 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
How Gender Debiasing Affects Internal Model Representations, and Why It Matters
Apr 14, 2022
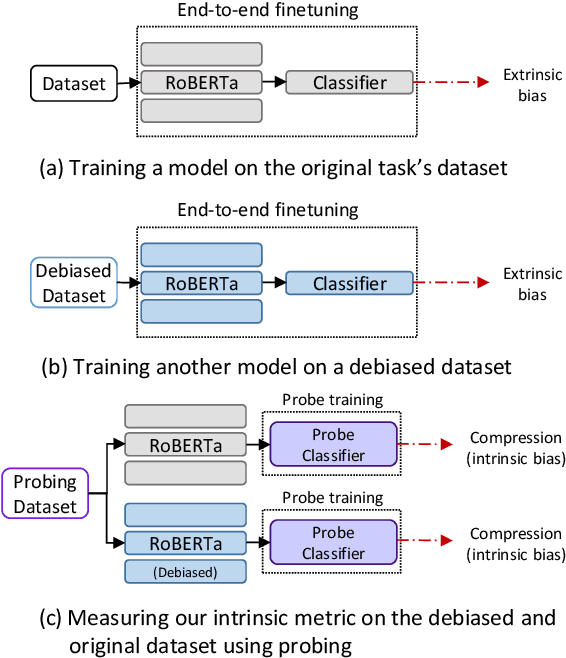
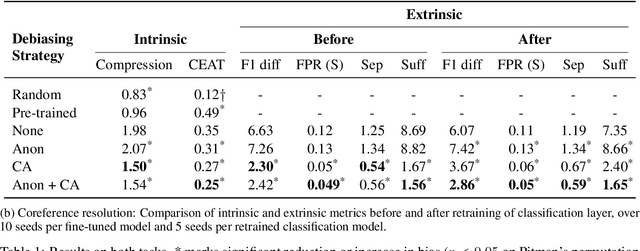
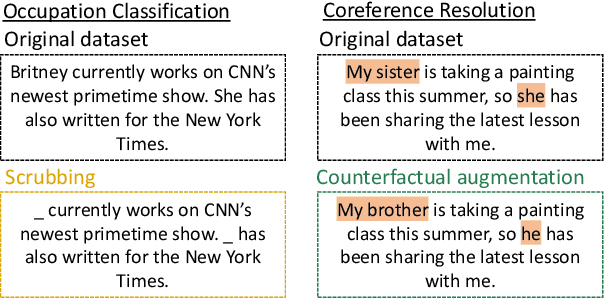
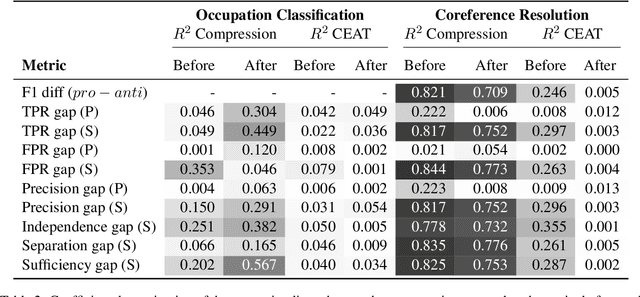
Common studies of gender bias in NLP focus either on extrinsic bias measured by model performance on a downstream task or on intrinsic bias found in models' internal representations. However, the relationship between extrinsic and intrinsic bias is relatively unknown. In this work, we illuminate this relationship by measuring both quantities together: we debias a model during downstream fine-tuning, which reduces extrinsic bias, and measure the effect on intrinsic bias, which is operationalized as bias extractability with information-theoretic probing. Through experiments on two tasks and multiple bias metrics, we show that our intrinsic bias metric is a better indicator of debiasing than (a contextual adaptation of) the standard WEAT metric, and can also expose cases of superficial debiasing. Our framework provides a comprehensive perspective on bias in NLP models, which can be applied to deploy NLP systems in a more informed manner. Our code will be made publicly available.
