 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fusion of Probability Density Functions
Feb 23, 2022
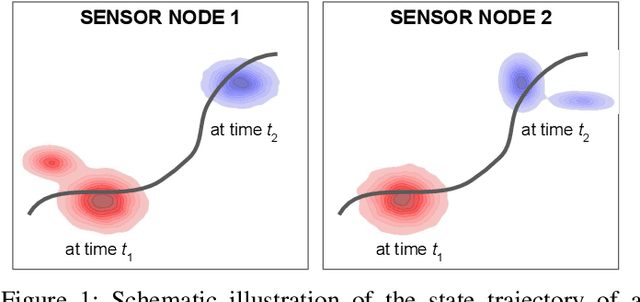
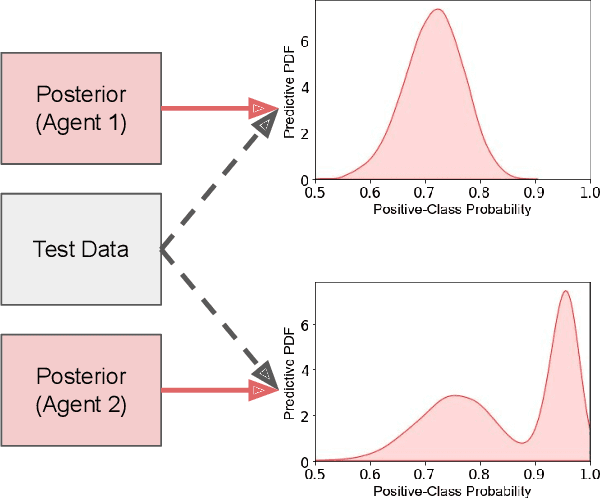
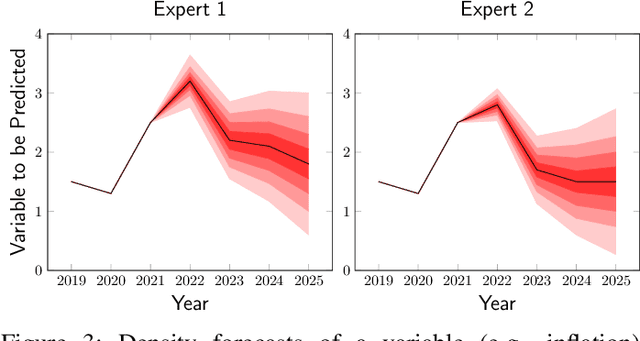
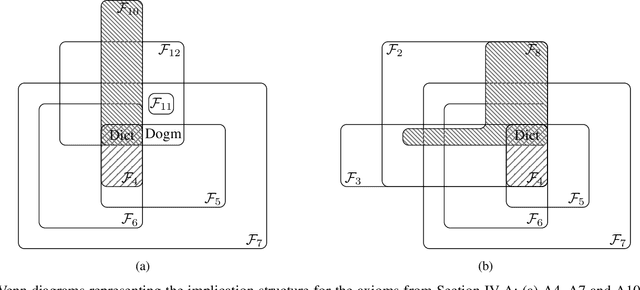
Fusing probabilistic information is a fundamental task in signal and data processing with relevance to many fields of technology and science. In this work, we investigate the fusion of multiple probability density functions (pdfs) of a continuous random variable or vector. Although the case of continuous random variables and the problem of pdf fusion frequently arise in multisensor signal processing, statistical inference, and machine learning, a universally accepted method for pdf fusion does not exist. The diversity of approaches, perspectives, and solutions related to pdf fusion motivates a unified presentation of the theory and methodology of the field. We discuss three different approaches to fusing pdfs. In the axiomatic approach, the fusion rule is defined indirectly by a set of properties (axioms). In the optimization approach, it is the result of minimizing an objective function that involves an information-theoretic divergence or a distance measure. In the supra-Bayesian approach, the fusion center interprets the pdfs to be fused as random observations. Our work is partly a survey, reviewing in a structured and coherent fashion many of the concepts and methods that have been developed in the literature. In addition, we present new results for each of the three approaches. Our original contributions include new fusion rules, axioms, and axiomatic and optimization-based characterizations; a new formulation of supra-Bayesian fusion in terms of finite-dimensional parametrizations; and a study of supra-Bayesian fusion of posterior pdfs for linear Gaussian models.
