 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-Layer Modeling of Dense Vegetation from Aerial LiDAR Scans
Apr 25, 2022
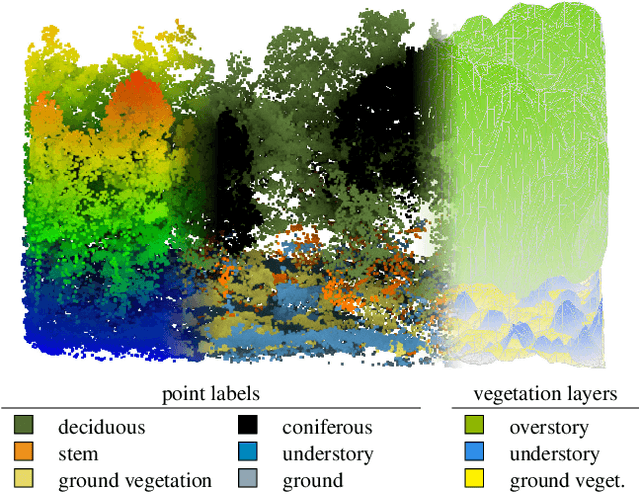

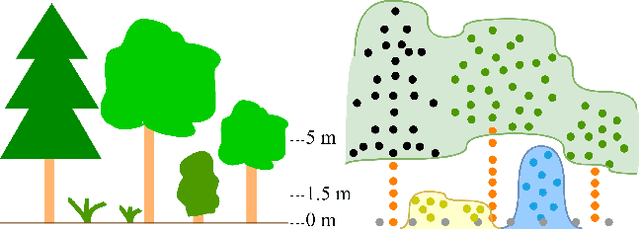
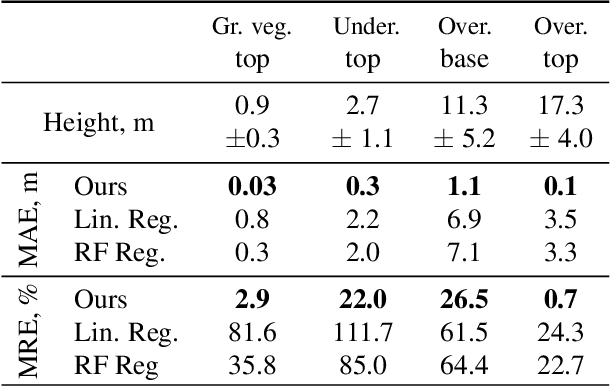
The analysis of the multi-layer structure of wild forests is an important challenge of automated large-scale forestry. While modern aerial LiDARs offer geometric information across all vegetation layers, most datasets and methods focus only on the segmentation and reconstruction of the top of canopy. We release WildForest3D, which consists of 29 study plots and over 2000 individual trees across 47 000m2 with dense 3D annotation, along with occupancy and height maps for 3 vegetation layers: ground vegetation, understory, and overstory. We propose a 3D deep network architecture predicting for the first time both 3D point-wise labels and high-resolution layer occupancy rasters simultaneously. This allows us to produce a precise estimation of the thickness of each vegetation layer as well as the corresponding watertight meshes, therefore meeting most forestry purposes. Both the dataset and the model are released in open access: https://github.com/ekalinicheva/multi_layer_vegetation.
