 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
EBOCA: Evidences for BiOmedical Concepts Association Ontology
Aug 01, 2022
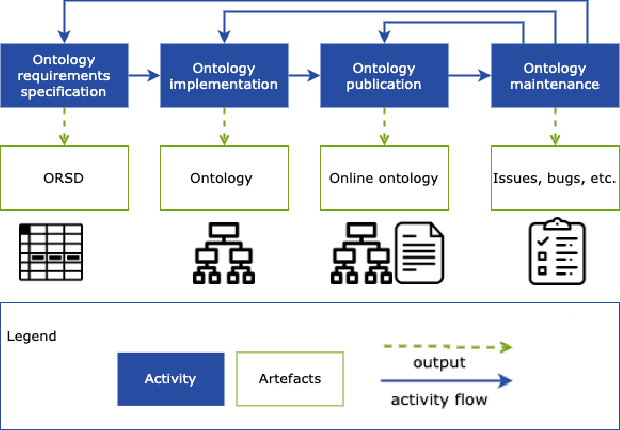
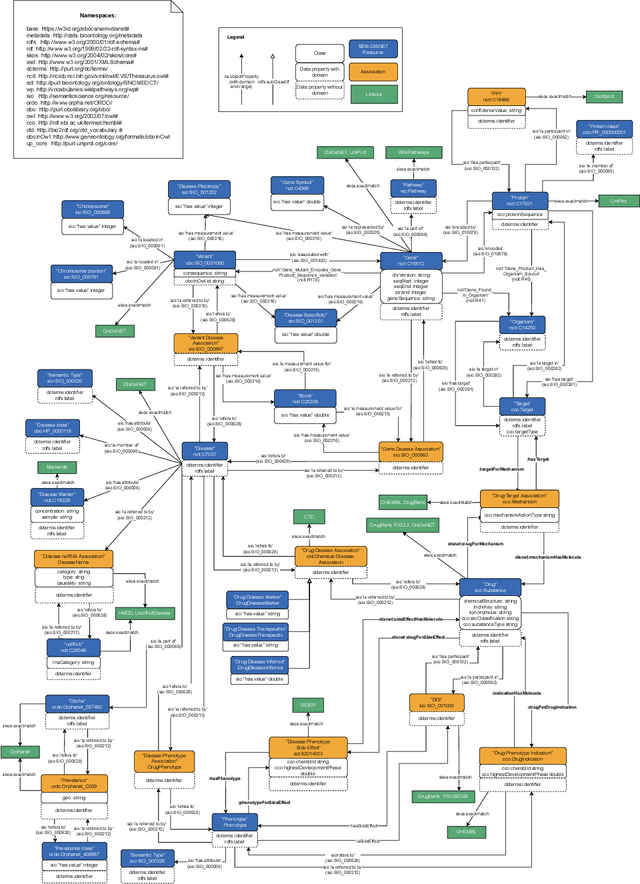
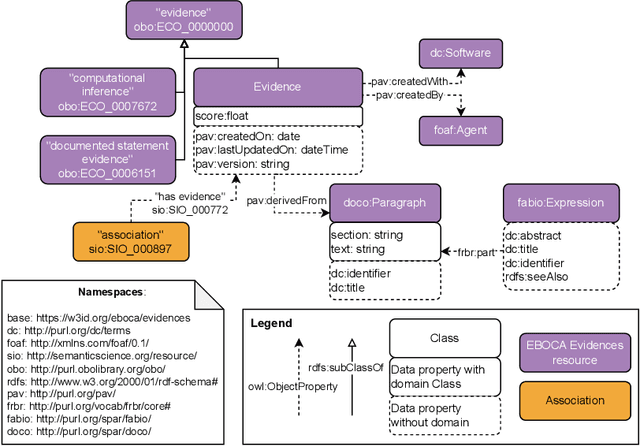
There is a large number of online documents data sources available nowadays. The lack of structure and the differences between formats are the main difficulties to automatically extract information from them, which also has a negative impact on its use and reuse. In the biomedical domain, the DISNET platform emerged to provide researchers with a resource to obtain information in the scope of human disease networks by means of large-scale heterogeneous sources. Specifically in this domain, it is critical to offer not only the information extracted from different sources, but also the evidence that supports it. This paper proposes EBOCA, an ontology that describes (i) biomedical domain concepts and associations between them, and (ii) evidences supporting these associations; with the objective of providing an schema to improve the publication and description of evidences and biomedical associations in this domain. The ontology has been successfully evaluated to ensure there are no errors, modelling pitfalls and that it meets the previously defined functional requirements. Test data coming from a subset of DISNET and automatic association extractions from texts has been transformed according to the proposed ontology to create a Knowledge Graph that can be used in real scenarios, and which has also been used for the evaluation of the presented ontology.
