 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Walk Autonomously via Reset-Free Quality-Diversity
Apr 07, 2022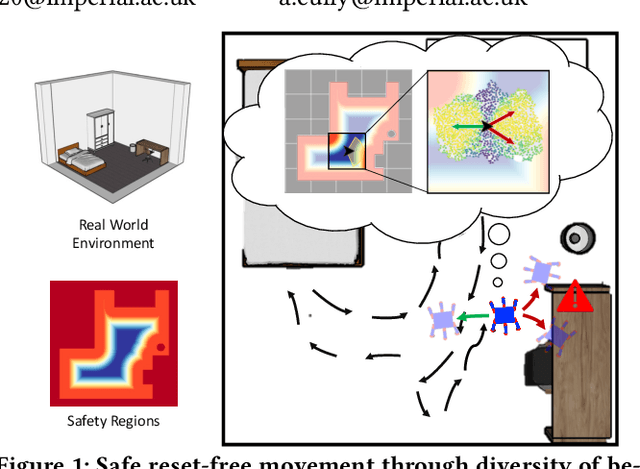
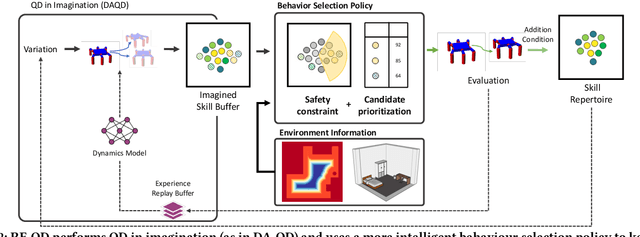
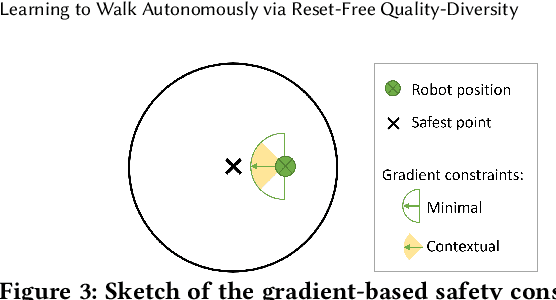
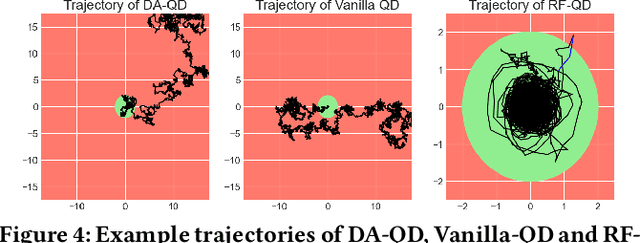
Quality-Diversity (QD) algorithms can discover large and complex behavioural repertoires consisting of both diverse and high-performing skills. However, the generation of behavioural repertoires has mainly been limited to simulation environments instead of real-world learning. This is because existing QD algorithms need large numbers of evaluations as well as episodic resets, which require manual human supervision and interventions. This paper proposes Reset-Free Quality-Diversity optimization (RF-QD) as a step towards autonomous learning for robotics in open-ended environments. We build on Dynamics-Aware Quality-Diversity (DA-QD) and introduce a behaviour selection policy that leverages the diversity of the imagined repertoire and environmental information to intelligently select of behaviours that can act as automatic resets. We demonstrate this through a task of learning to walk within defined training zones with obstacles. Our experiments show that we can learn full repertoires of legged locomotion controllers autonomously without manual resets with high sample efficiency in spite of harsh safety constraints. Finally, using an ablation of different target objectives, we show that it is important for RF-QD to have diverse types solutions available for the behaviour selection policy over solutions optimised with a specific objective. Videos and code available at https://sites.google.com/view/rf-qd.
