 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Transparency strategy-based data augmentation for BI-RADS classification of mammograms
Mar 20, 2022
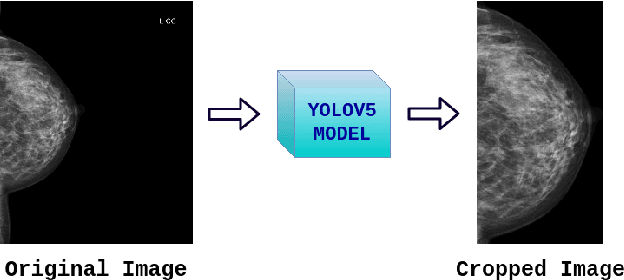

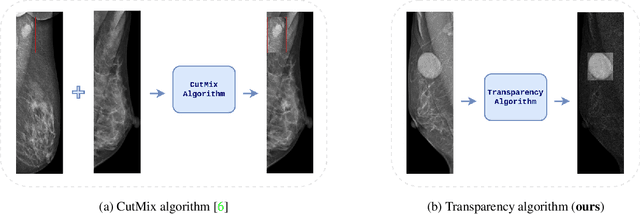
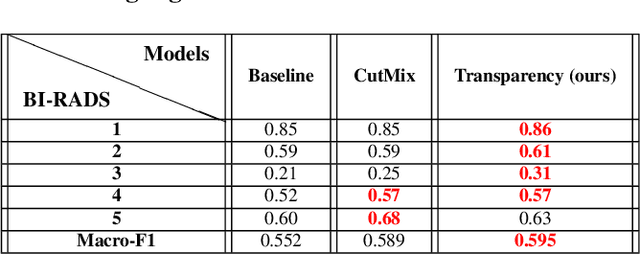
Image augmentation techniques have been widely investigated to improve the performance of deep learning (DL) algorithms on mammography classification tasks. Recent methods have proved the efficiency of image augmentation on data deficiency or data imbalance issues. In this paper, we propose a novel transparency strategy to boost the Breast Imaging Reporting and Data System (BI-RADS) scores of mammograms classifier. The proposed approach utilizes the Region of Interest (ROI) information to generate more high-risk training examples from original images. Our extensive experiments were conducted on our benchmark mammography dataset. The experiment results show that the proposed approach surpasses current state-of-the-art data augmentation techniques such as Upsampling or CutMix. The study highlights that the transparency method is more effective than other augmentation strategies for BI-RADS classification and can be widely applied for our computer vision tasks.
CycDA: Unsupervised Cycle Domain Adaptation from Image to Video
Mar 30, 2022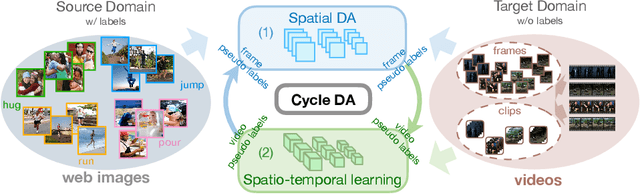
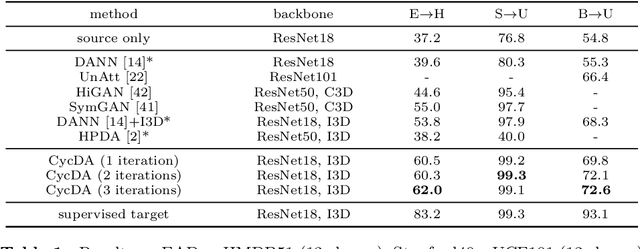
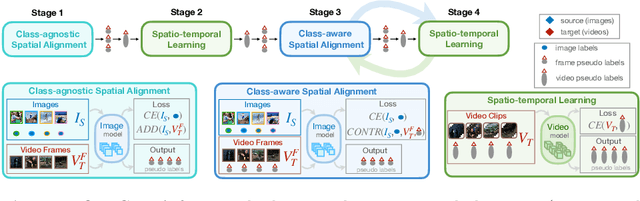
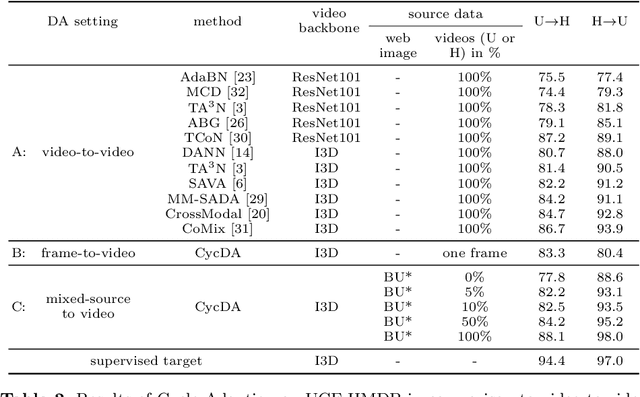
