receive as inputs the probability distributions instead of the original data. We show that the proposed NGEU formulation exhibits a global closed-form solution, and we analyze, based on the Rademacher complexity, how the underlying uncertainties theoretically affect the generalization ability of the framework. Empirical results on different datasets show the effectiveness of the proposed framework.
DARL1N: Distributed multi-Agent Reinforcement Learning with One-hop Neighbors
Feb 18, 2022



Most existing multi-agent reinforcement learning (MARL) methods are limited in the scale of problems they can handle. Particularly, with the increase of the number of agents, their training costs grow exponentially. In this paper, we address this limitation by introducing a scalable MARL method called Distributed multi-Agent Reinforcement Learning with One-hop Neighbors (DARL1N). DARL1N is an off-policy actor-critic method that breaks the curse of dimensionality by decoupling the global interactions among agents and restricting information exchanges to one-hop neighbors. Each agent optimizes its action value and policy functions over a one-hop neighborhood, significantly reducing the learning complexity, yet maintaining expressiveness by training with varying numbers and states of neighbors. This structure allows us to formulate a distributed learning framework to further speed up the training procedure. Comparisons with state-of-the-art MARL methods show that DARL1N significantly reduces training time without sacrificing policy quality and is scalable as the number of agents increases.
Interference Aware Cooperative Routing for Edge Computing-enabled 5G Networks
Jan 05, 2022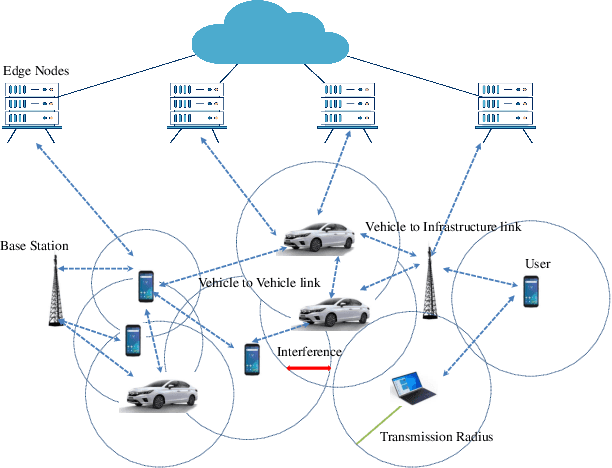
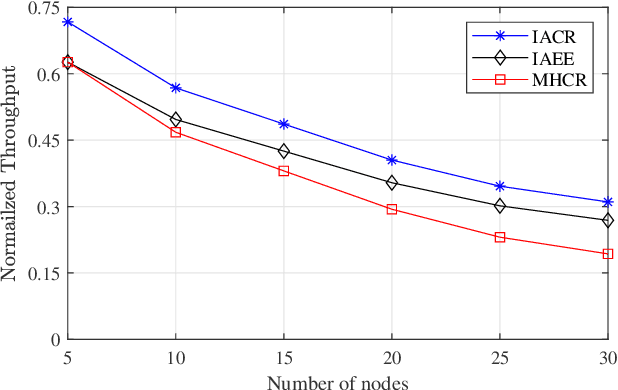
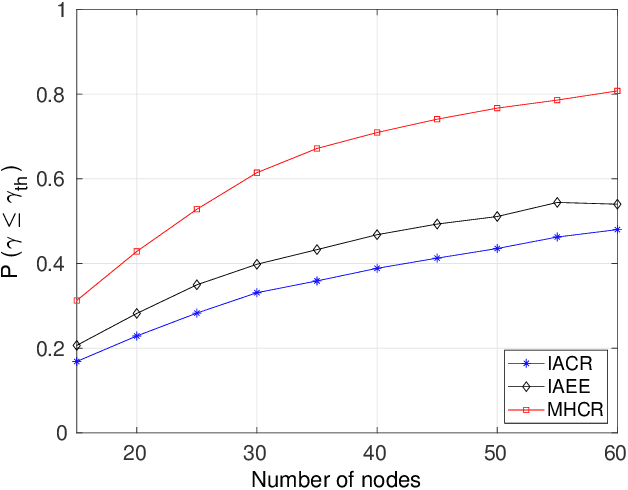
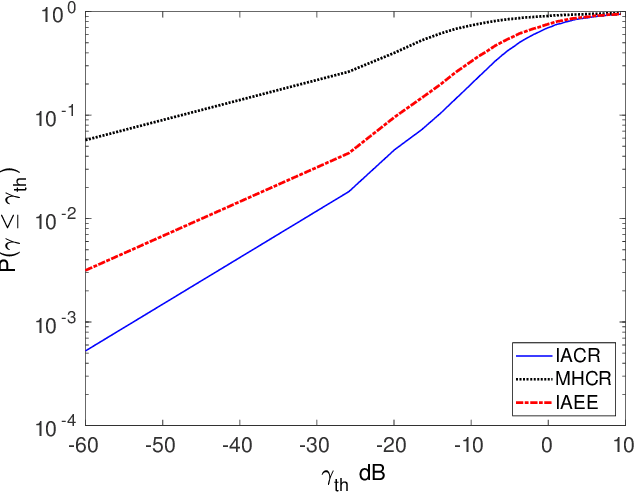
Recently, there has been growing research on developing interference-aware routing (IAR) protocols for supporting multiple concurrent transmission in next-generation wireless communication systems. The existing IAR protocols do not consider node cooperation while establishing the routes because motivating the nodes to cooperate and modeling that cooperation is not a trivial task. In addition, the information about the cooperative behavior of a node is not directly visible to neighboring nodes. Therefore, in this paper, we develop a new routing method in which the nodes' cooperation information is utilized to improve the performance of edge computing-enabled 5G networks. The proposed metric is a function of created and received interference in the network. The received interference term ensures that the Signal to Interference plus Noise Ratio (SINR) at the route remains above the threshold value, while the created interference term ensures that those nodes are selected to forward the packet that creates low interference for other nodes. The results show that the proposed solution improves ad hoc networks' performance compared to conventional routing protocols in terms of high network throughput and low outage probability.