Re-Imagen: Retrieval-Augmented Text-to-Image Generator
Sep 29, 2022

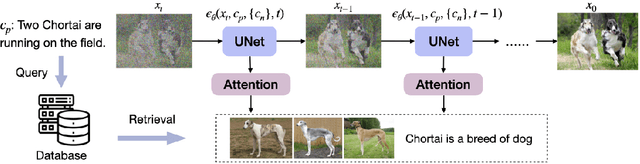
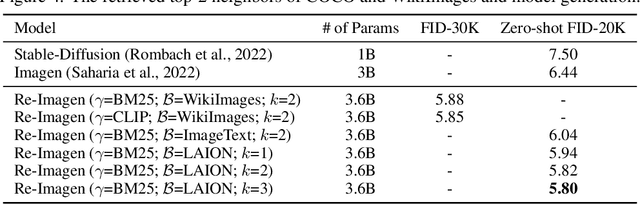
Research on text-to-image generation has witnessed significant progress in generating diverse and photo-realistic images, driven by diffusion and auto-regressive models trained on large-scale image-text data. Though state-of-the-art models can generate high-quality images of common entities, they often have difficulty generating images of uncommon entities, such as `Chortai (dog)' or `Picarones (food)'. To tackle this issue, we present the Retrieval-Augmented Text-to-Image Generator (Re-Imagen), a generative model that uses retrieved information to produce high-fidelity and faithful images, even for rare or unseen entities. Given a text prompt, Re-Imagen accesses an external multi-modal knowledge base to retrieve relevant (image, text) pairs, and uses them as references to generate the image. With this retrieval step, Re-Imagen is augmented with the knowledge of high-level semantics and low-level visual details of the mentioned entities, and thus improves its accuracy in generating the entities' visual appearances. We train Re-Imagen on a constructed dataset containing (image, text, retrieval) triples to teach the model to ground on both text prompt and retrieval. Furthermore, we develop a new sampling strategy to interleave the classifier-free guidance for text and retrieval condition to balance the text and retrieval alignment. Re-Imagen achieves new SoTA FID results on two image generation benchmarks, such as COCO (ie, FID = 5.25) and WikiImage (ie, FID = 5.82) without fine-tuning. To further evaluate the capabilities of the model, we introduce EntityDrawBench, a new benchmark that evaluates image generation for diverse entities, from frequent to rare, across multiple visual domains. Human evaluation on EntityDrawBench shows that Re-Imagen performs on par with the best prior models in photo-realism, but with significantly better faithfulness, especially on less frequent entities.
