 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Training Process of Unsupervised Learning Architecture for Gravity Spy Dataset
Aug 07, 2022
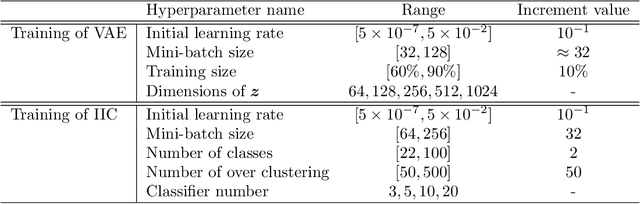
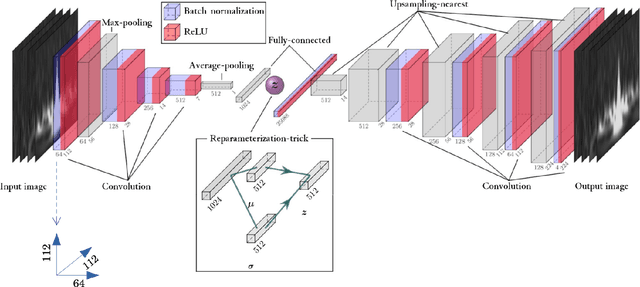
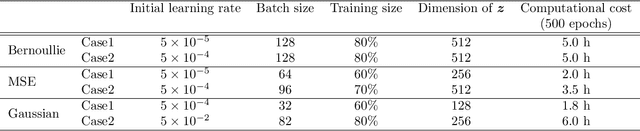
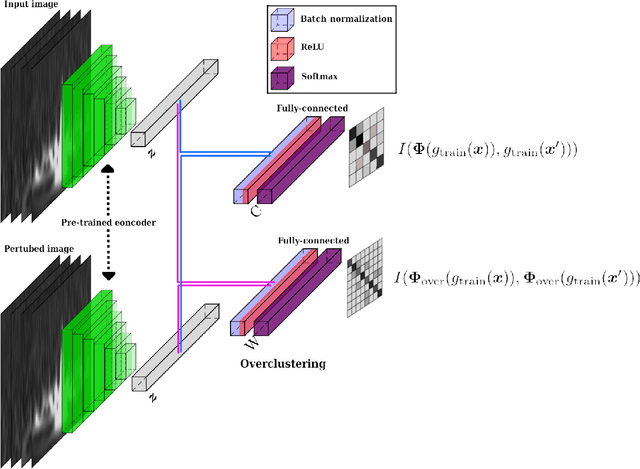
Transient noise appearing in the data from gravitational-wave detectors frequently causes problems, such as instability of the detectors and overlapping or mimicking gravitational-wave signals. Because transient noise is considered to be associated with the environment and instrument, its classification would help to understand its origin and improve the detector's performance. In a previous study, an architecture for classifying transient noise using a time-frequency 2D image (spectrogram) is proposed, which uses unsupervised deep learning combined with variational autoencoder and invariant information clustering. The proposed unsupervised-learning architecture is applied to the Gravity Spy dataset, which consists of Advanced Laser Interferometer Gravitational-Wave Observatory (Advanced LIGO) transient noises with their associated metadata to discuss the potential for online or offline data analysis. In this study, focused on the Gravity Spy dataset, the training process of unsupervised-learning architecture of the previous study is examined and reported.
