 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective, Interpretable, and Motion Consistent Privacy Attribute Obfuscation for Action Recognition
Mar 19, 2024



Concerns for the privacy of individuals captured in public imagery have led to privacy-preserving action recognition. Existing approaches often suffer from issues arising through obfuscation being applied globally and a lack of interpretability. Global obfuscation hides privacy sensitive regions, but also contextual regions important for action recognition. Lack of interpretability erodes trust in these new technologies. We highlight the limitations of current paradigms and propose a solution: Human selected privacy templates that yield interpretability by design, an obfuscation scheme that selectively hides attributes and also induces temporal consistency, which is important in action recognition. Our approach is architecture agnostic and directly modifies input imagery, while existing approaches generally require architecture training. Our approach offers more flexibility, as no retraining is required, and outperforms alternatives on three widely used datasets.
Score-Based Generative Models for Medical Image Segmentation using Signed Distance Functions
Mar 10, 2023



Medical image segmentation is a crucial task that relies on the ability to accurately identify and isolate regions of interest in images. Thereby, generative approaches allow to capture the statistical properties of segmentation masks that are dependent on the respective medical images. In this work we propose a conditional score-based generative modeling framework that leverages the signed distance function to represent an implicit and smoother distribution of segmentation masks. The score function of the conditional distribution of segmentation masks is learned in a conditional denoising process, which can be effectively used to generate accurate segmentation masks. Moreover, uncertainty maps can be generated, which can aid in further analysis and thus enhance the predictive robustness. We qualitatively and quantitatively illustrate competitive performance of the proposed method on a public nuclei and gland segmentation data set, highlighting its potential utility in medical image segmentation applications.
Is Appearance Free Action Recognition Possible?
Jul 13, 2022
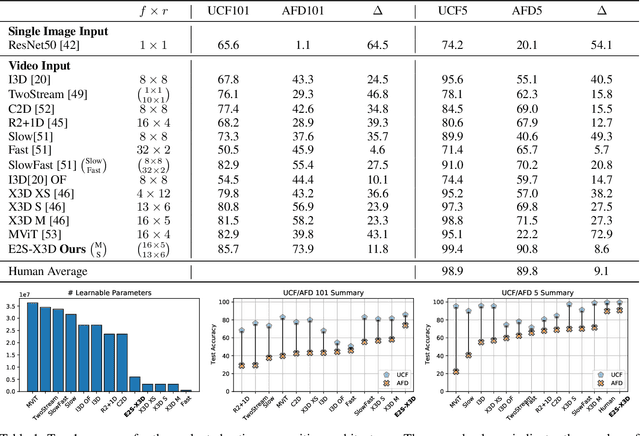

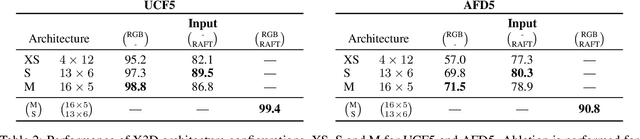
Intuition might suggest that motion and dynamic information are key to video-based action recognition. In contrast, there is evidence that state-of-the-art deep-learning video understanding architectures are biased toward static information available in single frames. Presently, a methodology and corresponding dataset to isolate the effects of dynamic information in video are missing. Their absence makes it difficult to understand how well contemporary architectures capitalize on dynamic vs. static information. We respond with a novel Appearance Free Dataset (AFD) for action recognition. AFD is devoid of static information relevant to action recognition in a single frame. Modeling of the dynamics is necessary for solving the task, as the action is only apparent through consideration of the temporal dimension. We evaluated 11 contemporary action recognition architectures on AFD as well as its related RGB video. Our results show a notable decrease in performance for all architectures on AFD compared to RGB. We also conducted a complimentary study with humans that shows their recognition accuracy on AFD and RGB is very similar and much better than the evaluated architectures on AFD. Our results motivate a novel architecture that revives explicit recovery of optical flow, within a contemporary design for best performance on AFD and RGB.