 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Integrating Sensing, Computing, and Communication in 6G Wireless Networks: Design and Optimization
Jul 08, 2022
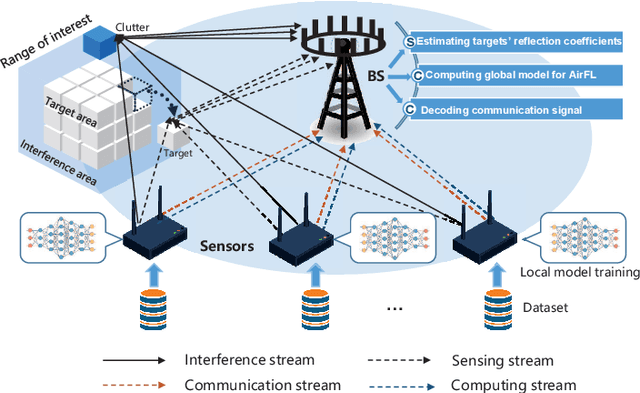
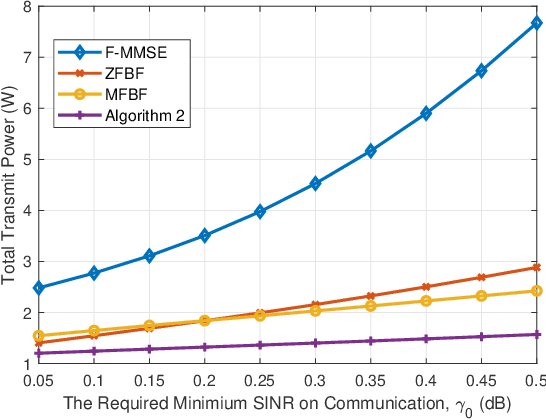
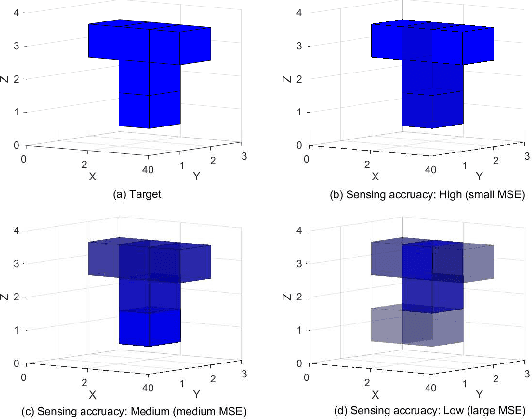
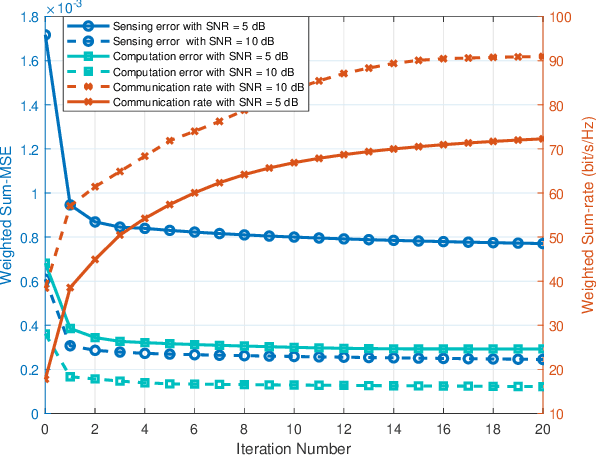
The roll-out of various emerging wireless services has triggered the need for the sixth-generation (6G) wireless networks to provide functions of target sensing, intelligent computing and information communication over the same radio spectrum. In this paper, we provide a unified framework integrating sensing, computing, and communication to optimize limited system resource for 6G wireless networks. In particular, two typical joint beamforming design algorithms are derived based on multi-objective optimization problems (MOOP) with the goals of the weighted overall performance maximization and the total transmit power minimization, respectively. Extensive simulation results validate the effectiveness of the proposed algorithms. Moreover, the impacts of key system parameters are revealed to provide useful insights for the design of integrated sensing, computing, and communication (ISCC).