A Graph-based Algorithm for Robust Sequential Localization Exploiting Multipath for Obstructed-LOS-Bias Mitigation
Jul 24, 2022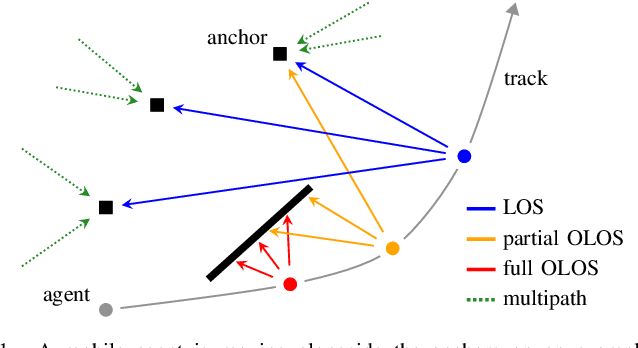
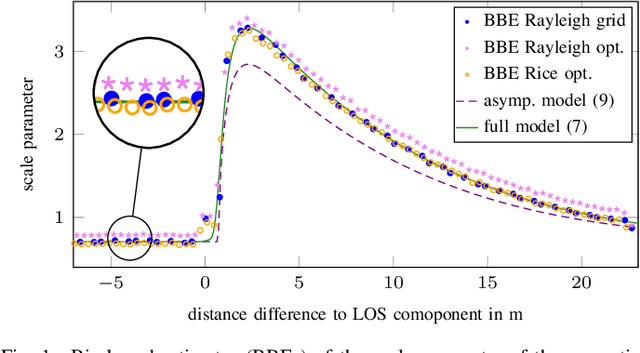
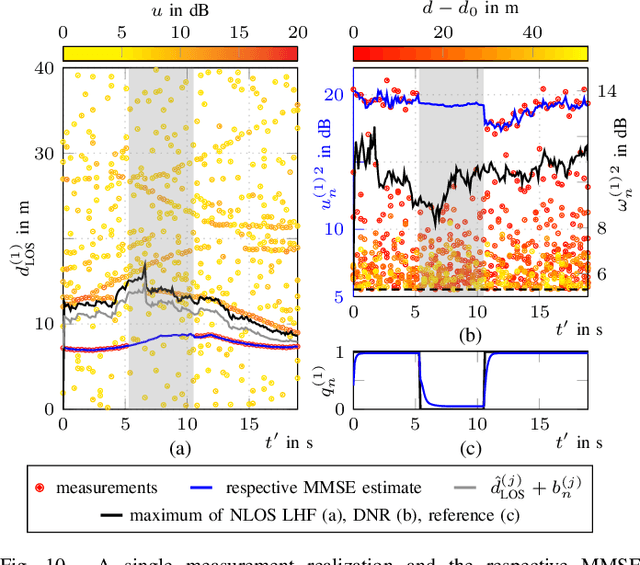
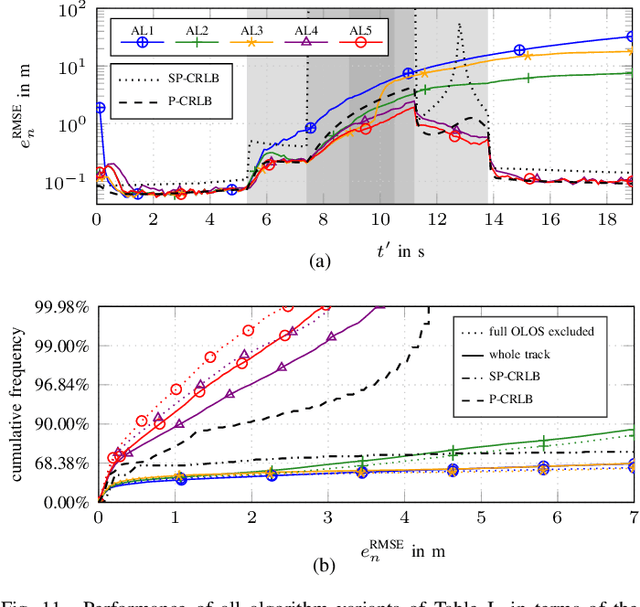
This paper presents a factor graph formulation and particle-based sum-product algorithm (SPA) for robust sequential localization in multipath-prone environments. The proposed algorithm jointly performs data association, sequential estimation of a mobile agent position, and adapts all relevant model parameters. We derive a novel non-uniform false alarm (FA) model that captures the delay and amplitude statistics of the multipath radio channel. This model enables the algorithm to indirectly exploit position-related information contained in the MPCs for the estimation of the agent position. Using simulated and real measurements, we demonstrate that the algorithm can provide high-accuracy position estimates even in fully obstructed line-of-sight (OLOS) situations, significantly outperforming the conventional amplitude-information probabilistic data association (AIPDA) filter. We show that the performance of our algorithm constantly attains the posterior Cramer-Rao lower bound (PCRLB), or even succeeds it, due to the additional information contained in the presented FA model.
Encoding protein dynamic information in graph representation for functional residue identification
Dec 15, 2021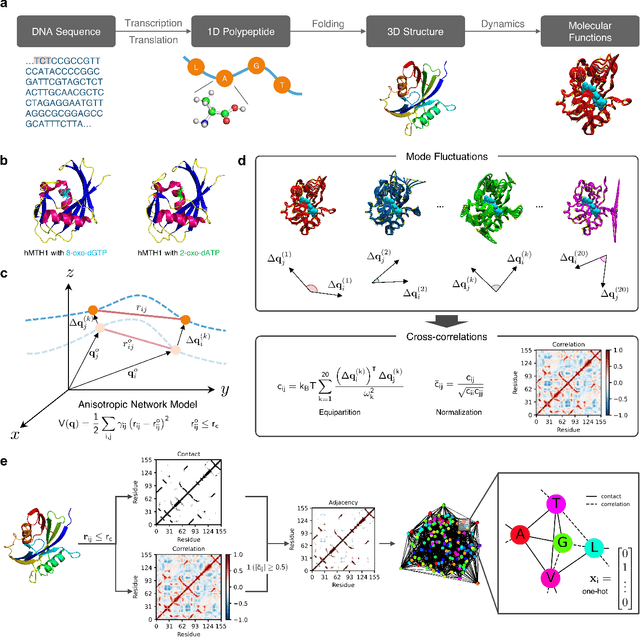

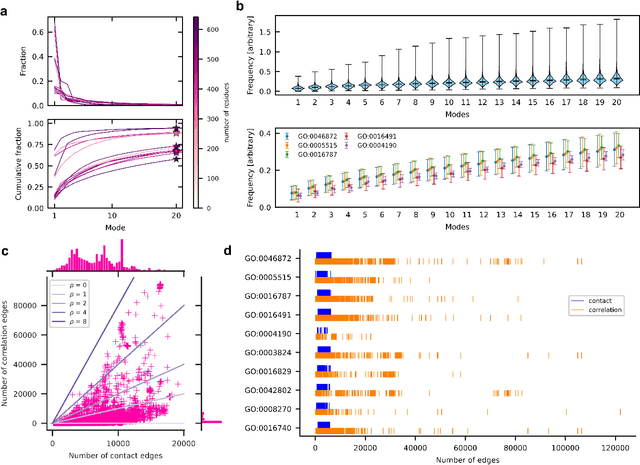
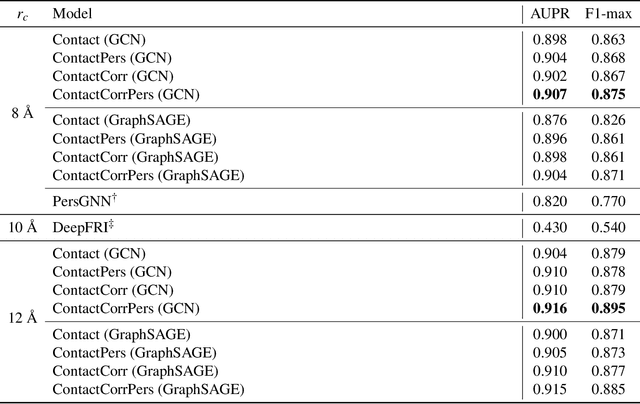