* 17 pages, 10 figures, Matches version published in Annalen der Physik
Robust DNN Watermarking via Fixed Embedding Weights with Optimized Distribution
Aug 23, 2022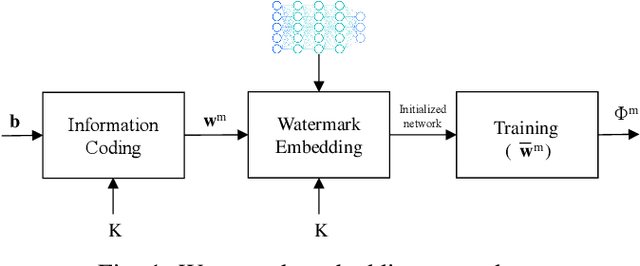
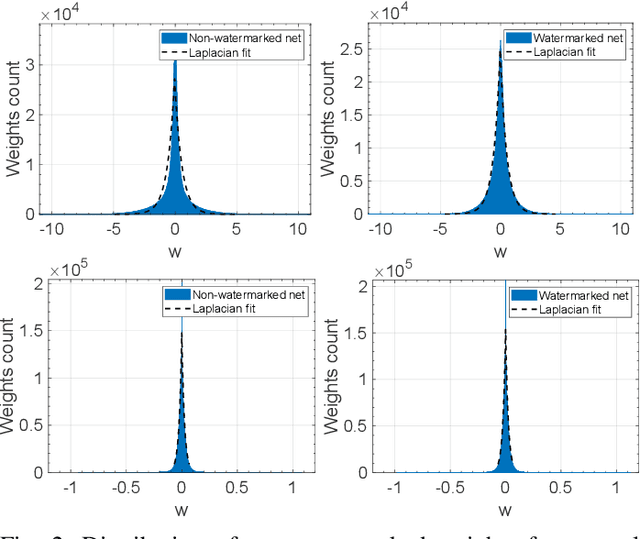
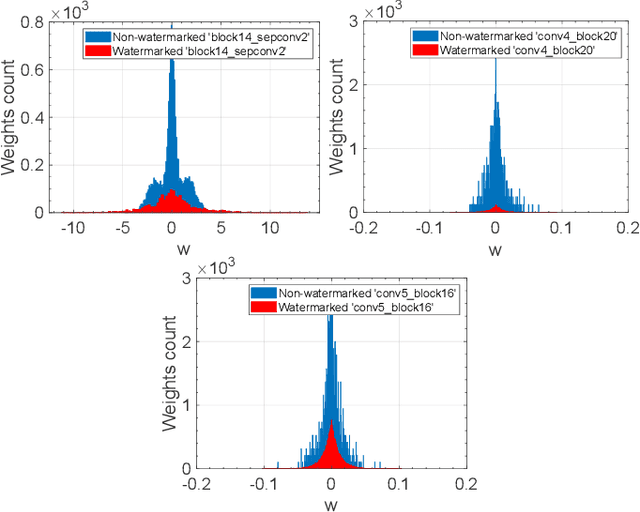
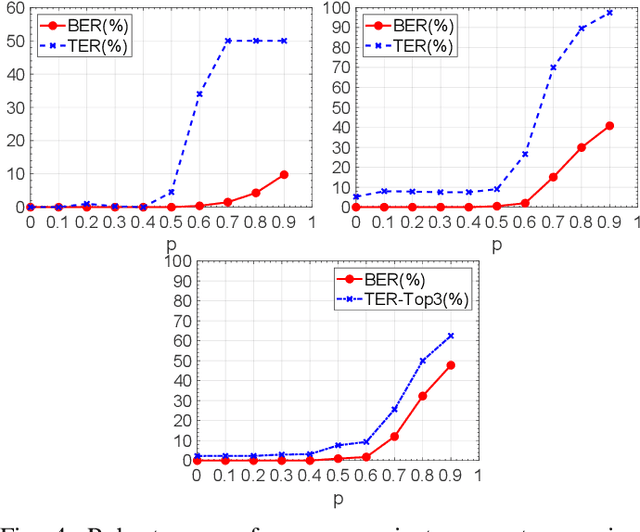
Watermarking has been proposed as a way to protect the Intellectual Property Rights (IPR) of Deep Neural Networks (DNNs) and track their use. Several methods have been proposed that embed the watermark into the trainable parameters of the network (white box watermarking) or into the input-output mappping implemented by the network in correspondence to specific inputs (black box watermarking). In both cases, achieving robustness against fine tuning, model compression and, even more, transfer learning, is one of the most difficult challenges researchers are trying to face with. In this paper, we propose a new white-box, multi-bit watermarking algorithm with strong robustness properties, including retraining for transfer learning. Robustness is achieved thanks to a new information coding strategy according to which the watermark message is spread across a number of fixed weights, whose position depends on a secret key. The weights hosting the watermark are set prior to training, and are left unchanged throughout the entire training procedure. The distribution of the weights carrying out the message is theoretically optimised to make sure that the watermarked weights are indistinguishable from the other weights, while at the same time keeping their amplitude as large as possible to improve robustness against retraining. We carried out several experiments demonstrating the capability of the proposed scheme to provide high payloads with practically no impact on the network accuracy, at the same time retaining excellent robustness against network modifications an re-use, including retraining for transfer learning.