Single-shot multispectral quantitative phase imaging using deep neural network
Jan 05, 2022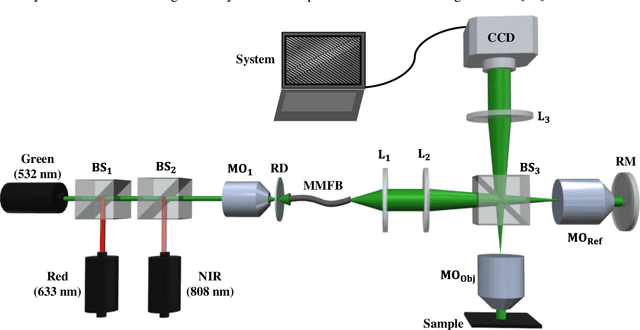
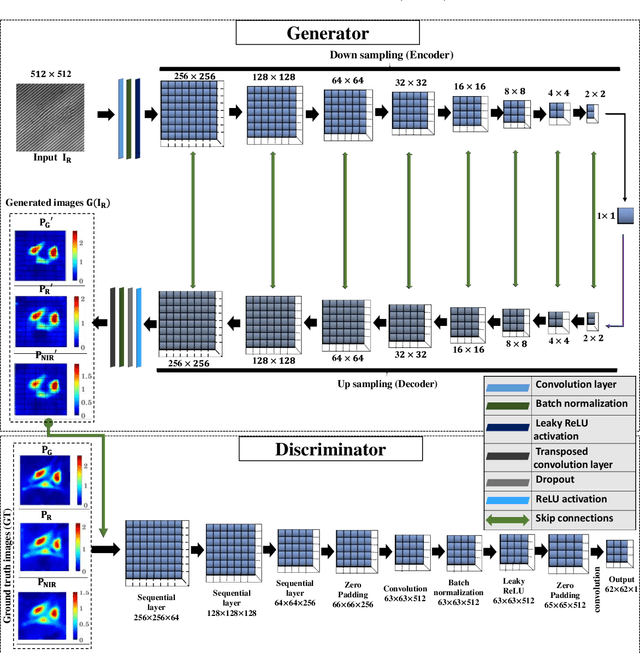
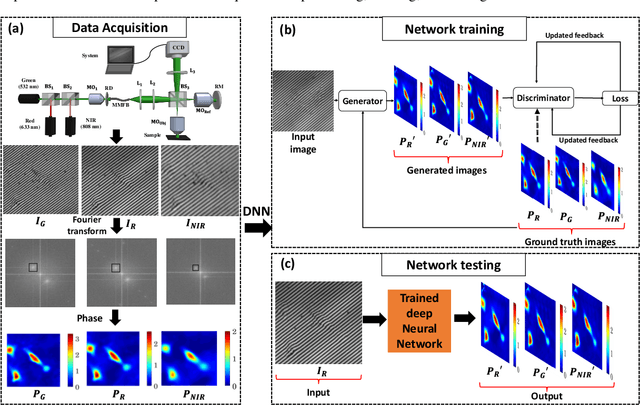
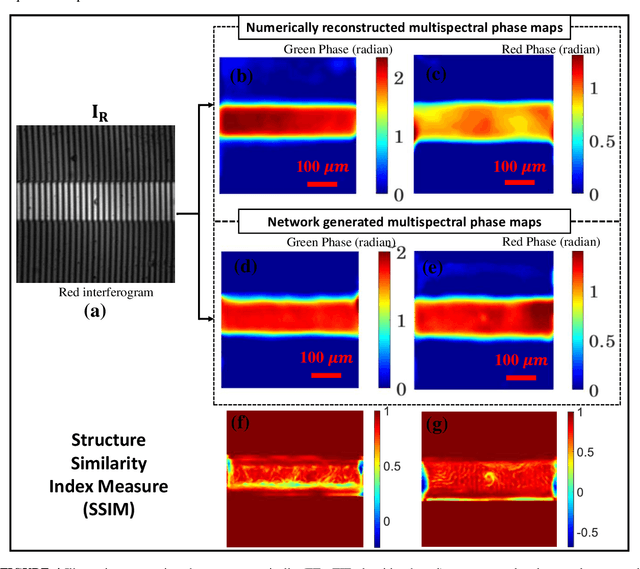
Multi-spectral quantitative phase imaging (MS-QPI) is a cutting-edge label-free technique to determine the morphological changes, refractive index variations and spectroscopic information of the specimens. The bottleneck to implement this technique to extract quantitative information, is the need of more than two measurements for generating MS-QPI images. We propose a single-shot MS-QPI technique using highly spatially sensitive digital holographic microscope assisted with deep neural network (DNN). Our method first acquires the interferometric datasets corresponding to multiple wavelengths ({\lambda}=532, 633 and 808 nm used here). The acquired datasets are used to train generative adversarial network (GAN) to generate multi-spectral quantitative phase maps from a single input interferogram. The network is trained and validated on two different samples, the optical waveguide and a MG63 osteosarcoma cells. Further, validation of the framework is performed by comparing the predicted phase maps with experimentally acquired and processed multi-spectral phase maps. The current MS-QPI+DNN framework can further empower spectroscopic QPI to improve the chemical specificity without complex instrumentation and color-cross talk.