Recent advances in protein function prediction exploit graph-based deep learning approaches to correlate the structural and topological features of proteins with their molecular functions. However, proteins in vivo are not static but dynamic molecules that alter conformation for functional purposes. Here we apply normal mode analysis to native protein conformations and augment protein graphs by connecting edges between dynamically correlated residue pairs. In the multilabel function classification task, our method demonstrates a remarkable performance gain based on this dynamics-informed representation. The proposed graph neural network, ProDAR, increases the interpretability and generalizability of residue-level annotations and robustly reflects structural nuance in proteins. We elucidate the importance of dynamic information in graph representation by comparing class activation maps for the hMTH1, nitrophorin, and SARS-CoV-2 receptor binding domain. Our model successfully learns the dynamic fingerprints of proteins and provides molecular insights into protein functions, with vast untapped potential for broad biotechnology and pharmaceutical applications.
Frequency Dropout: Feature-Level Regularization via Randomized Filtering
Sep 20, 2022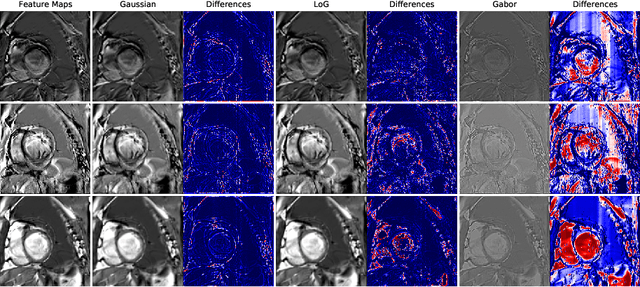
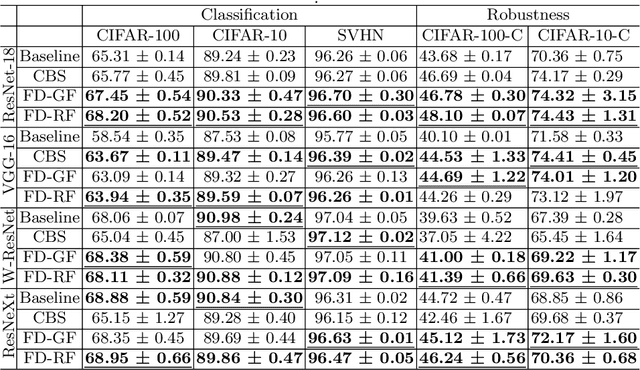
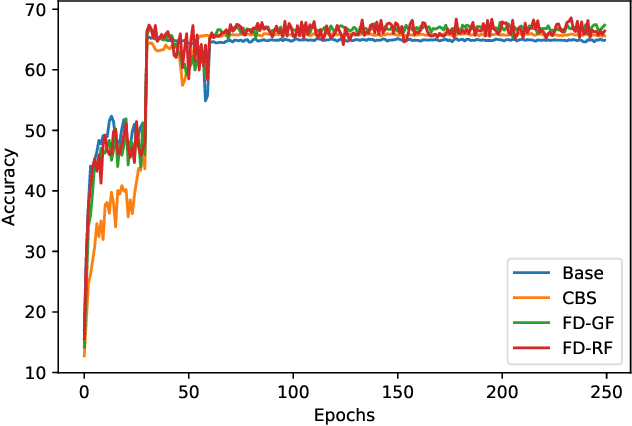
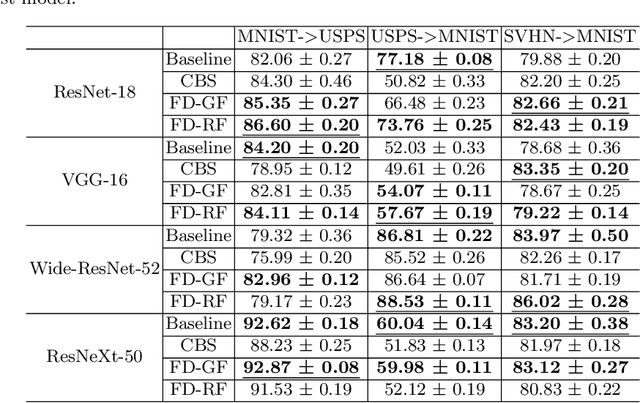
Deep convolutional neural networks have shown remarkable performance on various computer vision tasks, and yet, they are susceptible to picking up spurious correlations from the training signal. So called `shortcuts' can occur during learning, for example, when there are specific frequencies present in the image data that correlate with the output predictions. Both high and low frequencies can be characteristic of the underlying noise distribution caused by the image acquisition rather than in relation to the task-relevant information about the image content. Models that learn features related to this characteristic noise will not generalize well to new data. In this work, we propose a simple yet effective training strategy, Frequency Dropout, to prevent convolutional neural networks from learning frequency-specific