 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Judging by the Look: The Impact of Robot Gaze Strategies on Human Cooperation
Aug 25, 2022

Human eye gaze plays an important role in delivering information, communicating intent, and understanding others' mental states. Previous research shows that a robot's gaze can also affect humans' decision-making and strategy during an interaction. However, limited studies have trained humanoid robots on gaze-based data in human-robot interaction scenarios. Considering gaze impacts the naturalness of social exchanges and alters the decision process of an observer, it should be regarded as a crucial component in human-robot interaction. To investigate the impact of robot gaze on humans, we propose an embodied neural model for performing human-like gaze shifts. This is achieved by extending a social attention model and training it on eye-tracking data, collected by watching humans playing a game. We will compare human behavioral performances in the presence of a robot adopting different gaze strategies in a human-human cooperation game.
Quantization enabled Privacy Protection in Decentralized Stochastic Optimization
Aug 07, 2022
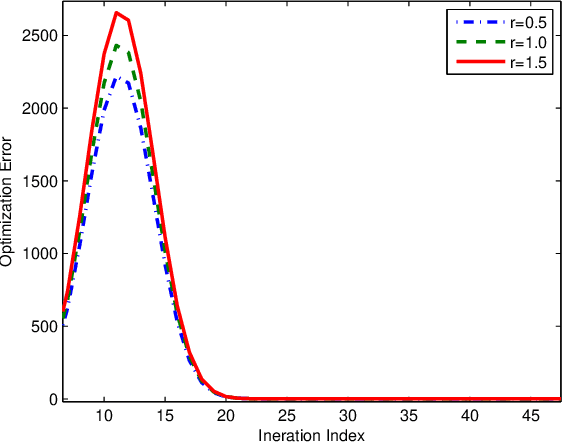
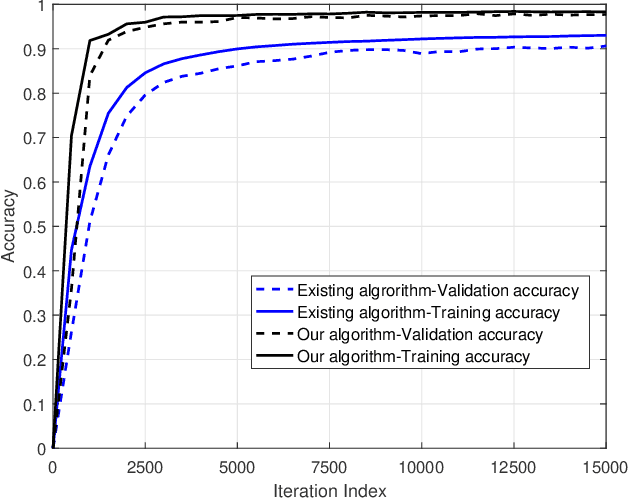
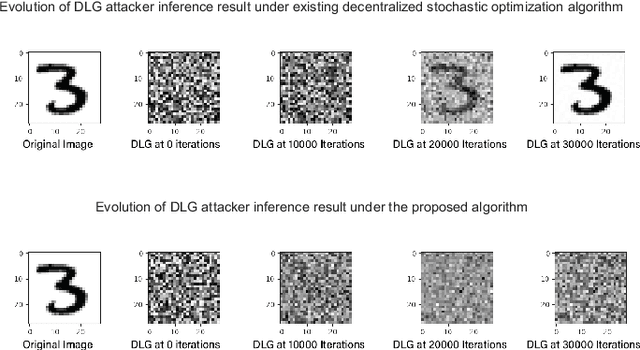
By enabling multiple agents to cooperatively solve a global optimization problem in the absence of a central coordinator, decentralized stochastic optimization is gaining increasing attention in areas as diverse as machine learning, control, and sensor networks. Since the associated data usually contain sensitive information, such as user locations and personal identities, privacy protection has emerged as a crucial need in the implementation of decentralized stochastic optimization. In this paper, we propose a decentralized stochastic optimization algorithm that is able to guarantee provable convergence accuracy even in the presence of aggressive quantization errors that are proportional to the amplitude of quantization inputs. The result applies to both convex and non-convex objective functions, and enables us to exploit aggressive quantization schemes to obfuscate shared information, and hence enables privacy protection without losing provable optimization accuracy. In fact, by using a {stochastic} ternary quantization scheme, which quantizes any value to three numerical levels, we achieve quantization-based rigorous differential privacy in decentralized stochastic optimization, which has not been reported before. In combination with the presented quantization scheme, the proposed algorithm ensures, for the first time, rigorous differential privacy in decentralized stochastic optimization without losing provable convergence accuracy. Simulation results for a distributed estimation problem as well as numerical experiments for decentralized learning on a benchmark machine learning dataset confirm the effectiveness of the proposed approach.
