 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Proving of Shannon-Type Entropy Inequalities via Fine-Tuned Language Models and Guided Tree Search
Jun 04, 2026Proving Shannon-type entropy inequalities is a fundamental task in information theory that often requires constructing non-trivial linear combinations of known constraints, which is a combinatorial search problem that scales poorly with the number of random variables. We investigate whether small-scale large language models (0.6B--1.7B parameters), fine-tuned on atomic proof steps and combined with guided beam search, can automate this process. On a held-out test set of 60 inequalities spanning n=10 to 15 variables, our 0.6B fine-tuned model achieves an 85\% proof success rate with tree search. GPT-5.5 solves 1.7\% samples under zero-shot prompting while Psitip solves 33.3\% samples. A systematic ablation study across training context length (4096 vs.\ 8192 tokens) and data distribution (n=9-skewed vs not skewed) reveals that a 4096-token not skewed training distribution yields the best performance, with extended context and skewed data providing no marginal benefit. We further identify two dominant failure modes -- format failures and step quality degradation -- and verify that the beam-scoring heuristic is essential via a controlled ablation (random scoring reduces success from 83\% to 23\%).
SPARKE: Scalable Prompt-Aware Diversity Guidance in Diffusion Models via RKE Score
Jun 11, 2025



Diffusion models have demonstrated remarkable success in high-fidelity image synthesis and prompt-guided generative modeling. However, ensuring adequate diversity in generated samples of prompt-guided diffusion models remains a challenge, particularly when the prompts span a broad semantic spectrum and the diversity of generated data needs to be evaluated in a prompt-aware fashion across semantically similar prompts. Recent methods have introduced guidance via diversity measures to encourage more varied generations. In this work, we extend the diversity measure-based approaches by proposing the Scalable Prompt-Aware R\'eny Kernel Entropy Diversity Guidance (SPARKE) method for prompt-aware diversity guidance. SPARKE utilizes conditional entropy for diversity guidance, which dynamically conditions diversity measurement on similar prompts and enables prompt-aware diversity control. While the entropy-based guidance approach enhances prompt-aware diversity, its reliance on the matrix-based entropy scores poses computational challenges in large-scale generation settings. To address this, we focus on the special case of Conditional latent RKE Score Guidance, reducing entropy computation and gradient-based optimization complexity from the $O(n^3)$ of general entropy measures to $O(n)$. The reduced computational complexity allows for diversity-guided sampling over potentially thousands of generation rounds on different prompts. We numerically test the SPARKE method on several text-to-image diffusion models, demonstrating that the proposed method improves the prompt-aware diversity of the generated data without incurring significant computational costs. We release our code on the project page: https://mjalali.github.io/SPARKE
Conditional Vendi Score: An Information-Theoretic Approach to Diversity Evaluation of Prompt-based Generative Models
Nov 05, 2024



Text-conditioned generation models are commonly evaluated based on the quality of the generated data and its alignment with the input text prompt. On the other hand, several applications of prompt-based generative models require sufficient diversity in the generated data to ensure the models' capability of generating image and video samples possessing a variety of features. However, most existing diversity metrics are designed for unconditional generative models, and thus cannot distinguish the diversity arising from variations in text prompts and that contributed by the generative model itself. In this work, our goal is to quantify the prompt-induced and model-induced diversity in samples generated by prompt-based models. We propose an information-theoretic approach for internal diversity quantification, where we decompose the kernel-based entropy $H(X)$ of the generated data $X$ into the sum of the conditional entropy $H(X|T)$, given text variable $T$, and the mutual information $I(X; T)$ between the text and data variables. We introduce the \emph{Conditional-Vendi} score based on $H(X|T)$ to quantify the internal diversity of the model and the \emph{Information-Vendi} score based on $I(X; T)$ to measure the statistical relevance between the generated data and text prompts. We provide theoretical results to statistically interpret these scores and relate them to the unconditional Vendi score. We conduct several numerical experiments to show the correlation between the Conditional-Vendi score and the internal diversity of text-conditioned generative models. The codebase is available at \href{https://github.com/mjalali/conditional-vendi}{https://github.com/mjalali/conditional-vendi}.
Impact of Fairness Regulations on Institutions' Policies and Population Qualifications
Apr 06, 2024The proliferation of algorithmic systems has fueled discussions surrounding the regulation and control of their social impact. Herein, we consider a system whose primary objective is to maximize utility by selecting the most qualified individuals. To promote demographic parity in the selection algorithm, we consider penalizing discrimination across social groups. We examine conditions under which a discrimination penalty can effectively reduce disparity in the selection. Additionally, we explore the implications of such a penalty when individual qualifications may evolve over time in response to the imposed penalizing policy. We identify scenarios where the penalty could hinder the natural attainment of equity within the population. Moreover, we propose certain conditions that can counteract this undesirable outcome, thus ensuring fairness.
On the Inductive Biases of Demographic Parity-based Fair Learning Algorithms
Feb 28, 2024