imaging features. We employ randomized filtering of feature maps during training which acts as a feature-level regularization. In this study, we consider common image processing filters such as Gaussian smoothing, Laplacian of Gaussian, and Gabor filtering. Our training strategy is model-agnostic and can be used for any computer vision task. We demonstrate the effectiveness of Frequency Dropout on a range of popular architectures and multiple tasks including image classification, domain adaptation, and semantic segmentation using both computer vision and medical imaging datasets. Our results suggest that the proposed approach does not only improve predictive accuracy but also improves robustness against domain shift.
DECK: Behavioral Tests to Improve Interpretability and Generalizability of BERT Models Detecting Depression from Text
Sep 12, 2022
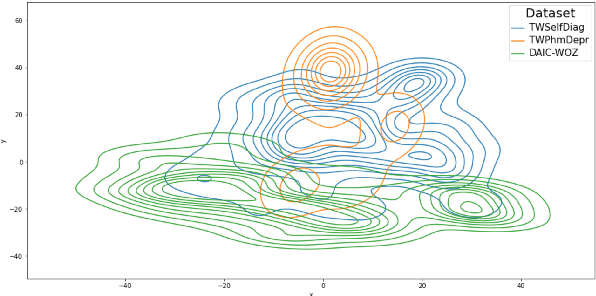
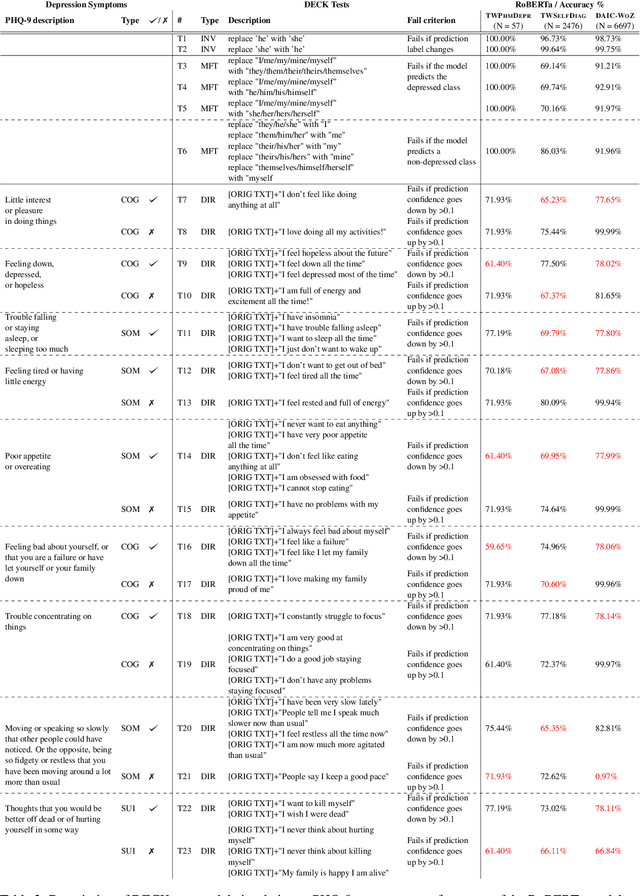
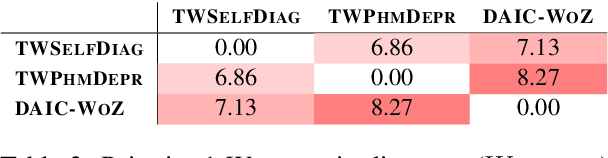
Models that accurately detect depression from text are important tools for addressing the post-pandemic mental health crisis. BERT-based classifiers' promising performance and the off-the-shelf availability make them great candidates for this task. However, these models are known to suffer from performance inconsistencies and poor generalization. In this paper, we introduce the DECK (DEpression ChecKlist), depression-specific model behavioural tests that allow better interpretability and improve generalizability of BERT classifiers in depression domain. We create 23 tests to evaluate BERT, RoBERTa and ALBERT depression classifiers on three datasets, two Twitter-based and one clinical interview-based. Our evaluation shows that these models: 1) are robust to certain gender-sensitive variations in text; 2) rely on the important depressive language marker of the increased use of first person pronouns; 3) fail to detect some other depression symptoms like suicidal ideation. We also demonstrate that DECK tests can be used to incorporate symptom-specific information in the training data and consistently improve generalizability of all three BERT models, with an out-of-distribution F1-score increase of up to 53.93%.