Use of 'off-the-shelf' information extraction algorithms in clinical informatics: a feasibility study of MetaMap annotation of Italian medical notes
Apr 02, 2021
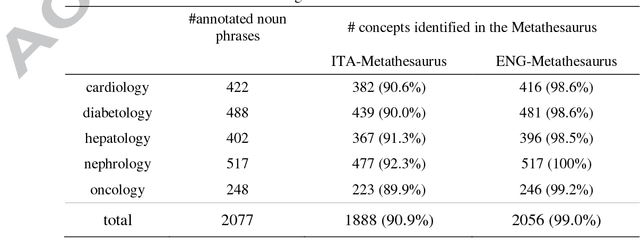

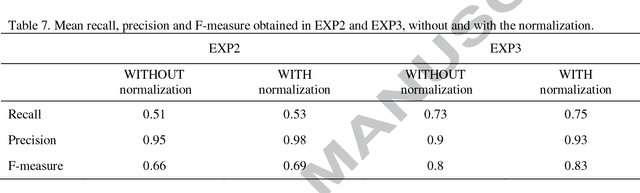
Information extraction from narrative clinical notes is useful for patient care, as well as for secondary use of medical data, for research or clinical purposes. Many studies focused on information extraction from English clinical texts, but less dealt with clinical notes in languages other than English. This study tested the feasibility of using 'off the shelf' information extraction algorithms to identify medical concepts from Italian clinical notes. We used MetaMap to map medical concepts to the Unified Medical Language System (UMLS). The study addressed two questions: (Q1) to understand if it would be possible to properly map medical terms found in clinical notes and related to the semantic group of 'Disorders' to the Italian UMLS resources; (Q2) to investigate if it would be feasible to use MetaMap as it is to extract these medical concepts from Italian clinical notes. Results in EXP1 showed that the Italian UMLS Metathesaurus sources covered 91% of the medical terms of the 'Disorders' semantic group, as found in the studied dataset. Even if MetaMap was built to analyze texts written in English, it worked properly also with texts written in Italian. MetaMap identified correctly about half of the concepts in the Italian clinical notes. Using MetaMap's annotation on Italian clinical notes instead of a simple text search improved our results of about 15 percentage points. MetaMap showed recall, precision and F-measure of 0.53, 0.98 and 0.69, respectively. Most of the failures were due to the impossibility for MetaMap to generate Italian meaningful variants. MetaMap's performance in annotating automatically translated English clinical notes was in line with findings in the literature, with similar recall (0.75), F-measure (0.83) and even higher precision (0.95).
* This paper has been published in the Journal of biomedical informatics, Volume 63, October 2016, Pages 22-32
NeuraGen-A Low-Resource Neural Network based approach for Gender Classification
Mar 29, 2022
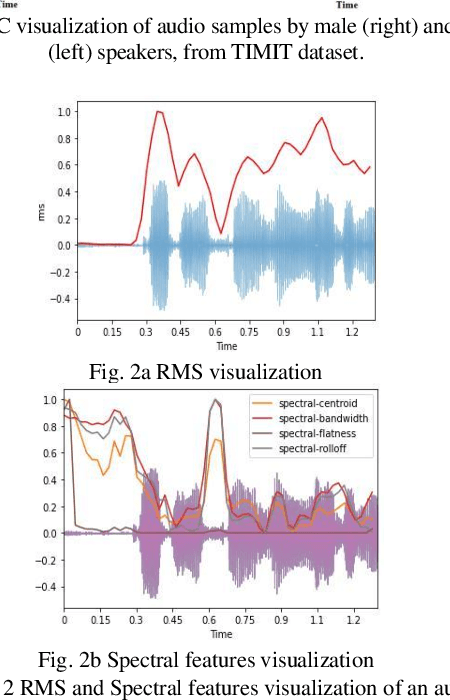
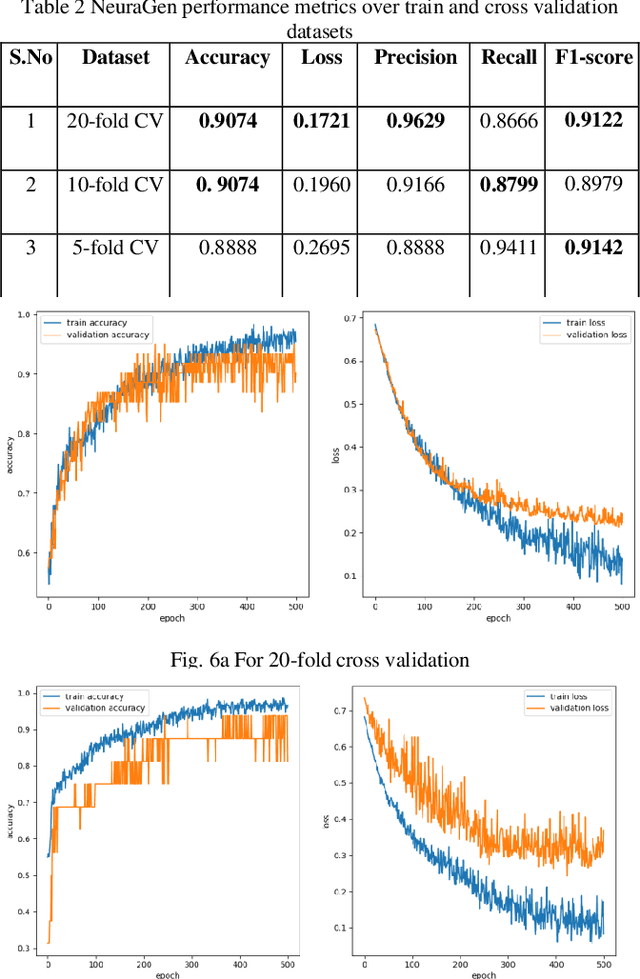
