 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the safe use of prior densities for Bayesian model selection
Jun 10, 2022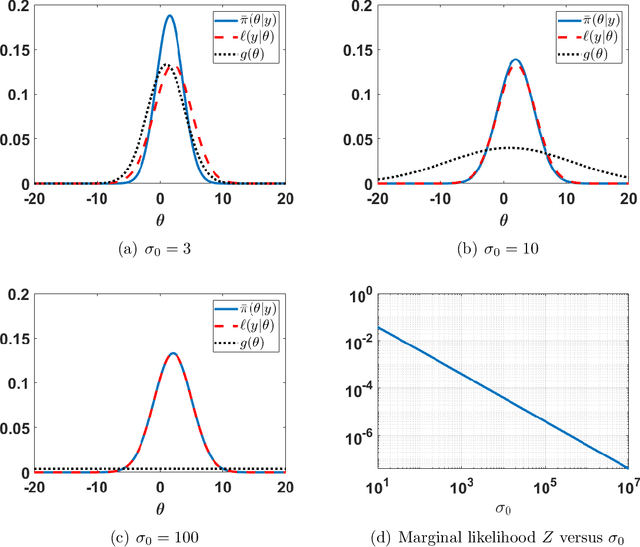


The application of Bayesian inference for the purpose of model selection is very popular nowadays. In this framework, models are compared through their marginal likelihoods, or their quotients, called Bayes factors. However, marginal likelihoods depends on the prior choice. For model selection, even diffuse priors can be actually very informative, unlike for the parameter estimation problem. Furthermore, when the prior is improper, the marginal likelihood of the corresponding model is undetermined. In this work, we discuss the issue of prior sensitivity of the marginal likelihood and its role in model selection. We also comment on the use of uninformative priors, which are very common choices in practice. Several practical suggestions are discussed and many possible solutions, proposed in the literature, to design objective priors for model selection are described. Some of them also allow the use of improper priors. The connection between the marginal likelihood approach and the well-known information criteria is also presented. We describe the main issues and possible solutions by illustrative numerical examples, providing also some related code. One of them involving a real-world application on exoplanet detection.
A survey of Monte Carlo methods for noisy and costly densities with application to reinforcement learning
Aug 01, 2021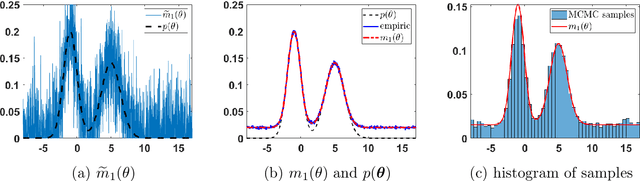
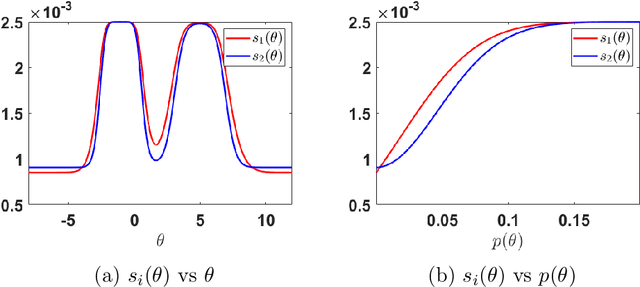
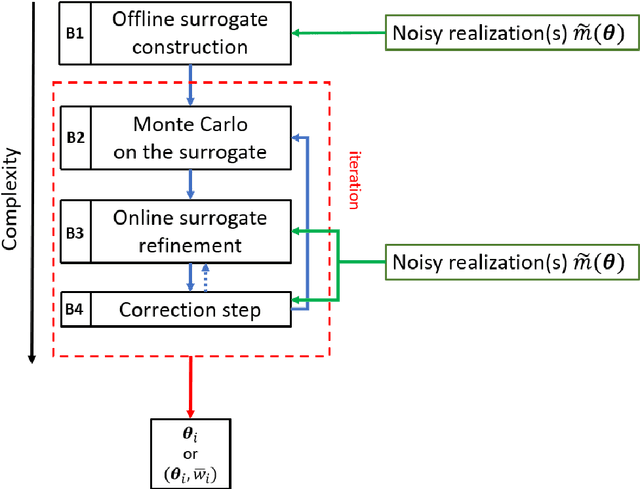

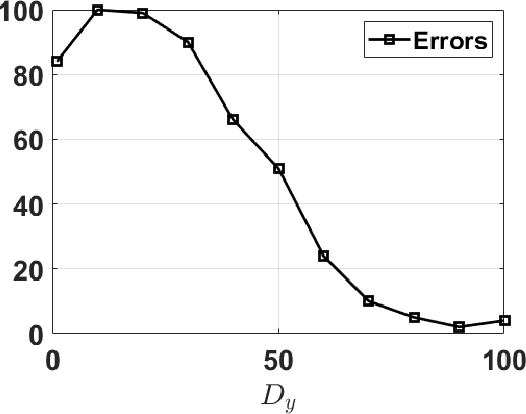
This survey gives an overview of Monte Carlo methodologies using surrogate models, for dealing with densities which are intractable, costly, and/or noisy. This type of problem can be found in numerous real-world scenarios, including stochastic optimization and reinforcement learning, where each evaluation of a density function may incur some computationally-expensive or even physical (real-world activity) cost, likely to give different results each time. The surrogate model does not incur this cost, but there are important trade-offs and considerations involved in the choice and design of such methodologies. We classify the different methodologies into three main classes and describe specific instances of algorithms under a unified notation. A modular scheme which encompasses the considered methods is also presented. A range of application scenarios is discussed, with special attention to the likelihood-free setting and reinforcement learning. Several numerical comparisons are also provided.