NeuralVDB: High-resolution Sparse Volume Representation using Hierarchical Neural Networks
Aug 08, 2022

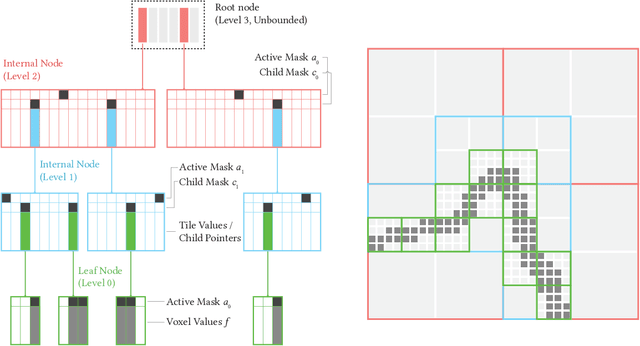
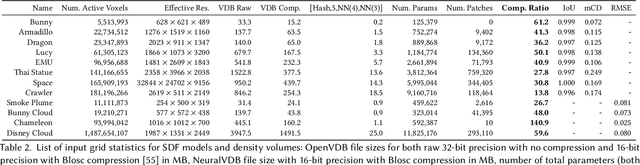
We introduce NeuralVDB, which improves on an existing industry standard for efficient storage of sparse volumetric data, denoted VDB, by leveraging recent advancements in machine learning. Our novel hybrid data structure can reduce the memory footprints of VDB volumes by orders of magnitude, while maintaining its flexibility and only incurring a small (user-controlled) compression errors. Specifically, NeuralVDB replaces the lower nodes of a shallow and wide VDB tree structure with multiple hierarchy neural networks that separately encode topology and value information by means of neural classifiers and regressors respectively. This approach has proven to maximize the compression ratio while maintaining the spatial adaptivity offered by the higher-level VDB data structure. For sparse signed distance fields and density volumes, we have observed compression ratios on the order of $10\times$ to more than $100\times$ from already compressed VDB inputs, with little to no visual artifacts. We also demonstrate how its application to animated sparse volumes can both accelerate training and generate temporally coherent neural networks.
DiSCoMaT: Distantly Supervised Composition Extraction from Tables in Materials Science Articles
Jul 10, 2022

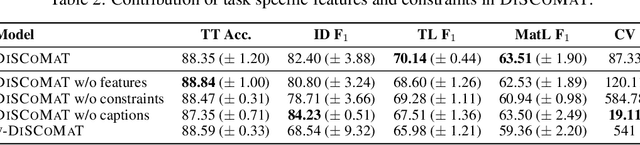
A crucial component in the curation of KB for a scientific domain is information extraction from tables in the domain's published articles -- tables carry important information (often numeric), which must be adequately extracted for a comprehensive machine understanding of an article. Existing table extractors assume prior knowledge of table structure and format, which may not be known in scientific tables. We study a specific and challenging table extraction problem: extracting compositions of materials (e.g., glasses, alloys). We first observe that materials science researchers organize similar compositions in a wide variety of table styles, necessitating an intelligent model for table understanding and composition extraction. Consequently, we define this novel task as a challenge for the ML community and create a training dataset comprising 4,408 distantly supervised tables, along with 1,475 manually annotated dev and test tables. We also present DiSCoMaT, a strong baseline geared towards this specific task, which combines multiple graph neural networks with several task-specific regular expressions, features, and constraints. We show that DiSCoMaT outperforms recent table processing architectures by significant margins.