Human voice is the source of several important information. This is in the form of features. These Features help in interpreting various features associated with the speaker and speech. The speaker dependent work researchersare targeted towards speaker identification, Speaker verification, speaker biometric, forensics using feature, and cross-modal matching via speech and face images. In such context research, it is a very difficult task to come across clean, and well annotated publicly available speech corpus as data set. Acquiring volunteers to generate such dataset is also very expensive, not to mention the enormous amount of effort and time researchers spend to gather such data. The present paper work, a Neural Network proposal as NeuraGen focused which is a low-resource ANN architecture. The proposed tool used to classify gender of the speaker from the speech recordings. We have used speech recordings collected from the ELSDSR and limited TIMIT datasets, from which we extracted 8 speech features, which were pre-processed and then fed into NeuraGen to identify the gender. NeuraGen has successfully achieved accuracy of 90.7407% and F1 score of 91.227% in train and 20-fold cross validation dataset.
Pop-Out Motion: 3D-Aware Image Deformation via Learning the Shape Laplacian
Mar 29, 2022We propose a framework that can deform an object in a 2D image as it exists in 3D space. Most existing methods for 3D-aware image manipulation are limited to (1) only changing the global scene information or depth, or (2) manipulating an object of specific categories. In this paper, we present a 3D-aware image deformation method with minimal restrictions on shape category and deformation type. While our framework leverages 2D-to-3D reconstruction, we argue that reconstruction is not sufficient for realistic deformations due to the vulnerability to topological errors. Thus, we propose to take a supervised learning-based approach to predict the shape Laplacian of the underlying volume of a 3D reconstruction represented as a point cloud. Given the deformation energy calculated using the predicted shape Laplacian and user-defined deformation handles (e.g., keypoints), we obtain bounded biharmonic weights to model plausible handle-based image deformation. In the experiments, we present our results of deforming 2D character and clothed human images. We also quantitatively show that our approach can produce more accurate deformation weights compared to alternative methods (i.e., mesh reconstruction and point cloud Laplacian methods).