Although action recognition has achieved impressive results over recent years, both collection and annotation of video training data are still time-consuming and cost intensive. Therefore, image-to-video adaptation has been proposed to exploit labeling-free web image source for adapting on unlabeled target videos. This poses two major challenges: (1) spatial domain shift between web images and video frames; (2) modality gap between image and video data. To address these challenges, we propose Cycle Domain Adaptation (CycDA), a cycle-based approach for unsupervised image-to-video domain adaptation by leveraging the joint spatial information in images and videos on the one hand and, on the other hand, training an independent spatio-temporal model to bridge the modality gap. We alternate between the spatial and spatio-temporal learning with knowledge transfer between the two in each cycle. We evaluate our approach on benchmark datasets for image-to-video as well as for mixed-source domain adaptation achieving state-of-the-art results and demonstrating the benefits of our cyclic adaptation.
Federated Learning for Energy-limited Wireless Networks: A Partial Model Aggregation Approach
Apr 20, 2022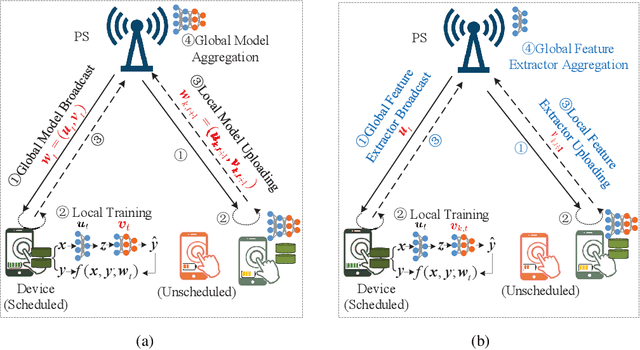
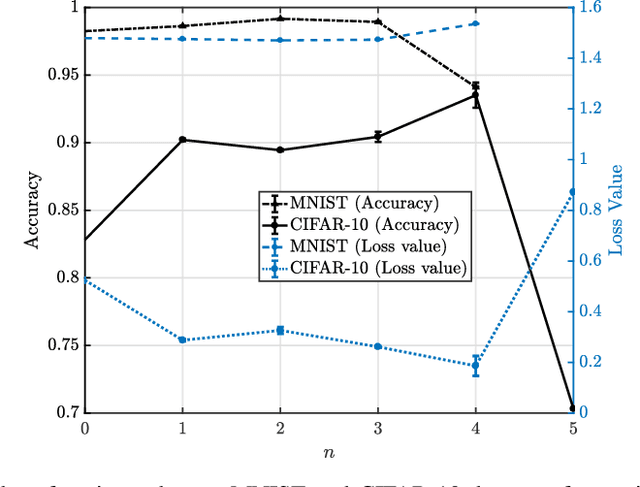
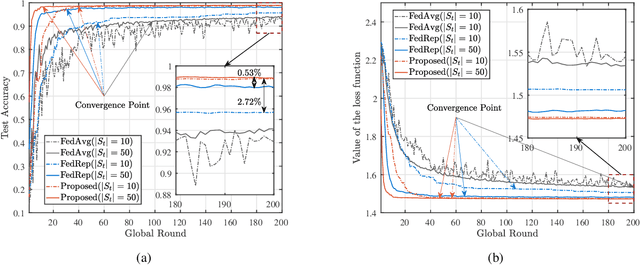
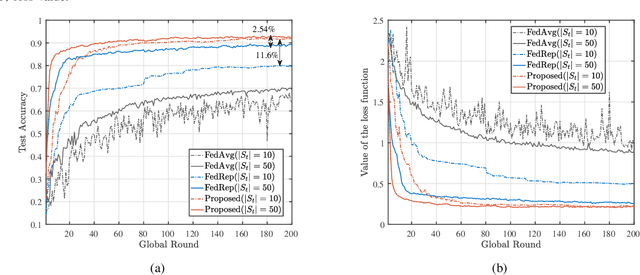
