 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Perspective on Neural Capacity Estimation: Viability and Reliability
Mar 22, 2022
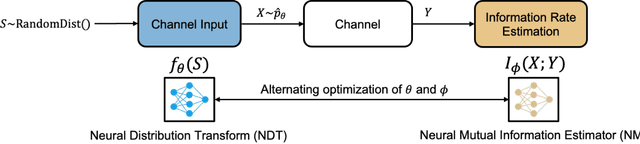
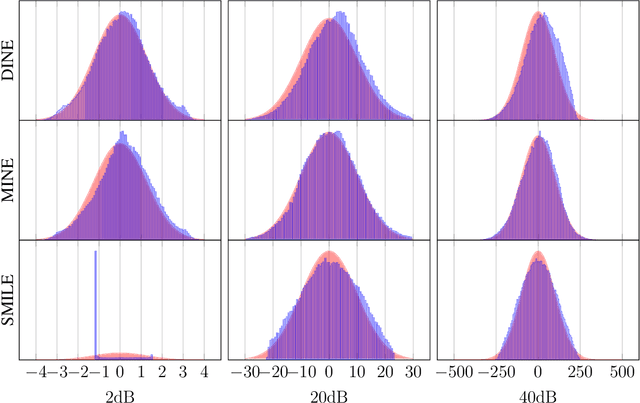
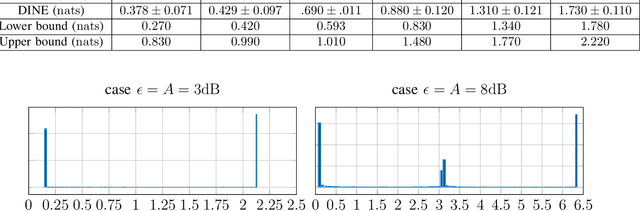
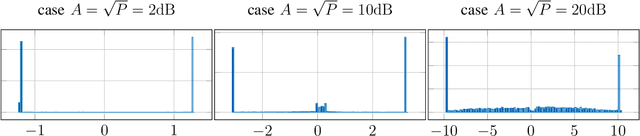
Recently, several methods have been proposed for estimating the mutual information from sample data using deep neural networks and without the knowledge of closed-form distribution of the data. This class of estimators is referred to as neural mutual information estimators (NMIE). In this paper, we investigate the performance of different NMIE proposed in the literature when applied to the capacity estimation problem. In particular, we study the performance of mutual information neural estimator (MINE), smoothed mutual information lower-bound estimator (SMILE), and directed information neural estimator (DINE). For the NMIE above, capacity estimation relies on two deep neural networks (DNN): (i) one DNN generates samples from a distribution that is learned, and (ii) a DNN to estimate the MI between the channel input and the channel output. We benchmark these NMIE in three scenarios: (i) AWGN channel capacity estimation and (ii) channels with unknown capacity and continuous inputs i.e., optical intensity and peak-power constrained AWGN channel (iii) channels with unknown capacity and a discrete number of mass points i.e., Poisson channel. Additionally, we also (iv) consider the extension to the MAC capacity problem by considering the AWGN and optical MAC models.
On the safe use of prior densities for Bayesian model selection
Jun 10, 2022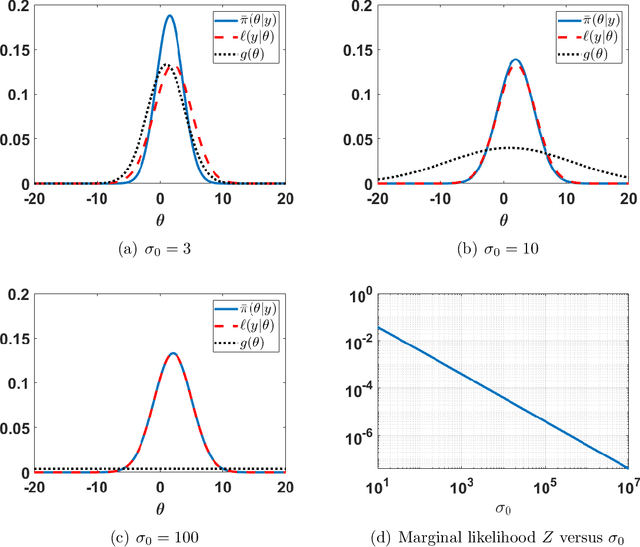


The application of Bayesian inference for the purpose of model selection is very popular nowadays. In this framework, models are compared through their marginal likelihoods, or their quotients, called Bayes factors. However, marginal likelihoods depends on the prior choice. For model selection, even diffuse priors can be actually very informative, unlike for the parameter estimation problem. Furthermore, when the prior is improper, the marginal likelihood of the corresponding model is undetermined. In this work, we discuss the issue of prior sensitivity of the marginal likelihood and its role in model selection. We also comment on the use of uninformative priors, which are very common choices in practice. Several practical suggestions are discussed and many possible solutions, proposed in the literature, to design objective priors for model selection are described. Some of them also allow the use of improper priors. The connection between the marginal likelihood approach and the well-known information criteria is also presented. We describe the main issues and possible solutions by illustrative numerical examples, providing also some related code. One of them involving a real-world application on exoplanet detection.