CYBORGS: Contrastively Bootstrapping Object Representations by Grounding in Segmentation
Mar 17, 2022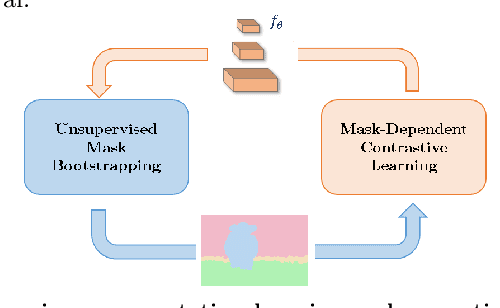
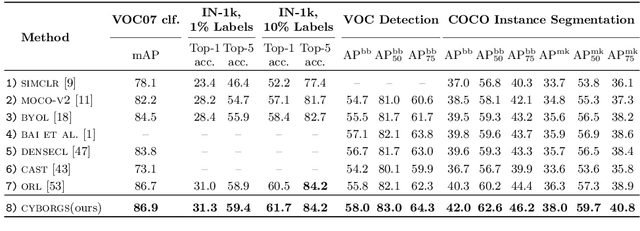
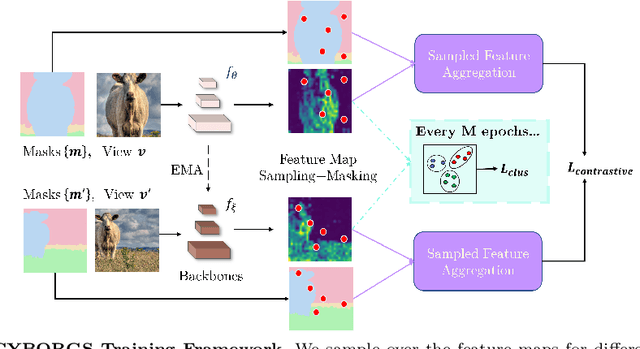

Many recent approaches in contrastive learning have worked to close the gap between pretraining on iconic images like ImageNet and pretraining on complex scenes like COCO. This gap exists largely because commonly used random crop augmentations obtain semantically inconsistent content in crowded scene images of diverse objects. Previous works use preprocessing pipelines to localize salient objects for improved cropping, but an end-to-end solution is still elusive. In this work, we propose a framework which accomplishes this goal via joint learning of representations and segmentation. We leverage segmentation masks to train a model with a mask-dependent contrastive loss, and use the partially trained model to bootstrap better masks. By iterating between these two components, we ground the contrastive updates in segmentation information, and simultaneously improve segmentation throughout pretraining. Experiments show our representations transfer robustly to downstream tasks in classification, detection and segmentation.
Multidimensional Orthogonal Matching Pursuit-based RIS-aided Joint Localization and Channel Estimation at mmWave
Mar 24, 2022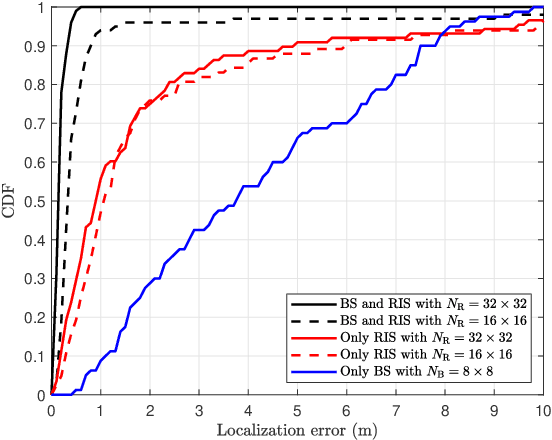
RIS-aided millimeter wave wireless systems benefit from robustness to blockage and enhanced coverage. In this paper, we study the ability of RIS to also provide enhanced localization capabilities as a by-product of communication. We consider sparse reconstruction algorithms to obtain high resolution channel estimates that are mapped to position information. In RIS-aided mmWave systems, the complexity of sparse recovery becomes a bottleneck, given the large number of elements of the RIS and the large communication arrays. We propose to exploit a multidimensional orthogonal matching pursuit strategy for compressive channel estimation in a RIS-aided millimeter wave system. We show how this algorithm, based on computing the projections on a set of independent dictionaries instead of a single large dictionary, enables high accuracy channel estimation at reduced complexity. We also combine this strategy with a localization approach which does not rely on the absolute time of arrival of the LoS path. Localization results in a realistic 3D indoor scenario show that RIS-aided wireless system can also benefit from a significant improvement in localization accuracy.