MCMC-driven importance samplers
May 09, 2021

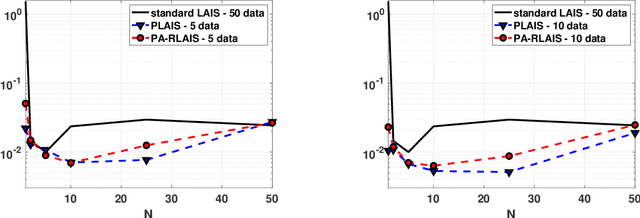
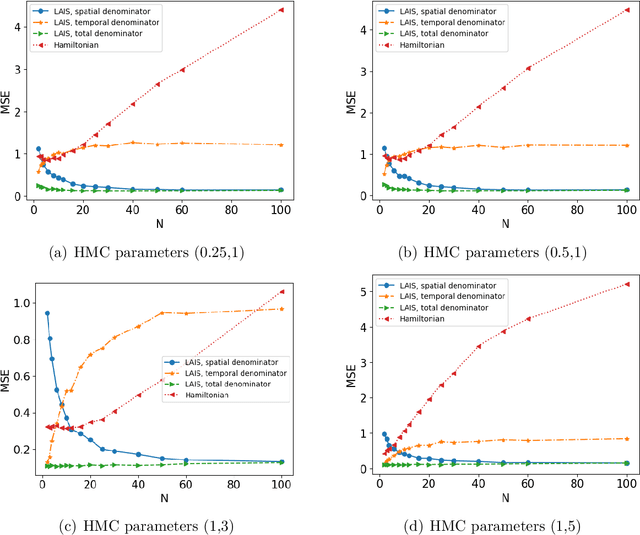
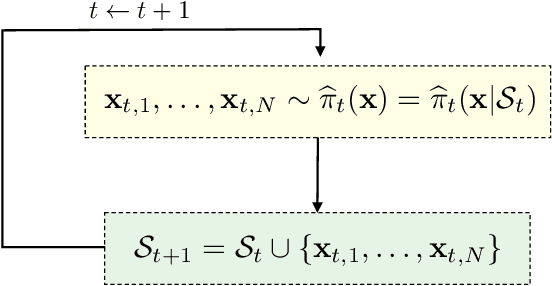
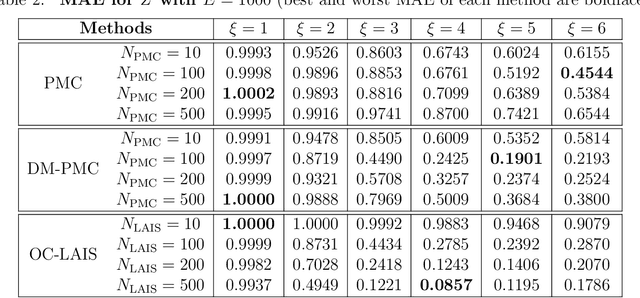
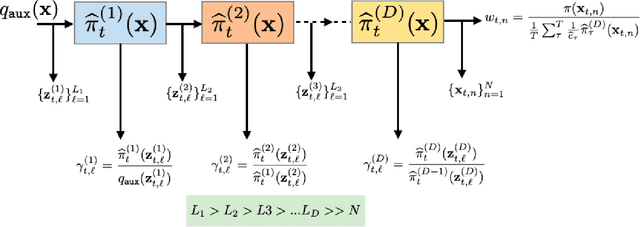
Monte Carlo methods are the standard procedure for estimating complicated integrals of multidimensional Bayesian posterior distributions. In this work, we focus on LAIS, a class of adaptive importance samplers where Markov chain Monte Carlo (MCMC) algorithms are employed to drive an underlying multiple importance sampling (IS) scheme. Its power lies in the simplicity of the layered framework: the upper layer locates proposal densities by means of MCMC algorithms; while the lower layer handles the multiple IS scheme, in order to compute the final estimators. The modular nature of LAIS allows for different possible choices in the upper and lower layers, that will have different performance and computational costs. In this work, we propose different enhancements in order to increase the efficiency and reduce the computational cost, of both upper and lower layers. The different variants are essential if we aim to address computational challenges arising in real-world applications, such as highly concentrated posterior distributions (due to large amounts of data, etc.). Hamiltonian-driven importance samplers are presented and tested. Furthermore, we introduce different strategies for designing cheaper schemes, for instance, recycling samples generated in the upper layer and using them in the final estimators in the lower layer. Numerical experiments show the benefits of the proposed schemes as compared to the vanilla version of LAIS and other benchmark methods.