OmniFusion: 360 Monocular Depth Estimation via Geometry-Aware Fusion
Mar 29, 2022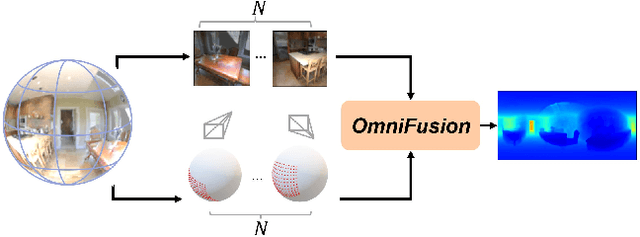
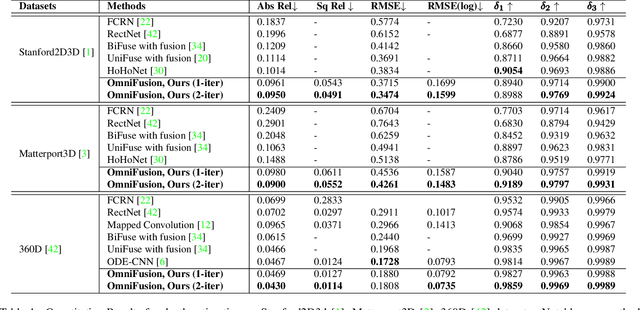
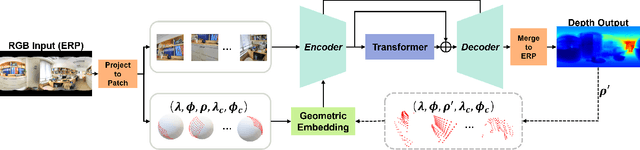

A well-known challenge in applying deep-learning methods to omnidirectional images is spherical distortion. In dense regression tasks such as depth estimation, where structural details are required, using a vanilla CNN layer on the distorted 360 image results in undesired information loss. In this paper, we propose a 360 monocular depth estimation pipeline, OmniFusion, to tackle the spherical distortion issue. Our pipeline transforms a 360 image into less-distorted perspective patches (i.e. tangent images) to obtain patch-wise predictions via CNN, and then merge the patch-wise results for final output. To handle the discrepancy between patch-wise predictions which is a major issue affecting the merging quality, we propose a new framework with the following key components. First, we propose a geometry-aware feature fusion mechanism that combines 3D geometric features with 2D image features to compensate for the patch-wise discrepancy. Second, we employ the self-attention-based transformer architecture to conduct a global aggregation of patch-wise information, which further improves the consistency. Last, we introduce an iterative depth refinement mechanism, to further refine the estimated depth based on the more accurate geometric features. Experiments show that our method greatly mitigates the distortion issue, and achieves state-of-the-art performances on several 360 monocular depth estimation benchmark datasets.
DMRF-UNet: A Two-Stage Deep Learning Scheme for GPR Data Inversion under Heterogeneous Soil Conditions
