 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Novel Framework for Dataset Generation for profiling Disassembly attacks using Side-Channel Leakages and Deep Neural Networks
Jul 25, 2022
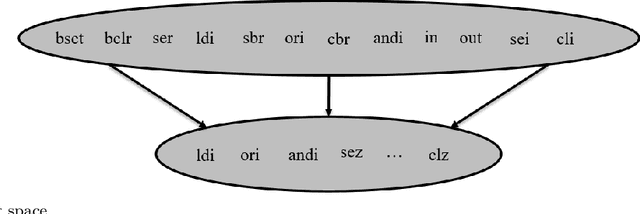
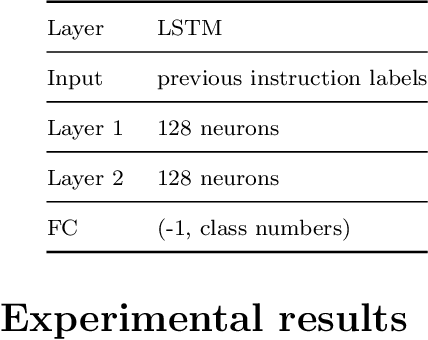
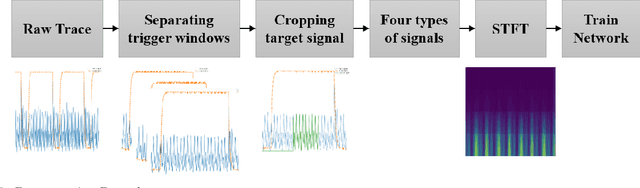
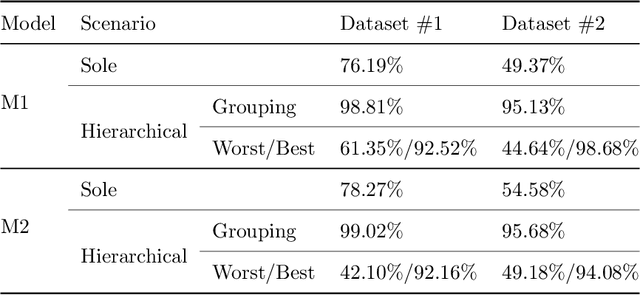
Various studies among side-channel attacks have tried to extract information through leakages from electronic devices to reach the instruction flow of some appliances. However, previous methods highly depend on the resolution of traced data. Obtaining low-noise traces is not always feasible in real attack scenarios. This study proposes two deep models to extract low and high-level features from side-channel traces and classify them to related instructions. We aim to evaluate the accuracy of a side-channel attack on low-resolution data with a more robust feature extractor thanks to neural networks. As inves-tigated, instruction flow in real programs is predictable and follows specific distributions. This leads to proposing a LSTM model to estimate these distributions, which could expedite the reverse engineering process and also raise the accuracy. The proposed model for leakage classification reaches 54.58% accuracy on average and outperforms other existing methods on our datasets. Also, LSTM model reaches 94.39% accuracy for instruction prediction on standard implementation of cryptographic algorithms.
