 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Robust Causal Graph Representation Learning against Confounding Effects
Aug 18, 2022
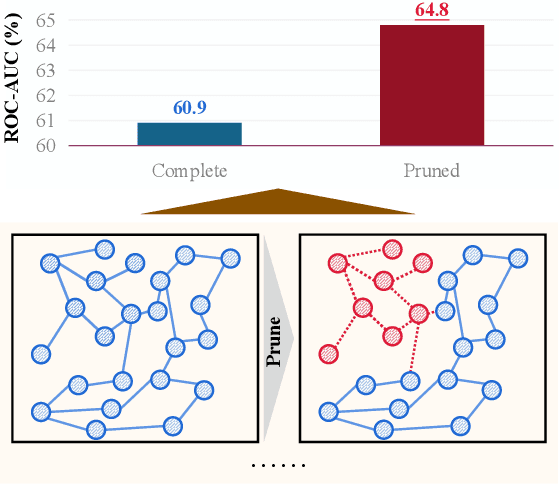
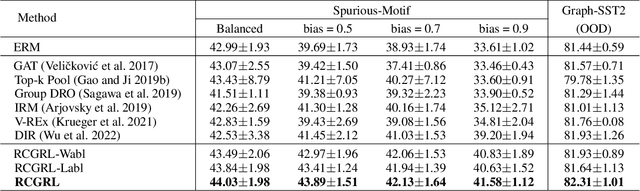
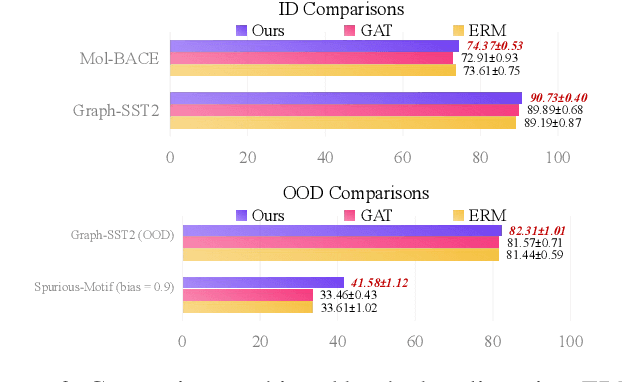
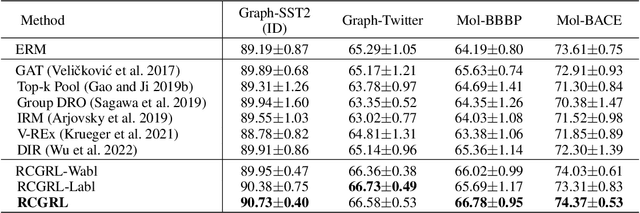
The prevailing graph neural network models have achieved significant progress in graph representation learning. However, in this paper, we uncover an ever-overlooked phenomenon: the pre-trained graph representation learning model tested with full graphs underperforms the model tested with well-pruned graphs. This observation reveals that there exist confounders in graphs, which may interfere with the model learning semantic information, and current graph representation learning methods have not eliminated their influence. To tackle this issue, we propose Robust Causal Graph Representation Learning (RCGRL) to learn robust graph representations against confounding effects. RCGRL introduces an active approach to generate instrumental variables under unconditional moment restrictions, which empowers the graph representation learning model to eliminate confounders, thereby capturing discriminative information that is causally related to downstream predictions. We offer theorems and proofs to guarantee the theoretical effectiveness of the proposed approach. Empirically, we conduct extensive experiments on a synthetic dataset and multiple benchmark datasets. The results demonstrate that compared with state-of-the-art methods, RCGRL achieves better prediction performance and generalization ability.