Additive Tensor Decomposition Considering Structural Data Information
Jul 27, 2020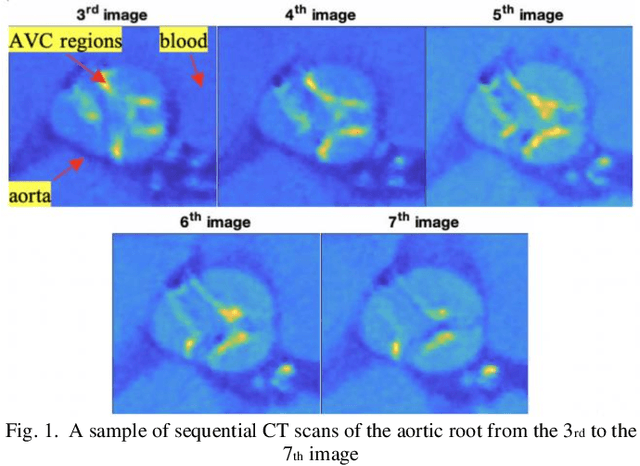
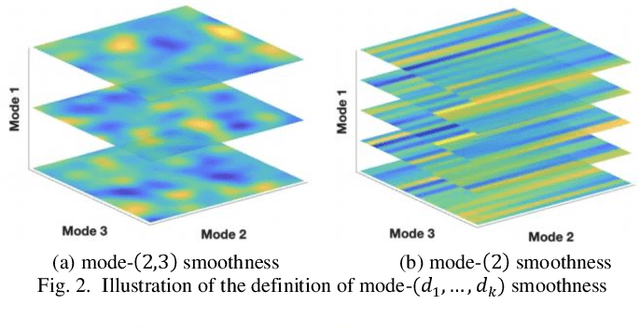

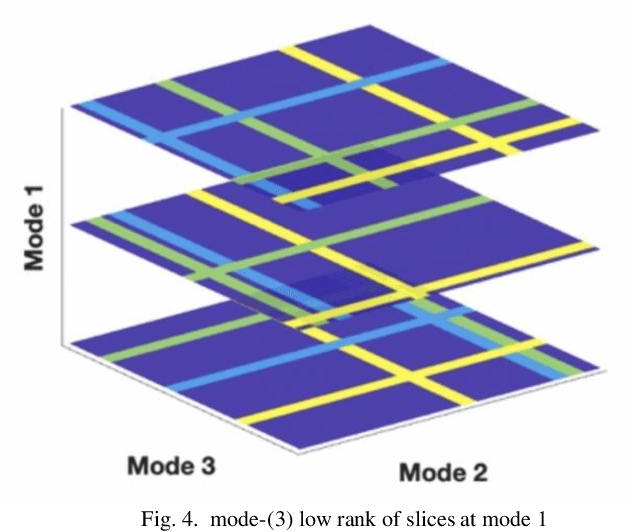
Tensor data with rich structural information becomes increasingly important in process modeling, monitoring, and diagnosis. Here structural information is referred to structural properties such as sparsity, smoothness, low-rank, and piecewise constancy. To reveal useful information from tensor data, we propose to decompose the tensor into the summation of multiple components based on different structural information of them. In this paper, we provide a new definition of structural information in tensor data. Based on it, we propose an additive tensor decomposition (ATD) framework to extract useful information from tensor data. This framework specifies a high dimensional optimization problem to obtain the components with distinct structural information. An alternating direction method of multipliers (ADMM) algorithm is proposed to solve it, which is highly parallelable and thus suitable for the proposed optimization problem. Two simulation examples and a real case study in medical image analysis illustrate the versatility and effectiveness of the ATD framework.
