 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn automatic counting algorithm for the quantification and uncertainty analysis of the number of microglial cells trainable in small and heterogeneous datasets
Feb 26, 2026Counting immunopositive cells on biological tissues generally requires either manual annotation or (when available) automatic rough systems, for scanning signal surface and intensity in whole slide imaging. In this work, we tackle the problem of counting microglial cells in lumbar spinal cord cross-sections of rats by omitting cell detection and focusing only on the counting task. Manual cell counting is, however, a time-consuming task and additionally entails extensive personnel training. The classic automatic color-based methods roughly inform about the total labeled area and intensity (protein quantification) but do not specifically provide information on cell number. Since the images to be analyzed have a high resolution but a huge amount of pixels contain just noise or artifacts, we first perform a pre-processing generating several filtered images {(providing a tailored, efficient feature extraction)}. Then, we design an automatic kernel counter that is a non-parametric and non-linear method. The proposed scheme can be easily trained in small datasets since, in its basic version, it relies only on one hyper-parameter. However, being non-parametric and non-linear, the proposed algorithm is flexible enough to express all the information contained in rich and heterogeneous datasets as well (providing the maximum overfit if required). Furthermore, the proposed kernel counter also provides uncertainty estimation of the given prediction, and can directly tackle the case of receiving several expert opinions over the same image. Different numerical experiments with artificial and real datasets show very promising results. Related Matlab code is also provided.
Adaptive posterior distributions for uncertainty analysis of covariance matrices in Bayesian inversion problems for multioutput signals
Jan 02, 2025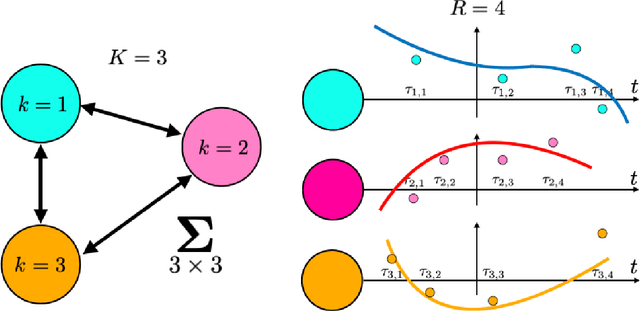

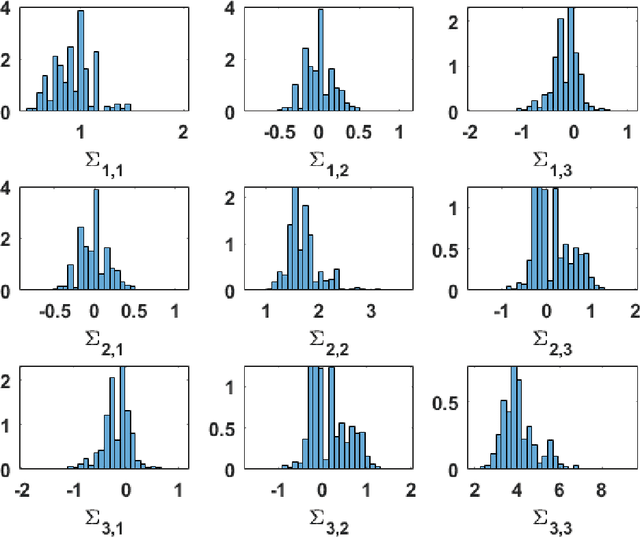
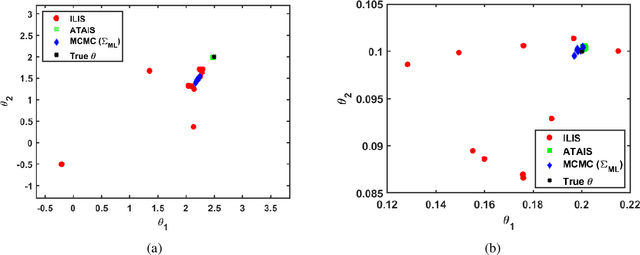
In this paper we address the problem of performing Bayesian inference for the parameters of a nonlinear multi-output model and the covariance matrix of the different output signals. We propose an adaptive importance sampling (AIS) scheme for multivariate Bayesian inversion problems, which is based in two main ideas: the variables of interest are split in two blocks and the inference takes advantage of known analytical optimization formulas. We estimate both the unknown parameters of the multivariate non-linear model and the covariance matrix of the noise. In the first part of the proposed inference scheme, a novel AIS technique called adaptive target adaptive importance sampling (ATAIS) is designed, which alternates iteratively between an IS technique over the parameters of the non-linear model and a frequentist approach for the covariance matrix of the noise. In the second