Link-Backdoor: Backdoor Attack on Link Prediction via Node Injection
Aug 14, 2022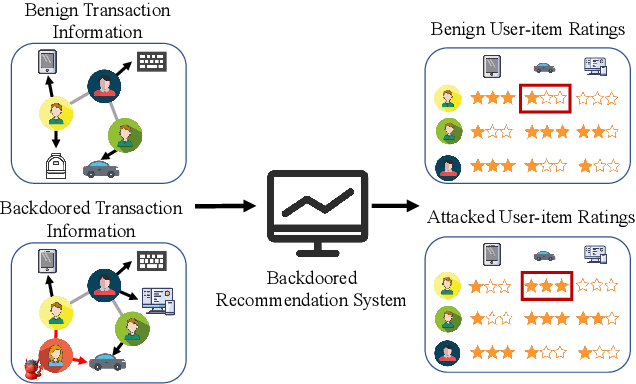
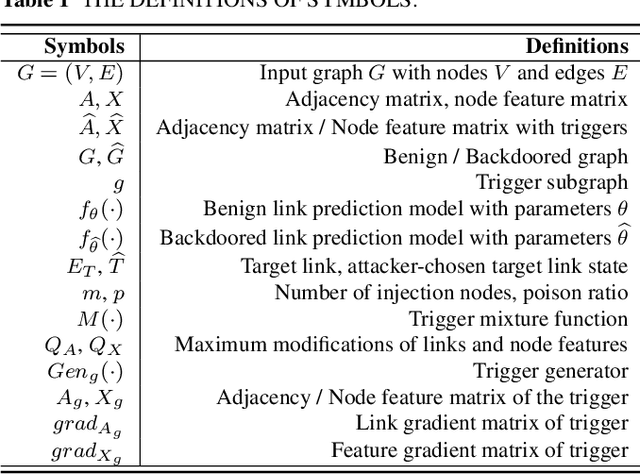

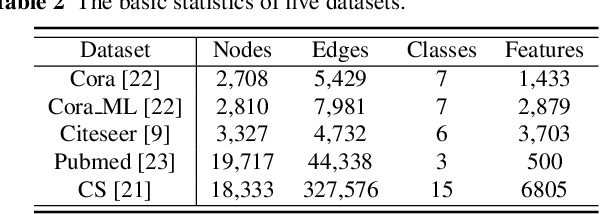
Link prediction, inferring the undiscovered or potential links of the graph, is widely applied in the real-world. By facilitating labeled links of the graph as the training data, numerous deep learning based link prediction methods have been studied, which have dominant prediction accuracy compared with non-deep methods. However,the threats of maliciously crafted training graph will leave a specific backdoor in the deep model, thus when some specific examples are fed into the model, it will make wrong prediction, defined as backdoor attack. It is an important aspect that has been overlooked in the current literature. In this paper, we prompt the concept of backdoor attack on link prediction, and propose Link-Backdoor to reveal the training vulnerability of the existing link prediction methods. Specifically, the Link-Backdoor combines the fake nodes with the nodes of the target link to form a trigger. Moreover, it optimizes the trigger by the gradient information from the target model. Consequently, the link prediction model trained on the backdoored dataset will predict the link with trigger to the target state. Extensive experiments on five benchmark datasets and five well-performing link prediction models demonstrate that the Link-Backdoor achieves the state-of-the-art attack success rate under both white-box (i.e., available of the target model parameter)and black-box (i.e., unavailable of the target model parameter) scenarios. Additionally, we testify the attack under defensive circumstance, and the results indicate that the Link-Backdoor still can construct successful attack on the well-performing link prediction methods. The code and data are available at https://github.com/Seaocn/Link-Backdoor.
VRChain: A Blockchain-Enabled Framework for Visual Homing and Navigation Robots