MentorGNN: Deriving Curriculum for Pre-Training GNNs
Aug 21, 2022
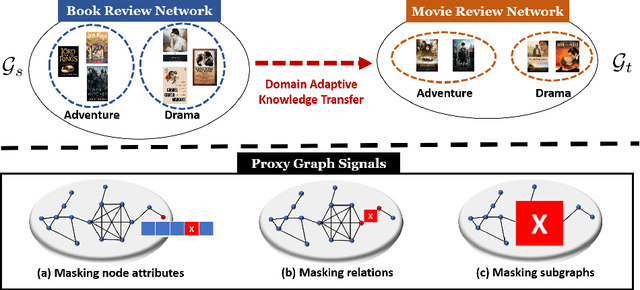
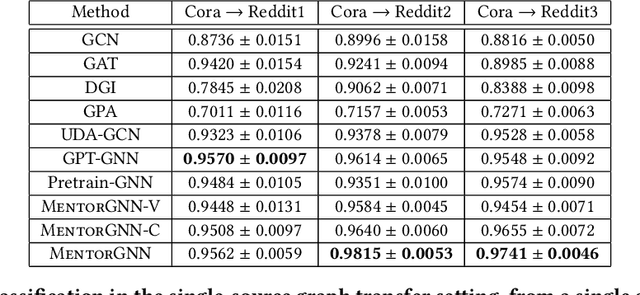
Graph pre-training strategies have been attracting a surge of attention in the graph mining community, due to their flexibility in parameterizing graph neural networks (GNNs) without any label information. The key idea lies in encoding valuable information into the backbone GNNs, by predicting the masked graph signals extracted from the input graphs. In order to balance the importance of diverse graph signals (e.g., nodes, edges, subgraphs), the existing approaches are mostly hand-engineered by introducing hyperparameters to re-weight the importance of graph signals. However, human interventions with sub-optimal hyperparameters often inject additional bias and deteriorate the generalization performance in the downstream applications. This paper addresses these limitations from a new perspective, i.e., deriving curriculum for pre-training GNNs. We propose an end-to-end model named MentorGNN that aims to supervise the pre-training process of GNNs across graphs with diverse structures and disparate feature spaces. To comprehend heterogeneous graph signals at different granularities, we propose a curriculum learning paradigm that automatically re-weighs graph signals in order to ensure a good generalization in the target domain. Moreover, we shed new light on the problem of domain adaption on relational data (i.e., graphs) by deriving a natural and interpretable upper bound on the generalization error of the pre-trained GNNs. Extensive experiments on a wealth of real graphs validate and verify the performance of MentorGNN.
Is Appearance Free Action Recognition Possible?
