 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An artificial intelligence natural language processing pipeline for information extraction in neuroradiology
Jul 21, 2021


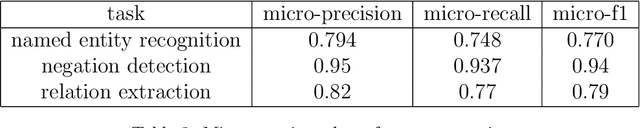
The use of electronic health records in medical research is difficult because of the unstructured format. Extracting information within reports and summarising patient presentations in a way amenable to downstream analysis would be enormously beneficial for operational and clinical research. In this work we present a natural language processing pipeline for information extraction of radiological reports in neurology. Our pipeline uses a hybrid sequence of rule-based and artificial intelligence models to accurately extract and summarise neurological reports. We train and evaluate a custom language model on a corpus of 150000 radiological reports from National Hospital for Neurology and Neurosurgery, London MRI imaging. We also present results for standard NLP tasks on domain-specific neuroradiology datasets. We show our pipeline, called `neuroNLP', can reliably extract clinically relevant information from these reports, enabling downstream modelling of reports and associated imaging on a heretofore unprecedented scale.
Rapid Flow Behavior Modeling of Thermal Interface Materials Using Deep Neural Networks
Aug 09, 2022


Thermal Interface Materials (TIMs) are widely used in electronic packaging. Increasing power density and limited assembly space pose high demands on thermal management. Large cooling surfaces need to be covered efficiently. When joining the heatsink, previously dispensed TIM spreads over the cooling surface. Recommendations on the dispensing pattern exist only for simple surface geometries such as rectangles. For more complex geometries, Computational Fluid Dynamics (CFD) simulations are used in combination with manual experiments. While CFD simulations offer a high accuracy, they involve simulation experts and are rather expensive to set up. We propose a lightweight heuristic to model the spreading behavior of TIM. We further speed up the calculation by training an Artificial Neural Network (ANN) on data from this model. This offers rapid computation times and further supplies gradient information. This ANN can not only be used to aid manual pattern design of TIM, but also enables an automated pattern optimization. We compare this approach against the state-of-the-art and use real product samples for validation.
Learning Primitive-aware Discriminative Representations for FSL
Aug 20, 2022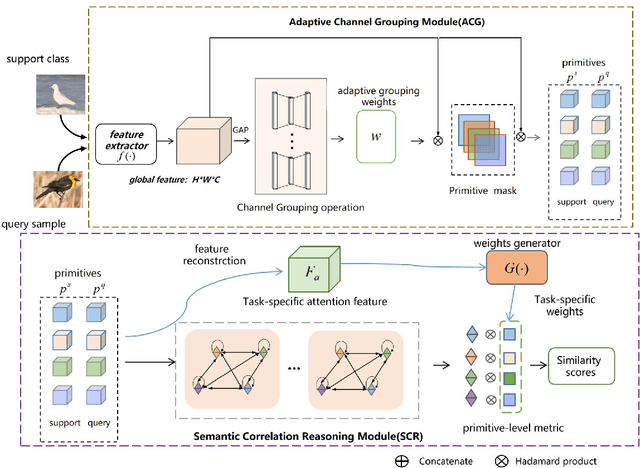
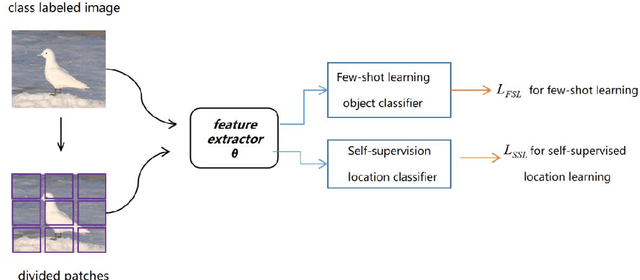