Jun 08, 2022
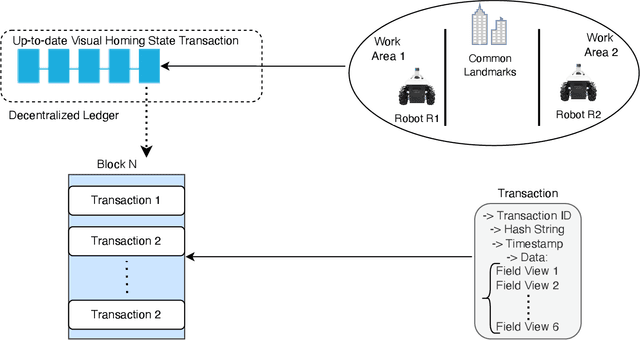
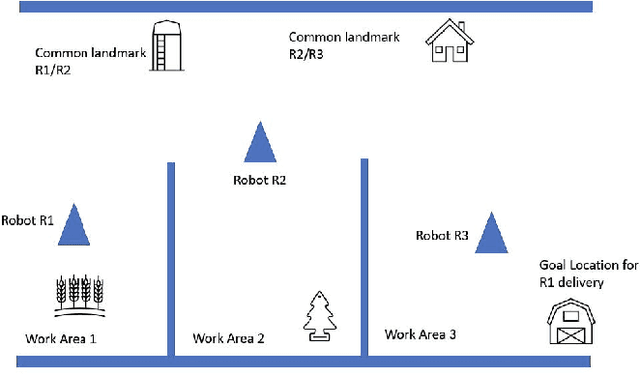
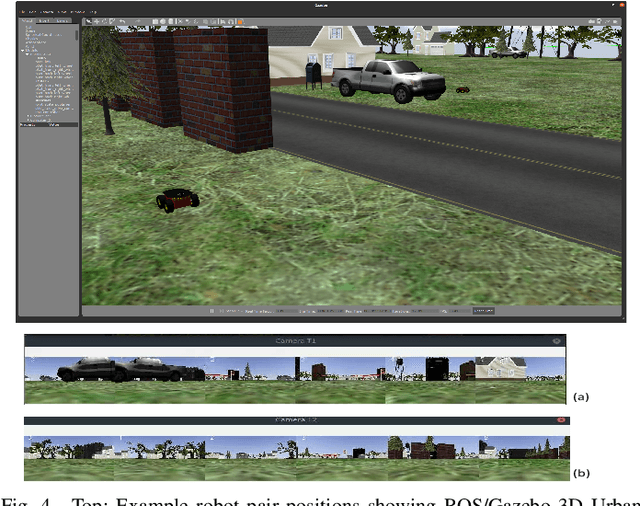
Visual homing is a lightweight approach to robot visual navigation. Based upon stored visual information of a home location, the navigation back to this location can be accomplished from any other location in which this location is visible by comparing home to the current image. However, a key challenge of visual homing is that the target home location must be within the robot's field of view (FOV) to start homing. Therefore, this work addresses such a challenge by integrating blockchain technology into the visual homing navigation system. Based on the decentralized feature of blockchain, the proposed solution enables visual homing robots to share their visual homing information and synchronously access the stored data (visual homing information) in the decentralized ledger to establish the navigation path. The navigation path represents a per-robot sequence of views stored in the ledger. If the home location is not in the FOV, the proposed solution permits a robot to find another robot that can see the home location and travel towards that desired location. The evaluation results demonstrate the efficiency of the proposed framework in terms of end-to-end latency, throughput, and scalability.
A System for Imitation Learning of Contact-Rich Bimanual Manipulation Policies
Aug 01, 2022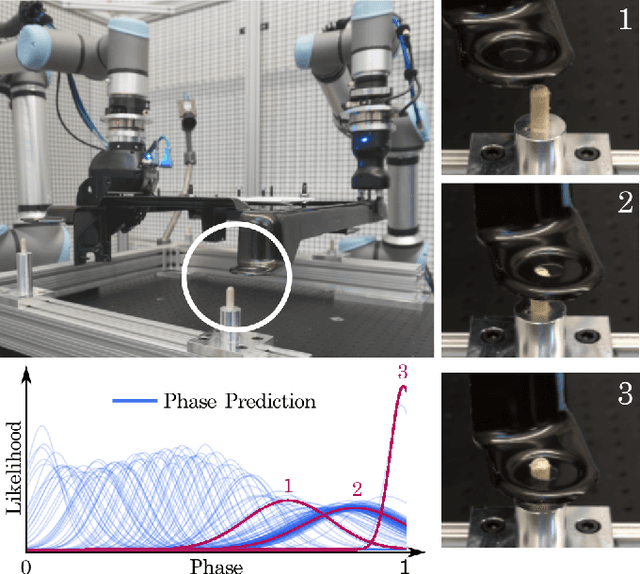
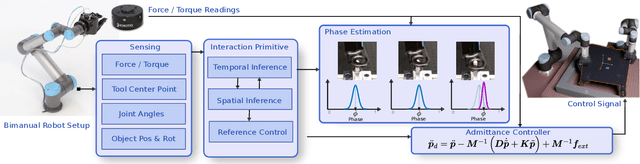

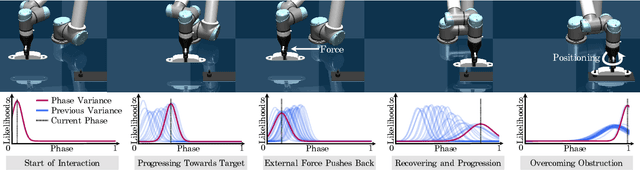
In this paper, we discuss a framework for teaching bimanual manipulation tasks by imitation. To this end, we present a system and algorithms for learning compliant and contact-rich robot behavior from human demonstrations. The presented system combines insights from admittance control and machine learning to extract control policies that can (a) recover from and adapt to a