Modeling and mitigation of occupational safety risks in dynamic industrial environments
May 02, 2022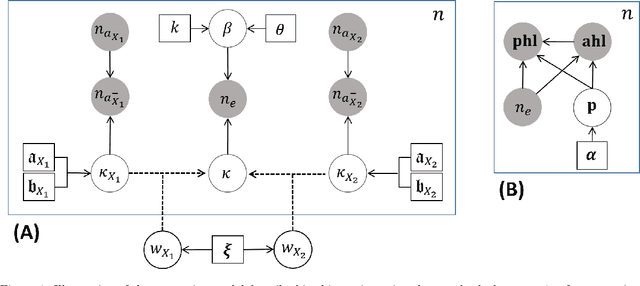
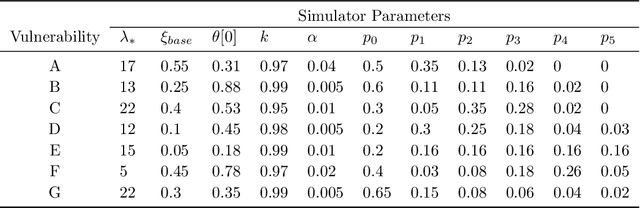


Identifying and mitigating safety risks is paramount in a number of industries. In addition to guidelines and best practices, many industries already have safety management systems (SMSs) designed to monitor and reinforce good safety behaviors. The analytic capabilities to analyze the data acquired through such systems, however, are still lacking in terms of their ability to robustly quantify risks posed by various occupational hazards. Moreover, best practices and modern SMSs are unable to account for dynamically evolving environments/behavioral characteristics commonly found in many industrial settings. This article proposes a method to address these issues by enabling continuous and quantitative assessment of safety risks in a data-driven manner. The backbone of our method is an intuitive hierarchical probabilistic model that explains sparse and noisy safety data collected by a typical SMS. A fully Bayesian approach is developed to calibrate this model from safety data in an online fashion. Thereafter, the calibrated model holds necessary information that serves to characterize risk posed by different safety hazards. Additionally, the proposed model can be leveraged for automated decision making, for instance solving resource allocation problems -- targeted towards risk mitigation -- that are often encountered in resource-constrained industrial environments. The methodology is rigorously validated on a simulated test-bed and its scalability is demonstrated on real data from large maintenance projects at a petrochemical plant.
Low-Complexity Designs of Symbol-Level Precoding for MU-MISO Systems
May 02, 2022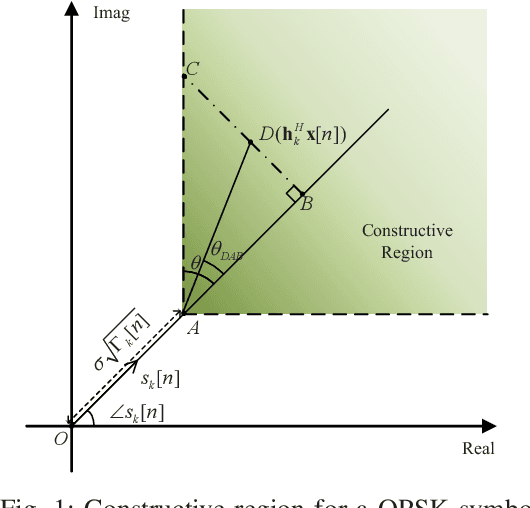
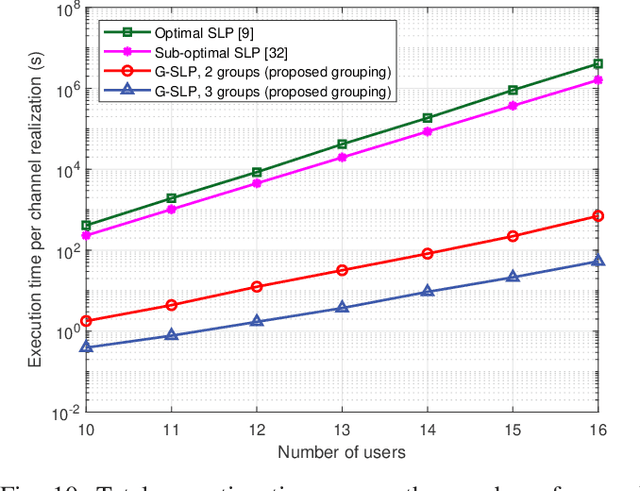
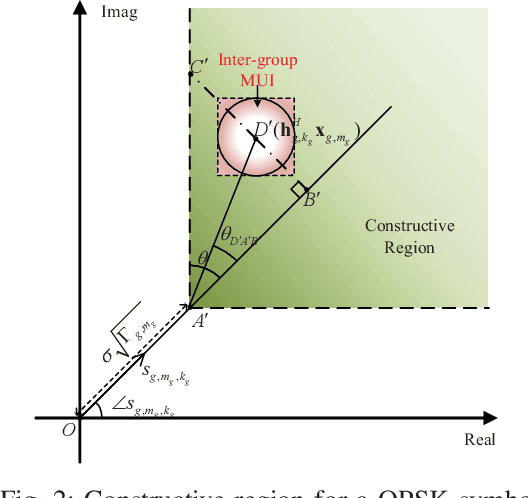
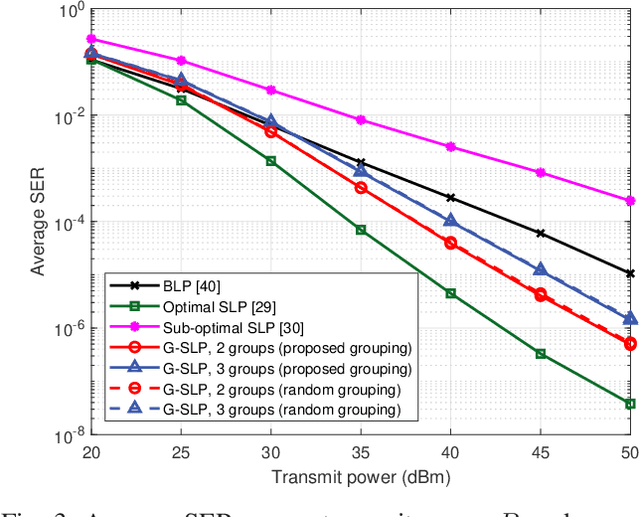
Symbol-level precoding (SLP), which converts the harmful multi-user interference (MUI) into beneficial signals, can significantly improve symbol-error-rate (SER) performance in multi-user communication systems. While enjoying symbolic gain, however, the complicated non-linear symbol-by-symbol precoder design suffers high computational complexity exponential with the number of users, which is unaffordable in realistic systems. In this paper, we propose a novel low-complexity grouped SLP (G-SLP) approach and develop efficient design algorithms for typical max-min fairness and