The Curse of Dense Low-Dimensional Information Retrieval for Large Index Sizes
Dec 28, 2020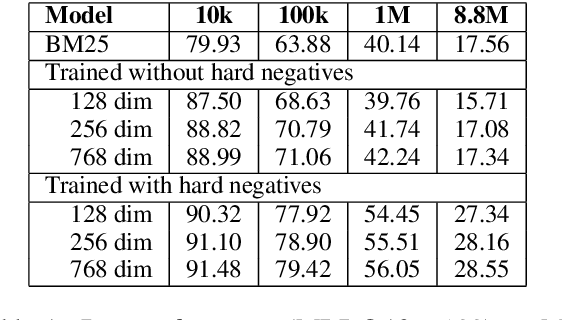
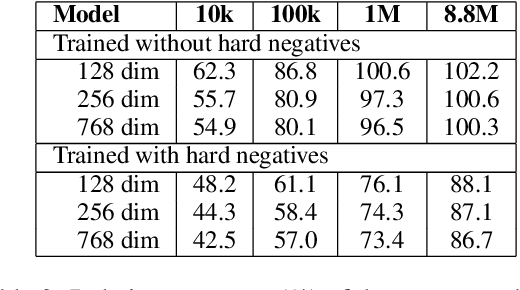
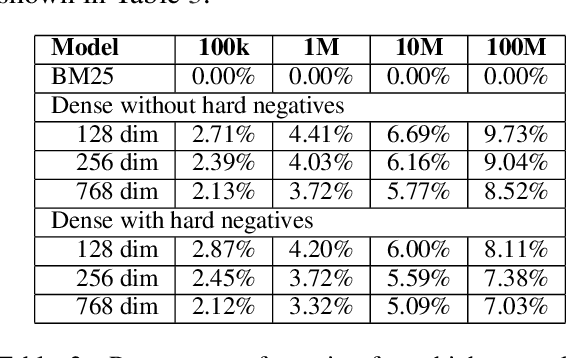
Information Retrieval using dense low-dimensional representations recently became popular and showed out-performance to traditional sparse-representations like BM25. However, no previous work investigated how dense representations perform with large index sizes. We show theoretically and empirically that the performance for dense representations decreases quicker than sparse representations for increasing index sizes. In extreme cases, this can even lead to a tipping point where at a certain index size sparse representations outperform dense representations. We show that this behavior is tightly connected to the number of dimensions of the representations: The lower the dimension, the higher the chance for false positives, i.e. returning irrelevant documents.
Homography Loss for Monocular 3D Object Detection
Apr 02, 2022
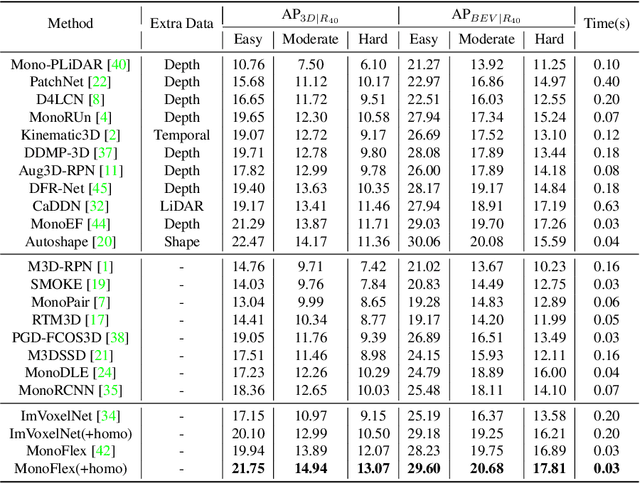
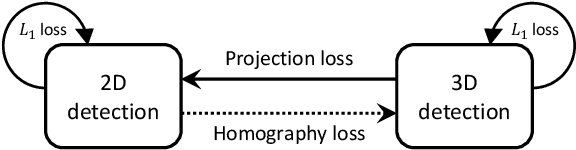
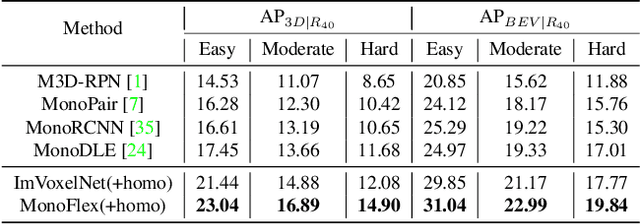
Monocular 3D object detection is an essential task in autonomous driving. However, most current methods consider each 3D object in the scene as an independent training sample, while ignoring their inherent geometric relations, thus inevitably resulting in a lack of leveraging spatial constraints. In this paper, we propose a novel method that takes all the objects into consideration and explores their mutual relationships to help better estimate the 3D boxes. Moreover, since 2D detection is more reliable currently, we also investigate how to use the detected 2D boxes as guidance to globally constrain the optimization of the corresponding predicted 3D boxes. To this end, a differentiable loss function, termed as Homography Loss, is proposed to achieve the goal, which exploits both 2D and 3D information, aiming at balancing the positional relationships between different objects by global constraints, so as to obtain more accurately predicted 3D boxes. Thanks to the concise design, our loss function is universal and can be plugged into any mature monocular 3D detector, while significantly boosting the performance over their baseline. Experiments demonstrate that our method yields the best performance (Nov. 2021) compared with the other state-of-the-arts by a large margin on KITTI 3D datasets.