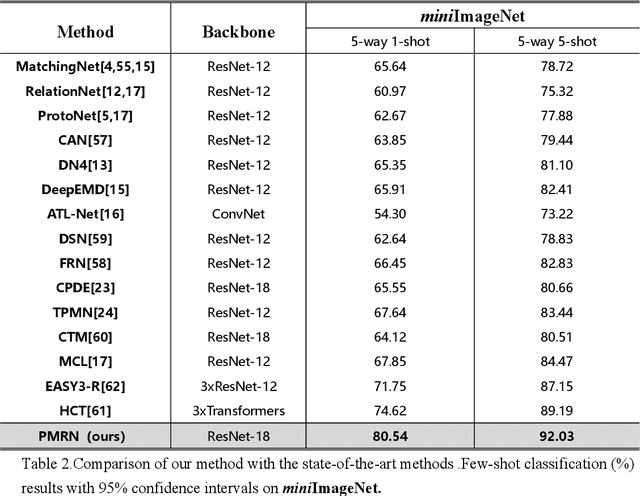
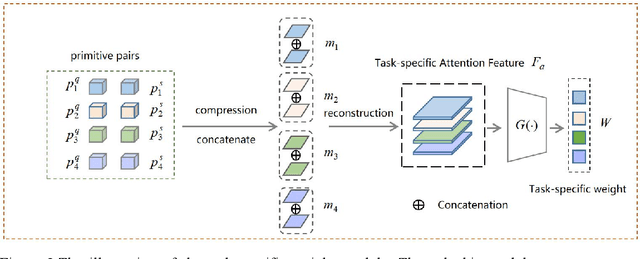
Few-shot learning (FSL) aims to learn a classifier that can be easily adapted to recognize novel classes,given only a few labeled examples per class.Limited data keep this task challenging for deep learning.Recent metric-based methods has achieved promising performance based on image-level features.However,these global features ignore abundant local and structural information that is transferable and consistent between seen and unseen classes.Some study in cognitive science argue that humans can recognize novel classes with the learned primitives.We expect to mine both transferable and discriminative representation from base classes and adopt them to recognize novel classes.Building on the episodic training mechanism,We propose a Primitive Mining and Reasoning Network(PMRN) to learn primitive-aware representation in an end-to-end manner for metric-based FSL model.We first add self-supervision auxiliary task,forcing feature extractor to learn tvisual pattern corresponding to primitives.To further mine and produce transferable primitive-aware representations,we design an Adaptive Channel Grouping(ACG)module to synthesize a set of visual primitives from object embedding by enhancing informative channel maps while suppressing useless ones. Based on the learned primitive feature,a Semantic Correlation Reasoning (SCR) module is proposed to capture internal relations among them.Finally,we learn the task-specific importance of primitives and conduct primitive-level metric based on the task-specific attention feature.Extensive experiments show that our method achieves state-of-the-art results on six standard benchmarks.
Towards an Improved Understanding of Software Vulnerability Assessment Using Data-Driven Approaches
Jul 24, 2022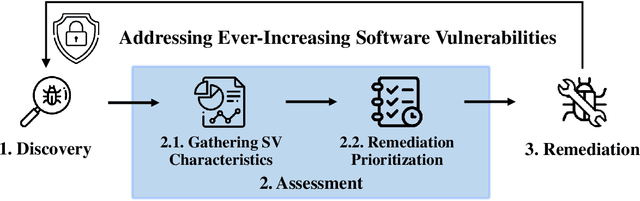
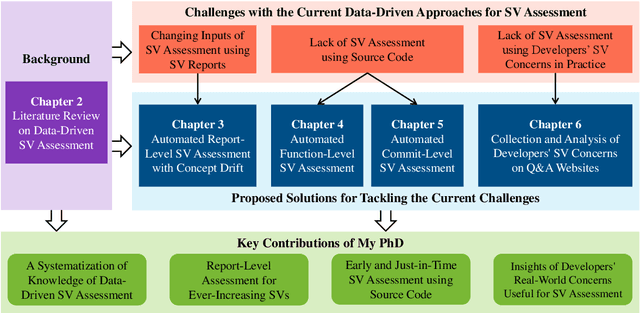


The thesis advances the field of software security by providing knowledge and automation support for software vulnerability assessment using data-driven approaches. Software vulnerability assessment provides important and multifaceted information to prevent and mitigate dangerous cyber-attacks in the wild. The key contributions include a systematisation of knowledge, along with a suite of novel data-driven techniques and practical recommendations for researchers and practitioners in the area. The thesis results help improve the understanding and inform the practice of assessing ever-increasing vulnerabilities in real-world software systems. This in turn enables more thorough and timely fixing prioritisation and planning of these critical security issues.