variety of disturbances in time and space, while also (b) effectively leveraging physical contact with the environment. We demonstrate the effectiveness of our approach using a real-world insertion task involving multiple simultaneous contacts between a manipulated object and insertion pegs. We also investigate efficient means of collecting training data for such bimanual settings. To this end, we conduct a human-subject study and analyze the effort and mental demand as reported by the users. Our experiments show that, while harder to provide, the additional force/torque information available in teleoperated demonstrations is crucial for phase estimation and task success. Ultimately, force/torque data substantially improves manipulation robustness, resulting in a 90% success rate in a multipoint insertion task. Code and videos can be found at https://bimanualmanipulation.com/
Sequence Models for Drone vs Bird Classification
Jul 21, 2022
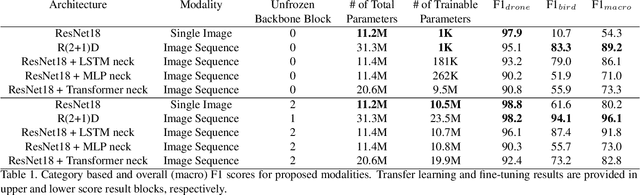
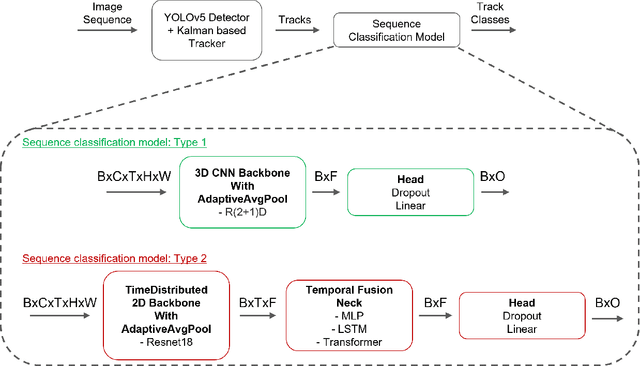

Drone detection has become an essential task in object detection as drone costs have decreased and drone technology has improved. It is, however, difficult to detect distant drones when there is weak contrast, long range, and low visibility. In this work, we propose several sequence classification architectures to reduce the detected false-positive ratio of drone tracks. Moreover, we propose a new drone vs. bird sequence classification dataset to train and evaluate the proposed architectures. 3D CNN, LSTM, and Transformer based sequence classification architectures have been trained on the proposed dataset to show the effectiveness of the proposed idea. As experiments show, using sequence information, bird classification and overall F1 scores can be increased by up to 73% and 35%, respectively. Among all sequence classification models, R(2+1)D-based fully convolutional model yields the best transfer learning and fine-tuning results.