power minimization problems. In particular, after dividing all users into several groups, the precoders for each group are separately designed on a symbol-by-symbol basis by only utilizing the symbol information of the users in that group, in which the intra-group MUI is exploited using the concept of constructive interference (CI) and the inter-group MUI is also effectively suppressed. In order to further reduce the computational complexity, we utilize the Lagrangian dual, Karush-Kuhn-Tucker (KKT) conditions and the majorization-minimization (MM) method to transform the resulting problems into more tractable forms, and develop efficient algorithms for obtaining closed-form solutions to them. Extensive simulation results illustrate that the proposed G-SLP strategy and design algorithms dramatically reduce the computational complexity without causing significant performance loss compared with the traditional SLP schemes.
Content addressable memory without catastrophic forgetting by heteroassociation with a fixed scaffold
Feb 01, 2022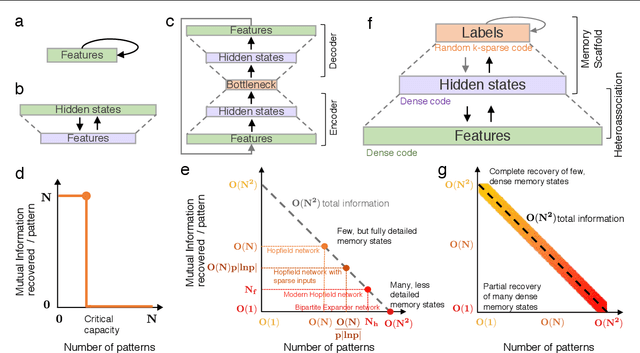
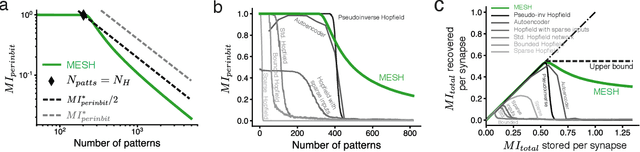
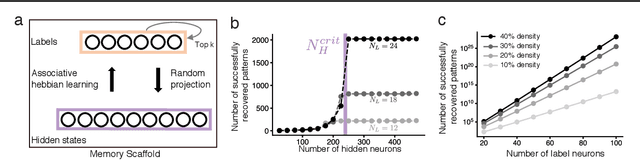
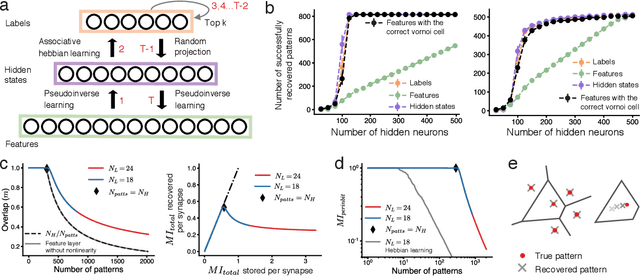
Content-addressable memory (CAM) networks, so-called because stored items can be recalled by partial or corrupted versions of the items, exhibit near-perfect recall of a small number of information-dense patterns below capacity and a `memory cliff' beyond, such that inserting a single additional pattern results in catastrophic forgetting of all stored patterns. We propose a novel ANN architecture, Memory Scaffold with Heteroassociation (MESH), that gracefully trades-off pattern richness with pattern number to generate a CAM continuum without a memory cliff: Small numbers of patterns are stored with complete information recovery matching standard CAMs, while inserting more patterns still results in partial recall of every pattern, with an information per pattern that scales inversely with the number of patterns. Motivated by the architecture of the Entorhinal-Hippocampal memory circuit in the brain, MESH is a tripartite architecture with pairwise interactions that uses a predetermined set of internally stabilized states together with heteroassociation between the internal states and arbitrary external patterns. We show analytically and experimentally that MESH nearly saturates the total information bound (given by the number of synapses) for CAM networks, invariant of the number of stored patterns, outperforming all existing CAM models.