The limited communication resources, e.g., bandwidth and energy, and data heterogeneity across devices are two of the main bottlenecks for federated learning (FL). To tackle these challenges, we first devise a novel FL framework with partial model aggregation (PMA), which only aggregates the lower layers of neural networks responsible for feature extraction while the upper layers corresponding to complex pattern recognition remain at devices for personalization. The proposed PMA-FL is able to address the data heterogeneity and reduce the transmitted information in wireless channels. We then obtain a convergence bound of the framework under a non-convex loss function setting. With the aid of this bound, we define a new objective function, named the scheduled data sample volume, to transfer the original inexplicit optimization problem into a tractable one for device scheduling, bandwidth allocation, computation and communication time division. Our analysis reveals that the optimal time division is achieved when the communication and computation parts of PMA-FL have the same power. We also develop a bisection method to solve the optimal bandwidth allocation policy and use the set expansion algorithm to address the optimal device scheduling. Compared with the state-of-the-art benchmarks, the proposed PMA-FL improves 2.72% and 11.6% accuracy on two typical heterogeneous datasets, i.e., MINIST and CIFAR-10, respectively. In addition, the proposed joint dynamic device scheduling and resource optimization approach achieve slightly higher accuracy than the considered benchmarks, but they provide a satisfactory energy and time reduction: 29% energy or 20% time reduction on the MNIST; and 25% energy or 12.5% time reduction on the CIFAR-10.