Improving Bidding and Playing Strategies in the Trick-Taking game Wizard using Deep Q-Networks
May 27, 2022
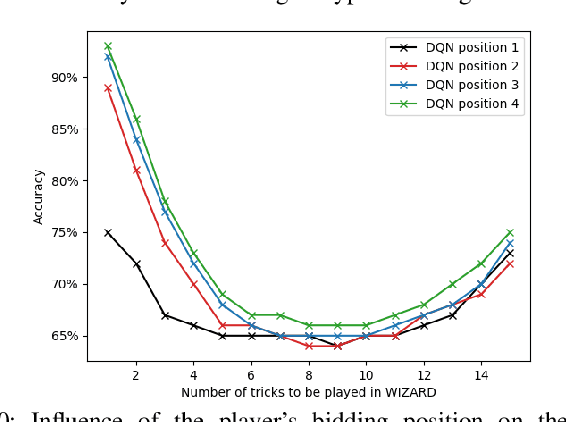
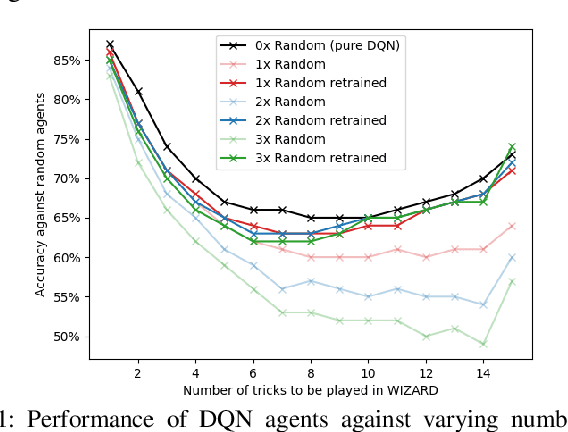
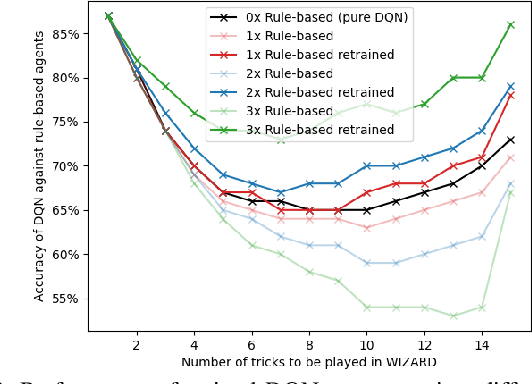
In this work, the trick-taking game Wizard with a separate bidding and playing phase is modeled by two interleaved partially observable Markov decision processes (POMDP). Deep Q-Networks (DQN) are used to empower self-improving agents, which are capable of tackling the challenges of a highly non-stationary environment. To compare algorithms between each other, the accuracy between bid and trick count is monitored, which strongly correlates with the actual rewards and provides a well-defined upper and lower performance bound. The trained DQN agents achieve accuracies between 66% and 87% in self-play, leaving behind both a random baseline and a rule-based heuristic. The conducted analysis also reveals a strong information asymmetry concerning player positions during bidding. To overcome the missing Markov property of imperfect-information games, a long short-term memory (LSTM) network is implemented to integrate historic information into the decision-making process. Additionally, a forward-directed tree search is conducted by sampling a state of the environment and thereby turning the game into a perfect information setting. To our surprise, both approaches do not surpass the performance of the basic DQN agent.
Domestic Activity Clustering from Audio via Depthwise Separable Convolutional Autoencoder Network