Dynamic Sensor Matching based on Geomagnetic Inertial Navigation
Aug 12, 2022

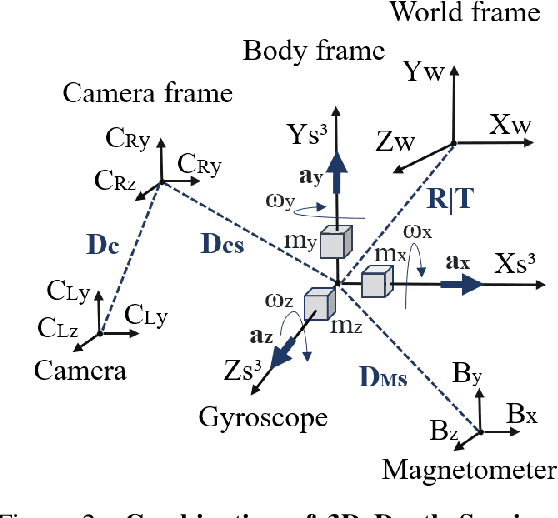

Optical sensors can capture dynamic environments and derive depth information in near real-time. The quality of these digital reconstructions is determined by factors like illumination, surface and texture conditions, sensing speed and other sensor characteristics as well as the sensor-object relations. Improvements can be obtained by using dynamically collected data from multiple sensors. However, matching the data from multiple sensors requires a shared world coordinate system. We present a concept for transferring multi-sensor data into a commonly referenced world coordinate system: the earth's magnetic field. The steady presence of our planetary magnetic field provides a reliable world coordinate system, which can serve as a reference for a position-defined reconstruction of dynamic environments. Our approach is evaluated using magnetic field sensors of the ZED 2 stereo camera from Stereolabs, which provides orientation relative to the North Pole similar to a compass. With the help of inertial measurement unit informations, each camera's position data can be transferred into the unified world coordinate system. Our evaluation reveals the level of quality possible using the earth magnetic field and allows a basis for dynamic and real-time-based applications of optical multi-sensors for environment detection.
* Page 16-25
Unlearning Protected User Attributes in Recommendations with Adversarial Training
Jun 09, 2022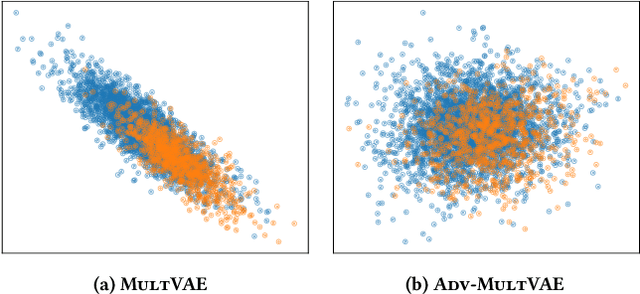
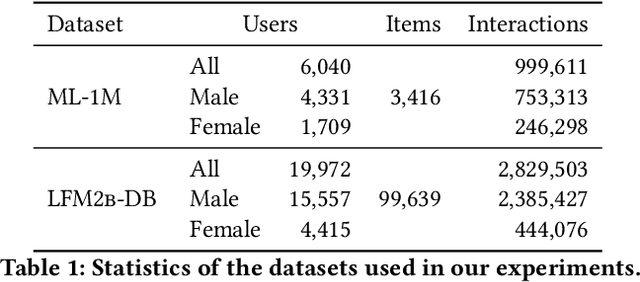
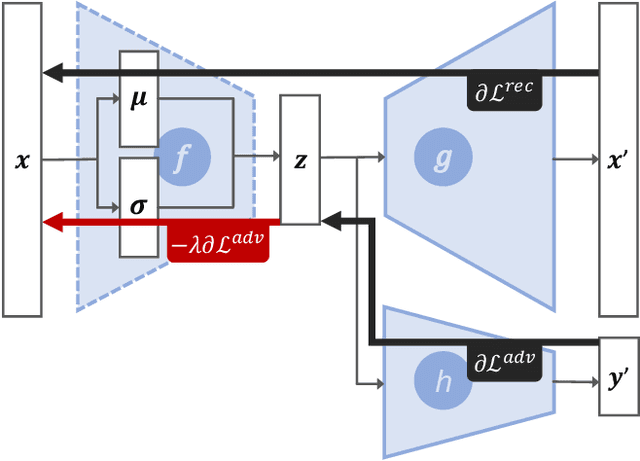
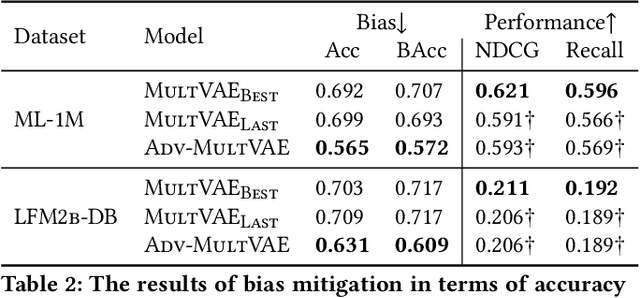