Identifying Cause-and-Effect Relationships of Manufacturing Errors using Sequence-to-Sequence Learning
May 05, 2022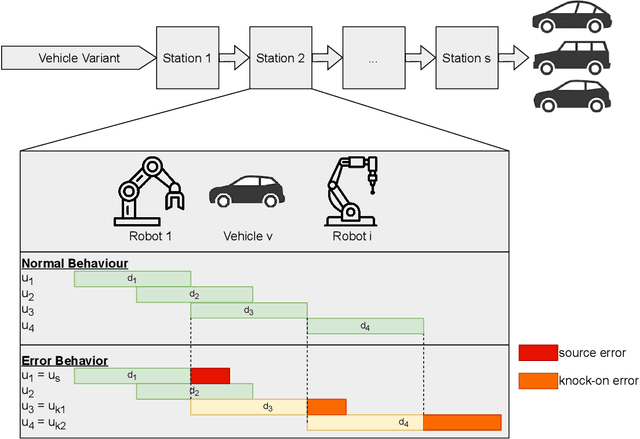
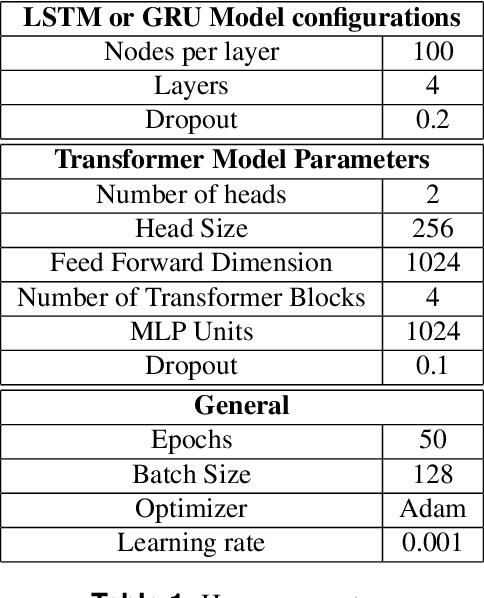
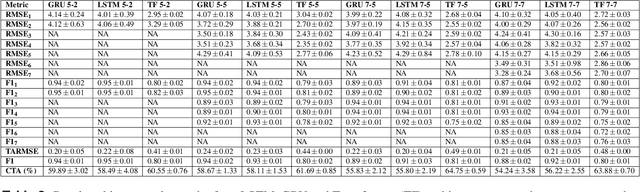
In car-body production the pre-formed sheet metal parts of the body are assembled on fully-automated production lines. The body passes through multiple stations in succession, and is processed according to the order requirements. The timely completion of orders depends on the individual station-based operations concluding within their scheduled cycle times. If an error occurs in one station, it can have a knock-on effect, resulting in delays on the downstream stations. To the best of our knowledge, there exist no methods for automatically distinguishing between source and knock-on errors in this setting, as well as establishing a causal relation between them. Utilizing real-time information about conditions collected by a production data acquisition system, we propose a novel vehicle manufacturing analysis system, which uses deep learning to establish a link between source and knock-on errors. We benchmark three sequence-to-sequence models, and introduce a novel composite time-weighted action metric for evaluating models in this context. We evaluate our framework on a real-world car production dataset recorded by Volkswagen Commercial Vehicles. Surprisingly we find that 71.68% of sequences contain either a source or knock-on error. With respect to seq2seq model training, we find that the Transformer demonstrates a better performance compared to LSTM and GRU in this domain, in particular when the prediction range with respect to the durations of future actions is increased.