part of the proposed inference scheme, a prior density over the covariance matrix is considered and the cloud of samples obtained by ATAIS are recycled and re-weighted to obtain a complete Bayesian study over the model parameters and covariance matrix. ATAIS is the main contribution of the work. Additionally, the inverted layered importance sampling (ILIS) is presented as a possible compelling algorithm (but based on a conceptually simpler idea). Different numerical examples show the benefits of the proposed approaches
On the safe use of prior densities for Bayesian model selection
Jun 10, 2022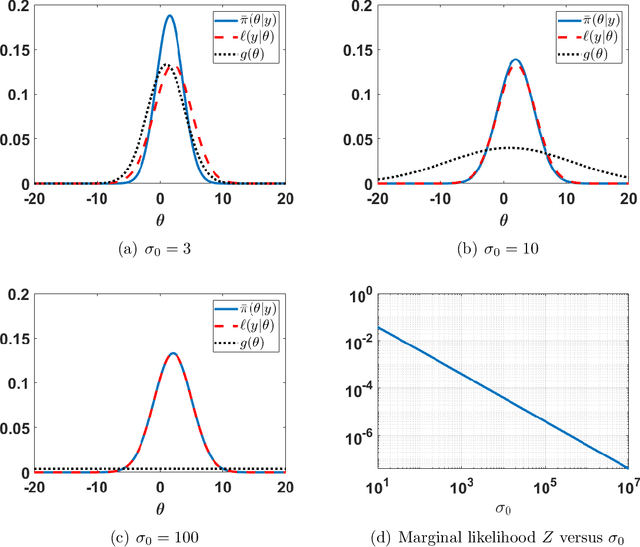


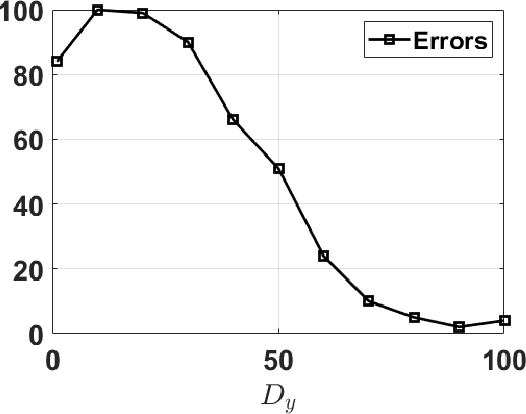
The application of Bayesian inference for the purpose of model selection is very popular nowadays. In this framework, models are compared through their marginal likelihoods, or their quotients, called Bayes factors. However, marginal likelihoods depends on the prior choice. For model selection, even diffuse priors can be actually very informative, unlike for the parameter estimation problem. Furthermore, when the prior is improper, the marginal likelihood of the corresponding model is undetermined. In this work, we discuss the issue of prior sensitivity of the marginal likelihood and its role in model selection. We also comment on the use of uninformative priors, which are very common choices in practice. Several practical suggestions are discussed and many possible solutions, proposed in the literature, to design objective priors for model selection are described. Some of them also allow the use of improper priors. The connection between the marginal likelihood approach and the well-known information criteria is also presented. We describe the main issues and possible solutions by illustrative numerical examples, providing also some related code. One of them involving a real-world application on exoplanet detection.
Automatic tempered posterior distributions for Bayesian inversion problems
Jul 24, 2021
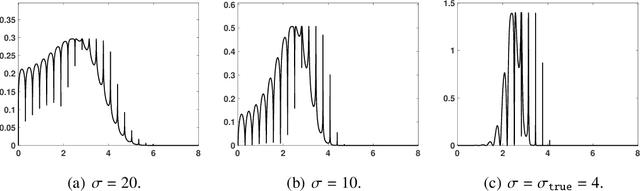

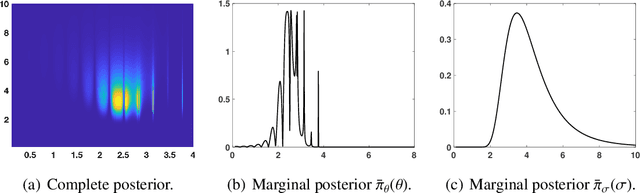
We propose a novel adaptive importance sampling scheme for Bayesian inversion problems where the inference of the variables of interest and the power of the data noise is split. More specifically, we consider a Bayesian analysis for the variables of interest (i.e., the parameters of the model to invert), whereas we employ a maximum likelihood approach for the estimation of the noise power. The whole technique is implemented by means of an iterative procedure, alternating sampling and optimization steps. Moreover, the noise power is also used as a tempered parameter for the posterior distribution of the the variables of interest. Therefore, a sequence of tempered posterior densities is generated, where the tempered parameter is automatically selected according to the actual estimation of the noise power. A complete Bayesian study over the model parameters and the scale parameter can be also performed. Numerical experiments show the benefits of the proposed approach.