Collaborative filtering algorithms capture underlying consumption patterns, including the ones specific to particular demographics or protected information of users, e.g. gender, race, and location. These encoded biases can influence the decision of a recommendation system (RS) towards further separation of the contents provided to various demographic subgroups, and raise privacy concerns regarding the disclosure of users' protected attributes. In this work, we investigate the possibility and challenges of removing specific protected information of users from the learned interaction representations of a RS algorithm, while maintaining its effectiveness. Specifically, we incorporate adversarial training into the state-of-the-art MultVAE architecture, resulting in a novel model, Adversarial Variational Auto-Encoder with Multinomial Likelihood (Adv-MultVAE), which aims at removing the implicit information of protected attributes while preserving recommendation performance. We conduct experiments on the MovieLens-1M and LFM-2b-DemoBias datasets, and evaluate the effectiveness of the bias mitigation method based on the inability of external attackers in revealing the users' gender information from the model. Comparing with baseline MultVAE, the results show that Adv-MultVAE, with marginal deterioration in performance (w.r.t. NDCG and recall), largely mitigates inherent biases in the model on both datasets.
2DPASS: 2D Priors Assisted Semantic Segmentation on LiDAR Point Clouds
Jul 10, 2022
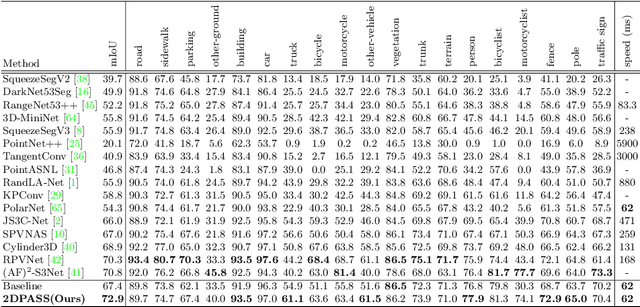
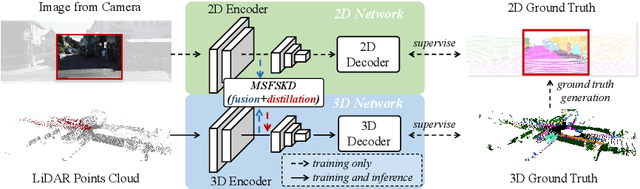
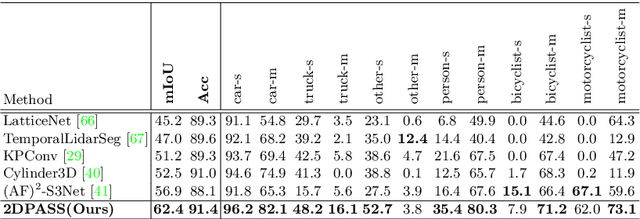
As camera and LiDAR sensors capture complementary information used in autonomous driving, great efforts have been made to develop semantic segmentation algorithms through multi-modality data fusion. However, fusion-based approaches require paired data, i.e., LiDAR point clouds and camera images with strict point-to-pixel