 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Coronary Artery Registration Method Based on Super-pixel Particle Swarm Optimization
May 30, 2025



Percutaneous Coronary Intervention (PCI) is a minimally invasive procedure that improves coronary blood flow and treats coronary artery disease. Although PCI typically requires 2D X-ray angiography (XRA) to guide catheter placement at real-time, computed tomography angiography (CTA) may substantially improve PCI by providing precise information of 3D vascular anatomy and status. To leverage real-time XRA and detailed 3D CTA anatomy for PCI, accurate multimodal image registration of XRA and CTA is required, to guide the procedure and avoid complications. This is a challenging process as it requires registration of images from different geometrical modalities (2D -> 3D and vice versa), with variations in contrast and noise levels. In this paper, we propose a novel multimodal coronary artery image registration method based on a swarm optimization algorithm, which effectively addresses challenges such as large deformations, low contrast, and noise across these imaging modalities. Our algorithm consists of two main modules: 1) preprocessing of XRA and CTA images separately, and 2) a registration module based on feature extraction using the Steger and Superpixel Particle Swarm Optimization algorithms. Our technique was evaluated on a pilot dataset of 28 pairs of XRA and CTA images from 10 patients who underwent PCI. The algorithm was compared with four state-of-the-art (SOTA) methods in terms of registration accuracy, robustness, and efficiency. Our method outperformed the selected SOTA baselines in all aspects. Experimental results demonstrate the significant effectiveness of our algorithm, surpassing the previous benchmarks and proposes a novel clinical approach that can potentially have merit for improving patient outcomes in coronary artery disease.
DM4Steal: Diffusion Model For Link Stealing Attack On Graph Neural Networks
Nov 05, 2024Graph has become increasingly integral to the advancement of recommendation systems, particularly with the fast development of graph neural network(GNN). By exploring the virtue of rich node features and link information, GNN is designed to provide personalized and accurate suggestions. Meanwhile, the privacy leakage of GNN in such contexts has also captured special attention. Prior work has revealed that a malicious user can utilize auxiliary knowledge to extract sensitive link data of the target graph, integral to recommendation systems, via the decision made by the target GNN model. This poses a significant risk to the integrity and confidentiality of data used in recommendation system. Though important, previous works on GNN's privacy leakage are still challenged in three aspects, i.e., limited stealing attack scenarios, sub-optimal attack performance, and adaptation against defense. To address these issues, we propose a diffusion model based link stealing attack, named DM4Steal. It differs previous work from three critical aspects. (i) Generality: aiming at six attack scenarios with limited auxiliary knowledge, we propose a novel training strategy for diffusion models so that DM4Steal is transferable to diverse attack scenarios. (ii) Effectiveness: benefiting from the retention of semantic structure in the diffusion model during the training process, DM4Steal is capable to learn the precise topology of the target graph through the GNN decision process. (iii) Adaptation: when GNN is defensive (e.g., DP, Dropout), DM4Steal relies on the stability that comes from sampling the score model multiple times to keep performance degradation to a minimum, thus DM4Steal implements successful adaptive attack on defensive GNN.
Motif-Backdoor: Rethinking the Backdoor Attack on Graph Neural Networks via Motifs
Oct 25, 2022Graph neural network (GNN) with a powerful representation capability has been widely applied to various areas, such as biological gene prediction, social recommendation, etc. Recent works have exposed that GNN is vulnerable to the backdoor attack, i.e., models trained with maliciously crafted training samples are easily fooled by patched samples. Most of the proposed studies launch the backdoor attack using a trigger that either is the randomly generated subgraph (e.g., erd\H{o}s-r\'enyi backdoor) for less computational burden, or the gradient-based generative subgraph (e.g., graph trojaning attack) to enable a more effective attack. However, the interpretation of how is the trigger structure and the effect of the backdoor attack related has been overlooked in the current literature. Motifs, recurrent and statistically significant sub-graphs in graphs, contain rich structure information. In this paper, we are rethinking the trigger from the perspective of motifs, and propose a motif-based backdoor attack, denoted as Motif-Backdoor. It contributes from three aspects. (i) Interpretation: it provides an in-depth explanation for backdoor effectiveness by the validity of the trigger structure from motifs, leading to some novel insights, e.g., using subgraphs that appear less frequently in the graph as the trigger can achieve better attack performance. (ii) Effectiveness: Motif-Backdoor reaches the state-of-the-art (SOTA) attack performance in both black-box and defensive scenarios. (iii) Efficiency: based on the graph motif distribution, Motif-Backdoor can quickly obtain an effective trigger structure without target model feedback or subgraph model generation. Extensive experimental results show that Motif-Backdoor realizes the SOTA performance on three popular models and four public datasets compared with five baselines.
