 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Collision detection and identification for a legged manipulator
Jul 29, 2022


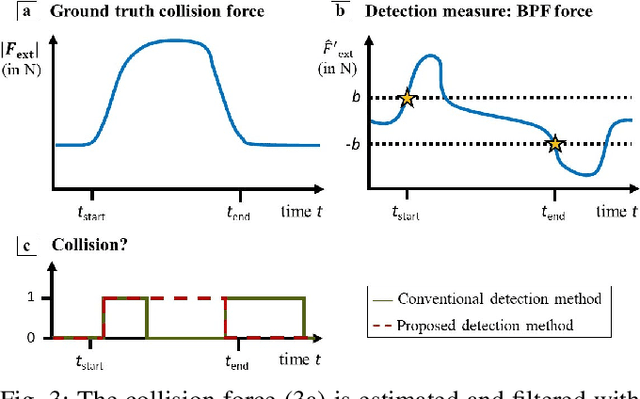
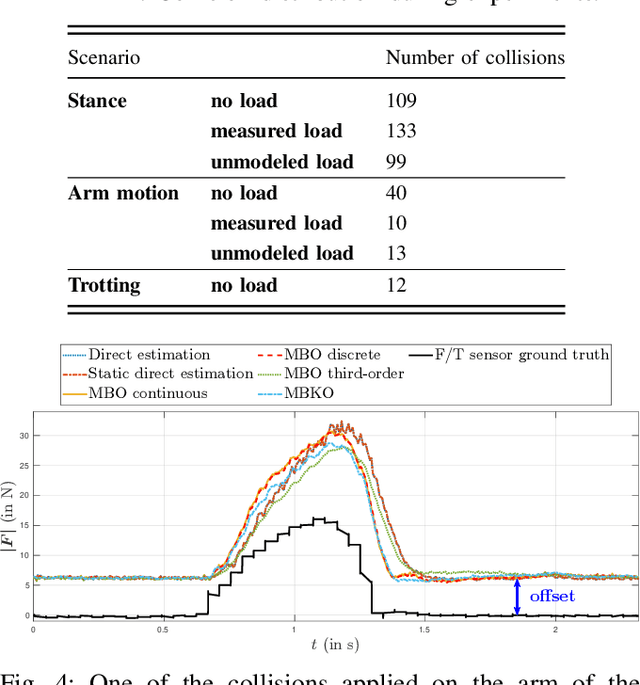
To safely deploy legged robots in the real world it is necessary to provide them with the ability to reliably detect unexpected contacts and accurately estimate the corresponding contact force. In this paper, we propose a collision detection and identification pipeline for a quadrupedal manipulator. We first introduce an approach to estimate the collision time span based on band-pass filtering and show that this information is key for obtaining accurate collision force estimates. We then improve the accuracy of the identified force magnitude by compensating for model inaccuracies, unmodeled loads, and any other potential source of quasi-static disturbances acting on the robot. We validate our framework with extensive hardware experiments in various scenarios, including trotting and additional unmodeled load on the robot.