Stochastic Variance-Reduced Newton: Accelerating Finite-Sum Minimization with Large Batches
Jun 06, 2022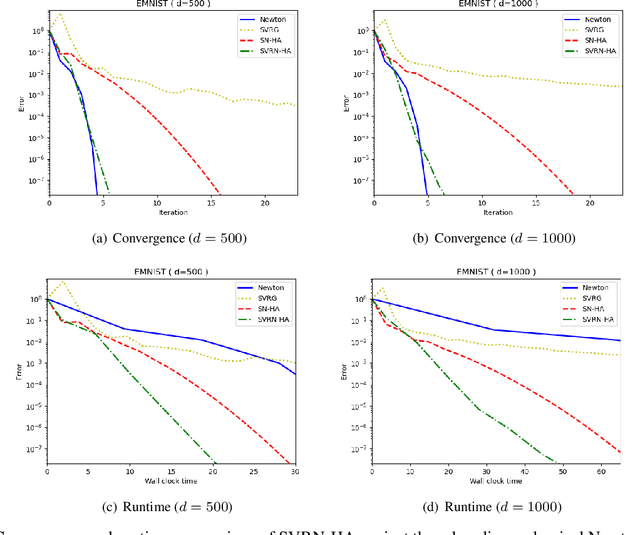
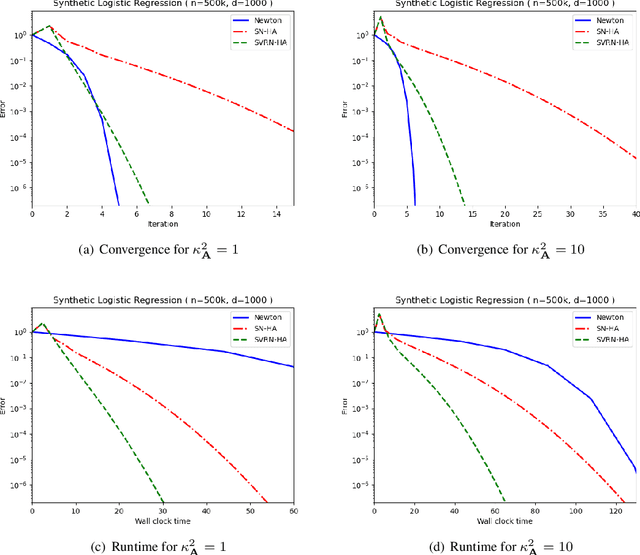
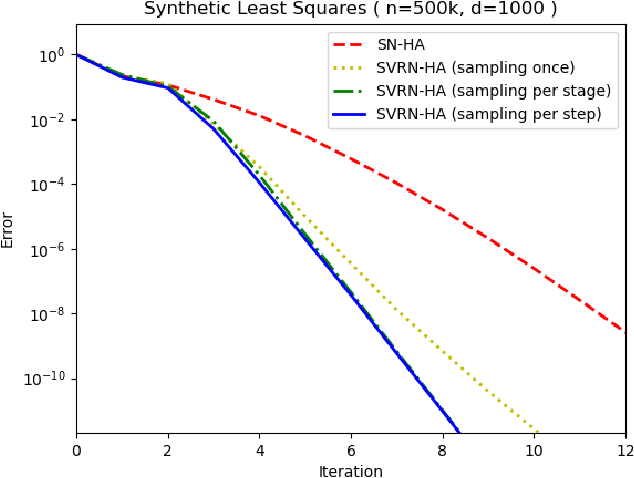
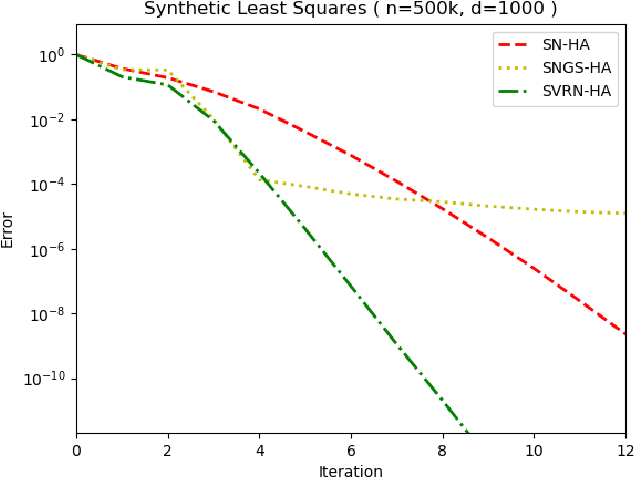
Stochastic variance reduction has proven effective at accelerating first-order algorithms for solving convex finite-sum optimization tasks such as empirical risk minimization. Incorporating additional second-order information has proven helpful in further improving the performance of these first-order methods. However, comparatively little is known about the benefits of using variance reduction to accelerate popular stochastic second-order methods such as Subsampled Newton. To address this, we propose Stochastic Variance-Reduced Newton (SVRN), a finite-sum minimization algorithm which enjoys all the benefits of second-order methods: simple unit step size, easily parallelizable large-batch operations, and fast local convergence, while at the same time taking advantage of variance reduction to achieve improved convergence rates (per data pass) for smooth and strongly convex problems. We show that SVRN can accelerate many stochastic second-order methods (such as Subsampled Newton) as well as iterative least squares solvers (such as Iterative Hessian Sketch), and it compares favorably to popular first-order methods with variance reduction.