A Quantum Algorithm for Computing All Diagnoses of a Switching Circuit
Sep 08, 2022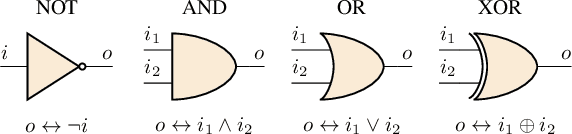
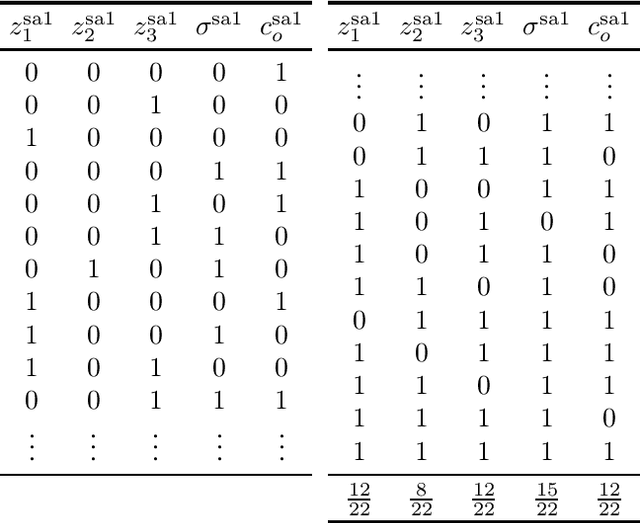
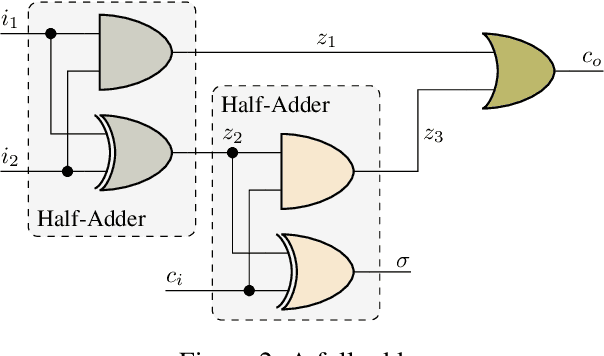
Faults are stochastic by nature while most man-made systems, and especially computers, work deterministically. This necessitates the linking of probability theory with mathematical logics, automata, and switching circuit theory. This paper provides such a connecting via quantum information theory which is an intuitive approach as quantum physics obeys probability laws. In this paper we provide a novel approach for computing diagnosis of switching circuits with gate-based quantum computers. The approach is based on the idea of putting the qubits representing faults in superposition and compute all, often exponentially many, diagnoses simultaneously. We empirically compare the quantum algorithm for diagnostics to an approach based on SAT and model-counting. For a benchmark of combinational circuits we establish an error of less than one percent in estimating the true probability of faults.
Information-Theoretic Based Target Search with Multiple Agents
Jul 27, 2021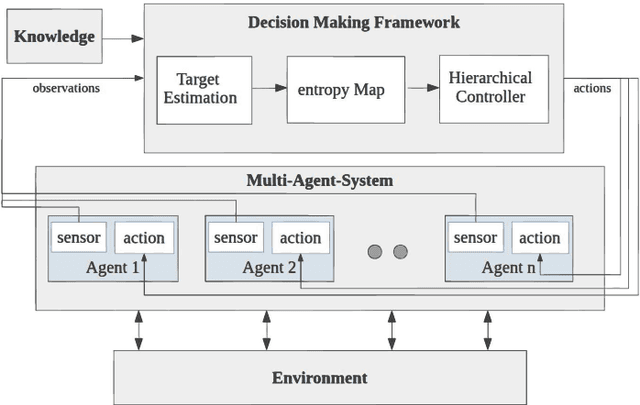
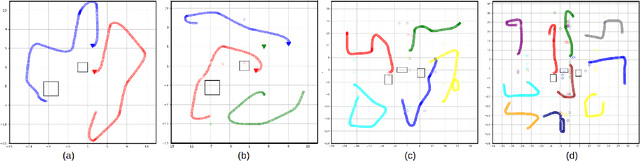
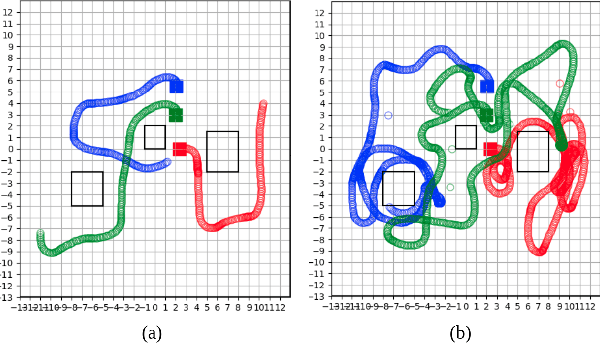
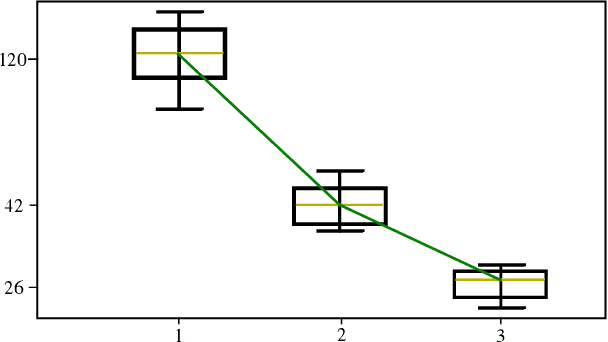
This paper proposes an online path planning and motion generation algorithm for heterogeneous robot teams performing target search in a real-world environment. Path selection for each robot is optimized using an information-theoretic formulation and is computed sequentially for each agent. First, we generate candidate trajectories sampled from both global waypoints derived from vertical cell decomposition and local frontier points. From this set, we choose the path with maximum information gain. We demonstrate that the hierarchical sequential decision-making structure provided by the algorithm is scalable to multiple agents in a simulation setup. We also validate our framework in a real-world apartment setting using a two robot team comprised of the Unitree A1 quadruped and the Toyota HSR mobile manipulator searching for a person. The agents leverage an efficient leader-follower communication structure where only critical information is shared.