Sub-aperture SAR Imaging with Uncertainty Quantification
Aug 25, 2022
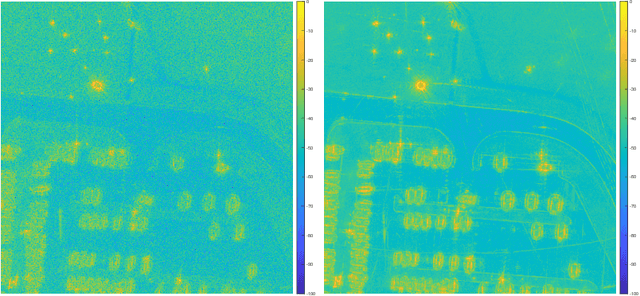
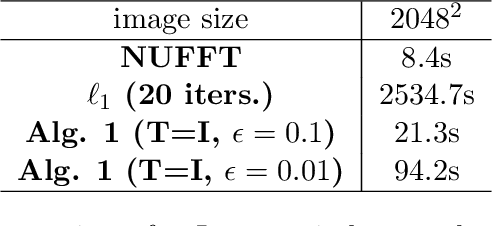
In the problem of spotlight mode airborne synthetic aperture radar (SAR) image formation, it is well-known that data collected over a wide azimuthal angle violate the isotropic scattering property typically assumed. Many techniques have been proposed to account for this issue, including both full-aperture and sub-aperture methods based on filtering, regularized least squares, and Bayesian methods. A full-aperture method that uses a hierarchical Bayesian prior to incorporate appropriate speckle modeling and reduction was recently introduced to produce samples of the posterior density rather than a single image estimate. This uncertainty quantification information is more robust as it can generate a variety of statistics for the scene. As proposed, the method was not well-suited for large problems, however, as the sampling was inefficient. Moreover, the method was not explicitly designed to mitigate the effects of the faulty isotropic scattering assumption. In this work we therefore propose a new sub-aperture SAR imaging method that uses a sparse Bayesian learning-type algorithm to more efficiently produce approximate posterior densities for each sub-aperture window. These estimates may be useful in and of themselves, or when of interest, the statistics from these distributions can be combined to form a composite image. Furthermore, unlike the often-employed lp-regularized least squares methods, no user-defined parameters are required. Application-specific adjustments are made to reduce the typically burdensome runtime and storage requirements so that appropriately large images can be generated. Finally, this paper focuses on incorporating these techniques into SAR image formation process. That is, for the problem starting with SAR phase history data, so that no additional processing errors are incurred.
An Information-Theoretic Analysis of The Cost of Decentralization for Learning and Inference Under Privacy Constraints
Oct 11, 2021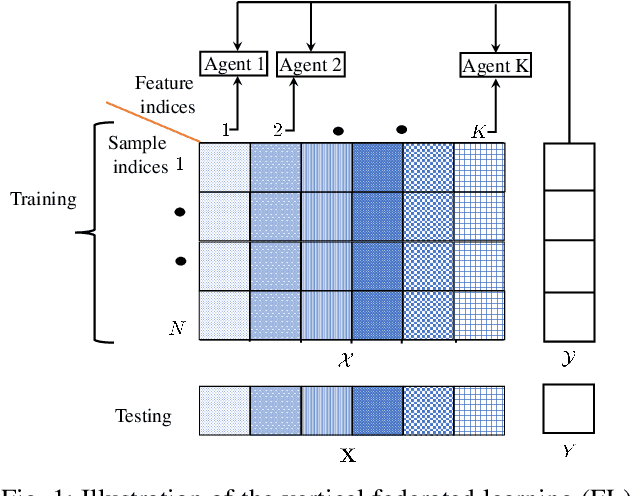
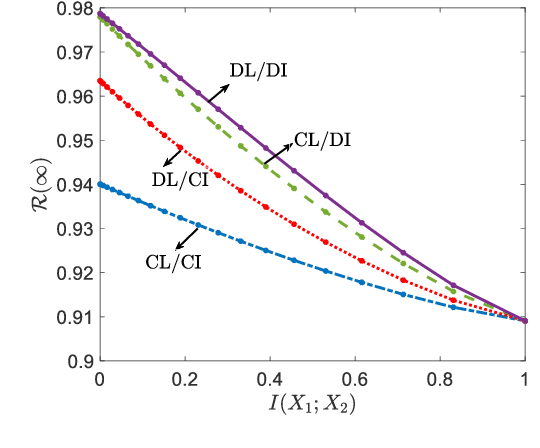
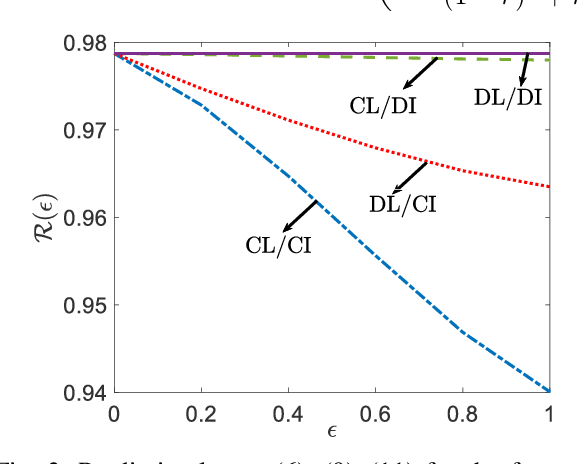

In vertical federated learning (FL), the features of a data sample are distributed across multiple agents. As such, inter-agent collaboration can be beneficial not only during the learning phase, as is the case for standard horizontal FL, but also during the inference phase. A fundamental theoretical question in this setting is how to quantify the cost, or performance loss, of decentralization for learning and/or inference. In this paper, we consider general supervised learning problems with any number of agents, and provide a novel information-theoretic quantification of the cost of decentralization in the presence of privacy constraints on inter-agent communication within a Bayesian framework. The cost of decentralization for learning and/or inference is shown to be quantified in terms of conditional mutual information terms involving features and label variables.