Fuse It More Deeply! A Variational Transformer with Layer-Wise Latent Variable Inference for Text Generation
Jul 13, 2022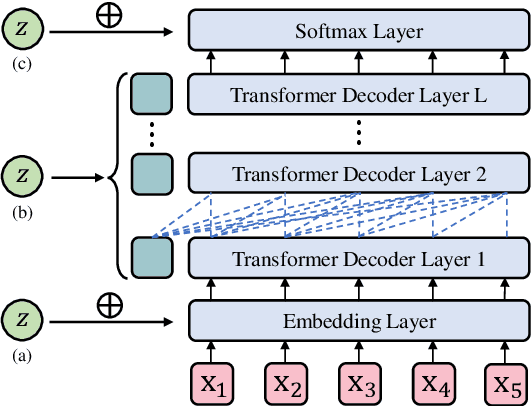
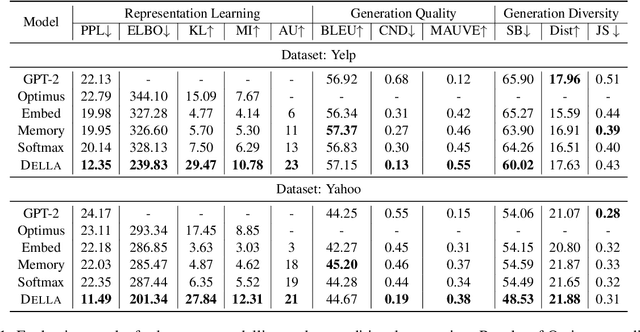
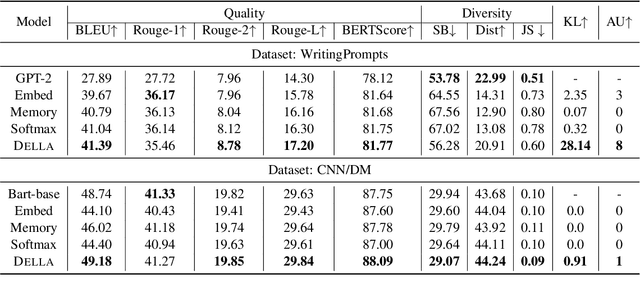
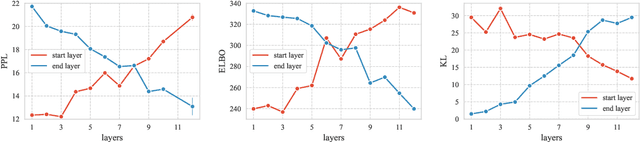
The past several years have witnessed Variational Auto-Encoder's superiority in various text generation tasks. However, due to the sequential nature of the text, auto-regressive decoders tend to ignore latent variables and then reduce to simple language models, known as the KL vanishing problem, which would further deteriorate when VAE is combined with Transformer-based structures. To ameliorate this problem, we propose DELLA, a novel variational Transformer framework. DELLA learns a series of layer-wise latent variables with each inferred from those of lower layers and tightly coupled with the hidden states by low-rank tensor product. In this way, DELLA forces these posterior latent variables to be fused deeply with the whole computation path and hence incorporate more information. We theoretically demonstrate that our method can be regarded as entangling latent variables to avoid posterior information decrease through layers, enabling DELLA to get higher non-zero KL values even without any annealing or thresholding tricks. Experiments on four unconditional and three conditional generation tasks show that DELLA could better alleviate KL vanishing and improve both quality and diversity compared to several strong baselines.