Taking snapshots from a stream
Jun 23, 2022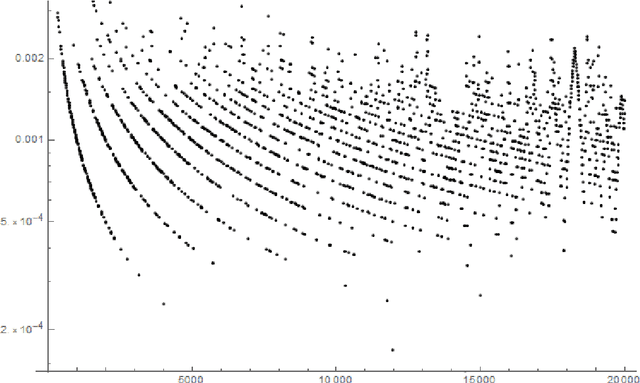
This work is devoted to a certain class of probabilistic snapshots for elements of the observed data stream. We show you how one can control their probabilistic properties and we show some potential applications. Our solution can be used to store information from the observed history with limited memory. It can be used for both web server applications and Ad hoc networks and, for example, for automatic taking snapshots from video stream online of unknown size.
Clustering Object-Centric Event Logs
Jul 26, 2022



Process mining provides various algorithms to analyze process executions based on event data. Process discovery, the most prominent category of process mining techniques, aims to discover process models from event logs, however, it leads to spaghetti models when working with real-life data. Therefore, several clustering techniques have been proposed on top of traditional event logs (i.e., event logs with a single case notion) to reduce the complexity of process models and discover homogeneous subsets of cases. Nevertheless, in real-life processes, particularly in the context of Business-to-Business (B2B) processes, multiple objects are involved in a process. Recently, Object-Centric Event Logs (OCELs) have been introduced to capture the information of such processes, and several process discovery techniques have been developed on top of OCELs. Yet, the output of the proposed discovery techniques on real OCELs leads to more informative but also more complex models. In this paper, we propose a clustering-based approach to cluster similar objects in OCELs to simplify the obtained process models. Using a case study of a real B2B process, we demonstrate that our approach reduces the complexity of the process models and generates coherent subsets of objects which help the end-users gain insights into the process.
Generative Steganography Network
Jul 29, 2022
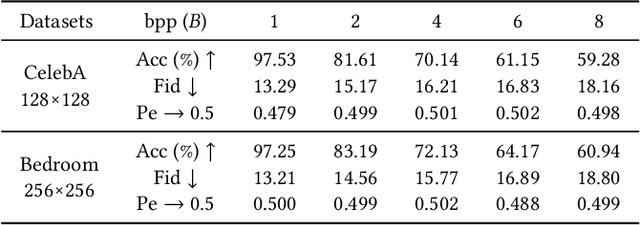
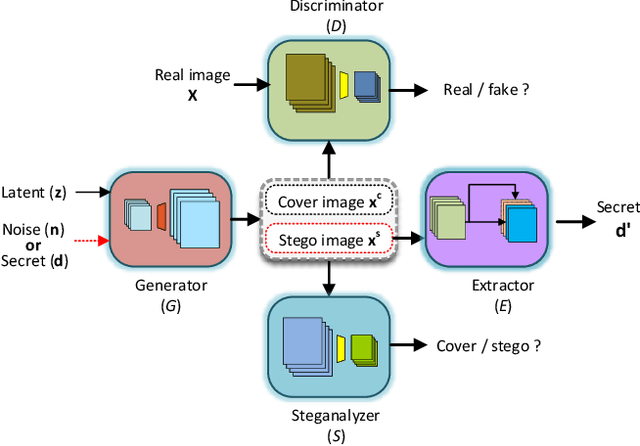
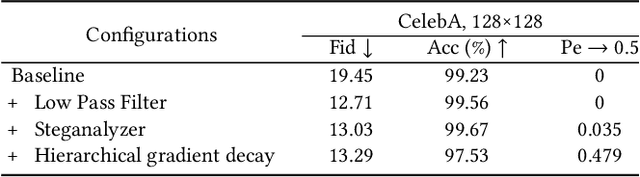
Steganography usually modifies cover media to embed secret data. A new steganographic approach called generative steganography (GS) has emerged recently, in which stego images (images containing secret data) are generated from secret data directly without cover media. However, existing GS schemes are often criticized for their poor performances. In this paper, we propose an advanced generative steganography network (GSN) that can generate realistic stego images without using