An Ontology-Based Information Extraction System for Residential Land Use Suitability Analysis
Sep 16, 2021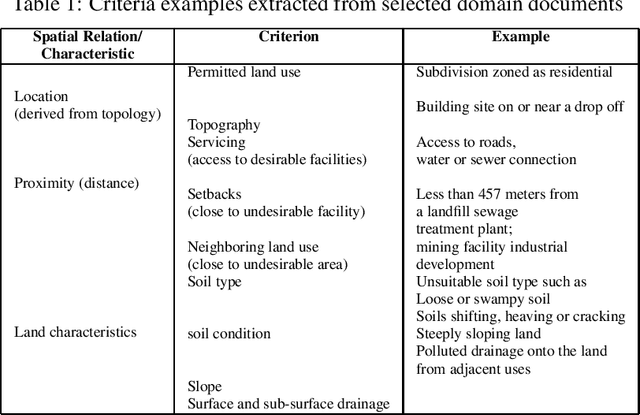
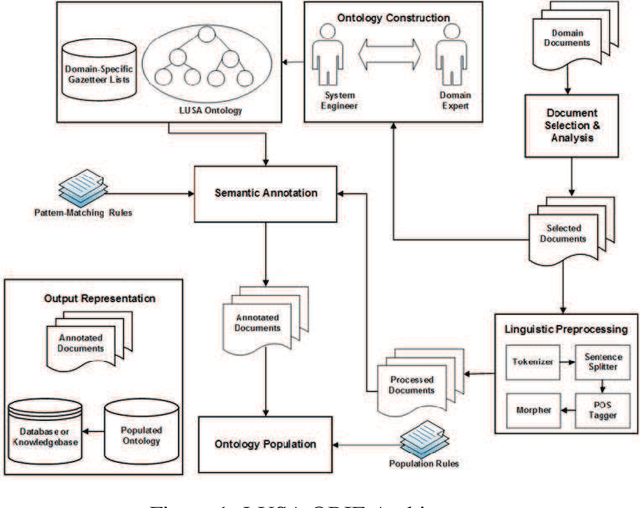
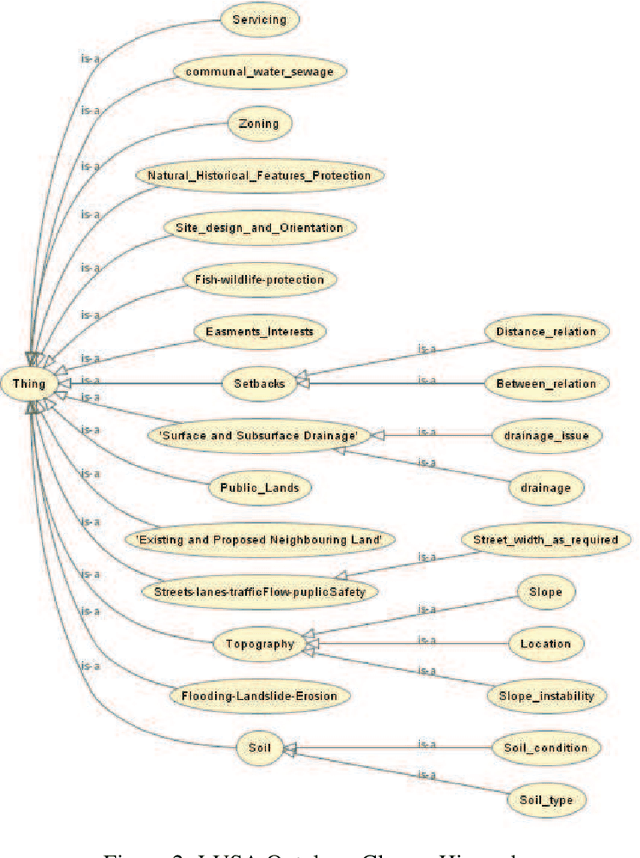
We propose an Ontology-Based Information Extraction (OBIE) system to automate the extraction of the criteria and values applied in Land Use Suitability Analysis (LUSA) from bylaw and regulation documents related to the geographic area of interest. The results obtained by our proposed LUSA OBIE system (land use suitability criteria and their values) are presented as an ontology populated with instances of the extracted criteria and property values. This latter output ontology is incorporated into a Multi-Criteria Decision Making (MCDM) model applied for constructing suitability maps for different kinds of land uses. The resulting maps may be the final desired product or can be incorporated into the cellular automata urban modeling and simulation for predicting future urban growth. A case study has been conducted where the output from LUSA OBIE is applied to help produce a suitability map for the City of Regina, Saskatchewan, to assist in the identification of suitable areas for residential development. A set of Saskatchewan bylaw and regulation documents were downloaded and input to the LUSA OBIE system. We accessed the extracted information using both the populated LUSA ontology and the set of annotated documents. In this regard, the LUSA OBIE system was effective in producing a final suitability map.
Skin Lesion Analysis: A State-of-the-Art Survey, Systematic Review, and Future Trends