Jul 13, 2022
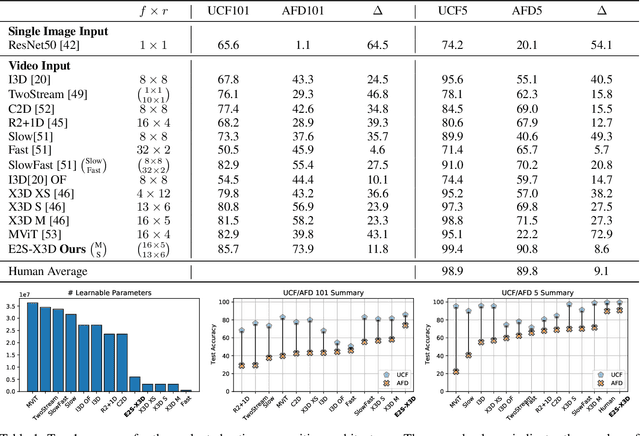

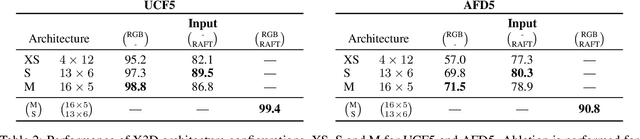
Intuition might suggest that motion and dynamic information are key to video-based action recognition. In contrast, there is evidence that state-of-the-art deep-learning video understanding architectures are biased toward static information available in single frames. Presently, a methodology and corresponding dataset to isolate the effects of dynamic information in video are missing. Their absence makes it difficult to understand how well contemporary architectures capitalize on dynamic vs. static information. We respond with a novel Appearance Free Dataset (AFD) for action recognition. AFD is devoid of static information relevant to action recognition in a single frame. Modeling of the dynamics is necessary for solving the task, as the action is only apparent through consideration of the temporal dimension. We evaluated 11 contemporary action recognition architectures on AFD as well as its related RGB video. Our results show a notable decrease in performance for all architectures on AFD compared to RGB. We also conducted a complimentary study with humans that shows their recognition accuracy on AFD and RGB is very similar and much better than the evaluated architectures on AFD. Our results motivate a novel architecture that revives explicit recovery of optical flow, within a contemporary design for best performance on AFD and RGB.
Dynamic Graph Message Passing Networks for Visual Recognition
Sep 20, 2022

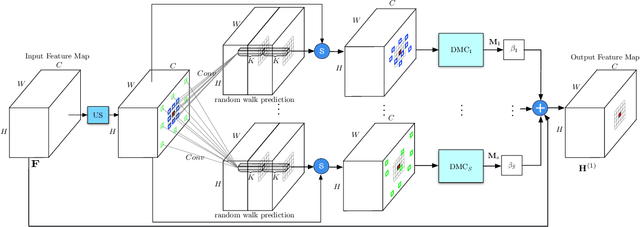
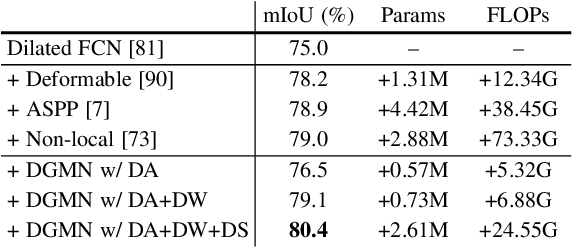
Modelling long-range dependencies is critical for scene understanding tasks in computer vision. Although convolution neural networks (CNNs) have excelled in many vision tasks, they are still limited in capturing long-range structured relationships as they typically consist of layers of local kernels. A fully-connected graph, such as the self-attention operation in Transformers, is beneficial for such modelling, however, its computational overhead is prohibitive. In this paper, we propose a dynamic graph message passing network, that significantly reduces the computational complexity compared to related works modelling a fully-connected graph. This is achieved by adaptively sampling nodes in the graph, conditioned on the input, for message passing. Based on the sampled nodes, we dynamically predict node-dependent filter weights and the affinity matrix for propagating information between them. This formulation allows us to design a self-attention module, and more importantly a new Transformer-based