MVMO: A Multi-Object Dataset for Wide Baseline Multi-View Semantic Segmentation
May 30, 2022
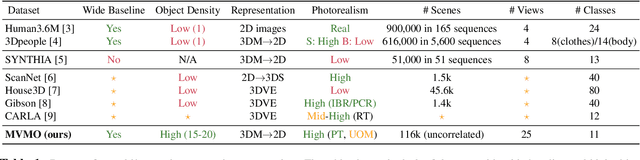
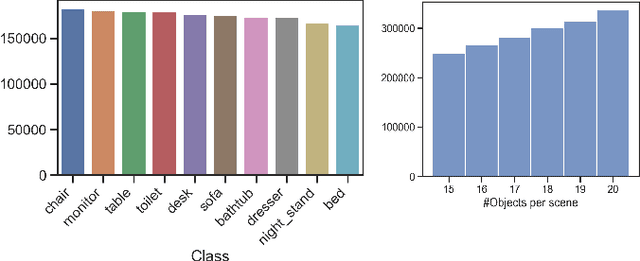
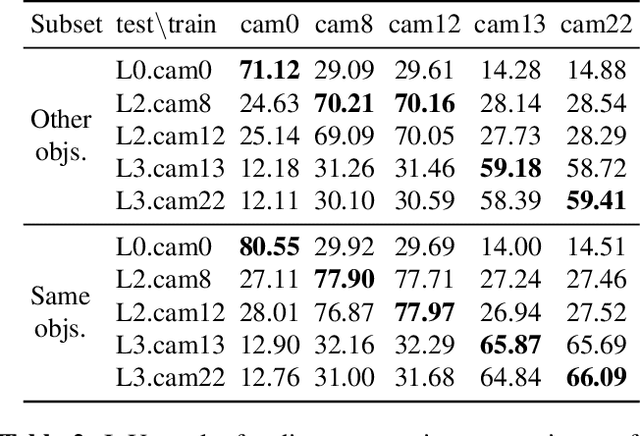
We present MVMO (Multi-View, Multi-Object dataset): a synthetic dataset of 116,000 scenes containing randomly placed objects of 10 distinct classes and captured from 25 camera locations in the upper hemisphere. MVMO comprises photorealistic, path-traced image renders, together with semantic segmentation ground truth for every view. Unlike existing multi-view datasets, MVMO features wide baselines between cameras and high density of objects, which lead to large disparities, heavy occlusions and view-dependent object appearance. Single view semantic segmentation is hindered by self and inter-object occlusions that could benefit from additional viewpoints. Therefore, we expect that MVMO will propel research in multi-view semantic segmentation and cross-view semantic transfer. We also provide baselines that show that new research is needed in such fields to exploit the complementary information of multi-view setups.