More to Less (M2L): Enhanced Health Recognition in the Wild with Reduced Modality of Wearable Sensors
Feb 16, 2022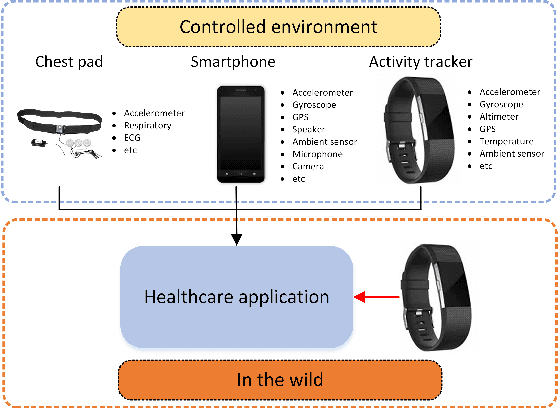
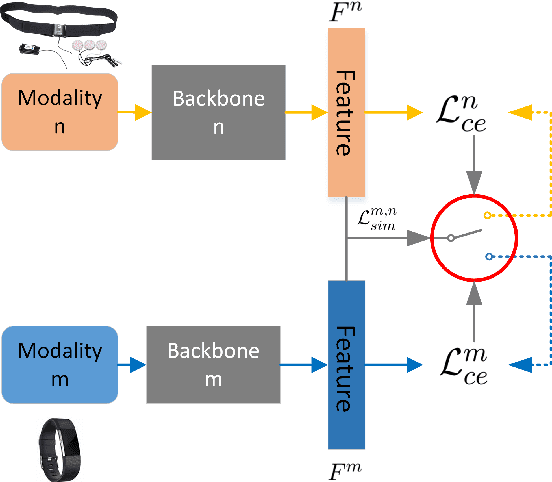
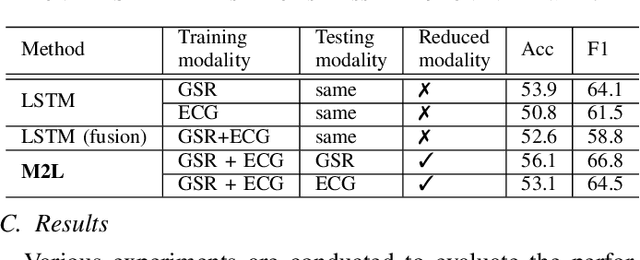
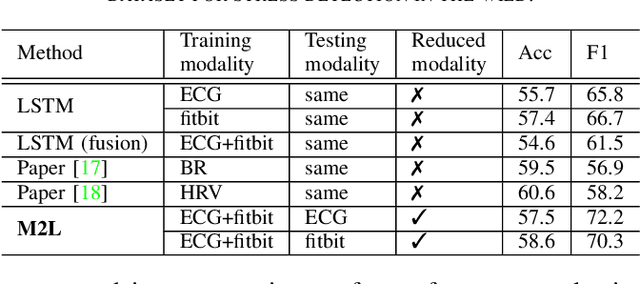
Accurately recognizing health-related conditions from wearable data is crucial for improved healthcare outcomes. To improve the recognition accuracy, various approaches have focused on how to effectively fuse information from multiple sensors. Fusing multiple sensors is a common scenario in many applications, but may not always be feasible in real-world scenarios. For example, although combining bio-signals from multiple sensors (i.e., a chest pad sensor and a wrist wearable sensor) has been proved effective for improved performance, wearing multiple devices might be impractical in the free-living context. To solve the challenges, we propose an effective more to less (M2L) learning framework to improve testing performance with reduced sensors through leveraging the complementary information of multiple modalities during training. More specifically, different sensors may carry different but complementary information, and our model is designed to enforce collaborations among different modalities, where positive knowledge transfer is encouraged and negative knowledge transfer is suppressed, so that better representation is learned for individual modalities. Our experimental results show that our framework achieves comparable performance when compared with the full modalities. Our code and results will be available at https://github.com/compwell-org/More2Less.git.