Aug 25, 2022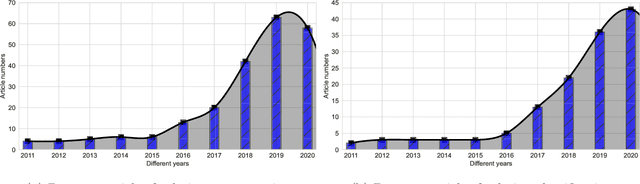
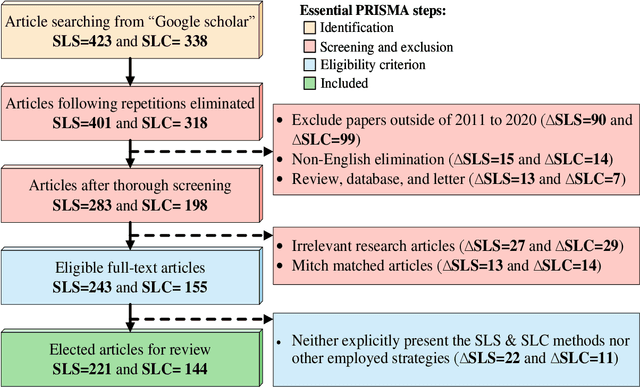
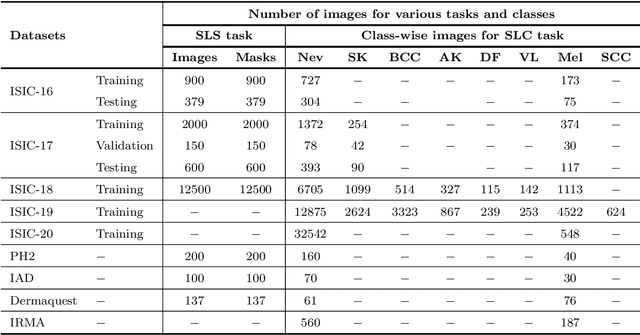
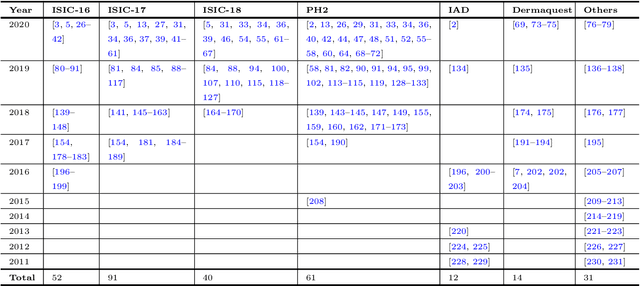
The Computer-aided Diagnosis (CAD) system for skin lesion analysis is an emerging field of research that has the potential to relieve the burden and cost of skin cancer screening. Researchers have recently indicated increasing interest in developing such CAD systems, with the intention of providing a user-friendly tool to dermatologists in order to reduce the challenges that are raised by manual inspection. The purpose of this article is to provide a complete literature review of cutting-edge CAD techniques published between 2011 and 2020. The Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) method was used to identify a total of 365 publications, 221 for skin lesion segmentation and 144 for skin lesion classification. These articles are analyzed and summarized in a number of different ways so that we can contribute vital information about the methods for the evolution of CAD systems. These ways include: relevant and essential definitions and theories, input data (datasets utilization, preprocessing, augmentations, and fixing imbalance problems), method configuration (techniques, architectures, module frameworks, and losses), training tactics (hyperparameter settings), and evaluation criteria (metrics). We also intend to investigate a variety of performance-enhancing methods, including ensemble and post-processing. In addition, in this survey, we highlight the primary problems