Distributionally Robust End-to-End Portfolio Construction
Jun 10, 2022
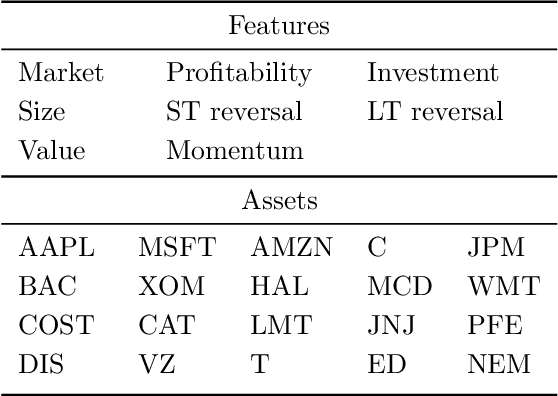
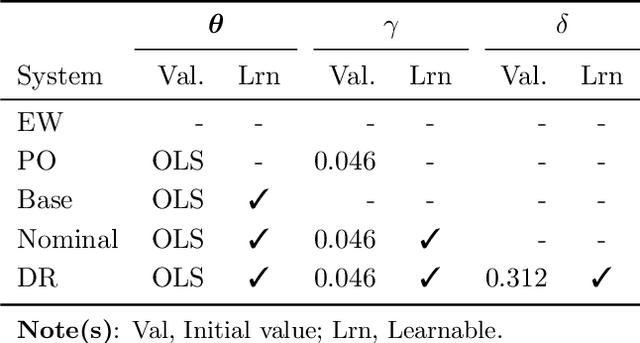
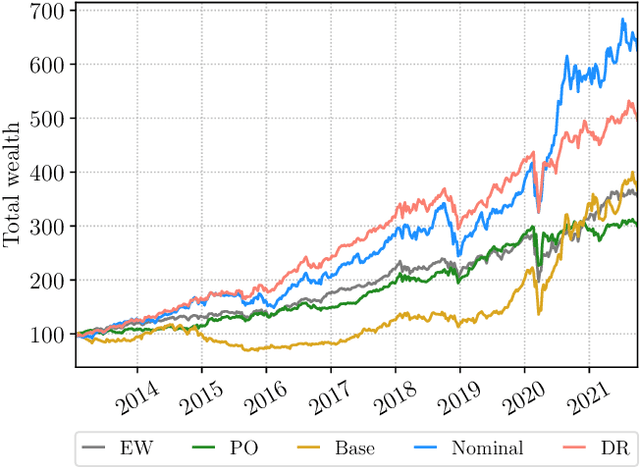
We propose an end-to-end distributionally robust system for portfolio construction that integrates the asset return prediction model with a distributionally robust portfolio optimization model. We also show how to learn the risk-tolerance parameter and the degree of robustness directly from data. End-to-end systems have an advantage in that information can be communicated between the prediction and decision layers during training, allowing the parameters to be trained for the final task rather than solely for predictive performance. However, existing end-to-end systems are not able to quantify and correct for the impact of model risk on the decision layer. Our proposed distributionally robust end-to-end portfolio selection system explicitly accounts for the impact of model risk. The decision layer chooses portfolios by solving a minimax problem where the distribution of the asset returns is assumed to belong to an ambiguity set centered around a nominal distribution. Using convex duality, we recast the minimax problem in a form that allows for efficient training of the end-to-end system.