Segmentation-Consistent Probabilistic Lesion Counting
Apr 11, 2022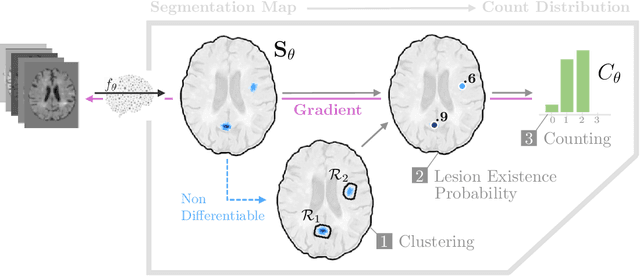
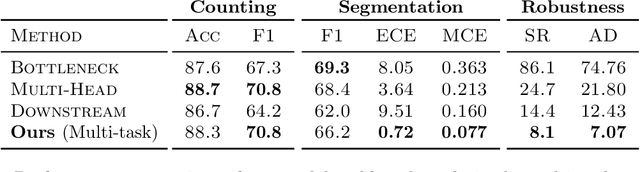
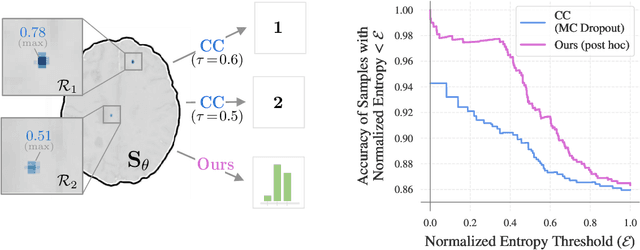
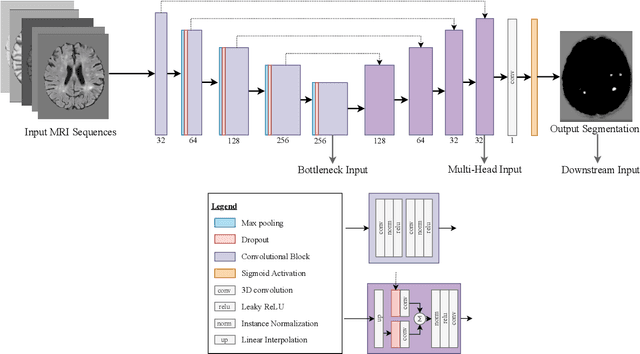
Lesion counts are important indicators of disease severity, patient prognosis, and treatment efficacy, yet counting as a task in medical imaging is often overlooked in favor of segmentation. This work introduces a novel continuously differentiable function that maps lesion segmentation predictions to lesion count probability distributions in a consistent manner. The proposed end-to-end approach--which consists of voxel clustering, lesion-level voxel probability aggregation, and Poisson-binomial counting--is non-parametric and thus offers a robust and consistent way to augment lesion segmentation models with post hoc counting capabilities. Experiments on Gadolinium-enhancing lesion counting demonstrate that our method outputs accurate and well-calibrated count distributions that capture meaningful uncertainty information. They also reveal that our model is suitable for multi-task learning of lesion segmentation, is efficient in low data regimes, and is robust to adversarial attacks.
Multicarrier-Division Duplex for Solving the Channel Aging Problem in Massive MIMO Systems
Apr 28, 2022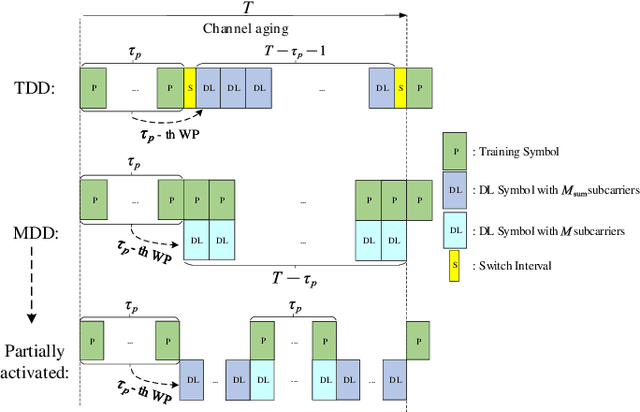
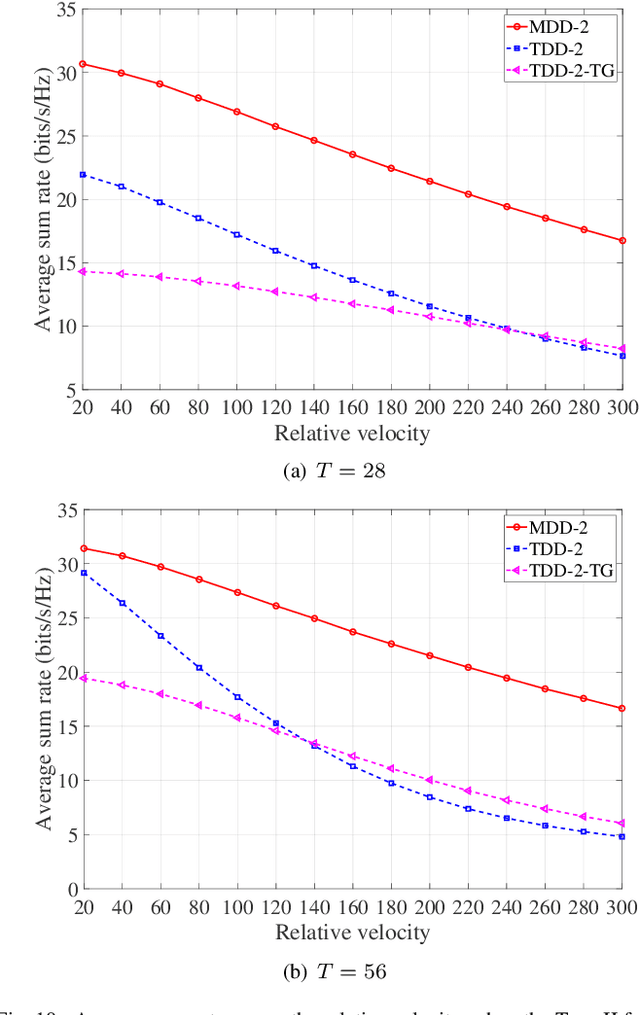
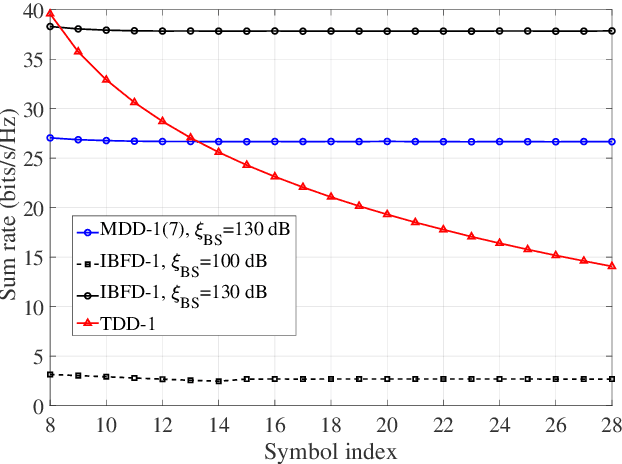