associated with evaluating skin lesion segmentation and classification systems using minimal datasets, as well as the potential solutions to these plights. In conclusion, enlightening findings, recommendations, and trends are discussed for the purpose of future research surveillance in related fields of interest. It is foreseen that it will guide researchers of all levels, from beginners to experts, in the process of developing an automated and robust CAD system for skin lesion analysis.
Fast T2w/FLAIR MRI Acquisition by Optimal Sampling of Information Complementary to Pre-acquired T1w MRI
Nov 11, 2021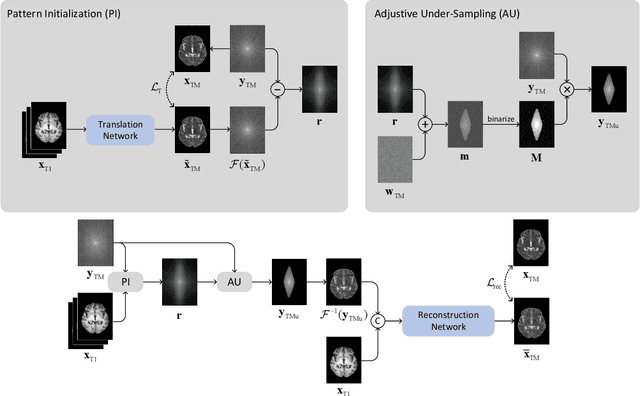
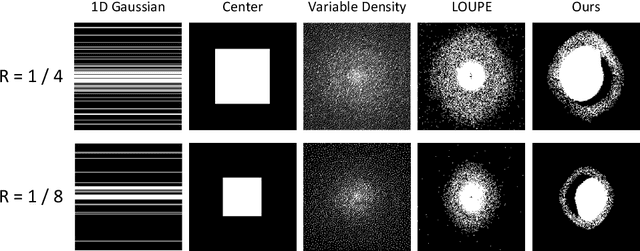

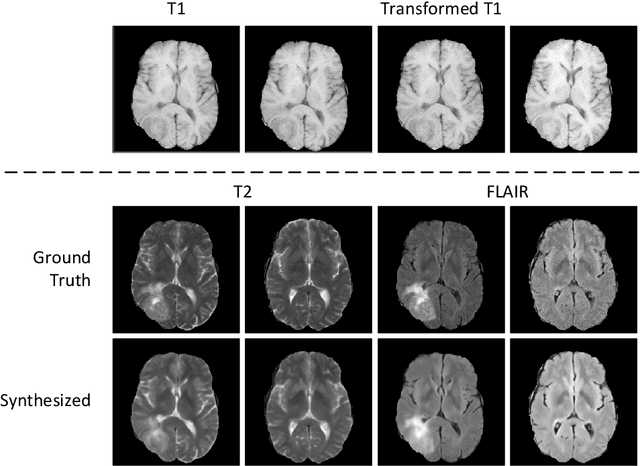
Recent studies on T1-assisted MRI reconstruction for under-sampled images of other modalities have demonstrated the potential of further accelerating MRI acquisition of other modalities. Most of the state-of-the-art approaches have achieved improvement through the development of network architectures for fixed under-sampling patterns, without fully exploiting the complementary information between modalities. Although existing under-sampling pattern learning algorithms can be simply modified to allow the fully-sampled T1-weighted MR image to assist the pattern learning, no significant improvement on the reconstruction task can be achieved. To this end, we propose an iterative framework to optimize the under-sampling pattern for MRI acquisition of another modality that can complement the fully-sampled T1-weighted MR image at different under-sampling factors, while jointly