cover images, in which mutual information is firstly introduced in stego image generation. Our model contains four sub-networks, i.e., an image generator ($G$), a discriminator ($D$), a steganalyzer ($S$), and a data extractor ($E$). $D$ and $S$ act as two adversarial discriminators to ensure the visual and statistical imperceptibility of generated stego images. $E$ is to extract the hidden secret from generated stego images. The generator $G$ is flexibly constructed to synthesize either cover or stego images with different inputs. It facilitates covert communication by hiding the function of generating stego images in a normal image generator. A module named secret block is designed delicately to conceal secret data in the feature maps during image generation, with which high hiding capacity and image fidelity are achieved. In addition, a novel hierarchical gradient decay skill is developed to resist steganalysis detection. Experiments demonstrate the superiority of our work over existing methods.
Detection of ADHD based on Eye Movements during Natural Viewing
Jul 14, 2022

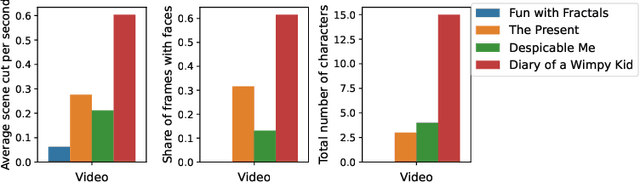
Attention-deficit/hyperactivity disorder (ADHD) is a neurodevelopmental disorder that is highly prevalent and requires clinical specialists to diagnose. It is known that an individual's viewing behavior, reflected in their eye movements, is directly related to attentional mechanisms and higher-order cognitive processes. We therefore explore whether ADHD can be detected based on recorded eye movements together with information about the video stimulus in a free-viewing task. To this end, we develop an end-to-end deep learning-based sequence model which we pre-train on a related task for which more data are available. We find that the method is in fact able to detect ADHD and outperforms relevant baselines. We investigate the relevance of the input features in an ablation study. Interestingly, we find that the model's performance is closely related to the content of the video, which provides insights for future experimental designs.
FETILDA: An Effective Framework For Fin-tuned Embeddings For Long Financial Text Documents
Jun 14, 2022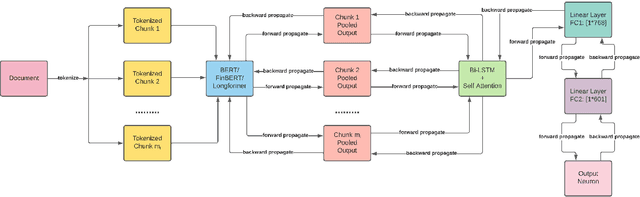
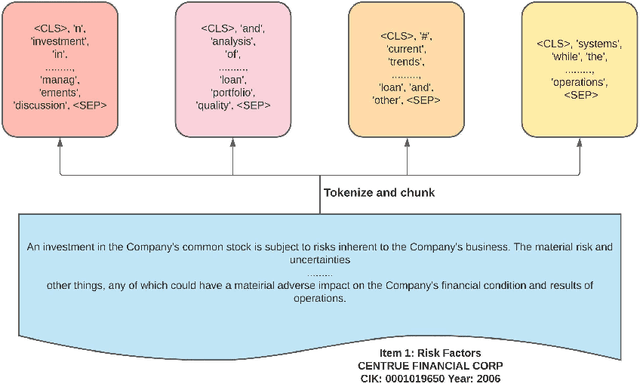

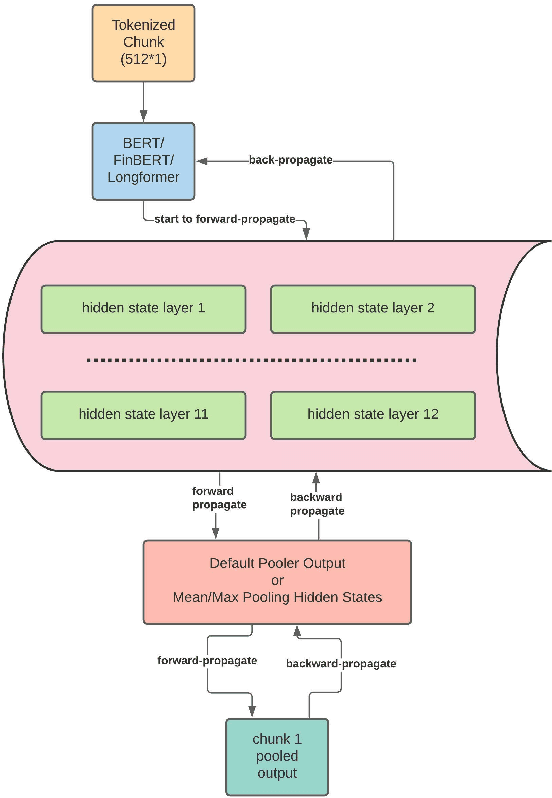