Bregman Deviations of Generic Exponential Families
Jan 18, 2022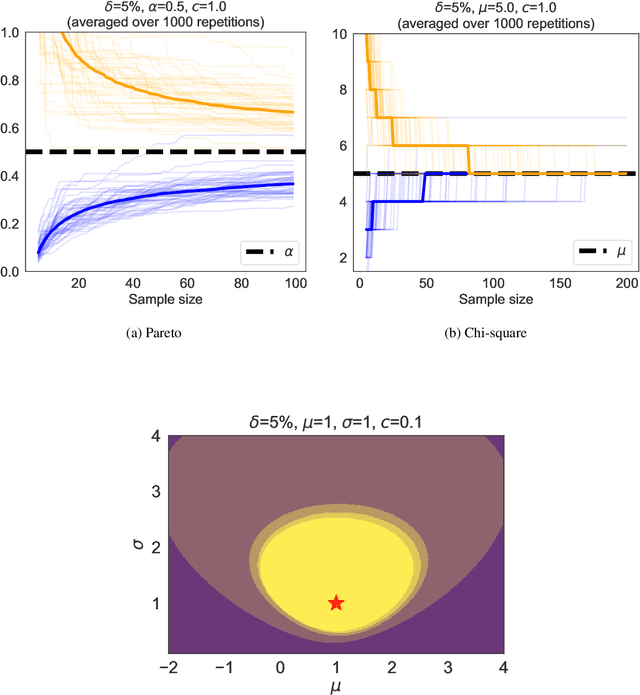
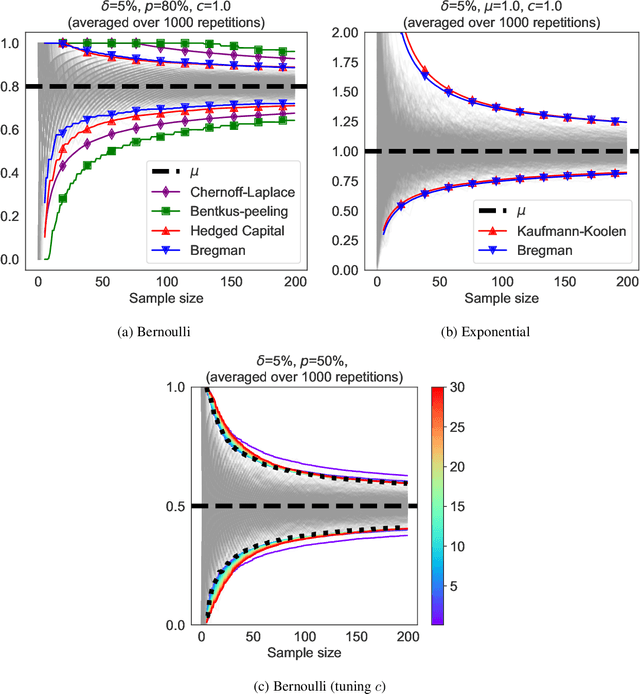
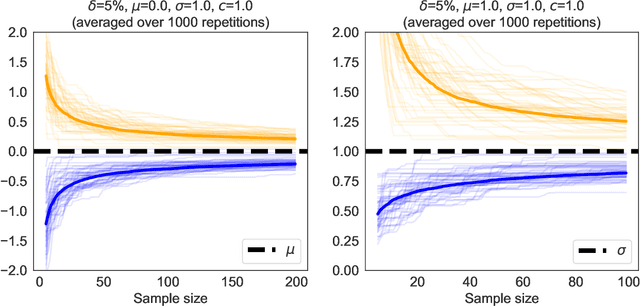
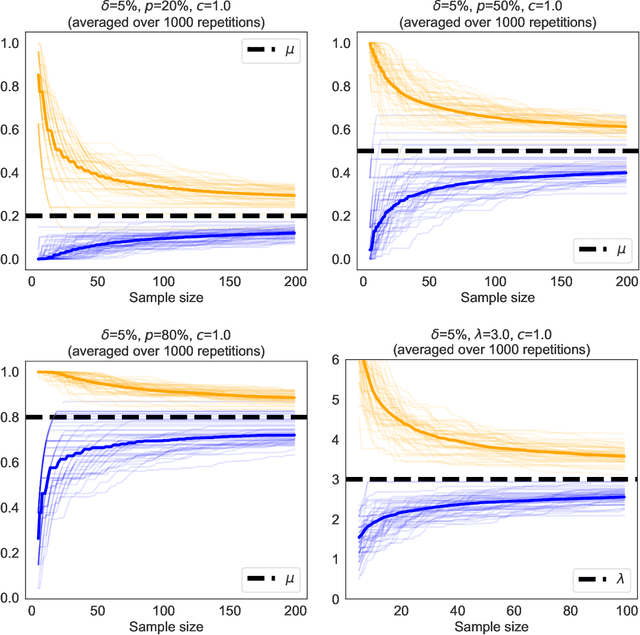
We revisit the method of mixture technique, also known as the Laplace method, to study the concentration phenomenon in generic exponential families. Combining the properties of Bregman divergence associated with log-partition function of the family with the method of mixtures for super-martingales, we establish a generic bound controlling the Bregman divergence between the parameter of the family and a finite sample estimate of the parameter. Our bound is time-uniform and makes appear a quantity extending the classical \textit{information gain} to exponential families, which we call the \textit{Bregman information gain}. For the practitioner, we instantiate this novel bound to several classical families, e.g., Gaussian, Bernoulli, Exponential and Chi-square yielding explicit forms of the confidence sets and the Bregman information gain. We further numerically compare the resulting confidence bounds to state-of-the-art alternatives for time-uniform concentration and show that this novel method yields competitive results. Finally, we highlight how our results can be applied in a linear contextual multi-armed bandit problem.