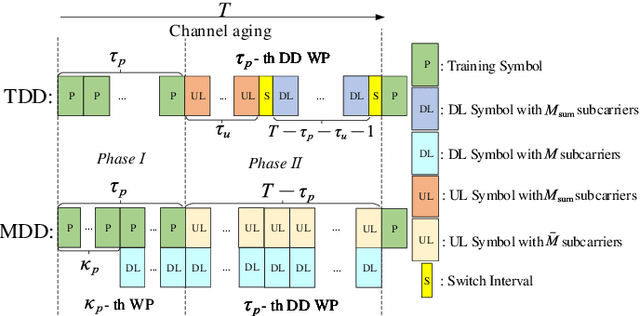
The separation of training and data transmission as well as the frequent uplink/downlink (UL/DL) switching make time-division duplex (TDD)-based massive multiple-input multiple-output (mMIMO) systems less competent in fast time-varying scenarios due to the resulted severe channel aging. To this end, a multicarrier-division duplex (MDD) mMIMO scheme associated with two types of well-designed frame structures are introduced for combating channel aging when communicating over fast time-varying channels. To compare with TDD, the corresponding frame structures related to 3GPP standards and their variant forms are presented. The MDD-specific general Wiener predictor and decision-directed Wiener predictor are introduced to predict the channel state information, respectively, in the time domain based on UL pilots and in the frequency domain based on the detected UL data, considering the impact of residual self-interference (SI). Moreover, by applying the zero-forcing precoding and maximum ratio combining, the closed-form approximations for the lower bounded rate achieved by TDD and MDD systems over time-varying channels are derived. Our main conclusion from this study is that the MDD, endowed with the capability of full-duplex but less demand on SI cancellation than in-band full-duplex (IBFD), outperforms both the conventional TDD and IBFD in combating channel aging.