A model for traffic incident prediction using emergency braking data
Feb 12, 2021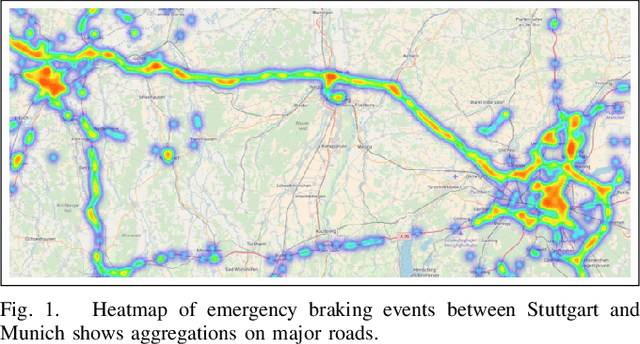
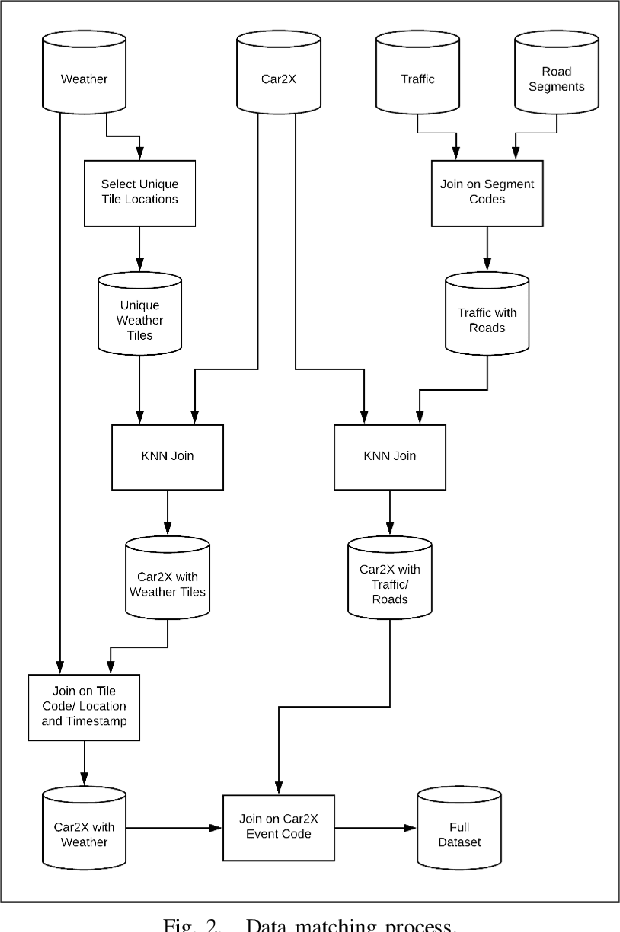
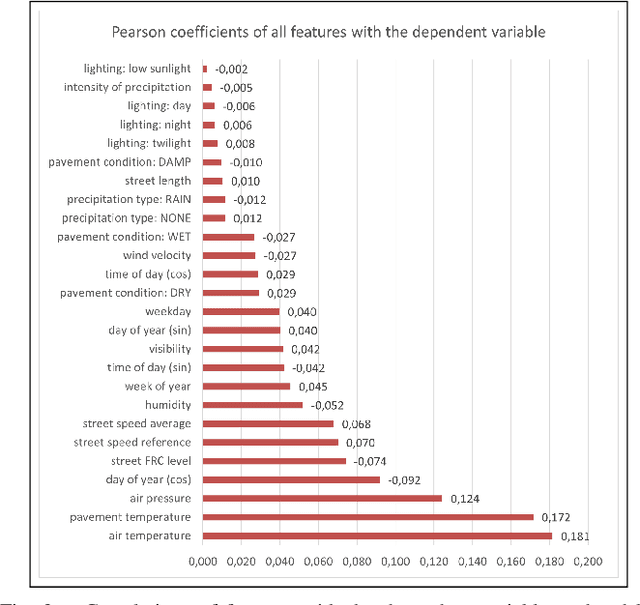
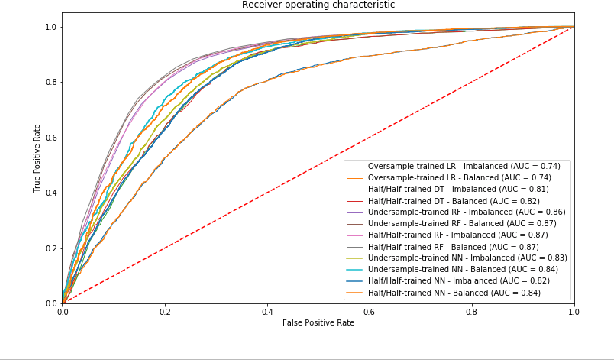
This article presents a model for traffic incident prediction. Specifically, we address the fundamental problem of data scarcity in road traffic accident prediction by training our model on emergency braking events instead of accidents. Based on relevant risk factors for traffic accidents and corresponding data categories, we evaluate different options for preprocessing sparse data and different Machine Learning models. Furthermore, we present a prototype implementing a traffic incident prediction model for Germany based on emergency braking data from Mercedes-Benz vehicles as well as weather, traffic and road data, respectively. After model evaluation and optimisation, we found that a Random Forest model trained on artificially balanced (under-sampled) data provided the highest classification accuracy of 85% on the original imbalanced data. Finally, we present our conclusions and discuss further work; from gathering more data over a longer period of time to build stronger classification systems, to addition of internal factors such as the driver's visual and cognitive attention.