 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Task Allocation using a Team of Robots
Jul 20, 2022
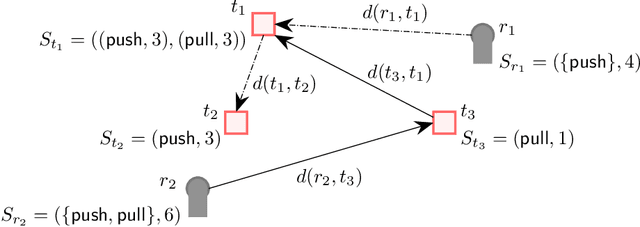
Task allocation using a team or coalition of robots is one of the most important problems in robotics, computer science, operational research, and artificial intelligence. In recent work, research has focused on handling complex objectives and feasibility constraints amongst other variations of the multi-robot task allocation problem. There are many examples of important research progress in these directions. We present a general formulation of the task allocation problem that generalizes several versions that are well-studied. Our formulation includes the states of robots, tasks, and the surrounding environment in which they operate. We describe how the problem can vary depending on the feasibility constraints, objective functions, and the level of dynamically changing information. In addition, we discuss existing solution approaches for the problem including optimization-based approaches, and market-based approaches.
Zero-Shot Bird Species Recognition by Learning from Field Guides
Jun 03, 2022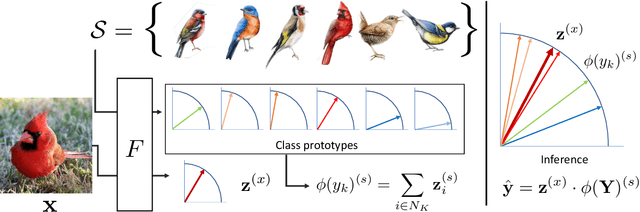
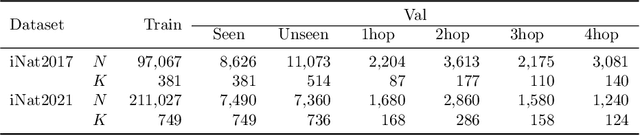
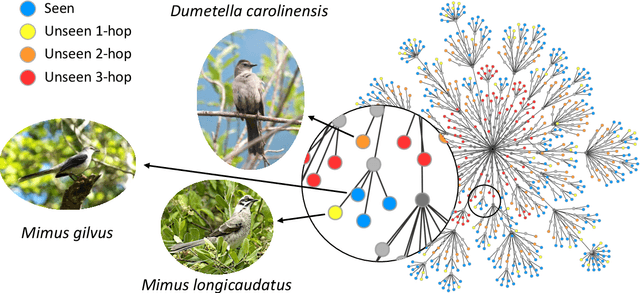
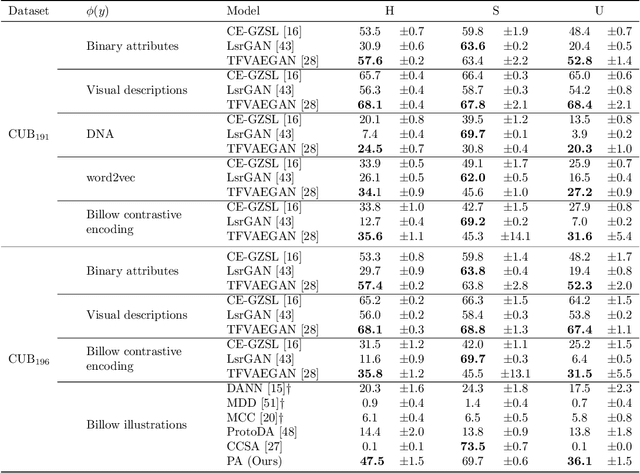
We exploit field guides to learn bird species recognition, in particular zero-shot recognition of unseen species. The illustrations contained in field guides deliberately focus on discriminative properties of a species, and can serve as side information to transfer knowledge from seen to unseen classes. We study two approaches: (1) a contrastive encoding of illustrations that can be fed into zero-shot learning schemes; and (2) a novel method that leverages the fact that illustrations are also images and as such structurally more similar to photographs than other kinds of side information. Our results show that illustrations from field guides, which are readily available for a wide range of species, are indeed a competitive source of side information. On the iNaturalist2021 subset, we obtain a harmonic mean from 749 seen and 739 unseen classes greater than $45\%$ (@top-10) and $15\%$ (@top-1). Which shows that field guides are a valuable option for challenging real-world scenarios with many species.