Reliable Representations Make A Stronger Defender: Unsupervised Structure Refinement for Robust GNN
Jun 30, 2022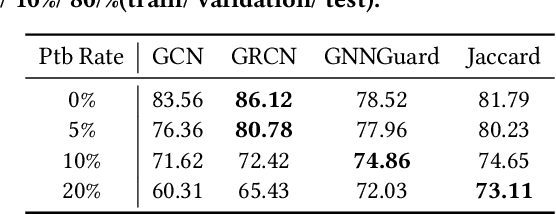
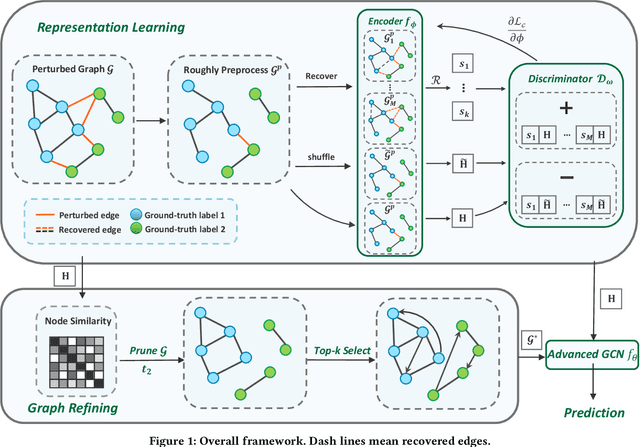
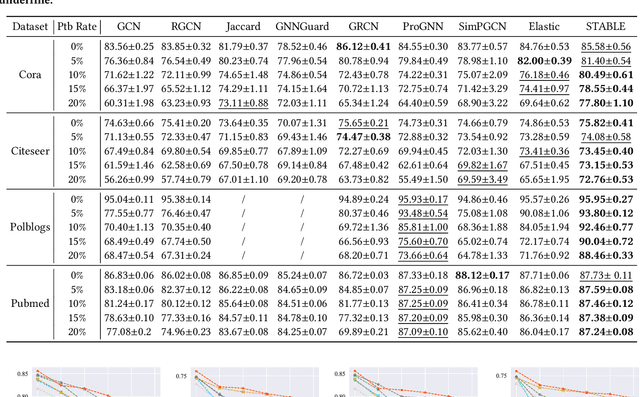
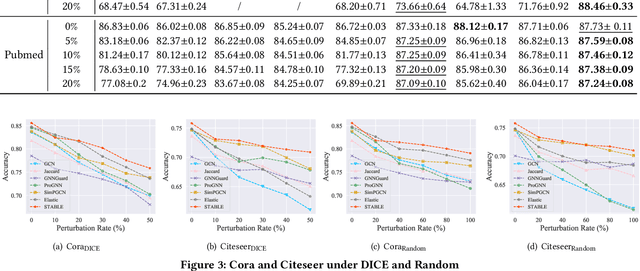
Benefiting from the message passing mechanism, Graph Neural Networks (GNNs) have been successful on flourish tasks over graph data. However, recent studies have shown that attackers can catastrophically degrade the performance of GNNs by maliciously modifying the graph structure. A straightforward solution to remedy this issue is to model the edge weights by learning a metric function between pairwise representations of two end nodes, which attempts to assign low weights to adversarial edges. The existing methods use either raw features or representations learned by supervised GNNs to model the edge weights. However, both strategies are faced with some immediate problems: raw features cannot represent various properties of nodes (e.g., structure information), and representations learned by supervised GNN may suffer from the poor performance of the classifier on the poisoned graph. We need representations that carry both feature information and as mush correct structure information as possible and are insensitive to structural perturbations. To this end, we propose an unsupervised pipeline, named STABLE, to optimize the graph structure. Finally, we input the well-refined graph into a downstream classifier. For this part, we design an advanced GCN that significantly enhances the robustness of vanilla GCN without increasing the time complexity. Extensive experiments on four real-world graph benchmarks demonstrate that STABLE outperforms the state-of-the-art methods and successfully defends against various attacks.