Unstructured data, especially text, continues to grow rapidly in various domains. In particular, in the financial sphere, there is a wealth of accumulated unstructured financial data, such as the textual disclosure documents that companies submit on a regular basis to regulatory agencies, such as the Securities and Exchange Commission (SEC). These documents are typically very long and tend to contain valuable soft information about a company's performance. It is therefore of great interest to learn predictive models from these long textual documents, especially for forecasting numerical key performance indicators (KPIs). Whereas there has been a great progress in pre-trained language models (LMs) that learn from tremendously large corpora of textual data, they still struggle in terms of effective representations for long documents. Our work fills this critical need, namely how to develop better models to extract useful information from long textual documents and learn effective features that can leverage the soft financial and risk information for text regression (prediction) tasks. In this paper, we propose and implement a deep learning framework that splits long documents into chunks and utilizes pre-trained LMs to process and aggregate the chunks into vector representations, followed by self-attention to extract valuable document-level features. We evaluate our model on a collection of 10-K public disclosure reports from US banks, and another dataset of reports submitted by US companies. Overall, our framework outperforms strong baseline methods for textual modeling as well as a baseline regression model using only numerical data. Our work provides better insights into how utilizing pre-trained domain-specific and fine-tuned long-input LMs in representing long documents can improve the quality of representation of textual data, and therefore, help in improving predictive analyses.
Temporal Information and Event Markup Language: TIE-ML Markup Process and Schema Version 1.0
Sep 28, 2021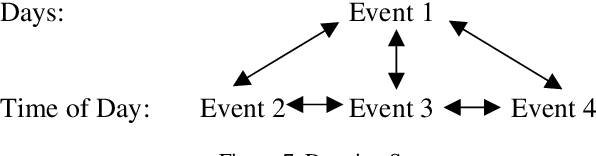

Temporal Information and Event Markup Language (TIE-ML) is a markup strategy and annotation schema to improve the productivity and accuracy of temporal and event related annotation of corpora to facilitate machine learning based model training. For the annotation of events, temporal sequencing, and durations, it is significantly simpler by providing an extremely reduced tag set for just temporal relations and event enumeration. In comparison to other standards, as for example the Time Markup Language (TimeML), it is much easier to use by dropping sophisticated formalisms, theoretical concepts, and annotation approaches. Annotations of corpora using TimeML can be mapped to TIE-ML with a loss, and TIE-ML annotations can be fully mapped to TimeML with certain under-specification.