Zero-delay Consistent and Smooth Trainable Interpolation
Mar 07, 2022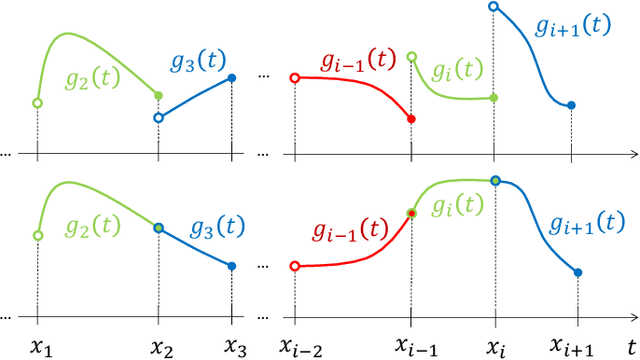
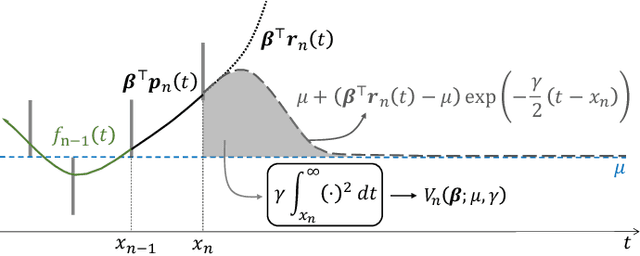
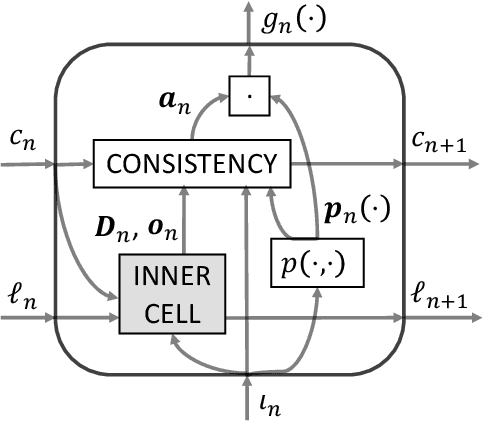
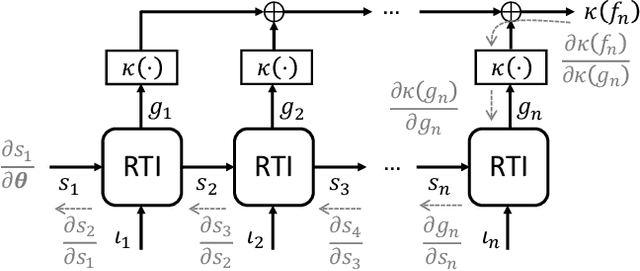
The question of how to produce a smooth interpolating curve from a stream of data points is addressed in this paper. To this end, we formalize the concept of real-time interpolator (RTI): a trainable unit that recovers smooth signals that are consistent with the received input samples in an online manner. Specifically, an RTI works under the requirement of producing a function section immediately after a sample is received (zero delay), without changing the reconstructed signal in past time sections. This work formulates the design of spline-based RTIs as a bi-level optimization problem. Their training consists in minimizing the average curvature of the interpolated signals over a set of example sequences. The latter are representative of the nature of the data sequence to be interpolated, allowing to tailor the RTI to a specific signal source. Our overall design allows for different possible schemes. In this work, we present two approaches, namely, the parametrized RTI and the recurrent neural network (RNN)-based RTI, including their architecture and properties. Experimental results show that the two proposed RTIs can be trained in a data-driven fashion to achieve improved performance (in terms of the curvature loss metric) with respect to a myopic-type RTI that only exploits the local information at each time sample, while maintaining smooth, zero-delay, and consistency requirements.