Causal Effect Estimation using Variational Information Bottleneck
Oct 26, 2021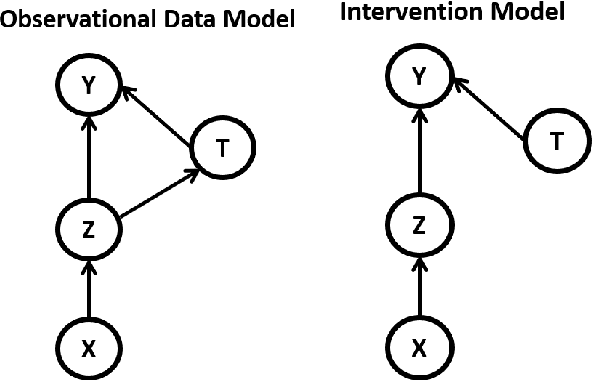
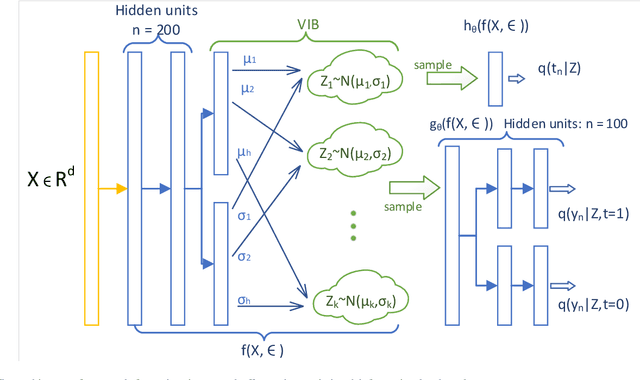
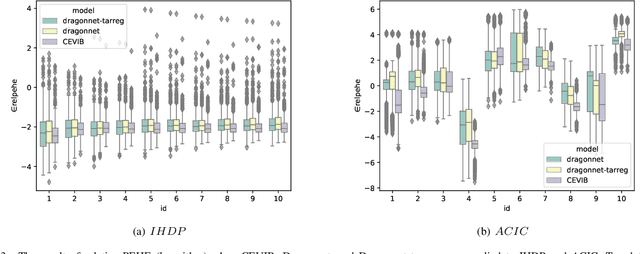
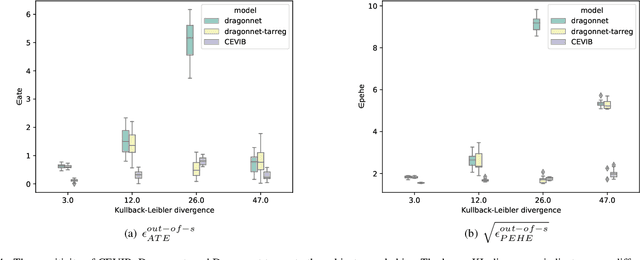
Causal inference is to estimate the causal effect in a causal relationship when intervention is applied. Precisely, in a causal model with binary interventions, i.e., control and treatment, the causal effect is simply the difference between the factual and counterfactual. The difficulty is that the counterfactual may never been obtained which has to be estimated and so the causal effect could only be an estimate. The key challenge for estimating the counterfactual is to identify confounders which effect both outcomes and treatments. A typical approach is to formulate causal inference as a supervised learning problem and so counterfactual could be predicted. Including linear regression and deep learning models, recent machine learning methods have been adapted to causal inference. In this paper, we propose a method to estimate Causal Effect by using Variational Information Bottleneck (CEVIB). The promising point is that VIB is able to naturally distill confounding variables from the data, which enables estimating causal effect by using observational data. We have compared CEVIB to other methods by applying them to three data sets showing that our approach achieved the best performance. We also experimentally showed the robustness of our method.