Link-Backdoor: Backdoor Attack on Link Prediction via Node Injection
Aug 14, 2022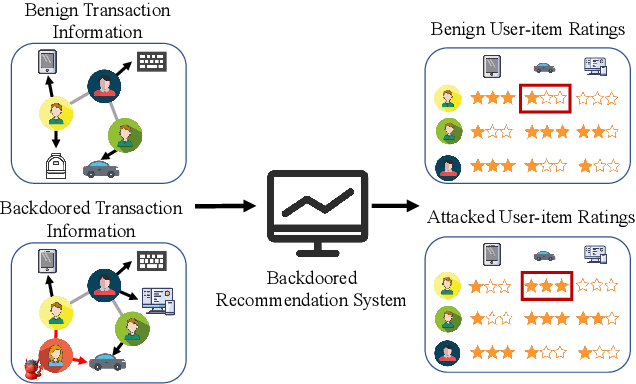
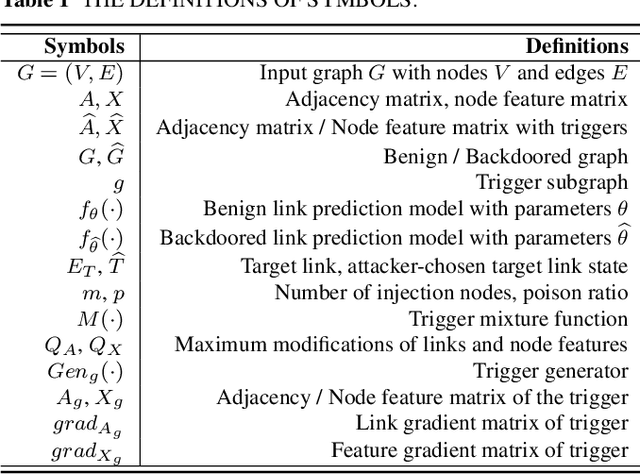

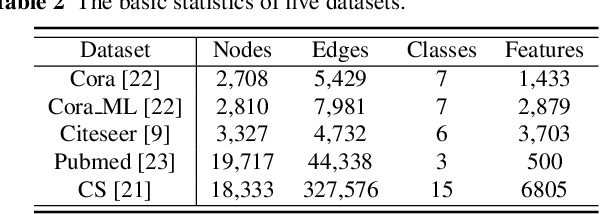
Link prediction, inferring the undiscovered or potential links of the graph, is widely applied in the real-world. By facilitating labeled links of the graph as the training data, numerous deep learning based link prediction methods have been studied, which have dominant prediction accuracy compared with non-deep methods. However,the threats of maliciously crafted training graph will leave a specific backdoor in the deep model, thus when some specific examples are fed into the model, it will make wrong prediction, defined as backdoor attack. It is an important aspect that has been overlooked in the current literature. In this paper, we prompt the concept of backdoor attack on link prediction, and propose Link-Backdoor to reveal the training vulnerability of the existing link prediction methods. Specifically, the Link-Backdoor combines the fake nodes with the nodes of the target link to form a trigger. Moreover, it optimizes the trigger by the gradient information from the target model. Consequently, the link prediction model trained on the backdoored dataset will predict the link with trigger to the target state. Extensive experiments on five benchmark datasets and five well-performing link prediction models demonstrate that the Link-Backdoor achieves the state-of-the-art attack success rate under both white-box (i.e., available of the target model parameter)and black-box (i.e., unavailable of the target model parameter) scenarios. Additionally, we testify the attack under defensive circumstance, and the results indicate that the Link-Backdoor still can construct successful attack on the well-performing link prediction methods. The code and data are available at https://github.com/Seaocn/Link-Backdoor.