FD-SLAM: 3-D Reconstruction Using Features and Dense Matching
Mar 25, 2022



It is well known that visual SLAM systems based on dense matching are locally accurate but are also susceptible to long-term drift and map corruption. In contrast, feature matching methods can achieve greater long-term consistency but can suffer from inaccurate local pose estimation when feature information is sparse. Based on these observations, we propose an RGB-D SLAM system that leverages the advantages of both approaches: using dense frame-to-model odometry to build accurate sub-maps and on-the-fly feature-based matching across sub-maps for global map optimisation. In addition, we incorporate a learning-based loop closure component based on 3-D features which further stabilises map building. We have evaluated the approach on indoor sequences from public datasets, and the results show that it performs on par or better than state-of-the-art systems in terms of map reconstruction quality and pose estimation. The approach can also scale to large scenes where other systems often fail.
A Self-Supervised Descriptor for Image Copy Detection
Mar 25, 2022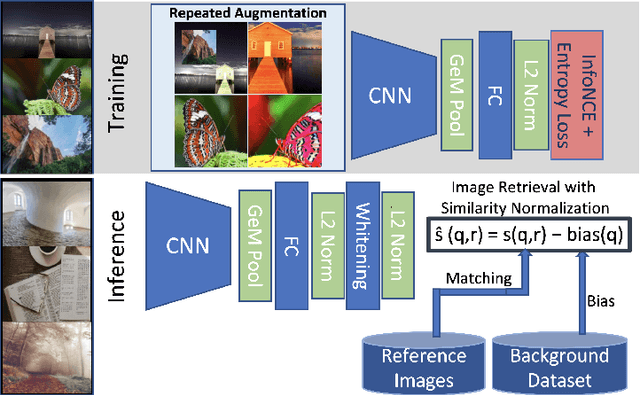


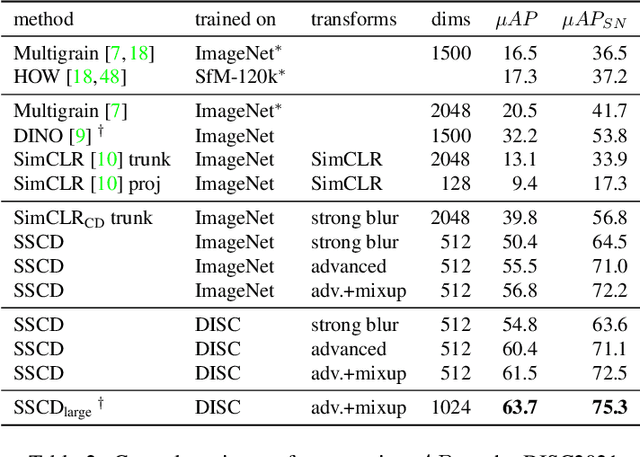
Image copy detection is an important task for content moderation. We introduce SSCD, a model that builds on a recent self-supervised contrastive training objective. We adapt this method to the copy detection task by changing the architecture and training objective, including a pooling operator from the instance matching literature, and adapting contrastive learning to augmentations that combine images. Our approach relies on an entropy regularization term, promoting consistent separation between descriptor vectors, and we demonstrate that this significantly improves copy detection accuracy. Our method produces a compact descriptor vector, suitable for real-world web scale applications. Statistical information from a background image distribution can be incorporated into the descriptor. On the recent DISC2021 benchmark, SSCD is shown to outperform both baseline copy detection models and self-supervised architectures designed for image classification by huge margins, in all settings. For example, SSCD out-performs SimCLR descriptors by 48% absolute. Code is available at https://github.com/facebookresearch/sscd-copy-detection.