Grid-Free MIMO Beam Alignment through Site-Specific Deep Learning
Sep 16, 2022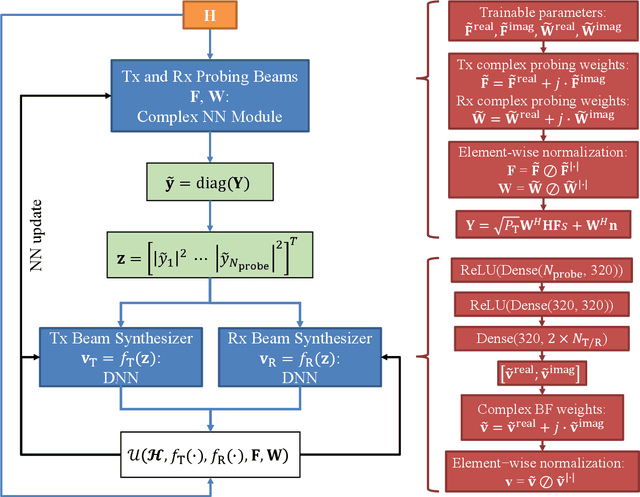
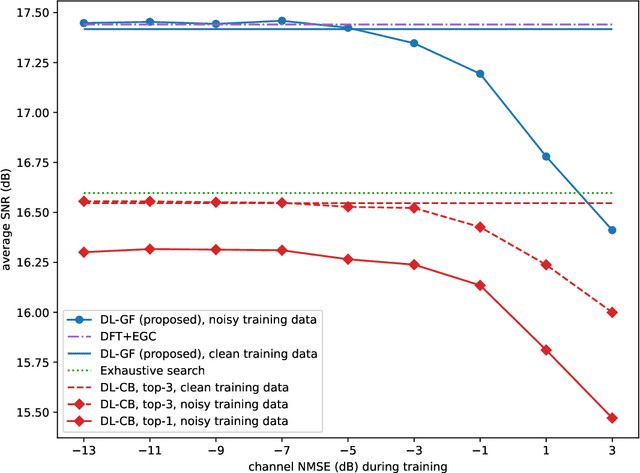
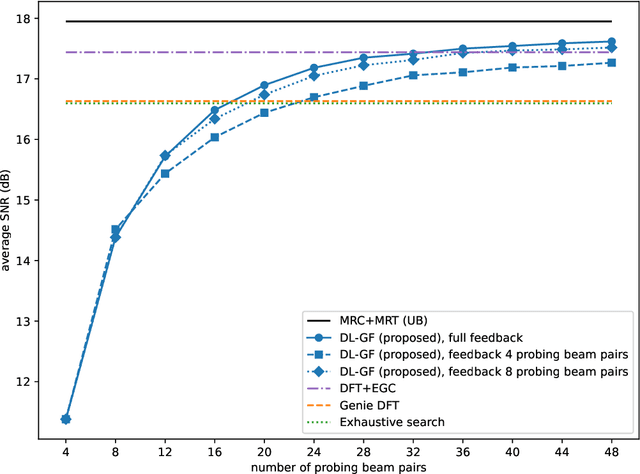
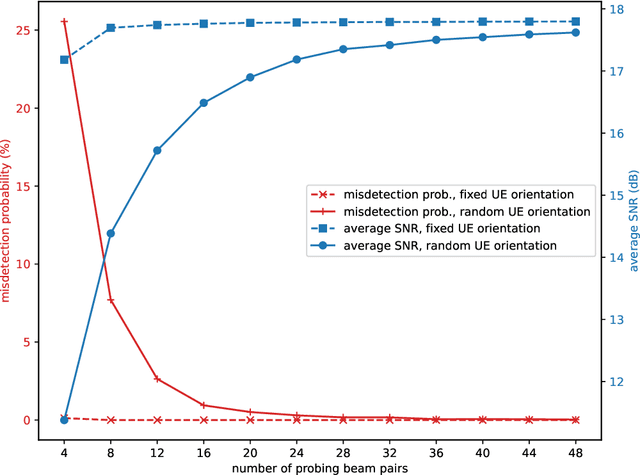
Beam alignment is a critical bottleneck in millimeter wave (mmWave) communication. An ideal beam alignment technique should achieve high beamforming (BF) gain with low latency, scale well to systems with higher carrier frequencies, larger antenna arrays and multiple user equipments (UEs), and not require hard-to-obtain context information (CI). These qualities are collectively lacking in existing methods. We depart from the conventional codebook-based (CB) approach where the optimal beam is chosen from quantized codebooks and instead propose a grid-free (GF) beam alignment method that directly synthesizes the transmit (Tx) and receive (Rx) beams from the continuous search space using measurements from a few site-specific probing beams that are found via a deep learning (DL) pipeline. In realistic settings, the proposed method achieves a far superior signal-to-noise ratio (SNR)-latency trade-off compared to the CB baselines: it aligns near-optimal beams 100x faster or equivalently finds beams with 10-15 dB better average SNR in the same number of searches, relative to an exhaustive search over a conventional codebook.