A Syntax Aware BERT for Identifying Well-Formed Queries in a Curriculum Framework
Aug 21, 2022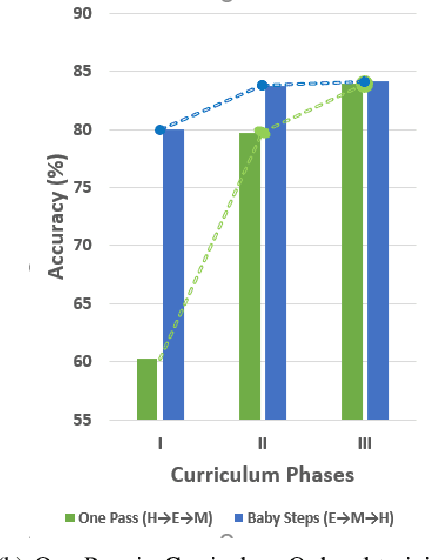
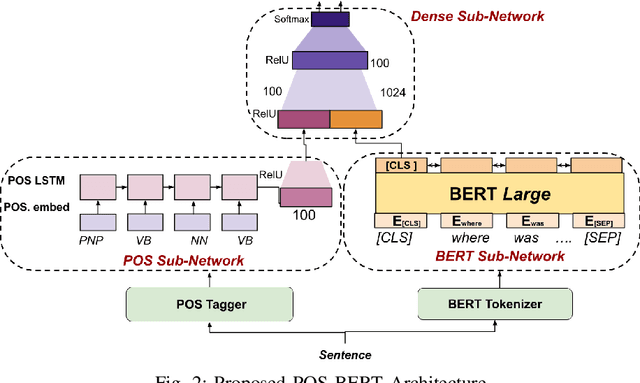
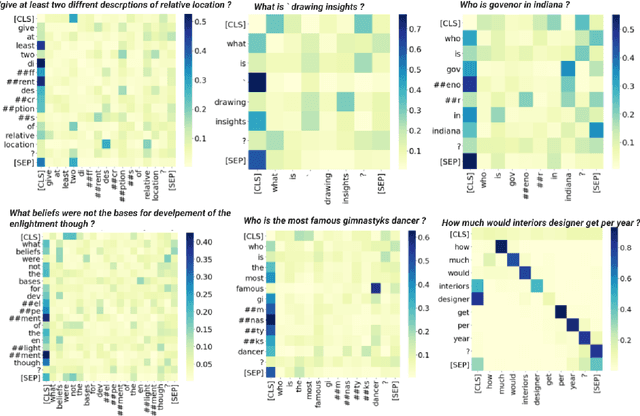

A well formed query is defined as a query which is formulated in the manner of an inquiry, and with correct interrogatives, spelling and grammar. While identifying well formed queries is an important task, few works have attempted to address it. In this paper we propose transformer based language model - Bidirectional Encoder Representations from Transformers (BERT) to this task. We further imbibe BERT with parts-of-speech information inspired from earlier works. Furthermore, we also train the model in multiple curriculum settings for improvement in performance. Curriculum Learning over the task is experimented with Baby Steps and One Pass techniques. Proposed architecture performs exceedingly well on the task. The best approach achieves accuracy of 83.93%, outperforming previous state-of-the-art at 75.0% and reaching close to the approximate human upper bound of 88.4%.