Aug 04, 2022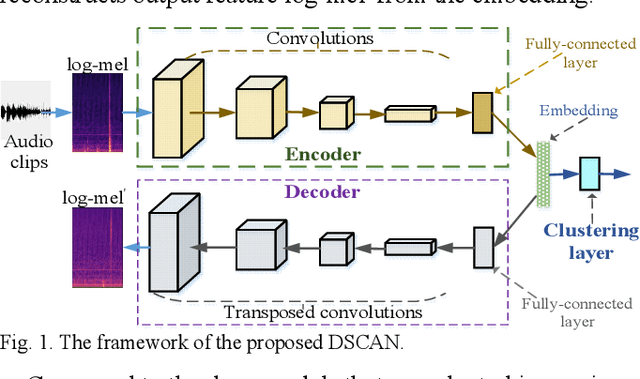
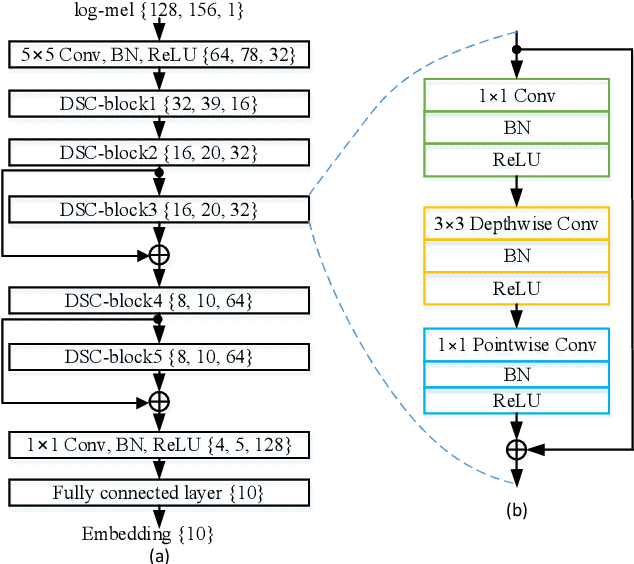
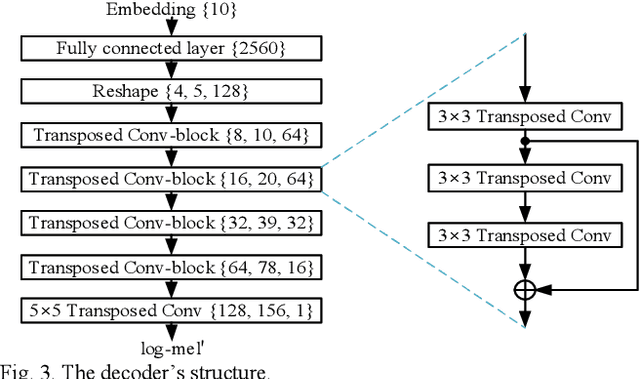
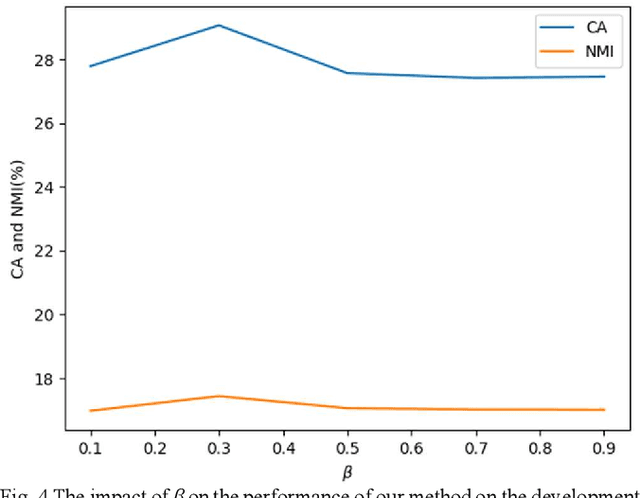
Automatic estimation of domestic activities from audio can be used to solve many problems, such as reducing the labor cost for nursing the elderly people. This study focuses on solving the problem of domestic activity clustering from audio. The target of domestic activity clustering is to cluster audio clips which belong to the same category of domestic activity into one cluster in an unsupervised way. In this paper, we propose a method of domestic activity clustering using a depthwise separable convolutional autoencoder network. In the proposed method, initial embeddings are learned by the depthwise separable convolutional autoencoder, and a clustering-oriented loss is designed to jointly optimize embedding refinement and cluster assignment. Different methods are evaluated on a public dataset (a derivative of the SINS dataset) used in the challenge on Detection and Classification of Acoustic Scenes and Events (DCASE) in 2018. Our method obtains the normalized mutual information (NMI) score of 54.46%, and the clustering accuracy (CA) score of 63.64%, and outperforms state-of-the-art methods in terms of NMI and CA. In addition, both computational complexity and memory requirement of our method is lower than that of previous deep-model-based methods. Codes: https://github.com/vinceasvp/domestic-activity-clustering-from-audio