Partition refinement for emulation
Jul 08, 2022Kripke models are useful to express static knowledge or belief. On the other hand, action models describe information flow and dynamic knowledge or belief. The technique of refinement partition has been used to find the smallest Kripke model under bisimulation, which is sufficient and necessary for the semantic equivalence of Kripke models. In this paper, we generalize refinement partition to action models to find the smallest action model under propositional action emulation, which is sufficient for the semantic equivalence of action models, and sufficient and necessary if the action models are required to be propositional.
Computing the Information Content of Trained Neural Networks
Mar 01, 2021
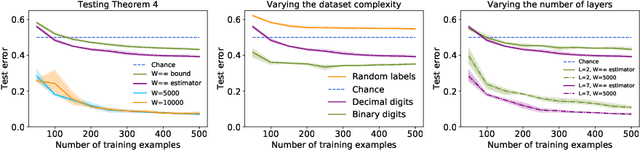
How much information does a learning algorithm extract from the training data and store in a neural network's weights? Too much, and the network would overfit to the training data. Too little, and the network would not fit to anything at all. Na\"ively, the amount of information the network stores should scale in proportion to the number of trainable weights. This raises the question: how can neural networks with vastly more weights than training data still generalise? A simple resolution to this conundrum is that the number of weights is usually a bad proxy for the actual amount of information stored. For instance, typical weight vectors may be highly compressible. Then another question occurs: is it possible to compute the actual amount of information stored? This paper derives both a consistent estimator and a closed-form upper bound on the information content of infinitely wide neural networks. The derivation is based on an identification between neural information content and the negative log probability of a Gaussian orthant. This identification yields bounds that analytically control the generalisation behaviour of the entire solution space of infinitely wide networks. The bounds have a simple dependence on both the network architecture and the training data. Corroborating the findings of Valle-P\'erez et al. (2019), who conducted a similar analysis using approximate Gaussian integration techniques, the bounds are found to be both non-vacuous and correlated with the empirical generalisation behaviour at finite width.
Short-term Load Forecasting with Distributed Long Short-Term Memory
Aug 01, 2022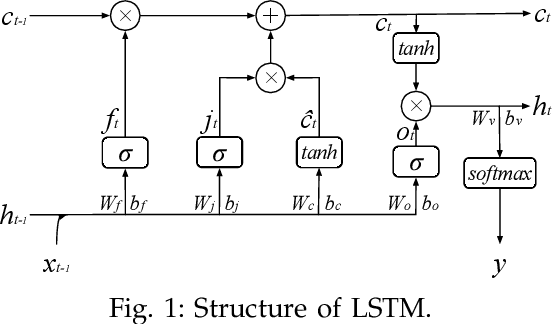
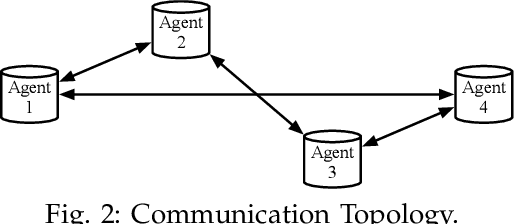
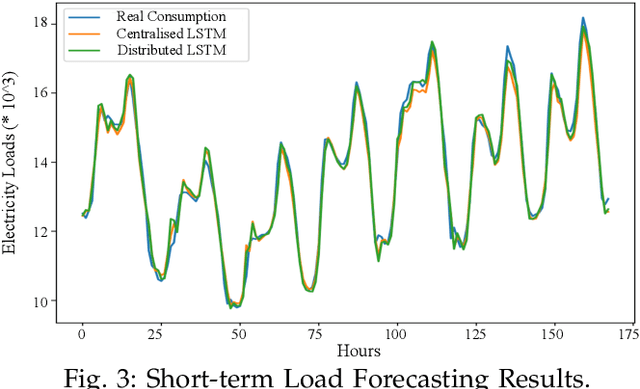
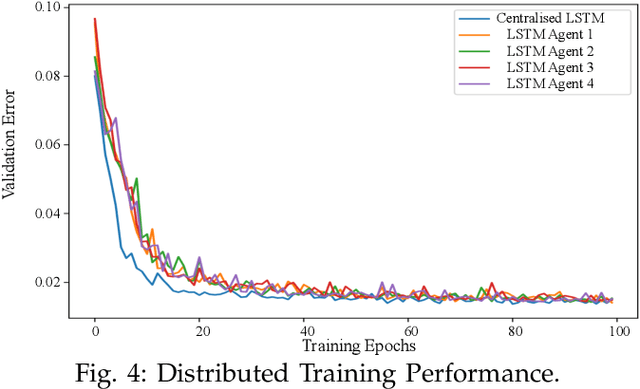
With the employment of smart meters, massive data on consumer behaviour can be collected by retailers. From the collected data, the retailers may obtain the household profile information and implement demand response. While retailers prefer to acquire a model as accurate as possible among different customers, there are two major challenges. First, different retailers in the retail market do not share their consumer's electricity consumption data as these data are regarded as their assets, which has led to the problem of data island. Second, the electricity load data are highly heterogeneous since different retailers may serve various consumers. To this end, a fully distributed short-term load forecasting framework based on a consensus algorithm and Long Short-Term Memory (LSTM) is proposed, which may protect the customer's privacy and satisfy the accurate load forecasting requirement. Specifically, a fully distributed learning framework is exploited for distributed training, and a consensus technique is applied to meet confidential privacy. Case studies show that the proposed method has comparable performance with centralised methods regarding the accuracy, but the proposed method shows advantages in training speed and data privacy.