May 16, 2022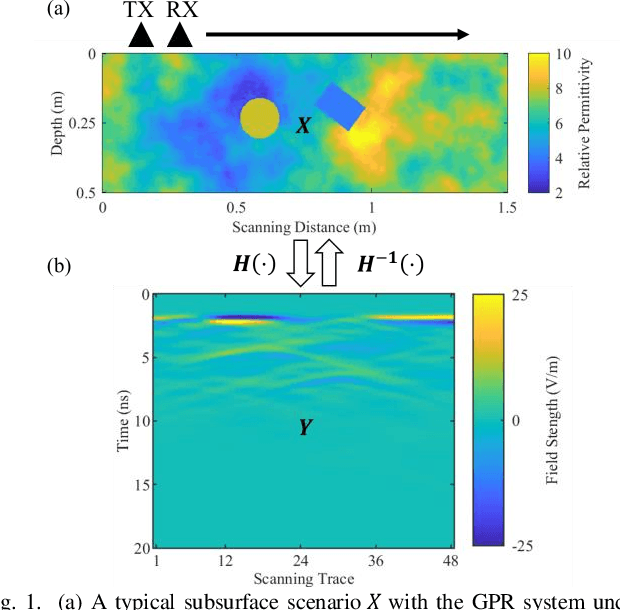
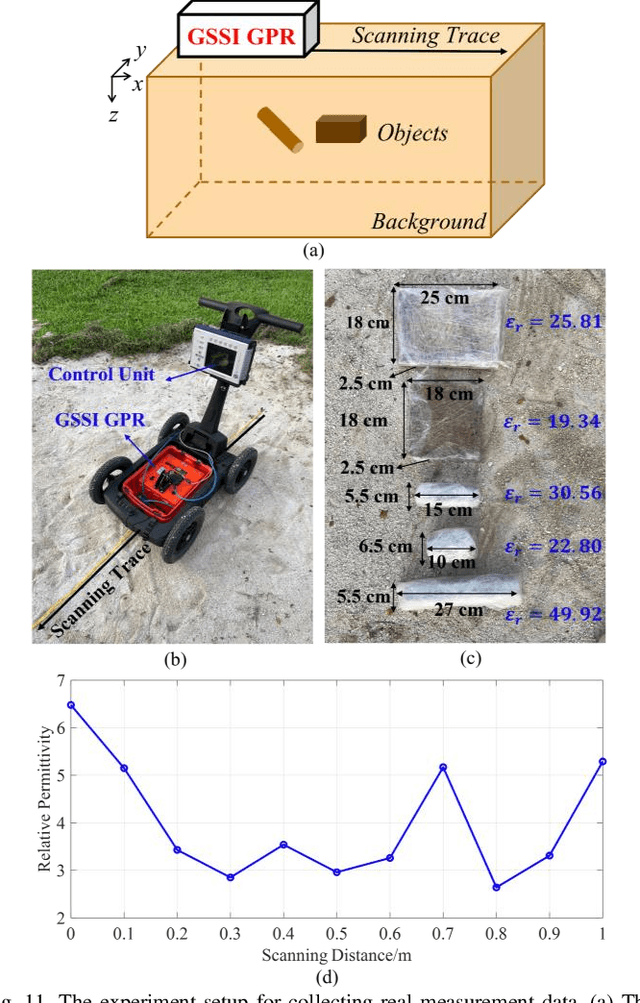
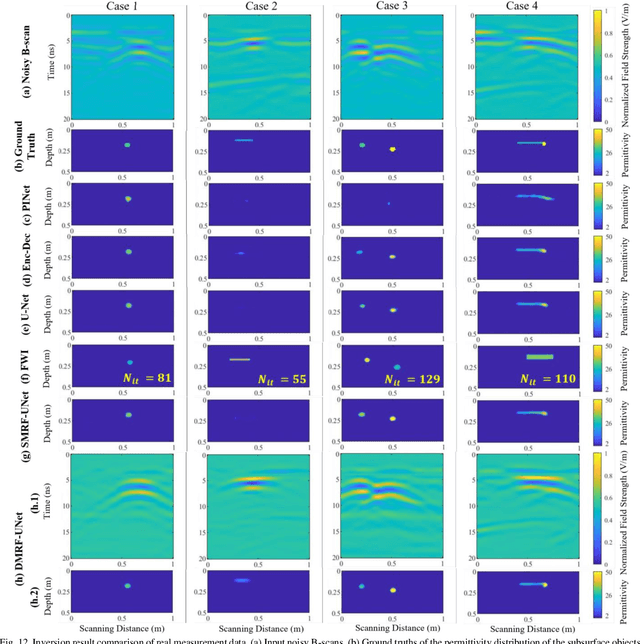
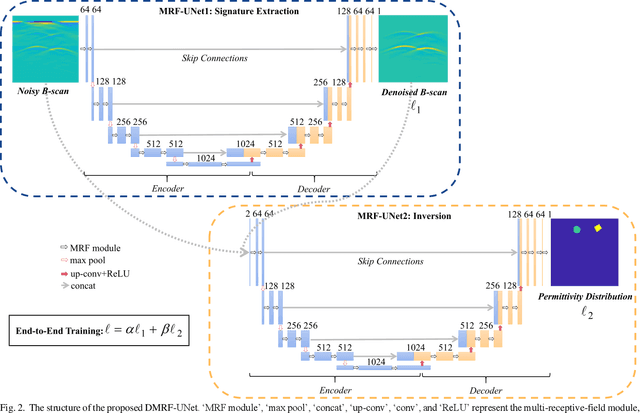
Traditional ground-penetrating radar (GPR) data inversion leverages iterative algorithms which suffer from high computation costs and low accuracy when applied to complex subsurface scenarios. Existing deep learning-based methods focus on the ideal homogeneous subsurface environments and ignore the interference due to clutters and noise in real-world heterogeneous environments. To address these issues, a two-stage deep neural network (DNN), called DMRF-UNet, is proposed to reconstruct the permittivity distributions of subsurface objects from GPR B-scans under heterogeneous soil conditions. In the first stage, a U-shape DNN with multi-receptive-field convolutions (MRF-UNet1) is built to remove the clutters due to inhomogeneity of the heterogeneous soil. Then the denoised B-scan from the MRF-UNet1 is combined with the noisy B-scan to be inputted to the DNN in the second stage (MRF-UNet2). The MRF-UNet2 learns the inverse mapping relationship and reconstructs the permittivity distribution of subsurface objects. To avoid information loss, an end-to-end training method combining the loss functions of two stages is introduced. A wide range of subsurface heterogeneous scenarios and B-scans are generated to evaluate the inversion performance. The test results in the numerical experiment and the real measurement show that the proposed network reconstructs the permittivities, shapes, sizes, and locations of subsurface objects with high accuracy. The comparison with existing methods demonstrates the superiority of the proposed methodology for the inversion under heterogeneous soil conditions.