Pure Exploration in Multi-armed Bandits with Graph Side Information
Aug 02, 2021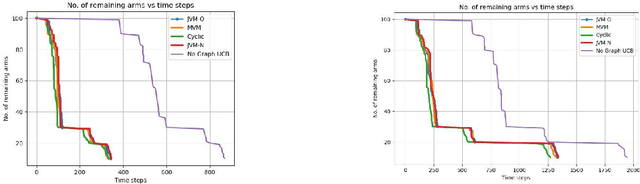
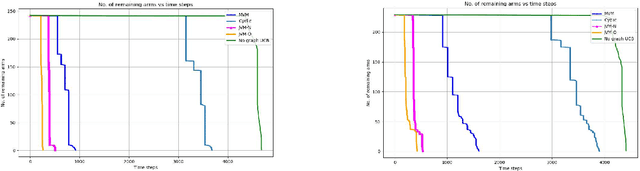
We study pure exploration in multi-armed bandits with graph side-information. In particular, we consider the best arm (and near-best arm) identification problem in the fixed confidence setting under the assumption that the arm rewards are smooth with respect to a given arbitrary graph. This captures a range of real world pure-exploration scenarios where one often has information about the similarity of the options or actions under consideration. We propose a novel algorithm GRUB (GRaph based UcB) for this problem and provide a theoretical characterization of its performance that elicits the benefit of the graph-side information. We complement our theory with experimental results that show that capitalizing on available graph side information yields significant improvements over pure exploration methods that are unable to use this information.
Temporal Fuzzy Utility Maximization with Remaining Measure
Aug 26, 2022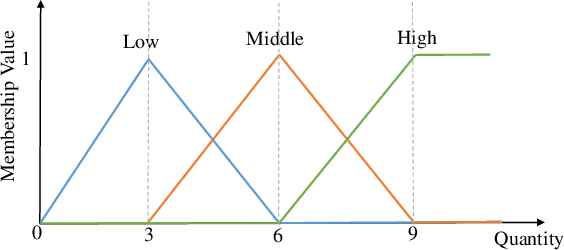
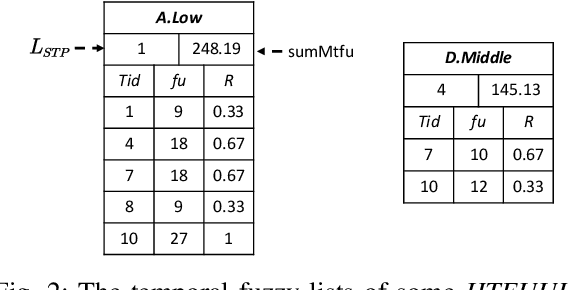
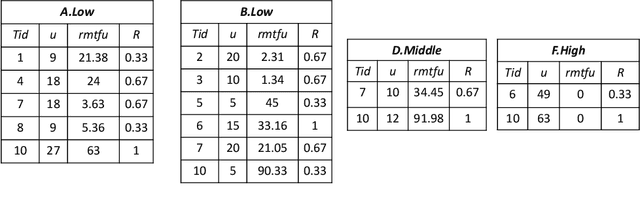
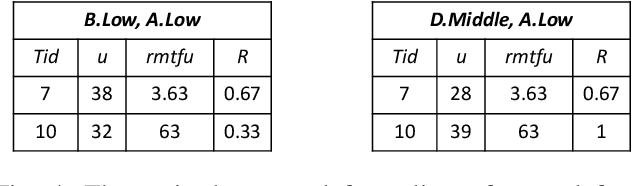
High utility itemset mining approaches discover hidden patterns from large amounts of temporal data. However, an inescapable problem of high utility itemset mining is that its discovered results hide the quantities of patterns, which causes poor interpretability. The results only reflect the shopping trends of customers, which cannot help decision makers quantify collected information. In linguistic terms, computers