Analyzing Generalization of Vision and Language Navigation to Unseen Outdoor Areas
Mar 25, 2022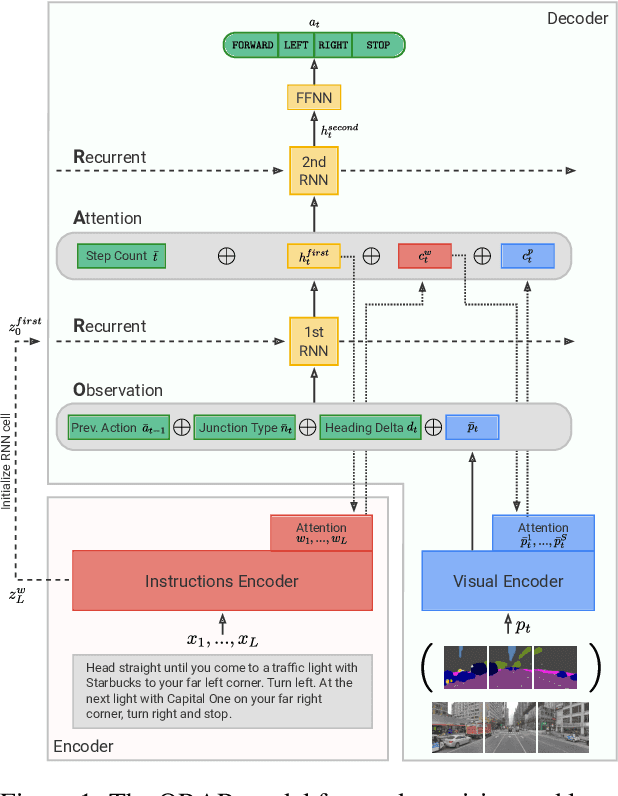
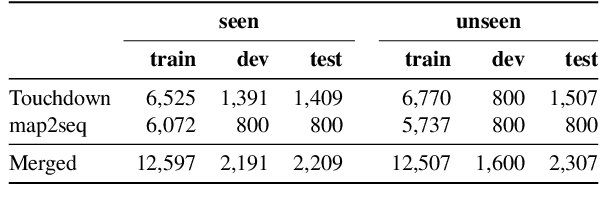
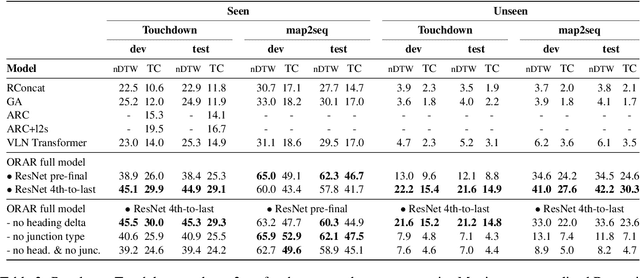
Vision and language navigation (VLN) is a challenging visually-grounded language understanding task. Given a natural language navigation instruction, a visual agent interacts with a graph-based environment equipped with panorama images and tries to follow the described route. Most prior work has been conducted in indoor scenarios where best results were obtained for navigation on routes that are similar to the training routes, with sharp drops in performance when testing on unseen environments. We focus on VLN in outdoor scenarios and find that in contrast to indoor VLN, most of the gain in outdoor VLN on unseen data is due to features like junction type embedding or heading delta that are specific to the respective environment graph, while image information plays a very minor role in generalizing VLN to unseen outdoor areas. These findings show a bias to specifics of graph representations of urban environments, demanding that VLN tasks grow in scale and diversity of geographical environments.