l-Leaks: Membership Inference Attacks with Logits
May 13, 2022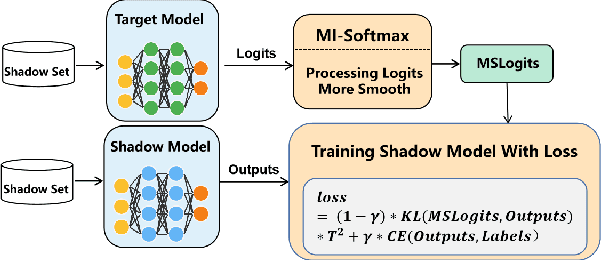

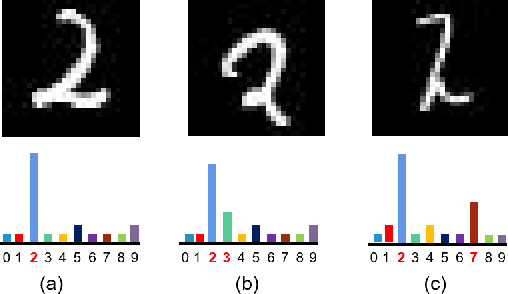

Machine Learning (ML) has made unprecedented progress in the past several decades. However, due to the memorability of the training data, ML is susceptible to various attacks, especially Membership Inference Attacks (MIAs), the objective of which is to infer the model's training data. So far, most of the membership inference attacks against ML classifiers leverage the shadow model with the same structure as the target model. However, empirical results show that these attacks can be easily mitigated if the shadow model is not clear about the network structure of the target model. In this paper, We present attacks based on black-box access to the target model. We name our attack \textbf{l-Leaks}. The l-Leaks follows the intuition that if an established shadow model is similar enough to the target model, then the adversary can leverage the shadow model's information to predict a target sample's membership.The logits of the trained target model contain valuable sample knowledge. We build the shadow model by learning the logits of the target model and making the shadow model more similar to the target model. Then shadow model will have sufficient confidence in the member samples of the target model. We also discuss the effect of the shadow model's different network structures to attack results. Experiments over different networks and datasets demonstrate that both of our attacks achieve strong performance.