Inline Detection of DGA Domains Using Side Information
Mar 12, 2020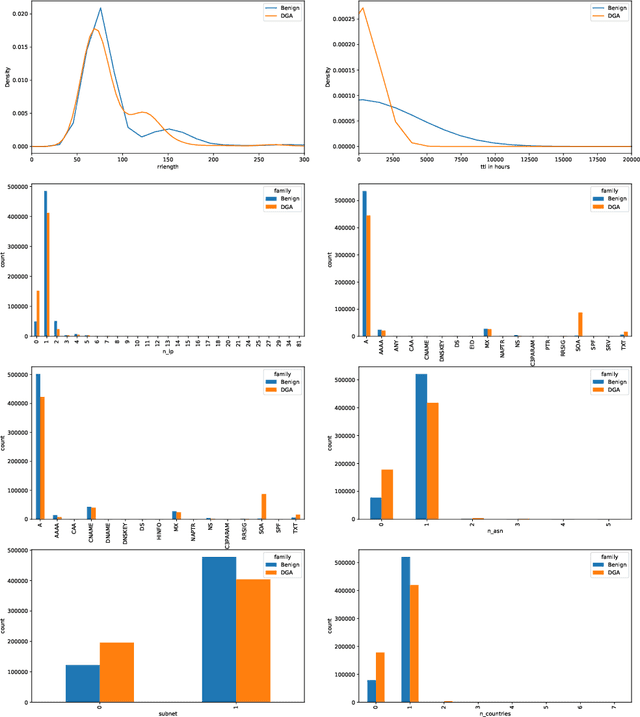

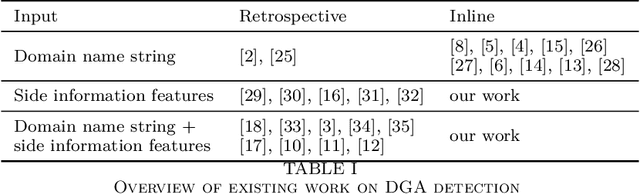

Malware applications typically use a command and control (C&C) server to manage bots to perform malicious activities. Domain Generation Algorithms (DGAs) are popular methods for generating pseudo-random domain names that can be used to establish a communication between an infected bot and the C&C server. In recent years, machine learning based systems have been widely used to detect DGAs. There are several well known state-of-the-art classifiers in the literature that can detect DGA domain names in real-time applications with high predictive performance. However, these DGA classifiers are highly vulnerable to adversarial attacks in which adversaries purposely craft domain names to evade DGA detection classifiers. In our work, we focus on hardening DGA classifiers against adversarial attacks. To this end, we train and evaluate state-of-the-art deep learning and random forest (RF) classifiers for DGA detection using side information that is harder for adversaries to manipulate than the domain name itself. Additionally, the side information features are selected such that they are easily obtainable in practice to perform inline DGA detection. The performance and robustness of these models is assessed by exposing them to one day of real-traffic data as well as domains generated by adversarial attack algorithms. We found that the DGA classifiers that rely on both the domain name and side information have high performance and are more robust against adversaries.