optimizing the T1-assisted MRI reconstruction model. Specifically, our proposed method exploits the difference of latent information between the two modalities for determining the sampling patterns that can maximize the assistance power of T1-weighted MR image in improving the MRI reconstruction. We have demonstrated superior performance of our learned under-sampling patterns on a public dataset, compared to commonly used under-sampling patterns and state-of-the-art methods that can jointly optimize both the reconstruction network and the under-sampling pattern, up to 8-fold under-sampling factor.
Matching with AffNet based rectifications
Jul 29, 2022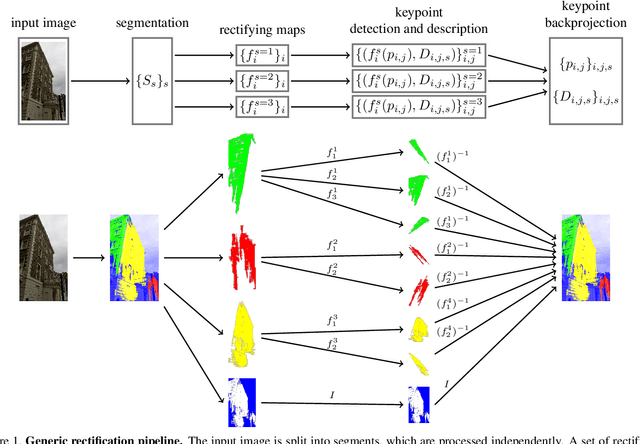
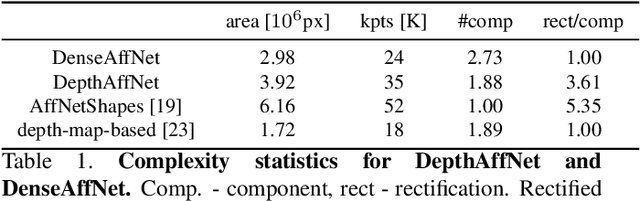
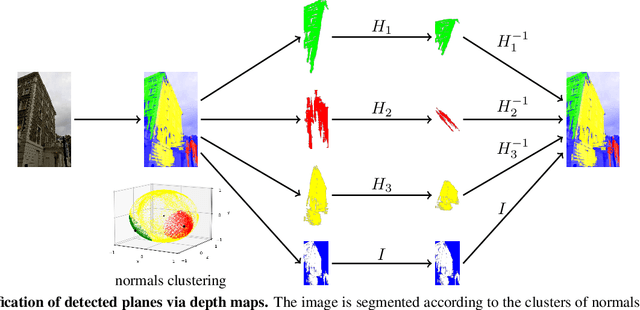

We consider the problem of two-view matching under significant viewpoint changes with view synthesis. We propose two novel methods, minimizing the view synthesis overhead. The first one, named DenseAffNet, uses dense affine shapes estimates from AffNet, which allows it to partition the image, rectifying each partition with just a single affine map. The second one, named DepthAffNet, combines information from depth maps and affine shapes estimates to produce different sets of rectifying affine maps for different image partitions. DenseAffNet is faster than the state-of-the-art and more accurate on generic scenes. DepthAffNet is on par with the state of the art on scenes containing large planes. The evaluation is performed on 3 public datasets - EVD Dataset, Strong ViewPoint Changes Dataset and IMC Phototourism Dataset.