mappings, as the inputs in both training and inference, which seriously hinders their application in practical scenarios. Thus, in this work, we propose the 2D Priors Assisted Semantic Segmentation (2DPASS), a general training scheme, to boost the representation learning on point clouds, by fully taking advantage of 2D images with rich appearance. In practice, by leveraging an auxiliary modal fusion and multi-scale fusion-to-single knowledge distillation (MSFSKD), 2DPASS acquires richer semantic and structural information from the multi-modal data, which are then online distilled to the pure 3D network. As a result, equipped with 2DPASS, our baseline shows significant improvement with only point cloud inputs. Specifically, it achieves the state-of-the-arts on two large-scale benchmarks (i.e. SemanticKITTI and NuScenes), including top-1 results in both single and multiple scan(s) competitions of SemanticKITTI.
Unsupervised Recognition of Informative Features via Tensor Network Machine Learning and Quantum Entanglement Variations
Jul 13, 2022
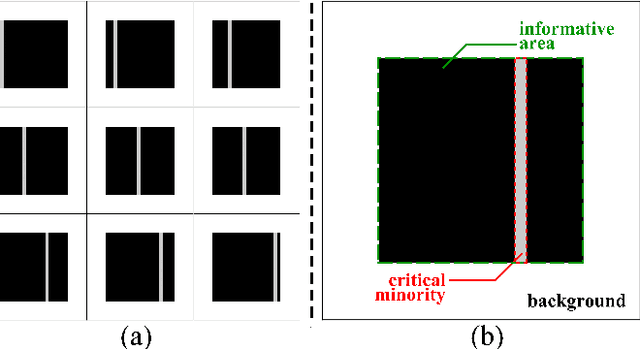
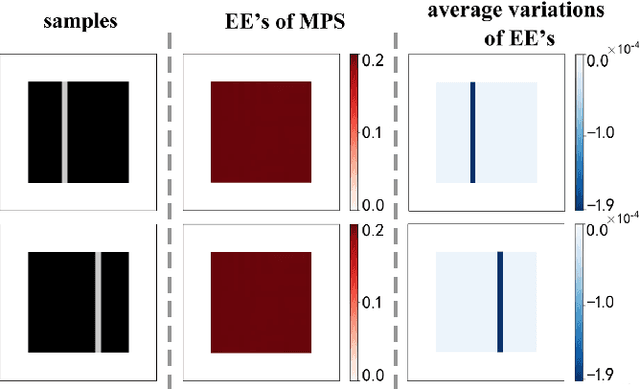
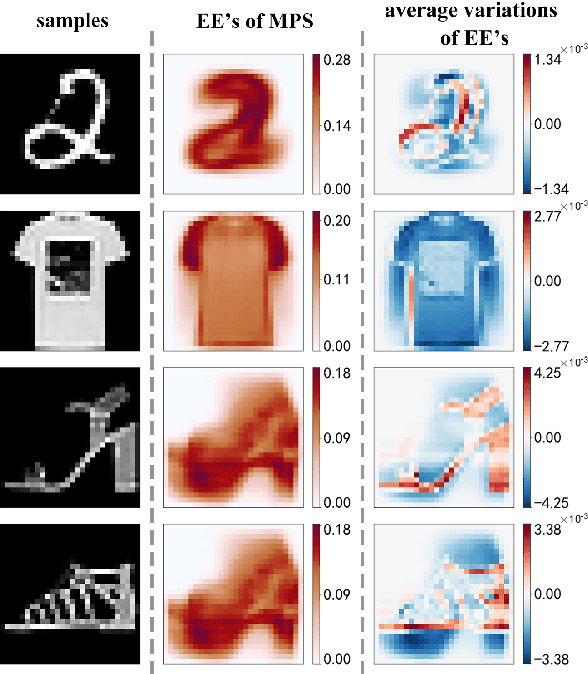
Given an image of a white shoe drawn on a blackboard, how are the white pixels deemed (say by human minds) to be informative for recognizing the shoe without any labeling information on the pixels? Here we investigate such a "white shoe" recognition problem from the perspective of tensor network (TN) machine learning and quantum entanglement. Utilizing a generative TN that captures the probability distribution of the features as quantum amplitudes, we propose an unsupervised recognition scheme of informative features with the variations of entanglement entropy (EE) caused by designed measurements. In this way, a given sample, where the values