Fair supervised learning algorithms assigning labels with little dependence on a sensitive attribute have attracted great attention in the machine learning community. While the demographic parity (DP) notion has been frequently used to measure a model's fairness in training fair classifiers, several studies in the literature suggest potential impacts of enforcing DP in fair learning algorithms. In this work, we analytically study the effect of standard DP-based regularization methods on the conditional distribution of the predicted label given the sensitive attribute. Our analysis shows that an imbalanced training dataset with a non-uniform distribution of the sensitive attribute could lead to a classification rule biased toward the sensitive attribute outcome holding the majority of training data. To control such inductive biases in DP-based fair learning, we propose a sensitive attribute-based distributionally robust optimization (SA-DRO) method improving robustness against the marginal distribution of the sensitive attribute. Finally, we present several numerical results on the application of DP-based learning methods to standard centralized and distributed learning problems. The empirical findings support our theoretical results on the inductive biases in DP-based fair learning algorithms and the debiasing effects of the proposed SA-DRO method.
Supermodular f-divergences and bounds on lossy compression and generalization error with mutual f-information
Jun 27, 2022
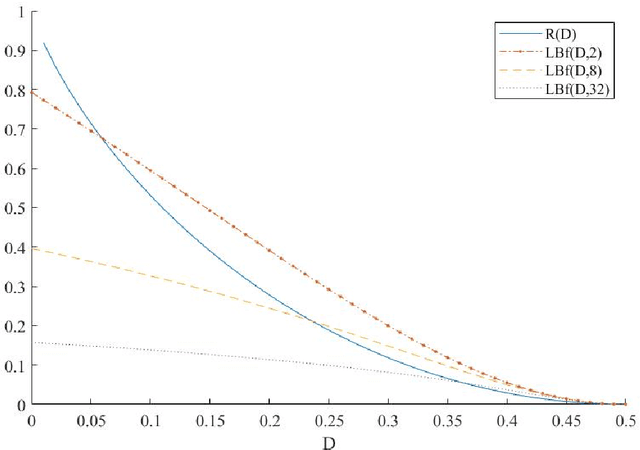
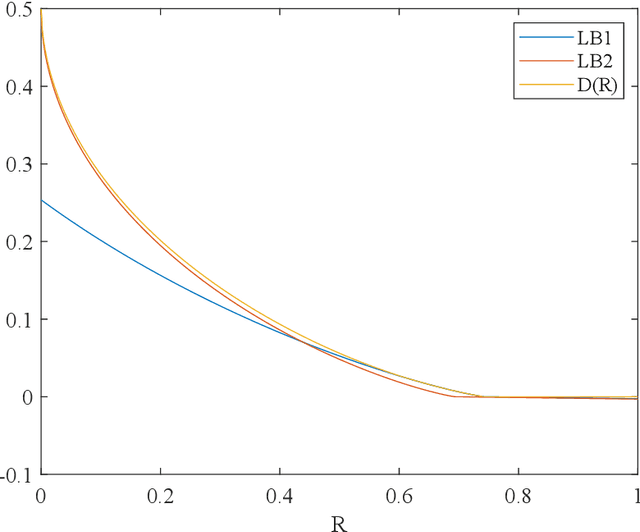
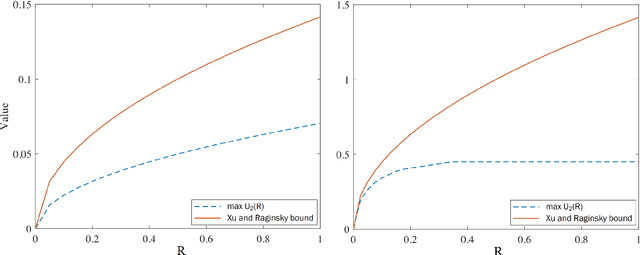
In this paper, we introduce super-modular $\mf$-divergences and provide three applications for them: (i) we introduce Sanov's upper bound on the tail probability of sum of independent random variables based on super-modular $\mf$-divergence and show that our generalized Sanov's bound strictly improves over ordinary one, (ii) we consider the lossy compression problem which studies the set of achievable rates for a given distortion and code length. We extend the rate-distortion function using mutual $\mf$-information and provide new and strictly better bounds on achievable rates in the finite blocklength regime using super-modular $\mf$-divergences, and (iii) we provide a connection between the generalization error of algorithms with bounded input/output mutual $\mf$-information and a generalized rate-distortion problem. This connection allows us to bound the generalization error of learning algorithms using lower bounds on the rate-distortion function. Our bound is based on a new lower bound on the rate-distortion function that (for some examples) strictly improves over previously best-known bounds. Moreover, super-modular $\mf$-divergences are utilized to reduce the dimension of the problem and obtain single-letter bounds.
Rate-Distortion Theoretic Generalization Bounds for Stochastic Learning Algorithms
Mar 04, 2022Understanding generalization in modern machine learning settings has been one of the major challenges in statistical learning theory. In this context, recent years have witnessed the development of various generalization bounds suggesting different complexity notions such as the mutual information between the data sample and the algorithm output, compressibility of the hypothesis space, and the fractal dimension of the hypothesis space. While these bounds have illuminated the problem at hand from different angles, their suggested complexity notions might appear seemingly unrelated, thereby restricting their high-level impact. In this study, we prove novel generalization bounds through the lens of rate-distortion theory, and explicitly relate the concepts of mutual information, compressibility, and fractal dimensions in a single mathematical framework. Our approach consists of (i) defining a generalized notion of compressibility by using source coding concepts, and (ii) showing that the `compression error rate' can be linked to the generalization error both in expectation and with high probability. We show that in the `lossless compression' setting, we recover and improve existing mutual information-based bounds, whereas a `lossy compression' scheme allows us to link generalization to the rate-distortion dimension -- a particular notion of fractal dimension. Our results bring a more unified perspective on generalization and open up several future research directions.