Dense Teacher: Dense Pseudo-Labels for Semi-supervised Object Detection
Jul 19, 2022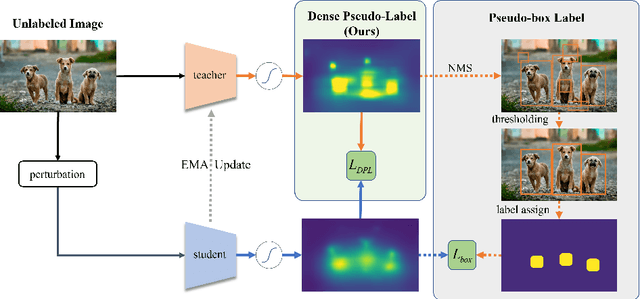
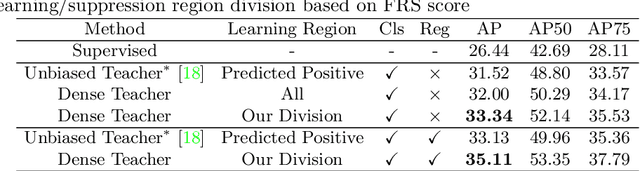
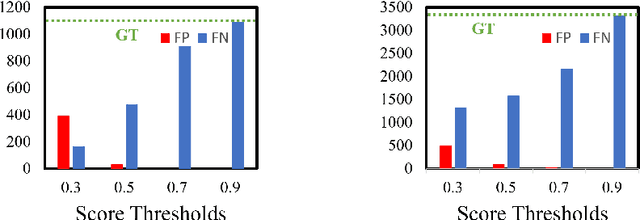
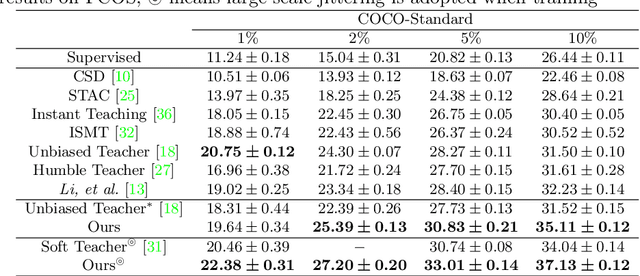
To date, the most powerful semi-supervised object detectors (SS-OD) are based on pseudo-boxes, which need a sequence of post-processing with fine-tuned hyper-parameters. In this work, we propose replacing the sparse pseudo-boxes with the dense prediction as a united and straightforward form of pseudo-label. Compared to the pseudo-boxes, our Dense Pseudo-Label (DPL) does not involve any post-processing method, thus retaining richer information. We also introduce a region selection technique to highlight the key information while suppressing the noise carried by dense labels. We name our proposed SS-OD algorithm that leverages the DPL as Dense Teacher. On COCO and VOC, Dense Teacher shows superior performance under various settings compared with the pseudo-box-based methods.
Sorting through the noise: Testing robustness of information processing in pre-trained language models
Sep 25, 2021
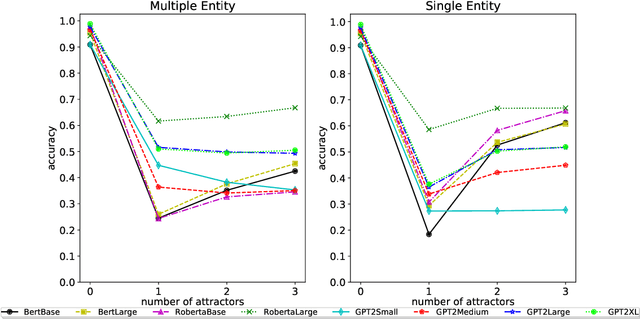
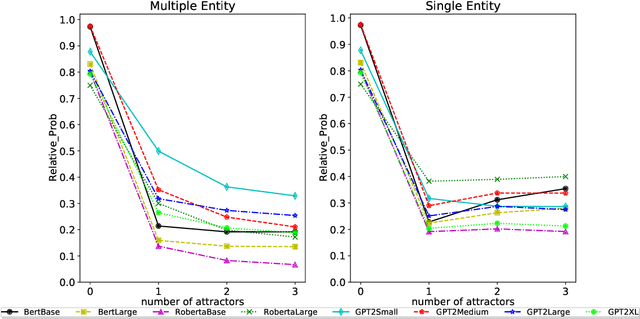
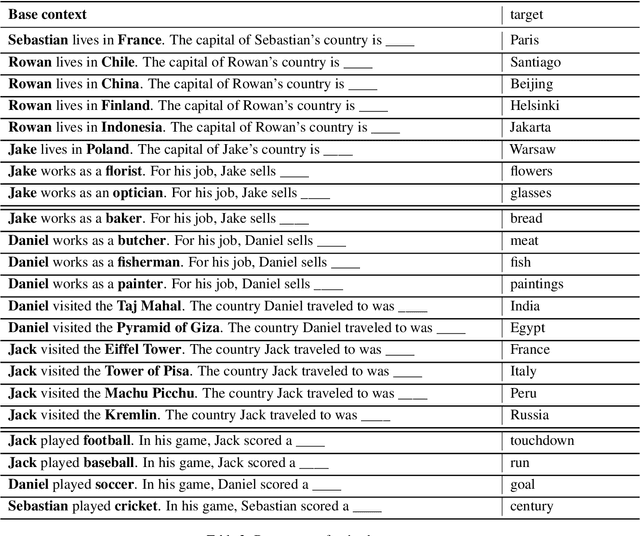
Pre-trained LMs have shown impressive performance on downstream NLP tasks, but we have yet to establish a clear understanding of their sophistication when it comes to processing, retaining, and applying information presented in their input. In this paper we tackle a component of this question by examining robustness of models' ability to deploy relevant context information in the face of distracting content. We present models with cloze tasks requiring use of critical context information, and introduce distracting content to test how robustly the models retain and use that critical information for prediction. We also systematically manipulate the nature of these distractors, to shed light on dynamics of models' use of contextual cues. We find that although models appear in simple contexts to make predictions based on understanding and applying relevant facts from prior context, the presence of distracting but irrelevant content has clear impact in confusing model predictions. In particular, models appear particularly susceptible to factors of semantic similarity and word position. The findings are consistent with the conclusion that LM predictions are driven in large part by superficial contextual cues, rather than by robust representations of context meaning.