Measuring Unintended Memorisation of Unique Private Features in Neural Networks
Feb 16, 2022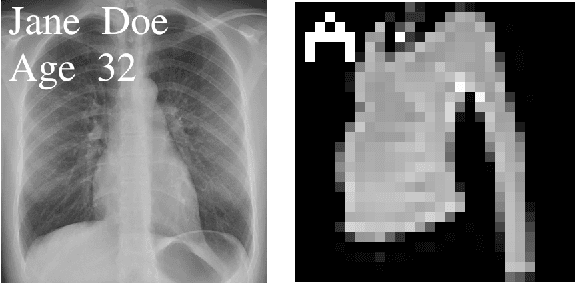
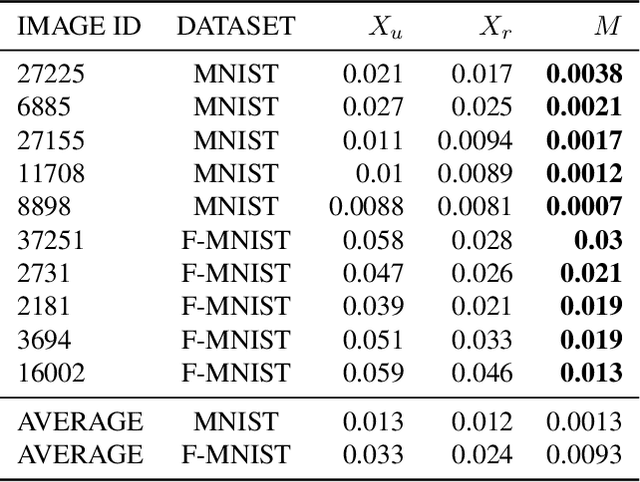

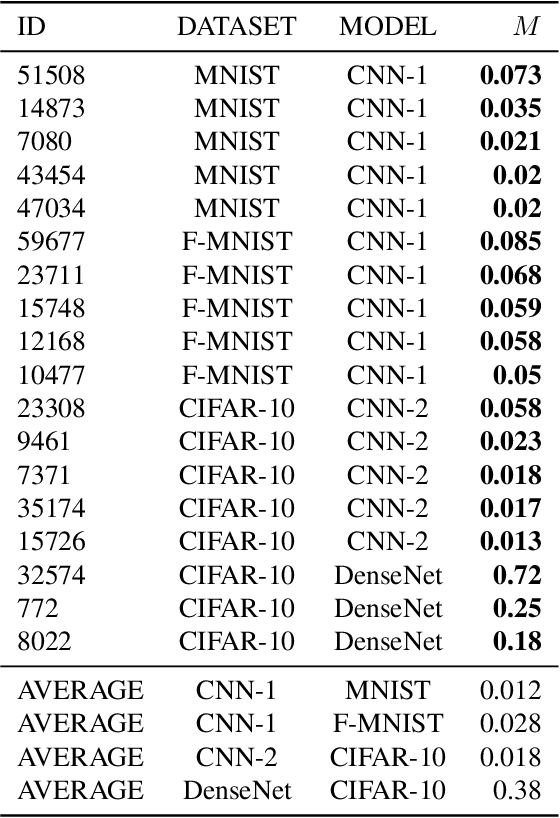
Neural networks pose a privacy risk to training data due to their propensity to memorise and leak information. Focusing on image classification, we show that neural networks also unintentionally memorise unique features even when they occur only once in training data. An example of a unique feature is a person's name that is accidentally present on a training image. Assuming access to the inputs and outputs of a trained model, the domain of the training data, and knowledge of unique features, we develop a score estimating the model's sensitivity to a unique feature by comparing the KL divergences of the model's output distributions given modified out-of-distribution images. Our results suggest that unique features are memorised by multi-layer perceptrons and convolutional neural networks trained on benchmark datasets, such as MNIST, Fashion-MNIST and CIFAR-10. We find that strategies to prevent overfitting (e.g.\ early stopping, regularisation, batch normalisation) do not prevent memorisation of unique features. These results imply that neural networks pose a privacy risk to rarely occurring private information. These risks can be more pronounced in healthcare applications if patient information is present in the training data.
INSIDE: Steering Spatial Attention with Non-Imaging Information in CNNs
Aug 21, 2020We consider the problem of integrating non-imaging information into segmentation networks to improve performance. Conditioning layers such as FiLM provide the means to selectively amplify or suppress the contribution of different feature maps in a linear fashion. However, spatial dependency is difficult to learn within a convolutional paradigm. In this paper, we propose a mechanism to allow for spatial localisation conditioned on non-imaging information, using a feature-wise attention mechanism comprising a differentiable parametrised function (e.g. Gaussian), prior to applying the feature-wise modulation. We name our method INstance modulation with SpatIal DEpendency (INSIDE). The conditioning information might comprise any factors that relate to spatial or spatio-temporal information such as lesion location, size, and cardiac cycle phase. Our method can be trained end-to-end and does not require additional supervision. We evaluate the method on two datasets: a new CLEVR-Seg dataset where we segment objects based on location, and the ACDC dataset conditioned on cardiac phase and slice location within the volume. Code and the CLEVR-Seg dataset are available at https://github.com/jacenkow/inside.