Weakly Supervised Learning with Side Information for Noisy Labeled Images
Sep 04, 2020
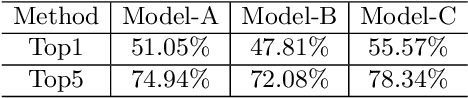
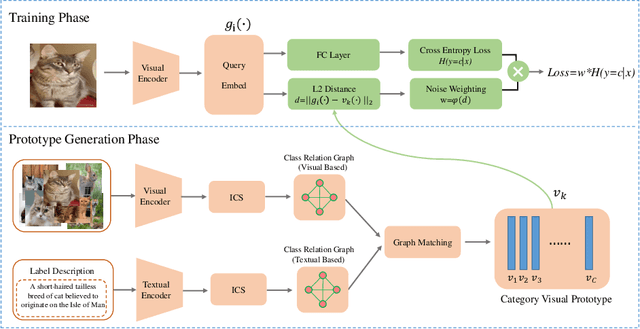

In many real-world datasets, like WebVision, the performance of DNN based classifier is often limited by the noisy labeled data. To tackle this problem, some image related side information, such as captions and tags, often reveal underlying relationships across images. In this paper, we present an efficient weakly supervised learning by using a Side Information Network (SINet), which aims to effectively carry out a large scale classification with severely noisy labels. The proposed SINet consists of a visual prototype module and a noise weighting module. The visual prototype module is designed to generate a compact representation for each category by introducing the side information. The noise weighting module aims to estimate the correctness of each noisy image and produce a confidence score for image ranking during the training procedure. The propsed SINet can largely alleviate the negative impact of noisy image labels, and is beneficial to train a high performance CNN based classifier. Besides, we released a fine-grained product dataset called AliProducts, which contains more than 2.5 million noisy web images crawled from the internet by using queries generated from 50,000 fine-grained semantic classes. Extensive experiments on several popular benchmarks (i.e. Webvision, ImageNet and Clothing-1M) and our proposed AliProducts achieve state-of-the-art performance. The SINet has won the first place in the classification task on WebVision Challenge 2019, and outperformed other competitors by a large margin.
Physics-Driven Deep Learning for Computational Magnetic Resonance Imaging
Mar 23, 2022
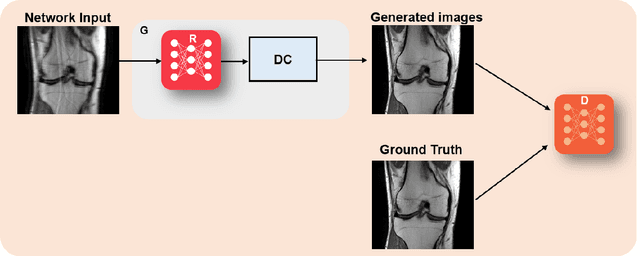
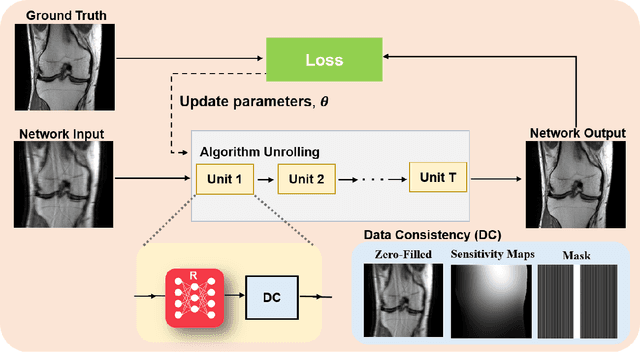
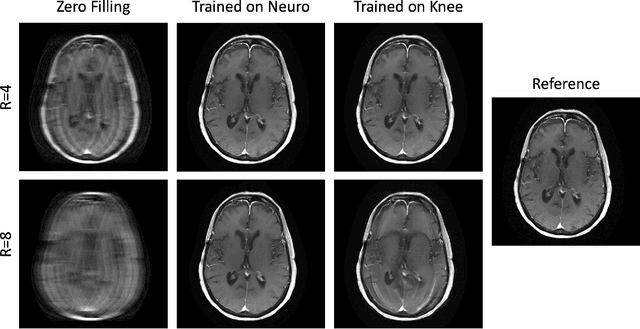
Physics-driven deep learning methods have emerged as a powerful tool for computational magnetic resonance imaging (MRI) problems, pushing reconstruction performance to new limits. This article provides an overview of the recent developments in incorporating physics information into learning-based MRI reconstruction. We consider inverse problems with both linear and non-linear forward models for computational MRI, and review the classical approaches for solving these. We then focus on physics-driven deep learning approaches, covering physics-driven loss functions, plug-and-play methods, generative models, and unrolled networks. We highlight domain-specific challenges such as real- and complex-valued building blocks of neural networks, and translational applications in MRI with linear and non-linear forward models. Finally, we discuss common issues and open challenges, and draw connections to the importance of physics-driven learning when combined with other downstream tasks in the medical imaging pipeline.