Domain-informed graph neural networks: a quantum chemistry case study
Aug 25, 2022
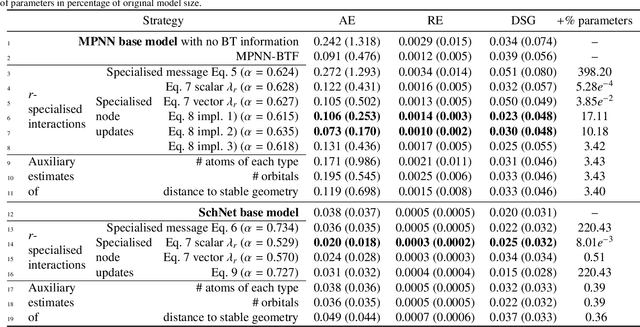
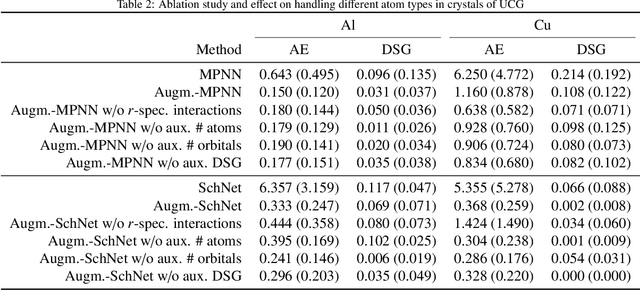
We explore different strategies to integrate prior domain knowledge into the design of a deep neural network (DNN). We focus on graph neural networks (GNN), with a use case of estimating the potential energy of chemical systems (molecules and crystals) represented as graphs. We integrate two elements of domain knowledge into the design of the GNN to constrain and regularise its learning, towards higher accuracy and generalisation. First, knowledge on the existence of different types of relations (chemical bonds) between atoms is used to modulate the interaction of nodes in the GNN. Second, knowledge of the relevance of some physical quantities is used to constrain the learnt features towards a higher physical relevance using a simple multi-task paradigm. We demonstrate the general applicability of our knowledge integrations by applying them to two architectures that rely on different mechanisms to propagate information between nodes and to update node states.
Neural Camera Models
Aug 27, 2022
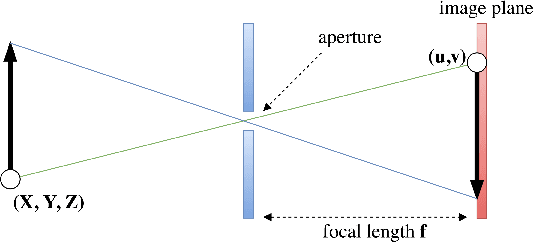

Modern computer vision has moved beyond the domain of internet photo collections and into the physical world, guiding camera-equipped robots and autonomous cars through unstructured environments. To enable these embodied agents to interact with real-world objects, cameras are increasingly being used as depth sensors, reconstructing the environment for a variety of downstream reasoning tasks. Machine-learning-aided depth perception, or depth estimation, predicts for each pixel in an image the distance to the imaged scene point. While impressive strides have been made in depth estimation, significant challenges remain: (1) ground truth depth labels are difficult and expensive to collect at scale, (2) camera information is typically assumed to be known, but is often unreliable and (3) restrictive camera assumptions are common, even though a great variety of camera types and lenses are used in practice. In this thesis, we focus on relaxing these assumptions, and describe contributions toward the ultimate goal of turning cameras into truly generic depth sensors.