Effective Few-Shot Named Entity Linking by Meta-Learning
Jul 19, 2022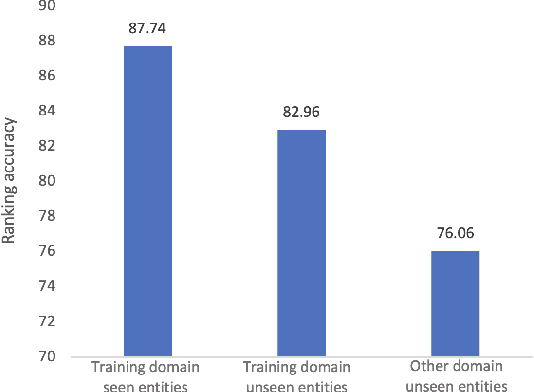
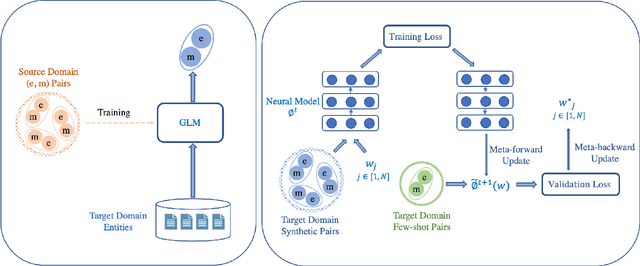
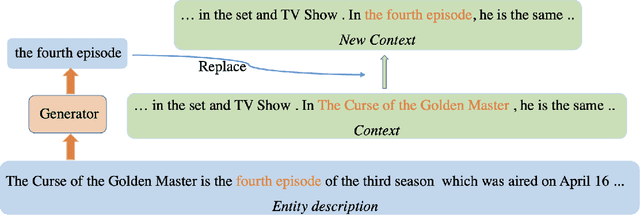
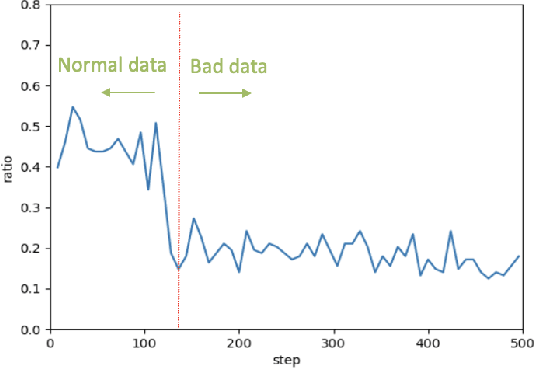
Entity linking aims to link ambiguous mentions to their corresponding entities in a knowledge base, which is significant and fundamental for various downstream applications, e.g., knowledge base completion, question answering, and information extraction. While great efforts have been devoted to this task, most of these studies follow the assumption that large-scale labeled data is available. However, when the labeled data is insufficient for specific domains due to labor-intensive annotation work, the performance of existing algorithms will suffer an intolerable decline. In this paper, we endeavor to solve the problem of few-shot entity linking, which only requires a minimal amount of in-domain labeled data and is more practical in real situations. Specifically, we firstly propose a novel weak supervision strategy to generate non-trivial synthetic entity-mention pairs based on mention rewriting. Since the quality of the synthetic data has a critical impact on effective model training, we further design a meta-learning mechanism to assign different weights to each synthetic entity-mention pair automatically. Through this way, we can profoundly exploit rich and precious semantic information to derive a well-trained entity linking model under the few-shot setting. The experiments on real-world datasets show that the proposed method can extensively improve the state-of-the-art few-shot entity linking model and achieve impressive performance when only a small amount of labeled data is available. Moreover, we also demonstrate the outstanding ability of the model's transferability.