HierAttn: Effectively Learn Representations from Stage Attention and Branch Attention for Skin Lesions Diagnosis
May 16, 2022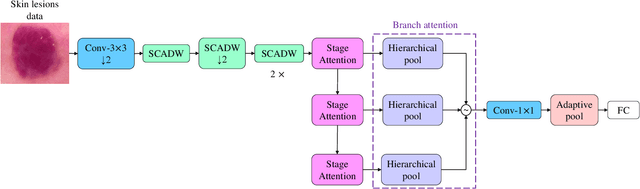
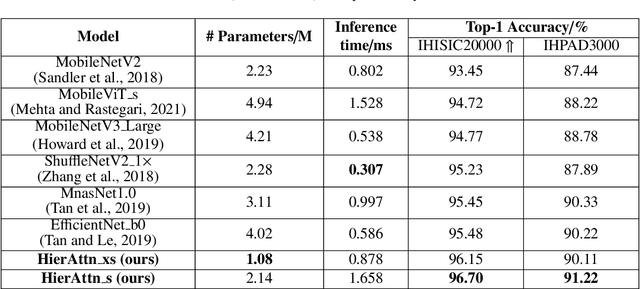
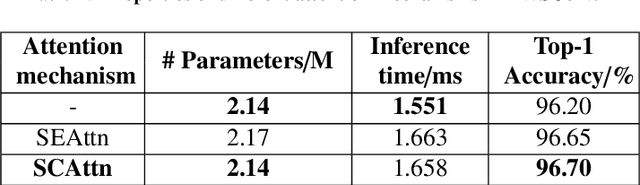
Accurate and unbiased examinations of skin lesions are critical for early diagnosis and treatment of skin conditions and disorders. Visual features of skin lesions vary significantly because the skin images are collected from patients with different skin colours by using dissimilar type of imaging equipment. Recent studies have reported ensembled convolutional neural networks (CNNs) to classify the images for early diagnosis of skin disorders. However, the practical use of CNNs is limited because the majority of networks are heavyweight and inadequate to use the contextual information. Although lightweight networks (e.g., MobileNetV3 and EfficientNet) were developed to save the computational cost for implementing deep neural networks on mobile devices, not sufficient representation depth restricts their performance. To address the limitations, we introduce a new light and effective neural network, namely HierAttn network. The HierAttn applies a novel strategy to balance the learning local and global features by using a multi-stage attention mechanism in a hierarchical architecture. The efficacy of HierAttn was evaluated by using the dermoscopy images dataset ISIC2019 and smartphone photos dataset PAD-UFES-20. The experimental results show that HierAttn achieves the best top-1 accuracy and AUC among the state-of-the-art light-weight networks. The new light HierAttn network has the potential in promoting the use of deep learning in clinics and allowing patients for early diagnosis of skin disorders with personal devices. The code is available at https://github.com/anthonyweidai/HierAttn.
Automated Mobility Context Detection with Inertial Signals
May 16, 2022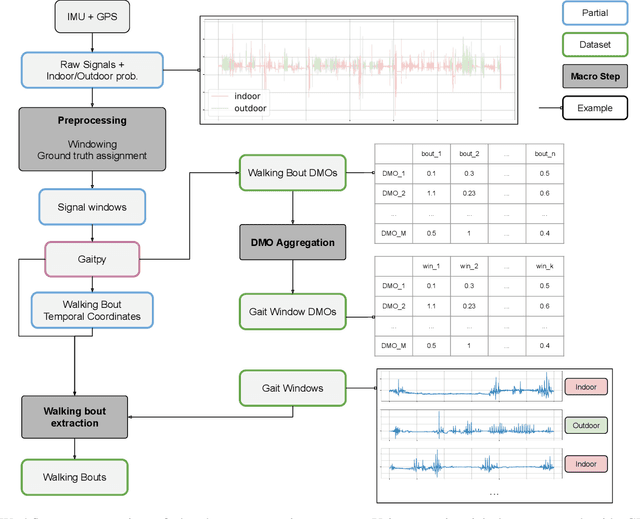
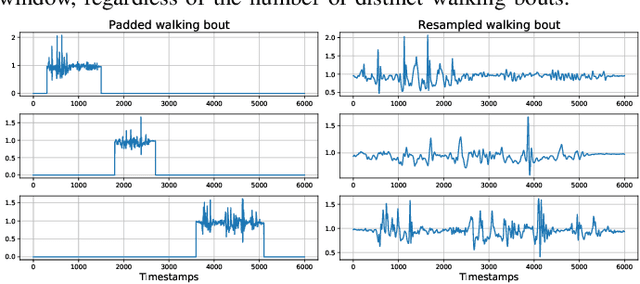
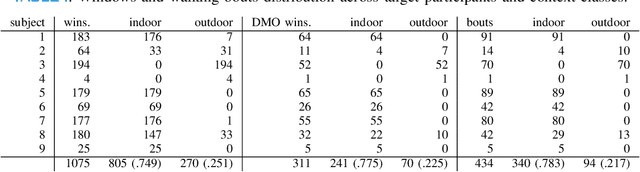
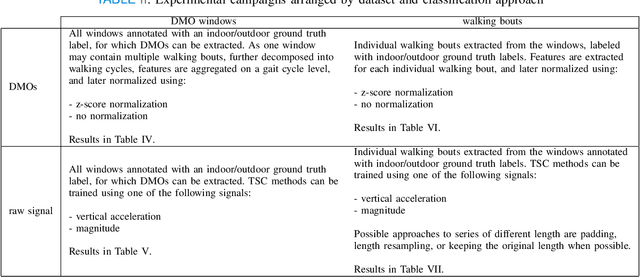
Remote monitoring of motor functions is a powerful approach for health assessment, especially among the elderly population or among subjects affected by pathologies that negatively impact their walking capabilities. This is further supported by the continuous development of wearable sensor devices, which are getting progressively smaller, cheaper, and more energy efficient. The