Movies2Scenes: Learning Scene Representations Using Movie Similarities
Mar 12, 2022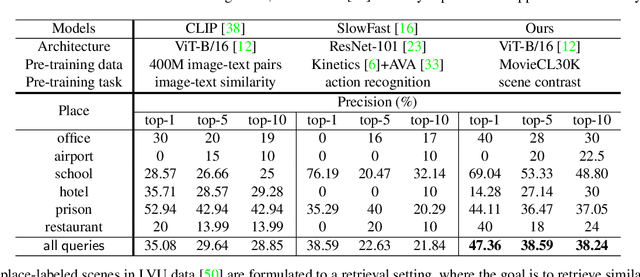
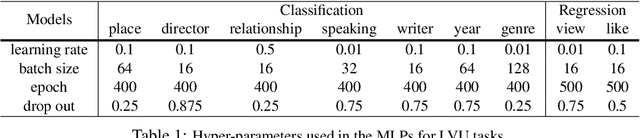
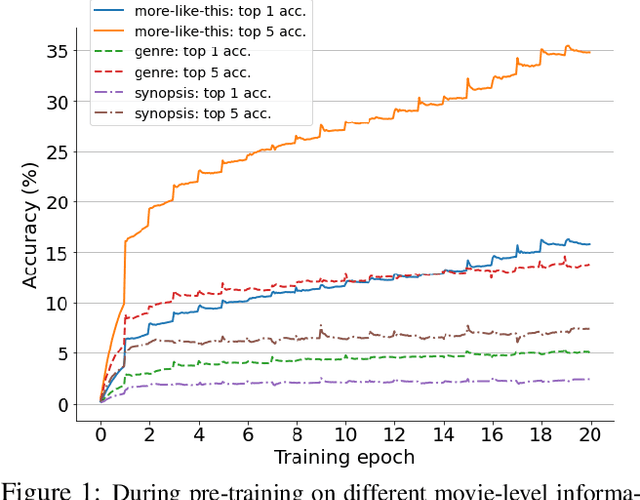
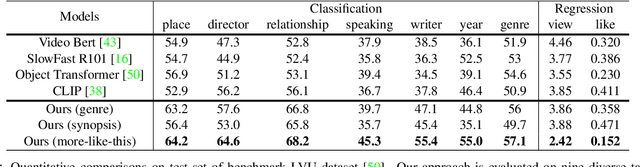
Labeling movie-scenes is a time-consuming process which makes applying end-to-end supervised methods for scene-understanding a challenging problem. Moreover, directly using image-based visual representations for scene-understanding tasks does not prove to be effective given the large gap between the two domains. To address these challenges, we propose a novel contrastive learning approach that uses commonly available movie-level information (e.g., co-watch, genre, synopsis) to learn a general-purpose scene-level representation. Our learned representation comfortably outperforms existing state-of-the-art approaches on eleven downstream tasks evaluated using multiple benchmark datasets. To further demonstrate generalizability of our learned representation, we present its comparative results on a set of video-moderation tasks evaluated using a newly collected large-scale internal movie dataset.