Structural Prior Guided Generative Adversarial Transformers for Low-Light Image Enhancement
Jul 16, 2022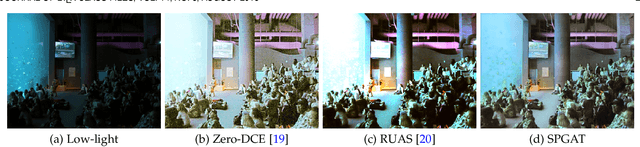
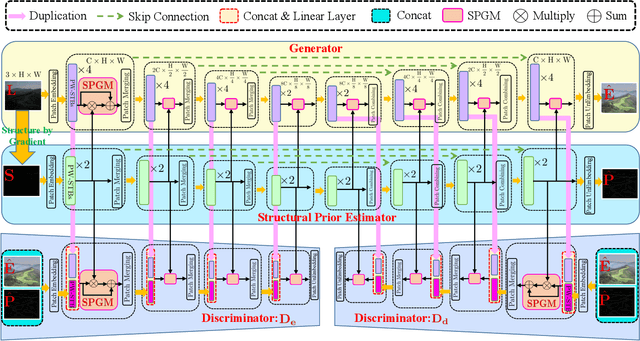


We propose an effective Structural Prior guided Generative Adversarial Transformer (SPGAT) to solve low-light image enhancement. Our SPGAT mainly contains a generator with two discriminators and a structural prior estimator (SPE). The generator is based on a U-shaped Transformer which is used to explore non-local information for better clear image restoration. The SPE is used to explore useful structures from images to guide the generator for better structural detail estimation. To generate more realistic images, we develop a new structural prior guided adversarial learning method by building the skip connections between the generator and discriminators so that the discriminators can better discriminate between real and fake features. Finally, we propose a parallel windows-based Swin Transformer block to aggregate different level hierarchical features for high-quality image restoration. Experimental results demonstrate that the proposed SPGAT performs favorably against recent state-of-the-art methods on both synthetic and real-world datasets.
A Lightweight Transmission Parameter Selection Scheme Using Reinforcement Learning for LoRaWAN
Aug 03, 2022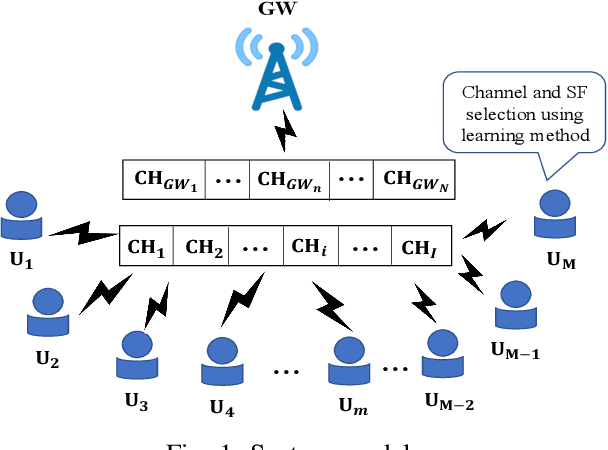
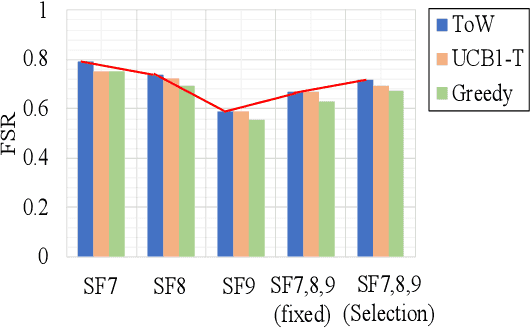
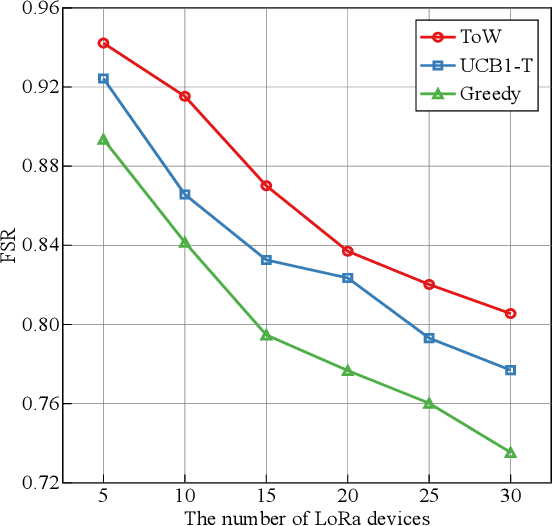
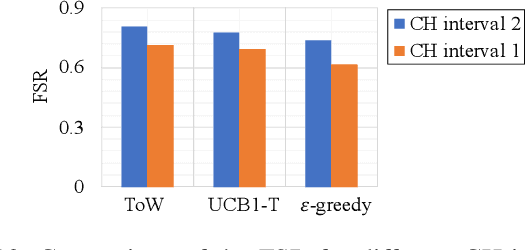
The number of IoT devices is predicted to reach 125 billion by 2023. The growth of IoT devices will intensify the collisions between devices, degrading communication performance. Selecting appropriate transmission parameters, such as channel and spreading factor (SF), can effectively reduce the collisions between long-range (LoRa) devices. However, most of the schemes proposed in the current literature are not easy to implement on an IoT device with limited computational complexity and memory. To solve this issue, we propose a lightweight transmission-parameter selection scheme, i.e., a joint channel and SF selection scheme using reinforcement learning for low-power wide area networking (LoRaWAN). In the proposed scheme, appropriate transmission parameters can be selected by simple four