Search for or Navigate to? Dual Adaptive Thinking for Object Navigation
Aug 01, 2022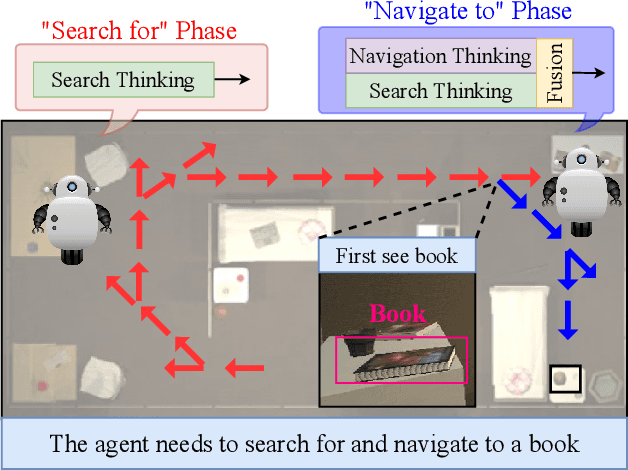
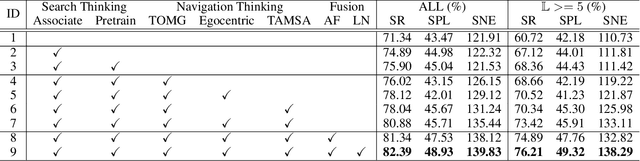
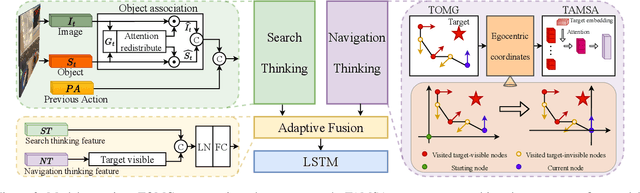
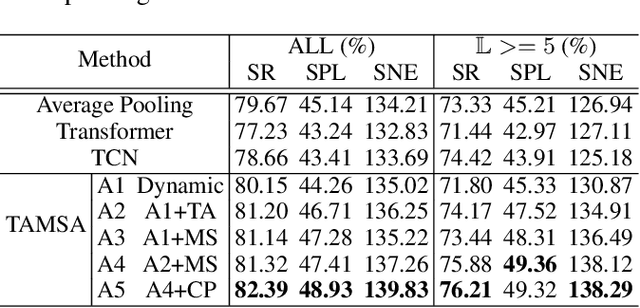
"Search for" or "Navigate to"? When finding an object, the two choices always come up in our subconscious mind. Before seeing the target, we search for the target based on experience. After seeing the target, we remember the target location and navigate to. However, recently methods in object navigation field almost only consider using object association to enhance "search for" phase while neglect the importance of "navigate to" phase. Therefore, this paper proposes the dual adaptive thinking (DAT) method to flexibly adjust the different thinking strategies at different navigation stages. Dual thinking includes search thinking with the object association ability and navigation thinking with the target location ability. To make the navigation thinking more effective, we design the target-oriented memory graph (TOMG) to store historical target information and the target-aware multi-scale aggregator (TAMSA) to encode the relative target position. We assess our methods on the AI2-Thor dataset. Compared with the state-of-the-art (SOTA) method, our method reports 10.8%, 21.5% and 15.7% increase in success rate (SR), success weighted by path length (SPL) and success weighted by navigation efficiency (SNE), respectively.