external environment and mobility context have an impact on walking performance, hence one of the biggest challenges when remotely analysing gait episodes is the ability to detect the context within which those episodes occurred. The primary goal of this paper is the investigation of context detection for remote monitoring of daily motor functions. We aim to understand whether inertial signals sampled with wearable accelerometers, provide reliable information to classify gait-related activities as either indoor or outdoor. We explore two different approaches to this task: (1) using gait descriptors and features extracted from the input inertial signals sampled during walking episodes, together with classic machine learning algorithms, and (2) treating the input inertial signals as time series data and leveraging end-to-end state-of-the-art time series classifiers. We directly compare the two approaches through a set of experiments based on data collected from 9 healthy individuals. Our results indicate that the indoor/outdoor context can be successfully derived from inertial data streams. We also observe that time series classification models achieve better accuracy than any other feature-based models, while preserving efficiency and ease of use.
Using Collocated Vision and Tactile Sensors for Visual Servoing and Localization
Apr 27, 2022
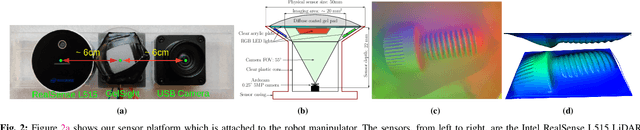


Coordinating proximity and tactile imaging by collocating cameras with tactile sensors can 1) provide useful information before contact such as object pose estimates and visually servo a robot to a target with reduced occlusion and higher resolution compared to head-mounted or external depth cameras, 2) simplify the contact point and pose estimation problems and help tactile sensing avoid erroneous matches when a surface does not have significant texture or has repetitive texture with many possible matches, and 3) use tactile imaging to further refine contact point and object pose estimation. We demonstrate our results with objects that have more surface texture than most objects in standard manipulation datasets. We learn that optic flow needs to be integrated over a substantial amount of camera travel to be useful in predicting movement direction. Most importantly, we also learn that state of the art vision algorithms do not do a good job localizing tactile images on object models, unless a reasonable prior can be provided from collocated cameras.