Learning to Walk Autonomously via Reset-Free Quality-Diversity
Apr 07, 2022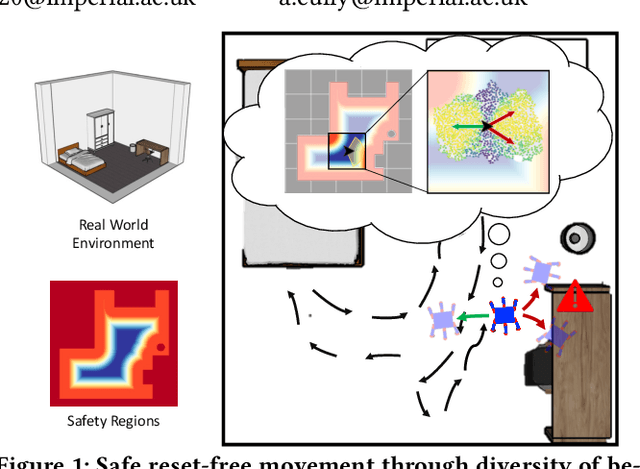
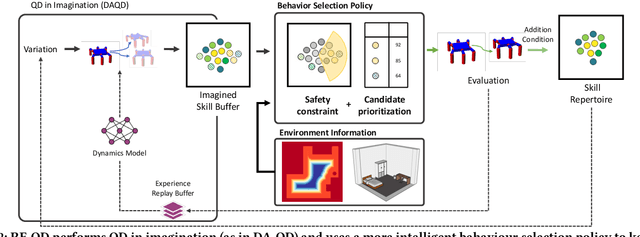
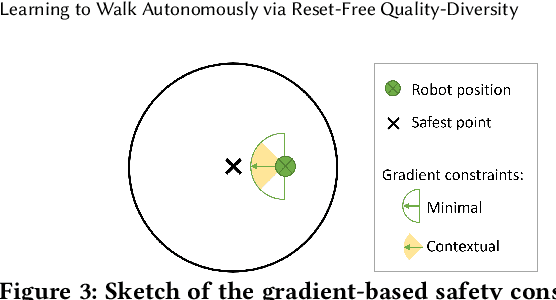
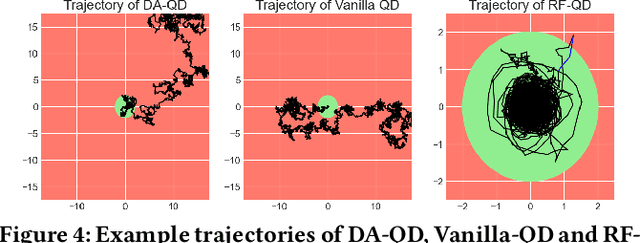
Quality-Diversity (QD) algorithms can discover large and complex behavioural repertoires consisting of both diverse and high-performing skills. However, the generation of behavioural repertoires has mainly been limited to simulation environments instead of real-world learning. This is because existing QD algorithms need large numbers of evaluations as well as episodic resets, which require manual human supervision and interventions. This paper proposes Reset-Free Quality-Diversity optimization (RF-QD) as a step towards autonomous learning for robotics in open-ended environments. We build on Dynamics-Aware Quality-Diversity (DA-QD) and introduce a behaviour selection policy that leverages the diversity of the imagined repertoire and environmental information to intelligently select of behaviours that can act as automatic resets. We demonstrate this through a task of learning to walk within defined training zones with obstacles. Our experiments show that we can learn full repertoires of legged locomotion controllers autonomously without manual resets with high sample efficiency in spite of harsh safety constraints. Finally, using an ablation of different target objectives, we show that it is important for RF-QD to have diverse types solutions available for the behaviour selection policy over solutions optimised with a specific objective. Videos and code available at https://sites.google.com/view/rf-qd.