of its features are statistically meaningless, is mapped to the variations of EE that are statistically meaningful. We show that the EE variations identify the features that are critical to recognize this specific sample, and the EE itself reveals the information distribution from the TN model. The signs of the variations further reveal the entanglement structures among the features. We test the validity of our scheme on a toy dataset of strip images, the MNIST dataset of hand-drawn digits, and the fashion-MNIST dataset of the pictures of fashion articles. Our scheme opens the avenue to the quantum-inspired and interpreted unsupervised learning and could be applied to, e.g., image segmentation and object detection.
Bayesian Variable Selection in a Million Dimensions
Aug 02, 2022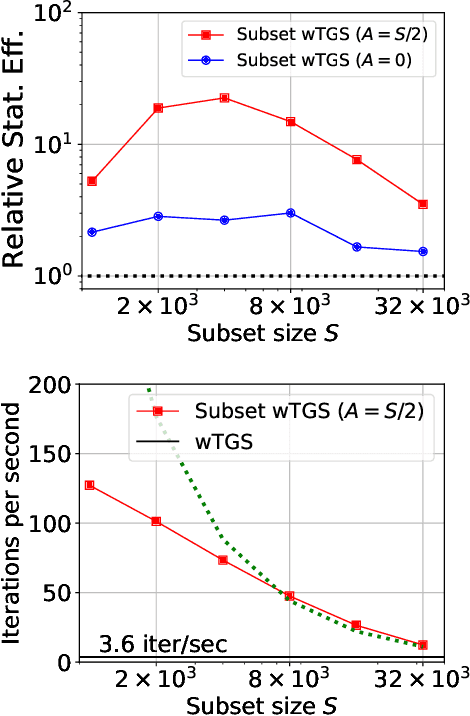
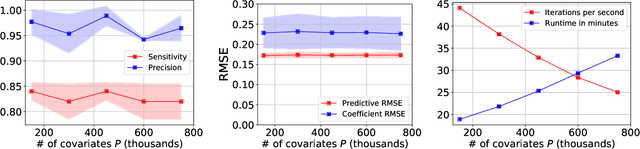
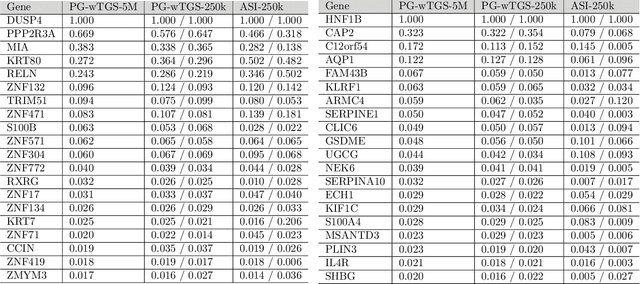

Bayesian variable selection is a powerful tool for data analysis, as it offers a principled method for variable selection that accounts for prior information and uncertainty. However, wider adoption of Bayesian variable selection has been hampered by computational challenges, especially in difficult regimes with a large number of covariates P or non-conjugate likelihoods. To scale to the large P regime we introduce an efficient MCMC scheme whose cost per iteration is sublinear in P. In addition we show how this scheme can be extended to generalized linear models for count data, which are prevalent in biology, ecology, economics, and beyond. In particular we design efficient algorithms for variable selection in binomial and negative binomial regression, which includes logistic regression as a special case. In experiments we demonstrate the effectiveness of our methods, including on cancer and maize genomic data.