Robust Contrastive Learning against Noisy Views
Jan 12, 2022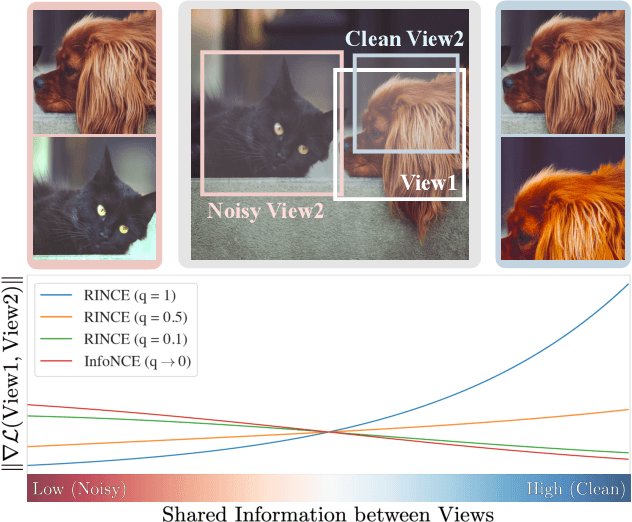
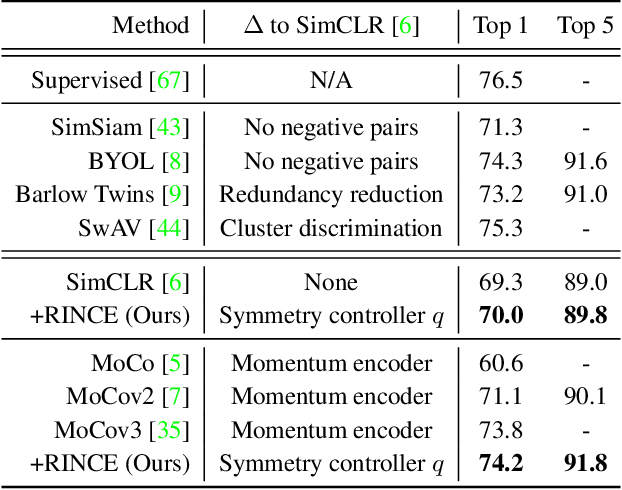

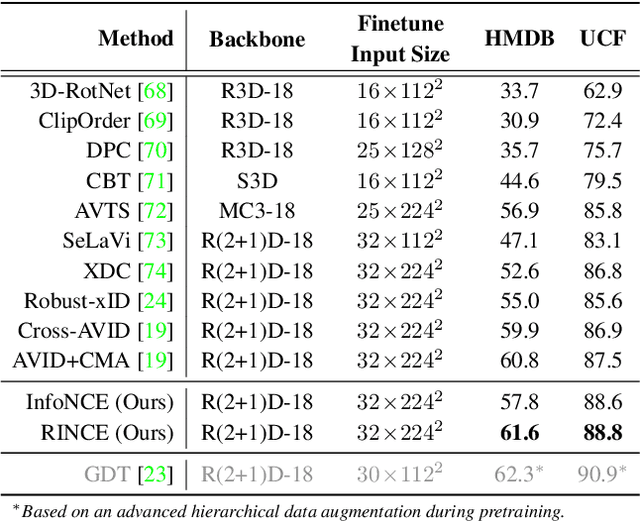
Contrastive learning relies on an assumption that positive pairs contain related views, e.g., patches of an image or co-occurring multimodal signals of a video, that share certain underlying information about an instance. But what if this assumption is violated? The literature suggests that contrastive learning produces suboptimal representations in the presence of noisy views, e.g., false positive pairs with no apparent shared information. In this work, we propose a new contrastive loss function that is robust against noisy views. We provide rigorous theoretical justifications by showing connections to robust symmetric losses for noisy binary classification and by establishing a new contrastive bound for mutual information maximization based on the Wasserstein distance measure. The proposed loss is completely modality-agnostic and a simple drop-in replacement for the InfoNCE loss, which makes it easy to apply to existing contrastive frameworks. We show that our approach provides consistent improvements over the state-of-the-art on image, video, and graph contrastive learning benchmarks that exhibit a variety of real-world noise patterns.