Improving Small Lesion Segmentation in CT Scans using Intensity Distribution Supervision: Application to Small Bowel Carcinoid Tumor
Jul 29, 2022
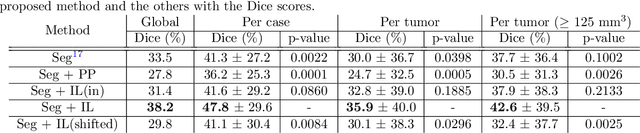
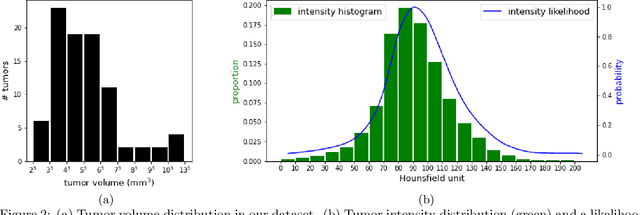
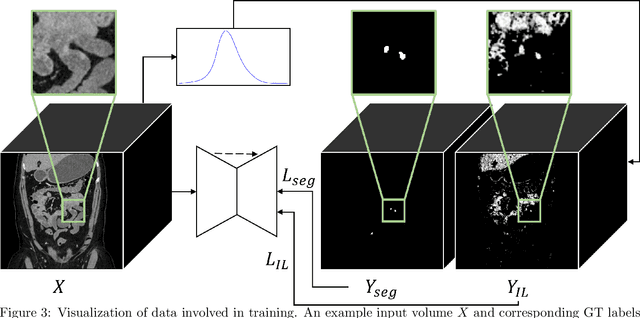
Finding small lesions is very challenging due to lack of noticeable features, severe class imbalance, as well as the size itself. One approach to improve small lesion segmentation is to reduce the region of interest and inspect it at a higher sensitivity rather than performing it for the entire region. It is usually implemented as sequential or joint segmentation of organ and lesion, which requires additional supervision on organ segmentation. Instead, we propose to utilize an intensity distribution of a target lesion at no additional labeling cost to effectively separate regions where the lesions are possibly located from the background. It is incorporated into network training as an auxiliary task. We applied the proposed method to segmentation of small bowel carcinoid tumors in CT scans. We observed improvements for all metrics (33.5% $\rightarrow$ 38.2%, 41.3% $\rightarrow$ 47.8%, 30.0% $\rightarrow$ 35.9% for the global, per case, and per tumor Dice scores, respectively.) compared to the baseline method, which proves the validity of our idea. Our method can be one option for explicitly incorporating intensity distribution information of a target in network training.