KINet: Keypoint Interaction Networks for Unsupervised Forward Modeling
Feb 18, 2022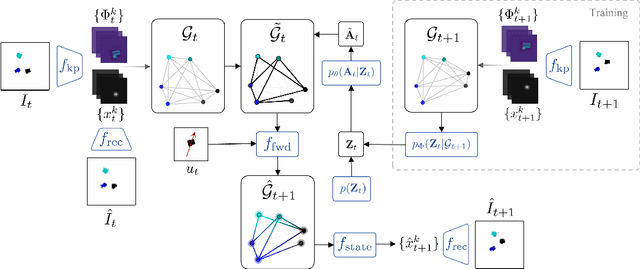
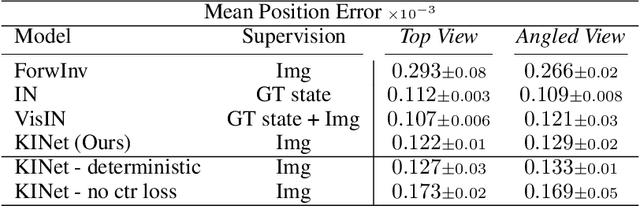
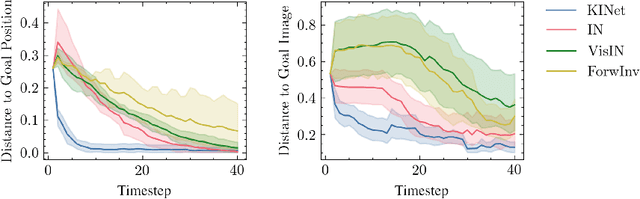
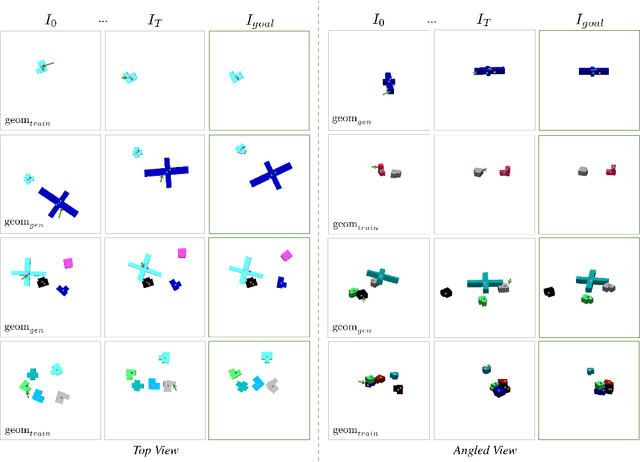
Object-centric representation is an essential abstraction for physical reasoning and forward prediction. Most existing approaches learn this representation through extensive supervision (e.g., object class and bounding box) although such ground-truth information is not readily accessible in reality. To address this, we introduce KINet (Keypoint Interaction Network) -- an end-to-end unsupervised framework to reason about object interactions in complex systems based on a keypoint representation. Using visual observations, our model learns to associate objects with keypoint coordinates and discovers a graph representation of the system as a set of keypoint embeddings and their relations. It then learns an action-conditioned forward model using contrastive estimation to predict future keypoint states. By learning to perform physical reasoning in the keypoint space, our model automatically generalizes to scenarios with a different number of objects, and novel object geometries. Experiments demonstrate the effectiveness of our model to accurately perform forward prediction and learn plannable object-centric representations which can also be used in downstream model-based control tasks.
The global information for land cover classification by dual-branch deep learning
May 30, 2020Land cover classification has played an important role in remote sensing because it can intelligently identify things in one huge remote sensing image so as to reduce the work of human. However, a lot of classification methods are designed based on the pixel feature or limited spatial feature of the remote sensing image, which limits the classification accuracy and universality of their methods. This paper proposed a novel method to take into the information of remote sensing image, i.e. geographic latitude-longitude information. In addition, a dual-channel convolutional neural network (CNN) classification method is designed to mine pixel feature of image in combination with the global information simultaneously. Firstly, 1-demensional network of CNN is designed to extract pixel information of remote sensing image, and the fully connected network (FCN) is employed to extract latitude-longitude feature. Then, their features of two neural networks are fused by another fully neural network to realize remote sensing image classification. Finally, two kinds of remote sensing, involving hyperspectral imaging (HSI) and polarimetric synthetic aperture radar (PolSAR), are used to verify the effectiveness of our method. The results of the proposed method is superior to the traditional single-channel convolutional neural network.