* This archival version of the manuscript is significantly different in content from the reviewed and published version. The published version can be accessed here: https://ieeexplore.ieee.org/document/9699405. Supplementary materials can be accessed here: https://arkadeepnc.github.io/projects/collocated_vision_touch/index.html
Biomedical Information Extraction for Disease Gene Prioritization
Nov 12, 2020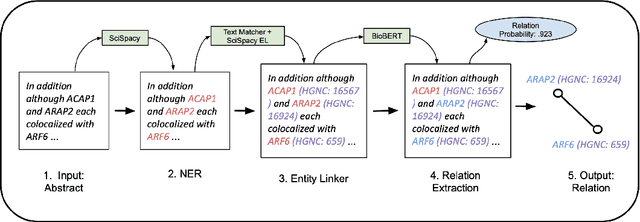
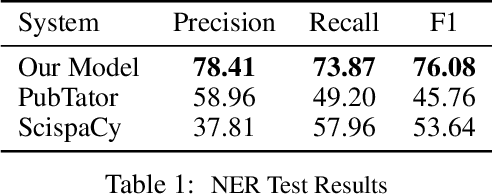
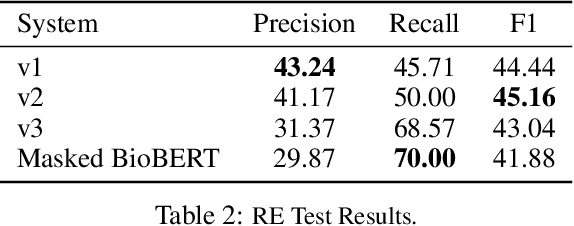
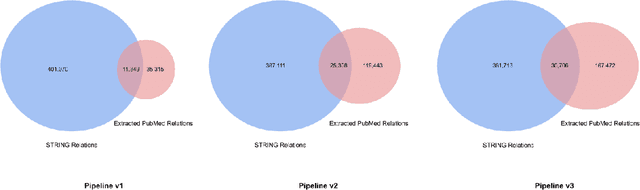
We introduce a biomedical information extraction (IE) pipeline that extracts biological relationships from text and demonstrate that its components, such as named entity recognition (NER) and relation extraction (RE), outperform state-of-the-art in BioNLP. We apply it to tens of millions of PubMed abstracts to extract protein-protein interactions (PPIs) and augment these extractions to a biomedical knowledge graph that already contains PPIs extracted from STRING, the leading structured PPI database. We show that, despite already containing PPIs from an established structured source, augmenting our own IE-based extractions to the graph allows us to predict novel disease-gene associations with a 20% relative increase in hit@30, an important step towards developing drug targets for uncured diseases.
Exploiting Variational Domain-Invariant User Embedding for Partially Overlapped Cross Domain Recommendation
May 13, 2022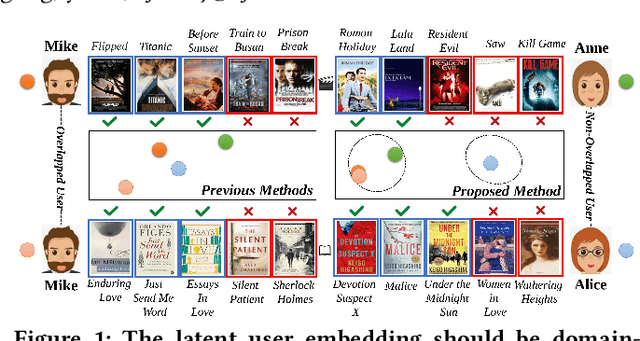
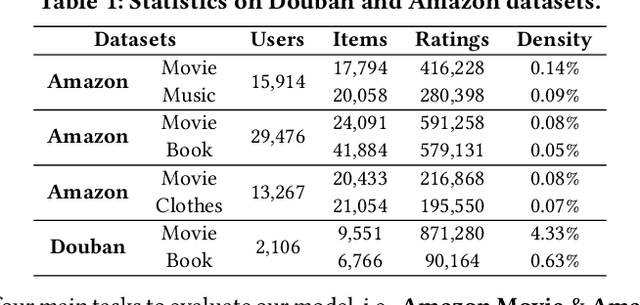
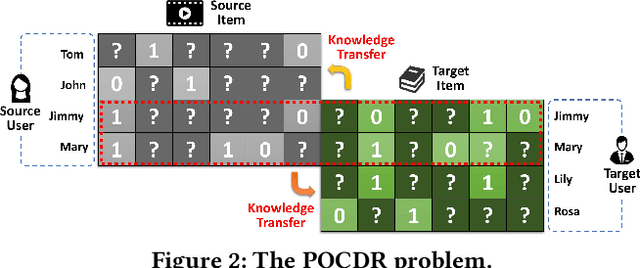
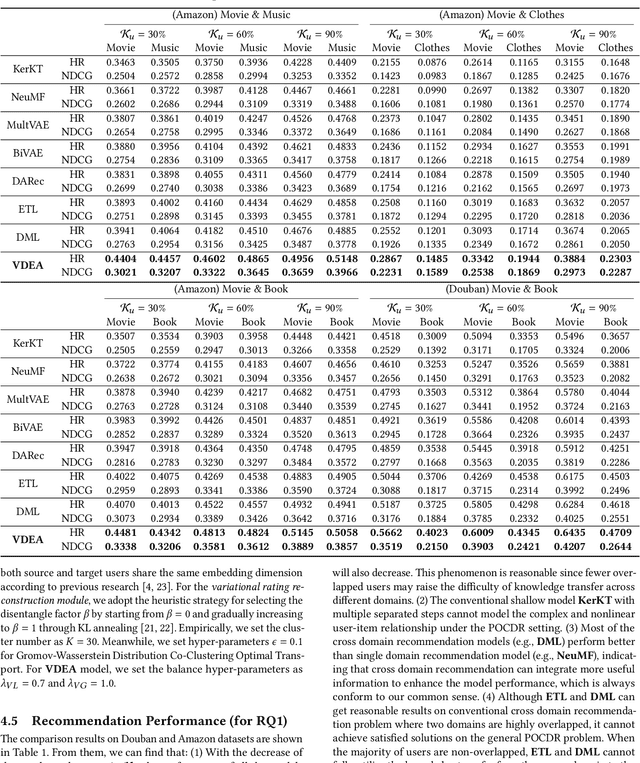
Cross-Domain Recommendation (CDR) has been popularly studied to utilize different domain knowledge to solve the cold-start problem in recommender systems. Most of the existing CDR models assume that both the source and target domains share the same overlapped user set for knowledge transfer. However, only few proportion of users simultaneously activate on both the source and target domains in practical CDR tasks. In this paper, we focus on the Partially Overlapped Cross-Domain Recommendation (POCDR) problem, that is, how to leverage the information of both the overlapped and non-overlapped users to improve recommendation performance. Existing approaches cannot fully utilize the useful knowledge behind the non-overlapped users across