Mitigating sampling bias in risk-based active learning via an EM algorithm
Jun 25, 2022

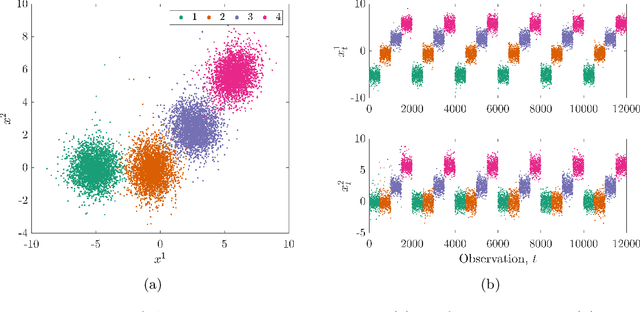
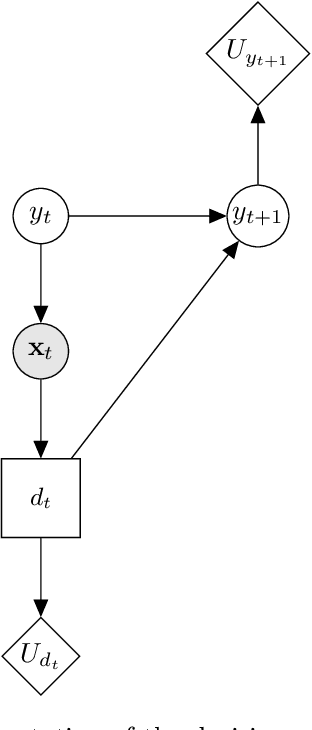
Risk-based active learning is an approach to developing statistical classifiers for online decision-support. In this approach, data-label querying is guided according to the expected value of perfect information for incipient data points. For SHM applications, the value of information is evaluated with respect to a maintenance decision process, and the data-label querying corresponds to the inspection of a structure to determine its health state. Sampling bias is a known issue within active-learning paradigms; this occurs when an active learning process over- or undersamples specific regions of a feature-space, thereby resulting in a training set that is not representative of the underlying distribution. This bias ultimately degrades decision-making performance, and as a consequence, results in unnecessary costs incurred. The current paper outlines a risk-based approach to active learning that utilises a semi-supervised Gaussian mixture model. The semi-supervised approach counteracts sampling bias by incorporating pseudo-labels for unlabelled data via an EM algorithm. The approach is demonstrated on a numerical example representative of the decision processes found in SHM.
Position-Agnostic Autonomous Navigation in Vineyards with Deep Reinforcement Learning
Jun 28, 2022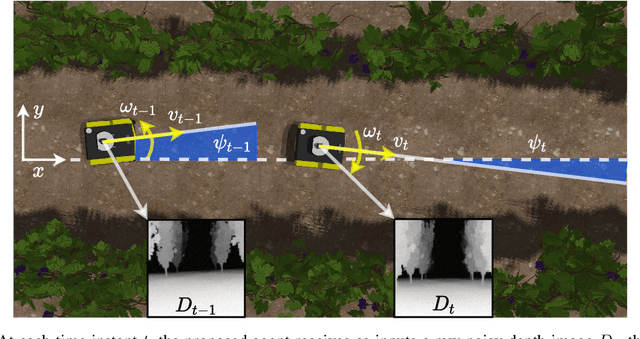
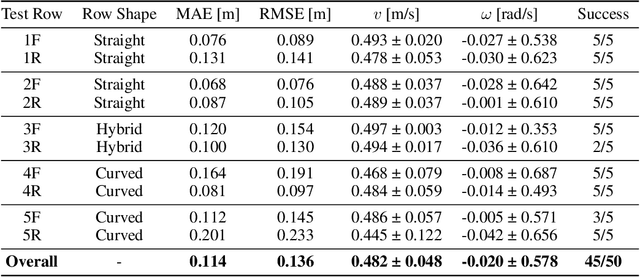

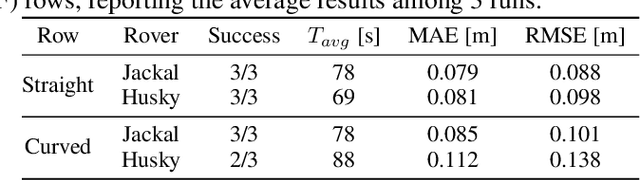
Precision agriculture is rapidly attracting research to efficiently introduce automation and robotics solutions to support agricultural activities. Robotic navigation in vineyards and orchards offers competitive advantages in autonomously monitoring and easily accessing crops for harvesting, spraying and performing time-consuming necessary tasks. Nowadays, autonomous navigation algorithms exploit expensive sensors which also require heavy computational cost for data processing. Nonetheless, vineyard rows represent a challenging outdoor scenario where GPS and Visual Odometry techniques often struggle to provide reliable positioning information. In this work, we combine Edge AI with Deep Reinforcement Learning to propose a cutting-edge lightweight solution to tackle the problem of autonomous vineyard navigation without exploiting precise localization data and overcoming task-tailored algorithms with a flexible learning-based approach. We train an end-to-end sensorimotor agent which directly maps noisy depth images and position-agnostic robot state information to velocity commands and guides the robot to the end of a row, continuously adjusting its heading for a collision-free central trajectory. Our extensive experimentation in realistic simulated vineyards demonstrates the effectiveness of our solution and the generalization capabilities of our agent.