Semi-Supervised Cross-Modal Salient Object Detection with U-Structure Networks
Aug 08, 2022
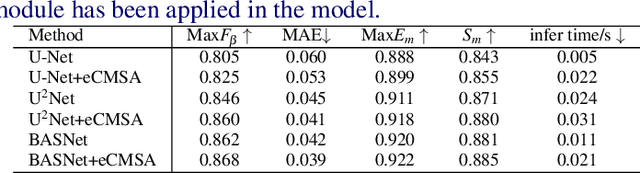

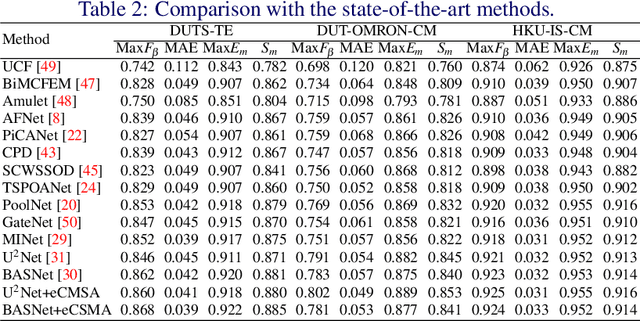
Salient Object Detection (SOD) is a popular and important topic aimed at precise detection and segmentation of the interesting regions in the images. We integrate the linguistic information into the vision-based U-Structure networks designed for salient object detection tasks. The experiments are based on the newly created DUTS Cross Modal (DUTS-CM) dataset, which contains both visual and linguistic labels. We propose a new module called efficient Cross-Modal Self-Attention (eCMSA) to combine visual and linguistic features and improve the performance of the original U-structure networks. Meanwhile, to reduce the heavy burden of labeling, we employ a semi-supervised learning method by training an image caption model based on the DUTS-CM dataset, which can automatically label other datasets like DUT-OMRON and HKU-IS. The comprehensive experiments show that the performance of SOD can be improved with the natural language input and is competitive compared with other SOD methods.
Domain Camera Adaptation and Collaborative Multiple Feature Clustering for Unsupervised Person Re-ID
Aug 18, 2022
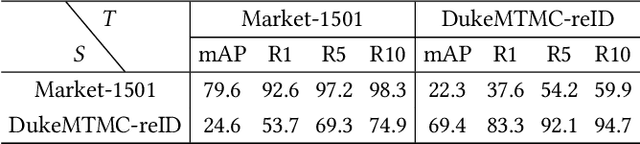
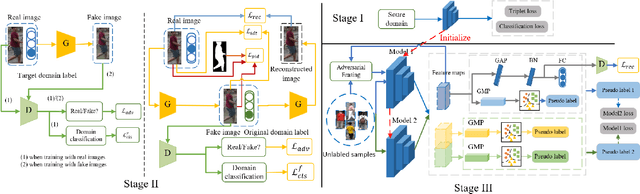
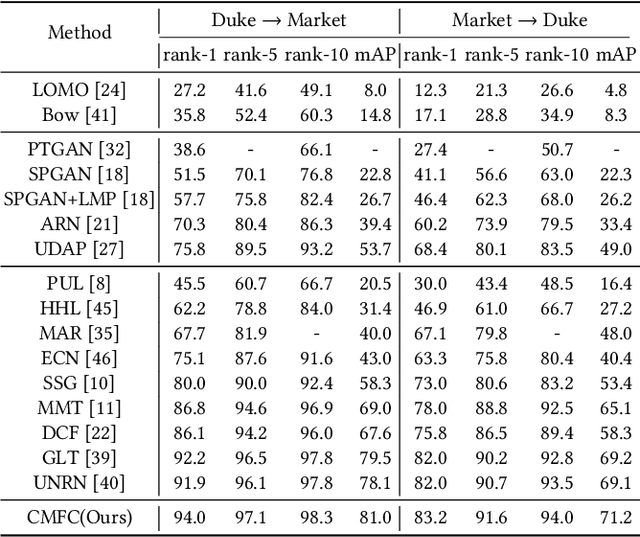
Recently unsupervised person re-identification (re-ID) has drawn much attention due to its open-world scenario settings where limited annotated data is available. Existing supervised methods often fail to generalize well on unseen domains, while the unsupervised methods, mostly lack multi-granularity information and are prone to suffer from confirmation bias. In this paper, we aim at finding better feature representations on the unseen target domain from two aspects, 1) performing unsupervised domain adaptation on the labeled source domain and 2) mining potential similarities on the unlabeled target domain. Besides, a collaborative pseudo re-labeling strategy is proposed to alleviate the influence of confirmation bias. Firstly, a generative adversarial network is utilized to transfer images from the source domain to the target domain. Moreover, person identity preserving and identity mapping losses are introduced to improve the quality of generated images. Secondly, we propose a novel collaborative multiple feature clustering framework (CMFC) to learn the internal data structure of target domain, including global feature and partial feature branches. The global feature branch (GB) employs unsupervised clustering on the global feature of person images while the Partial feature branch (PB) mines similarities within different body regions. Finally, extensive experiments on two benchmark datasets show the competitive performance of our method under unsupervised person re-ID settings.