MCMC-driven importance samplers
May 09, 2021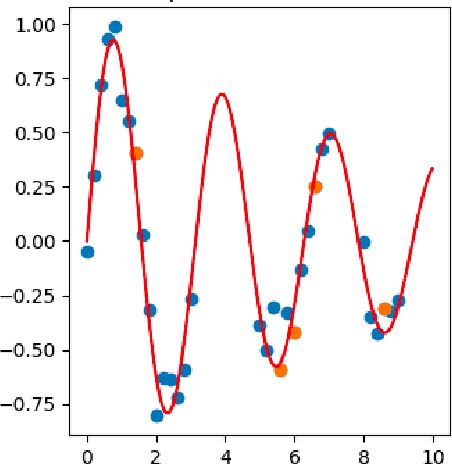

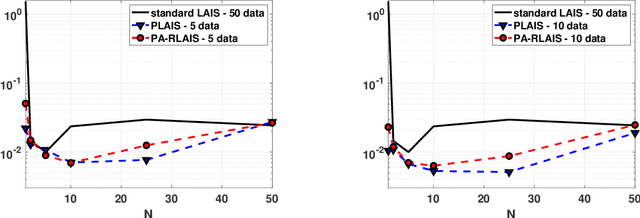
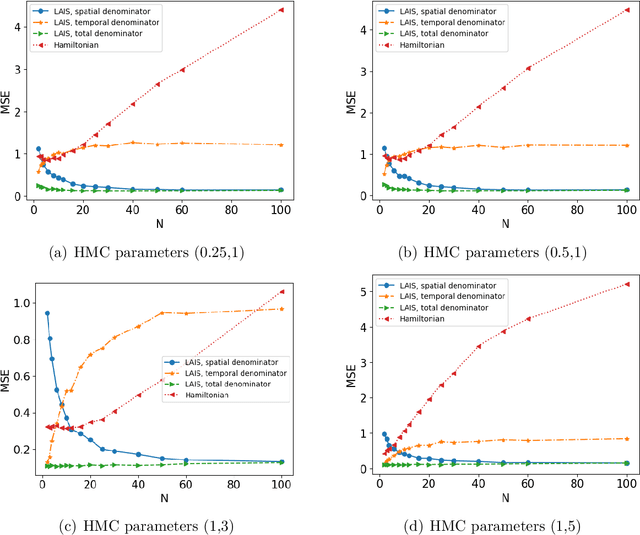
Monte Carlo methods are the standard procedure for estimating complicated integrals of multidimensional Bayesian posterior distributions. In this work, we focus on LAIS, a class of adaptive importance samplers where Markov chain Monte Carlo (MCMC) algorithms are employed to drive an underlying multiple importance sampling (IS) scheme. Its power lies in the simplicity of the layered framework: the upper layer locates proposal densities by means of MCMC algorithms; while the lower layer handles the multiple IS scheme, in order to compute the final estimators. The modular nature of LAIS allows for different possible choices in the upper and lower layers, that will have different performance and computational costs. In this work, we propose different enhancements in order to increase the efficiency and reduce the computational cost, of both upper and lower layers. The different variants are essential if we aim to address computational challenges arising in real-world applications, such as highly concentrated posterior distributions (due to large amounts of data, etc.). Hamiltonian-driven importance samplers are presented and tested. Furthermore, we introduce different strategies for designing cheaper schemes, for instance, recycling samples generated in the upper layer and using them in the final estimators in the lower layer. Numerical experiments show the benefits of the proposed schemes as compared to the vanilla version of LAIS and other benchmark methods.