Deep Importance Sampling based on Regression for Model Inversion and Emulation
Oct 20, 2020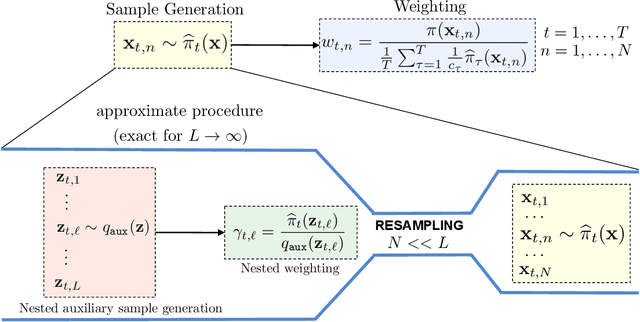
Understanding systems by forward and inverse modeling is a recurrent topic of research in many domains of science and engineering. In this context, Monte Carlo methods have been widely used as powerful tools for numerical inference and optimization. They require the choice of a suitable proposal density that is crucial for their performance. For this reason, several adaptive importance sampling (AIS) schemes have been proposed in the literature. We here present an AIS framework called Regression-based Adaptive Deep Importance Sampling (RADIS). In RADIS, the key idea is the adaptive construction via regression of a non-parametric proposal density (i.e., an emulator), which mimics the posterior distribution and hence minimizes the mismatch between proposal and target densities. RADIS is based on a deep architecture of two (or more) nested IS schemes, in order to draw samples from the constructed emulator. The algorithm is highly efficient since employs the posterior approximation as proposal density, which can be improved adding more support points. As a consequence, RADIS asymptotically converges to an exact sampler under mild conditions. Additionally, the emulator produced by RADIS can be in turn used as a cheap surrogate model for further studies. We introduce two specific RADIS implementations that use Gaussian Processes (GPs) and Nearest Neighbors (NN) for constructing the emulator. Several numerical experiments and comparisons show the benefits of the proposed schemes. A real-world application in remote sensing model inversion and emulation confirms the validity of the approach.
Adaptive quadrature schemes for Bayesian inference via active learning
Jun 03, 2020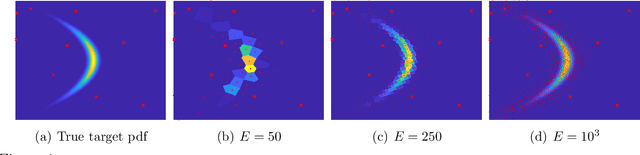
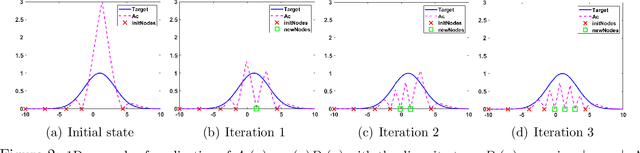
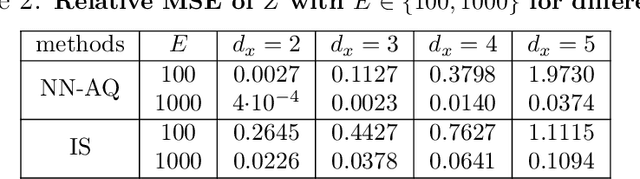
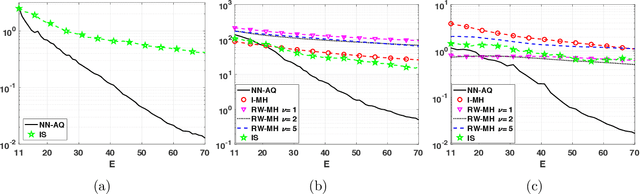
Numerical integration and emulation are fundamental topics across scientific fields. We propose novel adaptive quadrature schemes based on an active learning procedure. We consider an interpolative approach for building a surrogate posterior density, combining it with Monte Carlo sampling methods and other quadrature rules. The nodes of the quadrature are sequentially chosen by maximizing a suitable acquisition function, which takes into account the current approximation of the posterior and the positions of the nodes. This maximization does not require additional evaluations of the true posterior. We introduce two specific schemes based on Gaussian and Nearest Neighbors (NN) bases. For the Gaussian case, we also provide a novel procedure for fitting the bandwidth parameter, in order to build a suitable emulator of a density function. With both techniques, we always obtain a positive estimation of the marginal likelihood (a.k.a., Bayesian evidence). An equivalent importance sampling interpretation is also described, which allows the design of extended schemes. Several theoretical results are provided and discussed. Numerical results show the advantage of the proposed approach, including a challenging inference problem in an astronomic dynamical model, with the goal of revealing the number of planets orbiting a star.