Open ERP System Data For Occupational Fraud Detection
Jun 10, 2022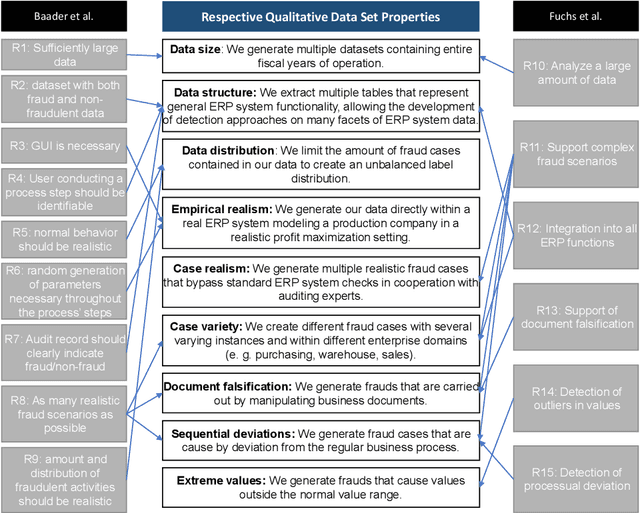

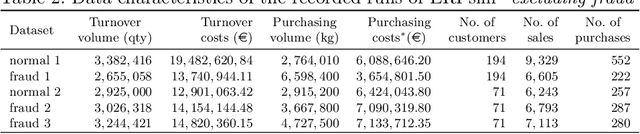
Recent estimates report that companies lose 5% of their revenue to occupational fraud. Since most medium-sized and large companies employ Enterprise Resource Planning (ERP) systems to track vast amounts of information regarding their business process, researchers have in the past shown interest in automatically detecting fraud through ERP system data. Current research in this area, however, is hindered by the fact that ERP system data is not publicly available for the development and comparison of fraud detection methods. We therefore endeavour to generate public ERP system data that includes both normal business operation and fraud. We propose a strategy for generating ERP system data through a serious game, model a variety of fraud scenarios in cooperation with auditing experts, and generate data from a simulated make-to-stock production company with multiple research participants. We aggregate the generated data into ready to used datasets for fraud detection in ERP systems, and supply both the raw and aggregated data to the general public to allow for open development and comparison of fraud detection approaches on ERP system data.
What do End-to-End Speech Models Learn about Speaker, Language and Channel Information? A Layer-wise and Neuron-level Analysis
Jul 01, 2021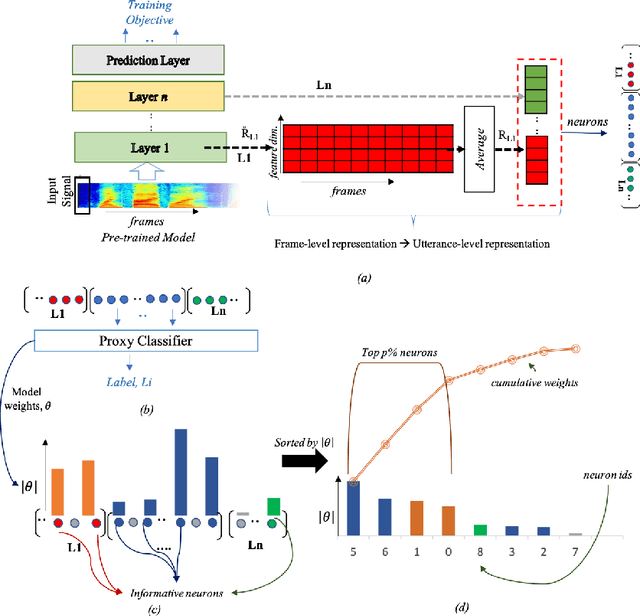
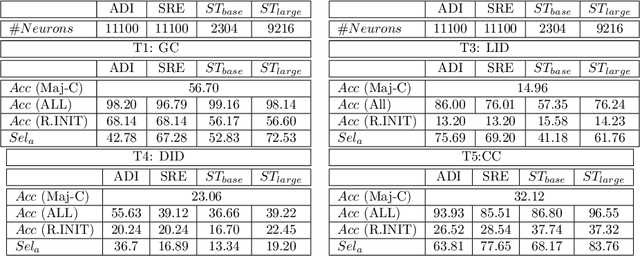
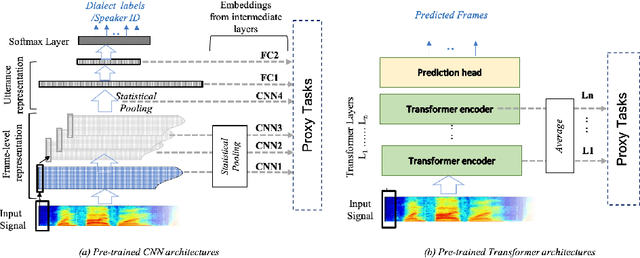
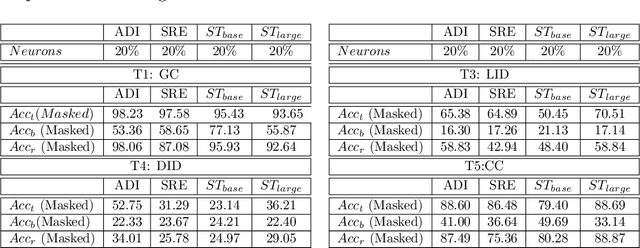
End-to-end DNN architectures have pushed the state-of-the-art in speech technologies, as well as in other spheres of AI, leading researchers to train more complex and deeper models. These improvements came at the cost of transparency. DNNs are innately opaque and difficult to interpret. We no longer understand what features are learned, where they are preserved, and how they inter-operate. Such an analysis is important for better model understanding, debugging and to ensure fairness in ethical decision making. In this work, we analyze the representations trained within deep speech models, towards the task of speaker recognition, dialect identification and reconstruction of masked signals. We carry a layer- and neuron-level analysis on the utterance-level representations captured within pretrained speech models for speaker, language and channel properties. We study: is this information captured in the learned representations? where is it preserved? how is it distributed? and can we identify a minimal subset of network that posses this information. Using diagnostic classifiers, we answered these questions. Our results reveal: (i) channel and gender information is omnipresent