A Dialogue-based Information Extraction System for Medical Insurance Assessment
Jul 13, 2021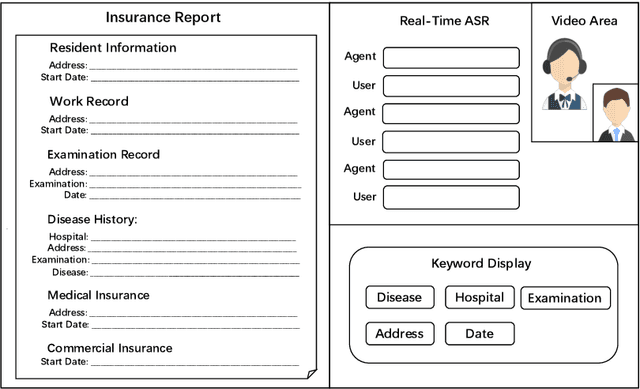

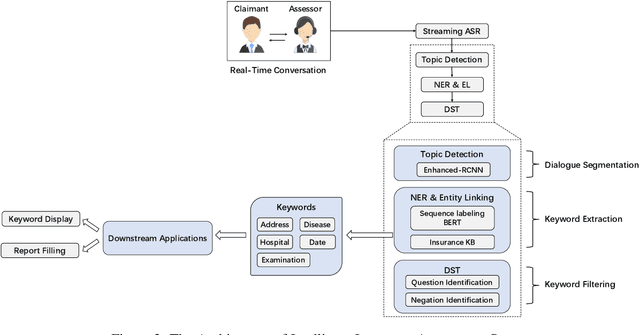

In the Chinese medical insurance industry, the assessor's role is essential and requires significant efforts to converse with the claimant. This is a highly professional job that involves many parts, such as identifying personal information, collecting related evidence, and making a final insurance report. Due to the coronavirus (COVID-19) pandemic, the previous offline insurance assessment has to be conducted online. However, for the junior assessor often lacking practical experience, it is not easy to quickly handle such a complex online procedure, yet this is important as the insurance company needs to decide how much compensation the claimant should receive based on the assessor's feedback. In order to promote assessors' work efficiency and speed up the overall procedure, in this paper, we propose a dialogue-based information extraction system that integrates advanced NLP technologies for medical insurance assessment. With the assistance of our system, the average time cost of the procedure is reduced from 55 minutes to 35 minutes, and the total human resources cost is saved 30% compared with the previous offline procedure. Until now, the system has already served thousands of online claim cases.
Audio-video fusion strategies for active speaker detection in meetings
Jun 09, 2022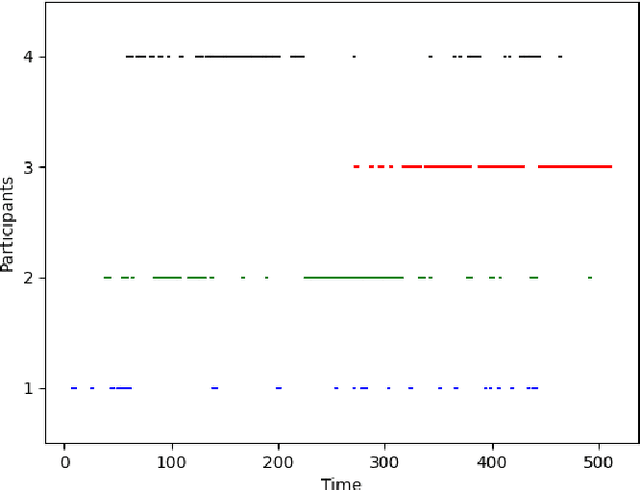



Meetings are a common activity in professional contexts, and it remains challenging to endow vocal assistants with advanced functionalities to facilitate meeting management. In this context, a task like active speaker detection can provide useful insights to model interaction between meeting participants. Motivated by our application context related to advanced meeting assistant, we want to combine audio and visual information to achieve the best possible performance. In this paper, we propose two different types of fusion for the detection of the active speaker, combining two visual modalities and an audio modality through neural networks. For comparison purpose, classical unsupervised approaches for audio feature extraction are also used. We expect visual data centered on the face of each participant to be very appropriate for detecting voice activity, based on the detection of lip and facial gestures. Thus, our baseline system uses visual data and we chose a 3D Convolutional Neural Network architecture, which is effective for simultaneously encoding appearance and movement. To improve this system, we supplemented the visual information by processing the audio stream with a CNN or an unsupervised speaker diarization system. We have further improved this system by adding visual modality information using motion through optical flow. We evaluated our proposal with a public and state-of-the-art benchmark: the AMI corpus. We analysed the contribution of each system to the merger carried out in order to determine if a given participant is currently speaking. We also discussed the results we obtained. Besides, we have shown that, for our application context, adding motion information greatly improves performance. Finally, we have shown that attention-based fusion improves performance while reducing the standard deviation.