Group Contextualization for Video Recognition
Mar 18, 2022
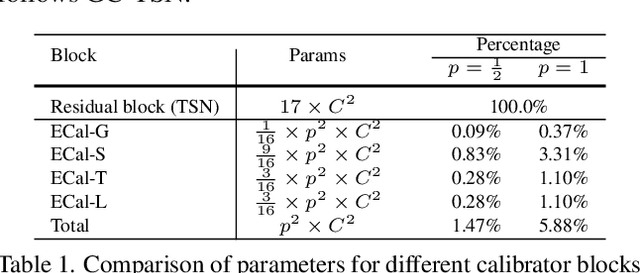
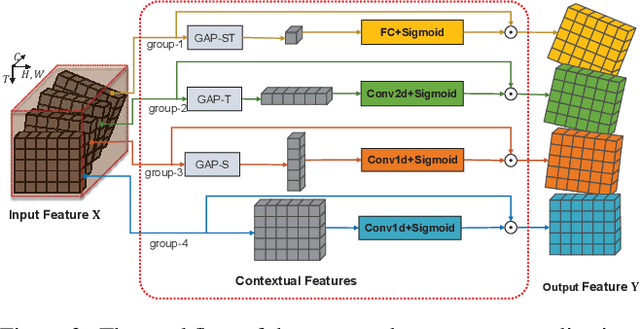
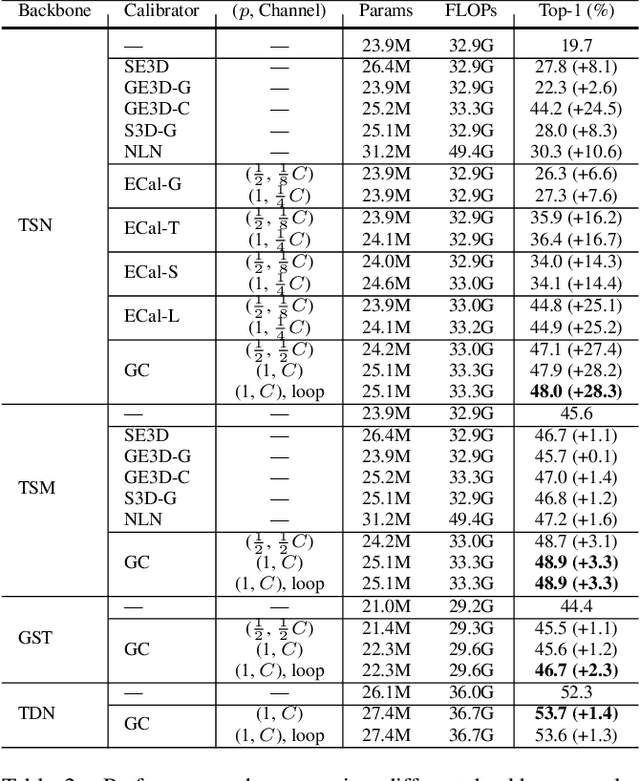
Learning discriminative representation from the complex spatio-temporal dynamic space is essential for video recognition. On top of those stylized spatio-temporal computational units, further refining the learnt feature with axial contexts is demonstrated to be promising in achieving this goal. However, previous works generally focus on utilizing a single kind of contexts to calibrate entire feature channels and could hardly apply to deal with diverse video activities. The problem can be tackled by using pair-wise spatio-temporal attentions to recompute feature response with cross-axis contexts at the expense of heavy computations. In this paper, we propose an efficient feature refinement method that decomposes the feature channels into several groups and separately refines them with different axial contexts in parallel. We refer this lightweight feature calibration as group contextualization (GC). Specifically, we design a family of efficient element-wise calibrators, i.e., ECal-G/S/T/L, where their axial contexts are information dynamics aggregated from other axes either globally or locally, to contextualize feature channel groups. The GC module can be densely plugged into each residual layer of the off-the-shelf video networks. With little computational overhead, consistent improvement is observed when plugging in GC on different networks. By utilizing calibrators to embed feature with four different kinds of contexts in parallel, the learnt representation is expected to be more resilient to diverse types of activities. On videos with rich temporal variations, empirically GC can boost the performance of 2D-CNN (e.g., TSN and TSM) to a level comparable to the state-of-the-art video networks. Code is available at https://github.com/haoyanbin918/Group-Contextualization.