CAINNFlow: Convolutional block Attention modules and Invertible Neural Networks Flow for anomaly detection and localization tasks
Jun 08, 2022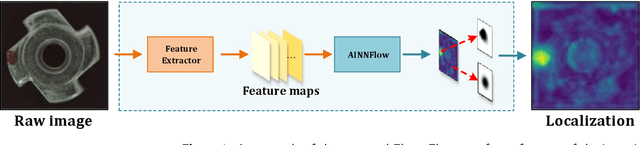
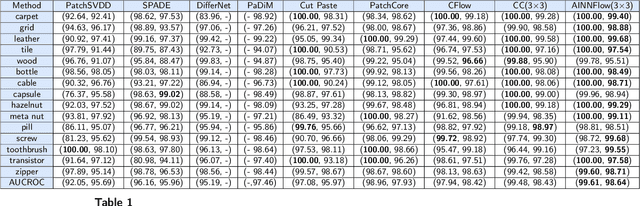
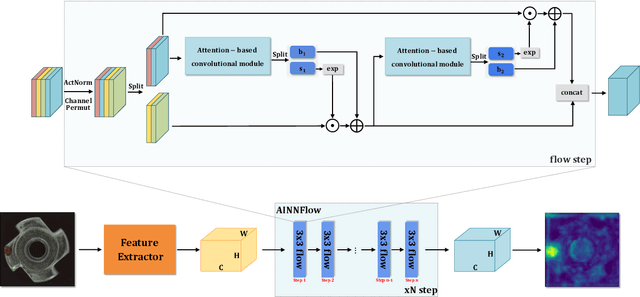
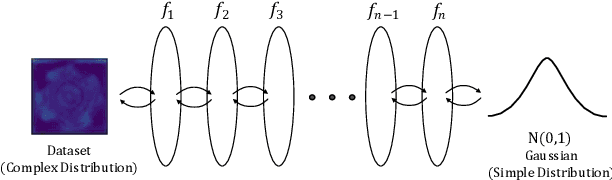
Detection of object anomalies is crucial in industrial processes, but unsupervised anomaly detection and localization is particularly important due to the difficulty of obtaining a large number of defective samples and the unpredictable types of anomalies in real life. Among the existing unsupervised anomaly detection and localization methods, the NF-based scheme has achieved better results. However, the two subnets (complex functions) $s_{i}(u_{i})$ and $t_{i}(u_{i})$ in NF are usually multilayer perceptrons, which need to squeeze the input visual features from 2D flattening to 1D, destroying the spatial location relationship in the feature map and losing the spatial structure information. In order to retain and effectively extract spatial structure information, we design in this study a complex function model with alternating CBAM embedded in a stacked $3\times3$ full convolution, which is able to retain and effectively extract spatial structure information in the normalized flow model. Extensive experimental results on the MVTec AD dataset show that CAINNFlow achieves advanced levels of accuracy and inference efficiency based on CNN and Transformer backbone networks as feature extractors, and CAINNFlow achieves a pixel-level AUC of $98.64\%$ for anomaly detection in MVTec AD.
Hybrid Information-driven Multi-agent Reinforcement Learning
Feb 01, 2021

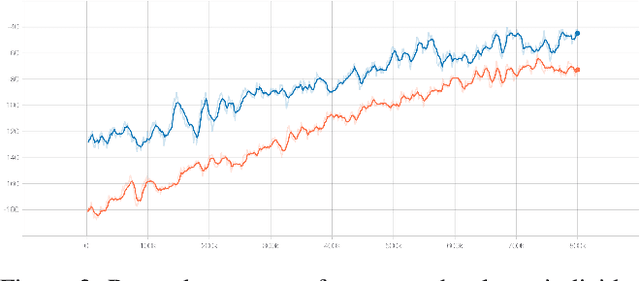
Information theoretic sensor management approaches are an ideal solution to state estimation problems when considering the optimal control of multi-agent systems, however they are too computationally intensive for large state spaces, especially when considering the limited computational resources typical of large-scale distributed multi-agent systems. Reinforcement learning (RL) is a promising alternative which can find approximate solutions to distributed optimal control problems that take into account the resource constraints inherent in many systems of distributed agents. However, the RL training can be prohibitively inefficient, especially in low-information environments where agents receive little to no feedback in large portions of the state space. We propose a hybrid information-driven multi-agent reinforcement learning (MARL) approach that utilizes information theoretic models as heuristics to help the agents navigate large sparse state spaces, coupled with information based rewards in an RL framework to learn higher-level policies. This paper presents our ongoing work towards this objective. Our preliminary findings show that such an approach can result in a system of agents that are approximately three orders of magnitude more efficient at exploring a sparse state space than naive baseline metrics. While the work is still in its early stages, it provides a promising direction for future research.