Constrained self-supervised method with temporal ensembling for fiber bundle detection on anatomic tracing data
Aug 06, 2022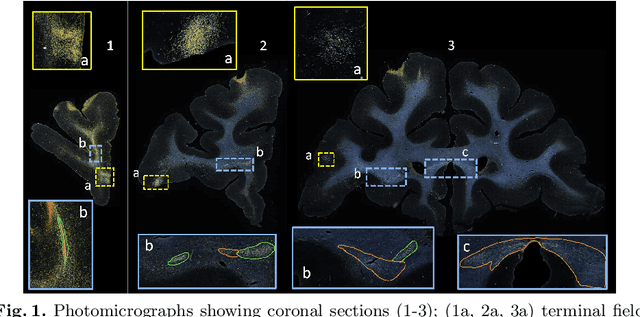
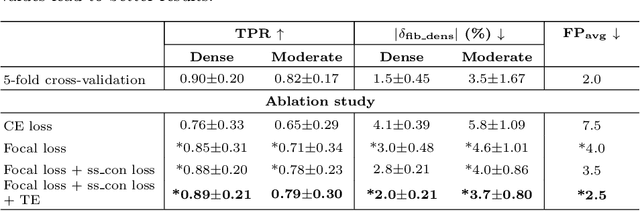
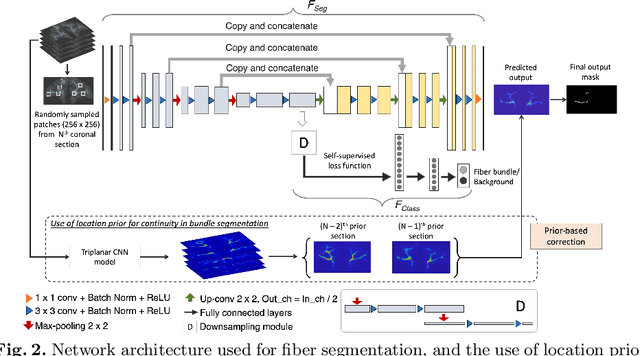
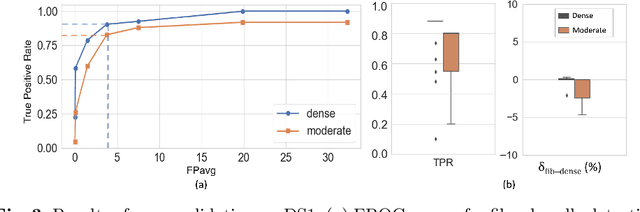
Anatomic tracing data provides detailed information on brain circuitry essential for addressing some of the common errors in diffusion MRI tractography. However, automated detection of fiber bundles on tracing data is challenging due to sectioning distortions, presence of noise and artifacts and intensity/contrast variations. In this work, we propose a deep learning method with a self-supervised loss function that takes anatomy-based constraints into account for accurate segmentation of fiber bundles on the tracer sections from macaque brains. Also, given the limited availability of manual labels, we use a semi-supervised training technique for efficiently using unlabeled data to improve the performance, and location constraints for further reduction of false positives. Evaluation of our method on unseen sections from a different macaque yields promising results with a true positive rate of ~0.90. The code for our method is available at https://github.com/v-sundaresan/fiberbundle_seg_tracing.