use mathematical or programming languages that are precisely formalized, but the language used by humans is always ambiguous. In this paper, we propose a novel one-phase temporal fuzzy utility itemset mining approach called TFUM. It revises temporal fuzzy-lists to maintain less but major information about potential high temporal fuzzy utility itemsets in memory, and then discovers a complete set of real interesting patterns in a short time. In particular, the remaining measure is the first adopted in the temporal fuzzy utility itemset mining domain in this paper. The remaining maximal temporal fuzzy utility is a tighter and stronger upper bound than that of previous studies adopted. Hence, it plays an important role in pruning the search space in TFUM. Finally, we also evaluate the efficiency and effectiveness of TFUM on various datasets. Extensive experimental results indicate that TFUM outperforms the state-of-the-art algorithms in terms of runtime cost, memory usage, and scalability. In addition, experiments prove that the remaining measure can significantly prune unnecessary candidates during mining.
Learning to Discriminate Information for Online Action Detection: Analysis and Application
Sep 09, 2021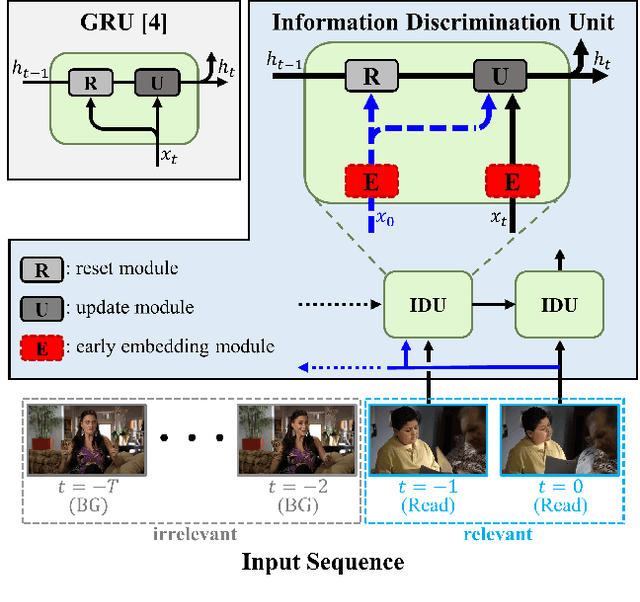
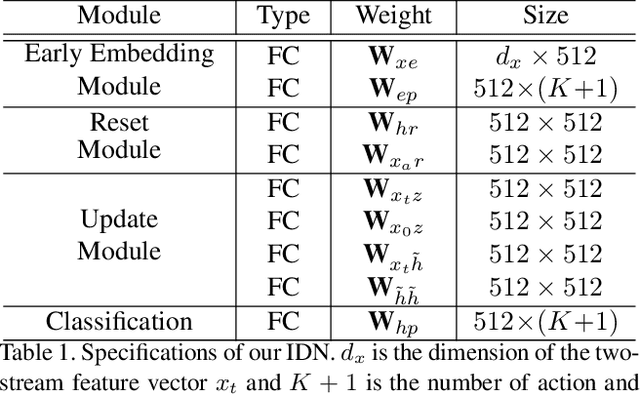
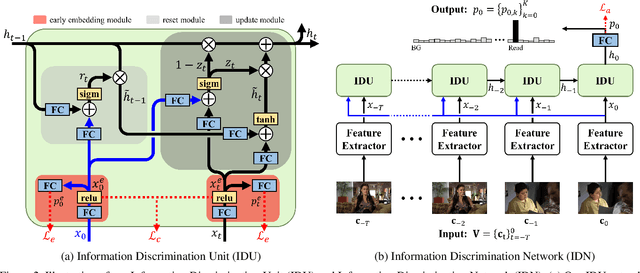
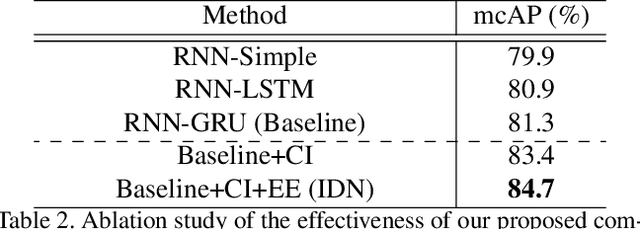
Online action detection, which aims to identify an ongoing action from a streaming video, is an important subject in real-world applications. For this task, previous methods use recurrent neural networks for modeling temporal relations in an input sequence. However, these methods