Bayesian regularization of empirical MDPs
Aug 03, 2022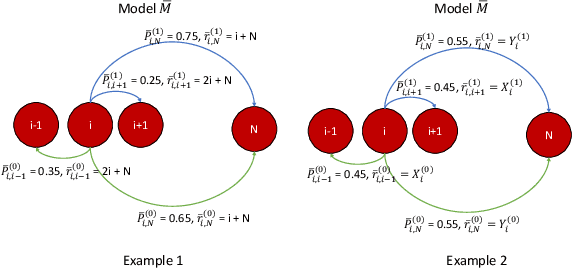
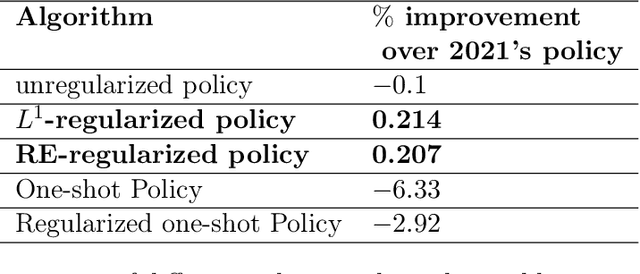
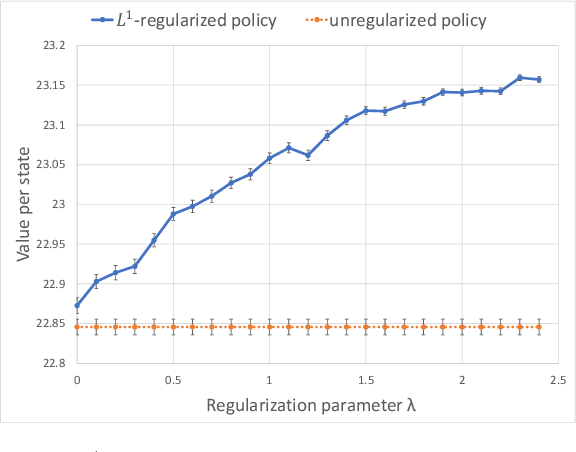
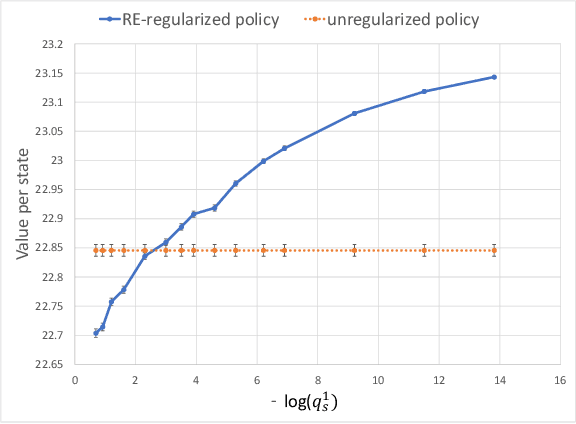
In most applications of model-based Markov decision processes, the parameters for the unknown underlying model are often estimated from the empirical data. Due to noise, the policy learnedfrom the estimated model is often far from the optimal policy of the underlying model. When applied to the environment of the underlying model, the learned policy results in suboptimal performance, thus calling for solutions with better generalization performance. In this work we take a Bayesian perspective and regularize the objective function of the Markov decision process with prior information in order to obtain more robust policies. Two approaches are proposed, one based on $L^1$ regularization and the other on relative entropic regularization. We evaluate our proposed algorithms on synthetic simulations and on real-world search logs of a large scale online shopping store. Our results demonstrate the robustness of regularized MDP policies against the noise present in the models.