Understanding Long Documents with Different Position-Aware Attentions
Aug 17, 2022
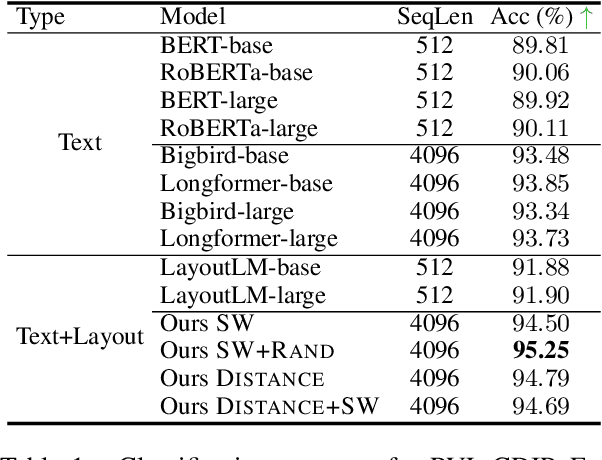
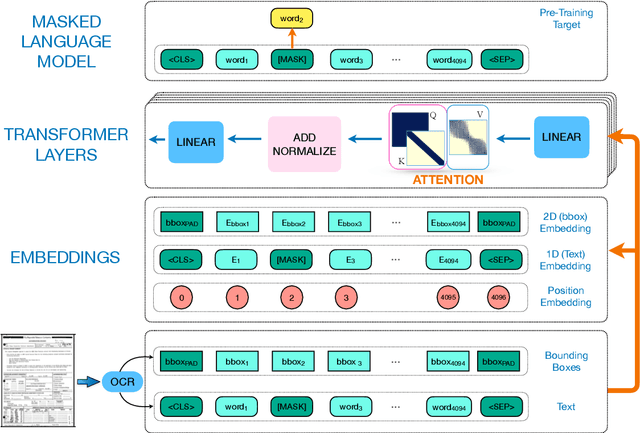
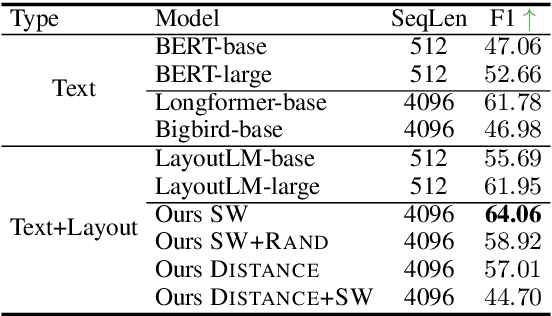
Despite several successes in document understanding, the practical task for long document understanding is largely under-explored due to several challenges in computation and how to efficiently absorb long multimodal input. Most current transformer-based approaches only deal with short documents and employ solely textual information for attention due to its prohibitive computation and memory limit. To address those issues in long document understanding, we explore different approaches in handling 1D and new 2D position-aware attention with essentially shortened context. Experimental results show that our proposed models have advantages for this task based on various evaluation metrics. Furthermore, our model makes changes only to the attention and thus can be easily adapted to any transformer-based architecture.
A Discussion of Discrimination and Fairness in Insurance Pricing
Sep 02, 2022Indirect discrimination is an issue of major concern in algorithmic models. This is particularly the case in insurance pricing where protected policyholder characteristics are not allowed to be used for insurance pricing. Simply disregarding protected policyholder information is not an appropriate solution because this still allows for the possibility of inferring the protected characteristics from the non-protected ones. This leads to so-called proxy or indirect discrimination. Though proxy discrimination is qualitatively different from the group fairness concepts in machine learning, these group fairness concepts are proposed to 'smooth out' the impact of protected characteristics in the calculation of insurance prices. The purpose of this note is to share some thoughts about group fairness concepts in the light of insurance pricing and to discuss their implications. We present a statistical model that is free of proxy discrimination, thus, unproblematic from an insurance pricing point of view. However, we find that the canonical price in this statistical model does not satisfy any of the three most popular group fairness axioms. This seems puzzling and we welcome feedback on our example and on the usefulness of these group fairness axioms for non-discriminatory insurance pricing.
Consistency of the Maximal Information Coefficient Estimator
Jul 08, 2021The Maximal Information Coefficient (MIC) of Reshef et al. (Science, 2011) is a statistic for measuring dependence between variable pairs in large datasets. In this note, we prove that MIC is a consistent estimator of the corresponding population statistic MIC$_*$. This corrects an error in an argument of Reshef et al. (JMLR, 2016), which we describe.