Part-of-Speech Tagging of Odia Language Using statistical and Deep Learning-Based Approaches
Jul 07, 2022



Automatic Part-of-speech (POS) tagging is a preprocessing step of many natural language processing (NLP) tasks such as name entity recognition (NER), speech processing, information extraction, word sense disambiguation, and machine translation. It has already gained a promising result in English and European languages, but in Indian languages, particularly in Odia language, it is not yet well explored because of the lack of supporting tools, resources, and morphological richness of language. Unfortunately, we were unable to locate an open source POS tagger for Odia, and only a handful of attempts have been made to develop POS taggers for Odia language. The main contribution of this research work is to present a conditional random field (CRF) and deep learning-based approaches (CNN and Bidirectional Long Short-Term Memory) to develop Odia part-of-speech tagger. We used a publicly accessible corpus and the dataset is annotated with the Bureau of Indian Standards (BIS) tagset. However, most of the languages around the globe have used the dataset annotated with Universal Dependencies (UD) tagset. Hence, to maintain uniformity Odia dataset should use the same tagset. So we have constructed a simple mapping from BIS tagset to UD tagset. We experimented with various feature set inputs to the CRF model, observed the impact of constructed feature set. The deep learning-based model includes Bi-LSTM network, CNN network, CRF layer, character sequence information, and pre-trained word vector. Character sequence information was extracted by using convolutional neural network (CNN) and Bi-LSTM network. Six different combinations of neural sequence labelling models are implemented, and their performance measures are investigated. It has been observed that Bi-LSTM model with character sequence feature and pre-trained word vector achieved a significant state-of-the-art result.
HaloAE: An HaloNet based Local Transformer Auto-Encoder for Anomaly Detection and Localization
Aug 06, 2022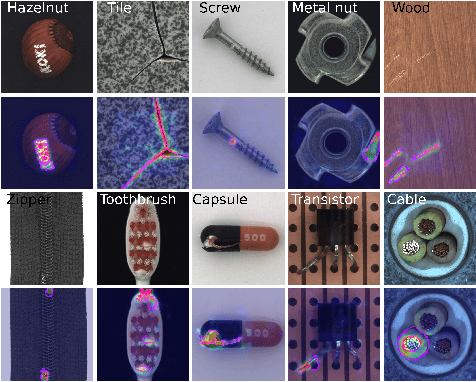

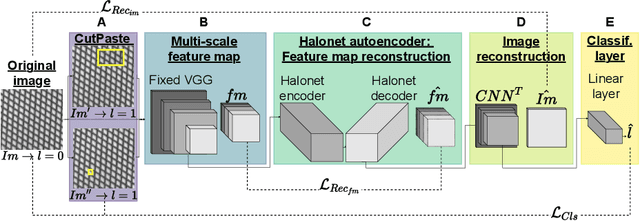
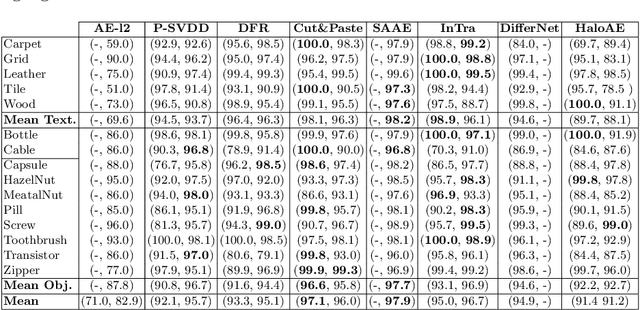
Unsupervised anomaly detection and localization is a crucial task as it is impossible to collect and label all possible anomalies. Many studies have emphasized the importance of integrating local and global information to achieve accurate segmentation of anomalies. To this end, there has been a growing interest in Transformer, which allows modeling long-range content interactions. However, global interactions through self attention are generally too expensive for most image scales. In this study, we introduce HaloAE, the first auto-encoder based on a local 2D version of Transformer with HaloNet. With HaloAE, we have created a hybrid model that combines convolution and local 2D block-wise self-attention layers and jointly performs anomaly detection and segmentation through a single model. We achieved competitive results on the MVTec dataset, suggesting that vision models incorporating Transformer could benefit from a local computation of the self-attention operation, and pave the way for other applications.