arithmetic operations using only Acknowledge (ACK) information. Additionally, we theoretically analyze the computational complexity and memory requirement of our proposed scheme, which verified that our proposed scheme could select transmission parameters with extremely low computational complexity and memory requirement. Moreover, a large number of experiments were implemented on the LoRa devices in the real world to evaluate the effectiveness of our proposed scheme. The experimental results demonstrate the following main phenomena. (1) Compared to other lightweight transmission-parameter selection schemes, collisions between LoRa devices can be efficiently avoided by our proposed scheme in LoRaWAN irrespective of changes in the available channels. (2) The frame success rate (FSR) can be improved by selecting access channels and using SFs as opposed to only selecting access channels. (3) Since interference exists between adjacent channels, FSR and fairness can be improved by increasing the interval of adjacent available channels.
Geometric Features Informed Multi-person Human-object Interaction Recognition in Videos
Jul 19, 2022


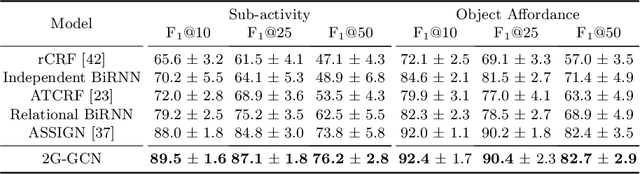
Human-Object Interaction (HOI) recognition in videos is important for analyzing human activity. Most existing work focusing on visual features usually suffer from occlusion in the real-world scenarios. Such a problem will be further complicated when multiple people and objects are involved in HOIs. Consider that geometric features such as human pose and object position provide meaningful information to understand HOIs, we argue to combine the benefits of both visual and geometric features in HOI recognition, and propose a novel Two-level Geometric feature-informed Graph Convolutional Network (2G-GCN). The geometric-level graph models the interdependency between geometric features of humans and objects, while the fusion-level graph further fuses them with visual features of humans and objects. To demonstrate the novelty and effectiveness of our method in challenging scenarios, we propose a new multi-person HOI dataset (MPHOI-72). Extensive experiments on MPHOI-72 (multi-person HOI), CAD-120 (single-human HOI) and Bimanual Actions (two-hand HOI) datasets demonstrate our superior performance compared to state-of-the-arts.