and is redundantly distributed (ii) complex properties such as dialectal information is encoded only in the task-oriented pretrained network and is localised in the upper layers (iii) a minimal subset of neurons can be extracted to encode the predefined property (iv) salient neurons are sometimes shared between properties and can highlights presence of biases in the network. Our cross-architectural comparison indicates that (v) the pretrained models captures speaker-invariant information and (vi) the pretrained CNNs models are competitive to the Transformers for encoding information for the studied properties. To the best of our knowledge, this is the first study to investigate neuron analysis on the speech models.
Distributed Transition Systems with Tags for Privacy Analysis
Apr 06, 2022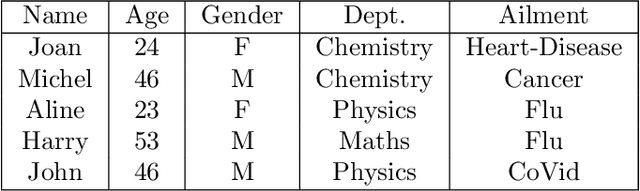
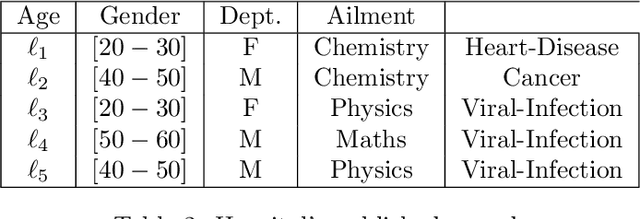

We present a logical framework that formally models how a given private information P stored on a given database D, can get captured progressively, by an agent/adversary querying the database repeatedly.Named DLTTS (Distributed Labeled Tagged Transition System), the frame-work borrows ideas from several domains: Probabilistic Automata of Segala, Probabilistic Concurrent Systems, and Probabilistic labelled transition systems. To every node on a DLTTS is attached a tag that represents the 'current' knowledge of the adversary, acquired from the responses of the answering mechanism of the DBMS to his/her queries, at the nodes traversed earlier, along any given run; this knowledge is completed at the same node, with further relational deductions, possibly in combination with 'public' information from other databases given in advance. A 'blackbox' mechanism is also part of a DLTTS, and it is meant as an oracle; its role is to tell if the private information has been deduced by the adversary at the current node, and if so terminate the run. An additional special feature is that the blackbox also gives information on how 'close',or how 'far', the knowledge of the adversary is, from the private information P , at the current node. A metric is defined for that purpose, on the set of all 'type compatible' tuples from the given database, the data themselves being typed with the headers of the base. Despite the transition systems flavor of our framework, this metric is not 'behavioral' in the sense presented in some other works. It is exclusively database oriented,and allows to define new notions of adjacency and of -indistinguishabilty between databases, more generally than those usually based on the Hamming metric (and a restricted notion of adjacency). Examples are given all along to illustrate how our framework works. Keywords:Database, Privacy, Transition System, Probability, Distribution.