TrojViT: Trojan Insertion in Vision Transformers
Aug 27, 2022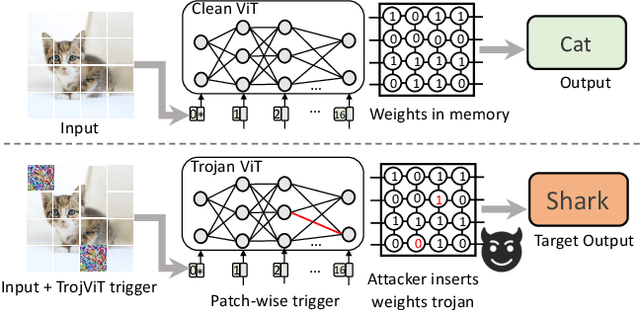

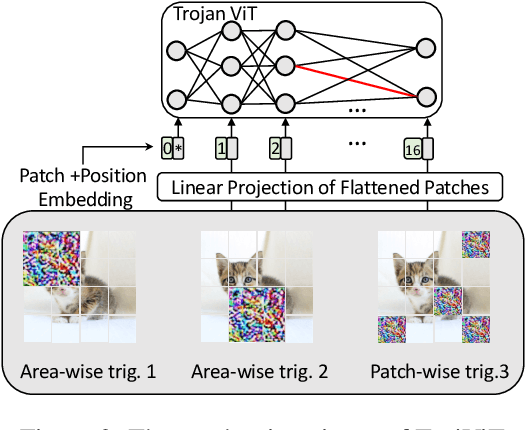
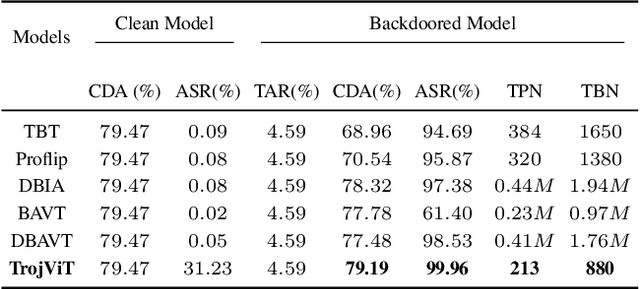
Vision Transformers (ViTs) have demonstrated the state-of-the-art performance in various vision-related tasks. The success of ViTs motivates adversaries to perform backdoor attacks on ViTs. Although the vulnerability of traditional CNNs to backdoor attacks is well-known, backdoor attacks on ViTs are seldom-studied. Compared to CNNs capturing pixel-wise local features by convolutions, ViTs extract global context information through patches and attentions. Na\"ively transplanting CNN-specific backdoor attacks to ViTs yields only a low clean data accuracy and a low attack success rate. In this paper, we propose a stealth and practical ViT-specific backdoor attack $TrojViT$. Rather than an area-wise trigger used by CNN-specific backdoor attacks, TrojViT generates a patch-wise trigger designed to build a Trojan composed of some vulnerable bits on the parameters of a ViT stored in DRAM memory through patch salience ranking and attention-target loss. TrojViT further uses minimum-tuned parameter update to reduce the bit number of the Trojan. Once the attacker inserts the Trojan into the ViT model by flipping the vulnerable bits, the ViT model still produces normal inference accuracy with benign inputs. But when the attacker embeds a trigger into an input, the ViT model is forced to classify the input to a predefined target class. We show that flipping only few vulnerable bits identified by TrojViT on a ViT model using the well-known RowHammer can transform the model into a backdoored one. We perform extensive experiments of multiple datasets on various ViT models. TrojViT can classify $99.64\%$ of test images to a target class by flipping $345$ bits on a ViT for ImageNet.