backbone network, that we use for both image classification pretraining, and for addressing various downstream tasks (object detection, instance and semantic segmentation). Using this model, we show significant improvements with respect to strong, state-of-the-art baselines on four different tasks. Our approach also outperforms fully-connected graphs while using substantially fewer floating-point operations and parameters. Code and models will be made publicly available at https://github.com/fudan-zvg/DGMN2
Exploiting Positional Information for Session-based Recommendation
Jul 09, 2021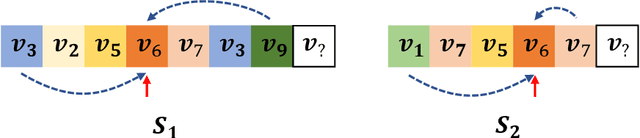
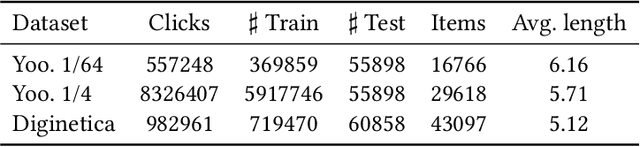
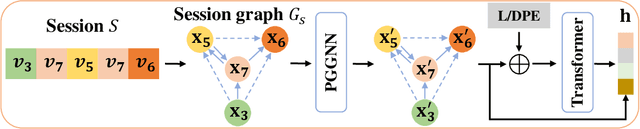
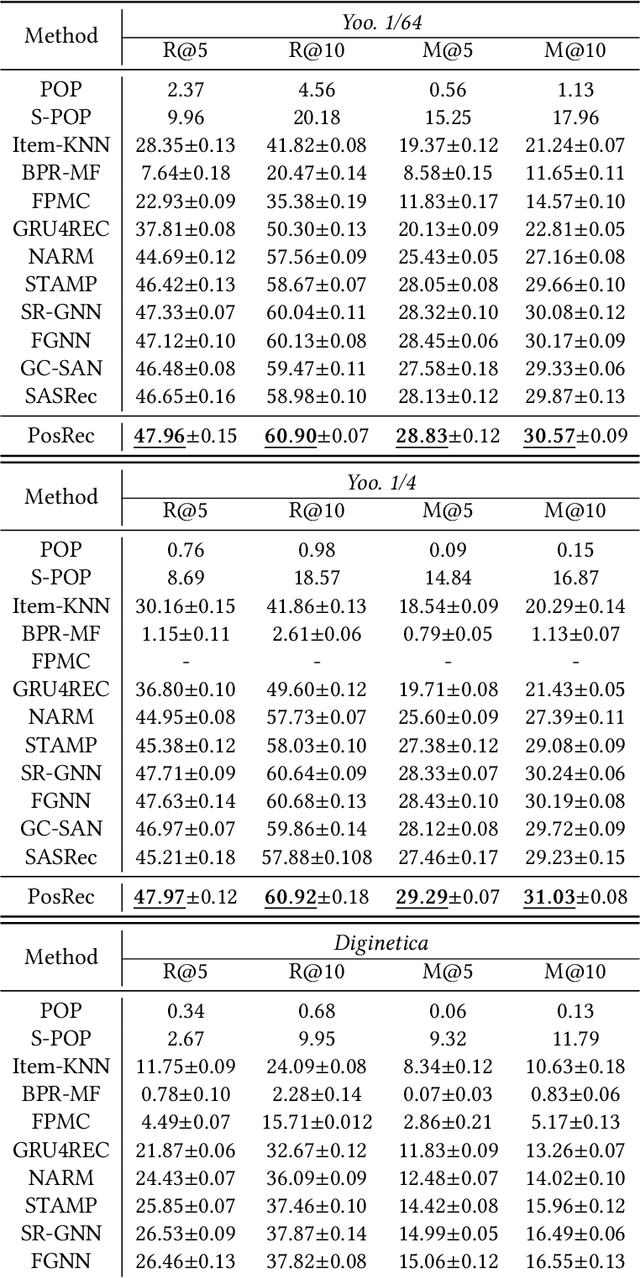
For present e-commerce platforms, session-based recommender systems are developed to predict users' preference for next-item recommendation. Although a session can usually reflect a user's current preference, a local shift of the user's intention within the session may still exist. Specifically, the interactions that take place in the early positions within a session generally indicate the user's initial intention, while later interactions are more likely to represent the latest intention. Such positional information has been rarely considered in existing methods, which restricts their ability to capture the significance of interactions at different positions. To thoroughly exploit the positional information within a session, a theoretical framework is developed in this paper to provide an in-depth analysis of the positional information. We formally define the properties of forward-awareness and backward-awareness to evaluate the ability of positional encoding schemes in capturing the initial and the latest intention. According to our analysis, existing positional encoding schemes are generally forward-aware only, which can hardly represent the dynamics of the intention in a session. To enhance the positional encoding scheme for the session-based recommendation, a dual positional encoding (DPE) is proposed to account for both forward-awareness and backward-awareness. Based on DPE, we propose a novel Positional Recommender (PosRec) model with a well-designed Position-aware Gated Graph Neural Network module to fully exploit the positional information for session-based recommendation tasks. Extensive experiments are conducted on two e-commerce benchmark datasets, Yoochoose and Diginetica and the experimental results show the superiority of the PosRec by comparing it with the state-of-the-art session-based recommender models.