Feature Learning and Ensemble Pre-Tasks Based Self-Supervised Speech Denoising and Dereverberation
Jun 10, 2022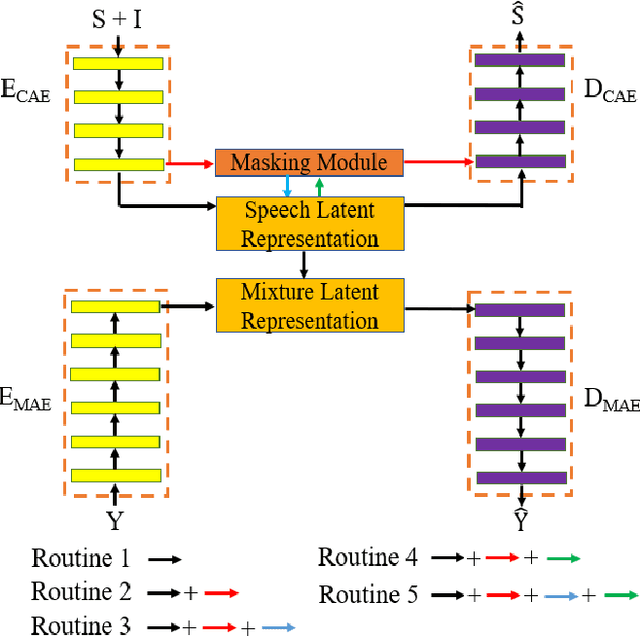
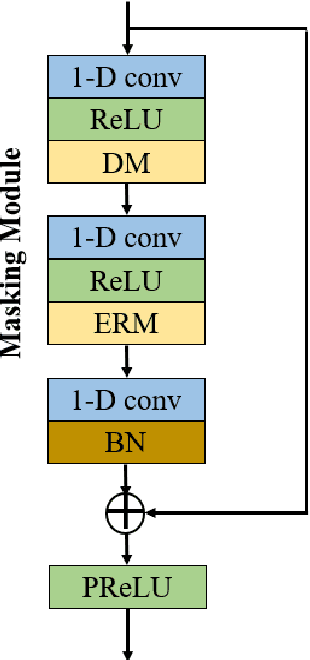
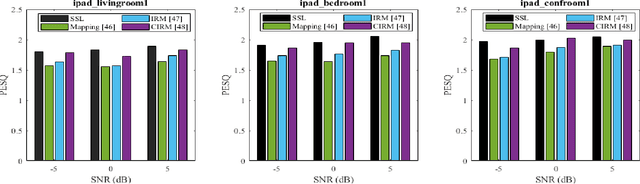
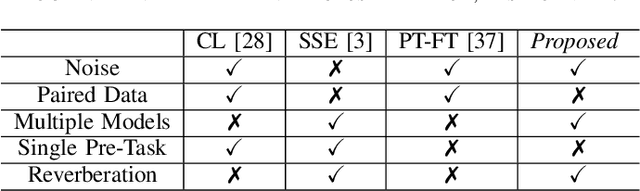
Self-supervised learning (SSL) achieves great success in monaural speech enhancement, while the accuracy of the target speech estimation, particularly for unseen speakers, remains inadequate with existing pre-tasks. As speech signal contains multi-faceted information including speaker identity, paralinguistics, and spoken content, the latent representation for speech enhancement becomes a tough task. In this paper, we study the effectiveness of each feature which is commonly used in speech enhancement and exploit the feature combination in the SSL case. Besides, we propose an ensemble training strategy. The latent representation of the clean speech signal is learned, meanwhile, the dereverberated mask and the estimated ratio mask are exploited to denoise and dereverberate the mixture. The latent representation learning and the masks estimation are considered as two pre-tasks in the training stage. In addition, to study the effectiveness between the pre-tasks, we compare different training routines to train the model and further refine the performance. The NOISEX and DAPS corpora are used to evaluate the efficacy of the proposed method, which also outperforms the state-of-the-art methods.