domains, which limits the model performance when the majority of users turn out to be non-overlapped. To address this issue, we propose an end-to-end dual-autoencoder with Variational Domain-invariant Embedding Alignment (VDEA) model, a cross-domain recommendation framework for the POCDR problem, which utilizes dual variational autoencoders with both local and global embedding alignment for exploiting domain-invariant user embedding. VDEA first adopts variational inference to capture collaborative user preferences, and then utilizes Gromov-Wasserstein distribution co-clustering optimal transport to cluster the users with similar rating interaction behaviors. Our empirical studies on Douban and Amazon datasets demonstrate that VDEA significantly outperforms the state-of-the-art models, especially under the POCDR setting.
Rate-Distortion Theoretic Generalization Bounds for Stochastic Learning Algorithms
Mar 04, 2022Understanding generalization in modern machine learning settings has been one of the major challenges in statistical learning theory. In this context, recent years have witnessed the development of various generalization bounds suggesting different complexity notions such as the mutual information between the data sample and the algorithm output, compressibility of the hypothesis space, and the fractal dimension of the hypothesis space. While these bounds have illuminated the problem at hand from different angles, their suggested complexity notions might appear seemingly unrelated, thereby restricting their high-level impact. In this study, we prove novel generalization bounds through the lens of rate-distortion theory, and explicitly relate the concepts of mutual information, compressibility, and fractal dimensions in a single mathematical framework. Our approach consists of (i) defining a generalized notion of compressibility by using source coding concepts, and (ii) showing that the `compression error rate' can be linked to the generalization error both in expectation and with high probability. We show that in the `lossless compression' setting, we recover and improve existing mutual information-based bounds, whereas a `lossy compression' scheme allows us to link generalization to the rate-distortion dimension -- a particular notion of fractal dimension. Our results bring a more unified perspective on generalization and open up several future research directions.