overlook the fact that the input image sequence includes not only the action of interest but background and irrelevant actions. This would induce recurrent units to accumulate unnecessary information for encoding features on the action of interest. To overcome this problem, we propose a novel recurrent unit, named Information Discrimination Unit (IDU), which explicitly discriminates the information relevancy between an ongoing action and others to decide whether to accumulate the input information. This enables learning more discriminative representations for identifying an ongoing action. In this paper, we further present a new recurrent unit, called Information Integration Unit (IIU), for action anticipation. Our IIU exploits the outputs from IDU as pseudo action labels as well as RGB frames to learn enriched features of observed actions effectively. In experiments on TVSeries and THUMOS-14, the proposed methods outperform state-of-the-art methods by a significant margin in online action detection and action anticipation. Moreover, we demonstrate the effectiveness of the proposed units by conducting comprehensive ablation studies.
Using Wi-Fi Signal as Sensing Medium: Passive Radar, Channel State Information and Followups
Jan 09, 2022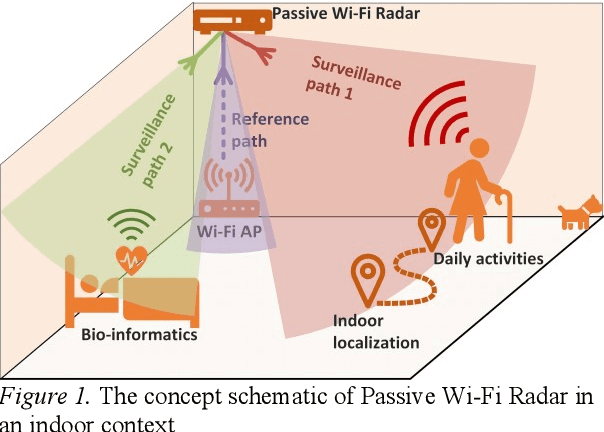
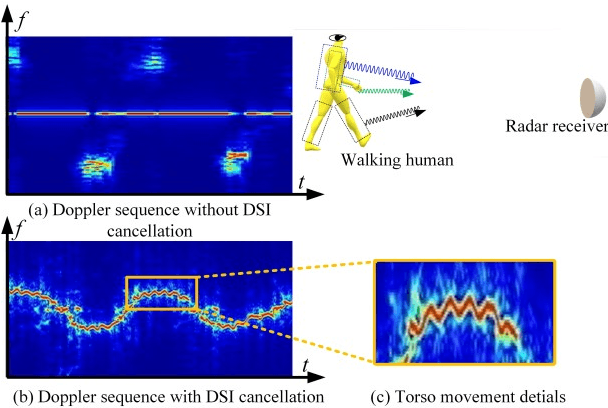
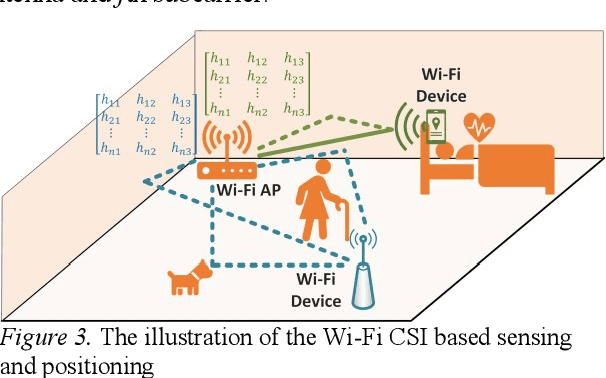
The idea of exploiting the Wi-Fi bursts as the medium for sensing purposes, particularly for the human targets in the indoor environment, was cultivated in both radar and computer science communities and it has became a noticeable research genre with cross-disciplinary impact in security, healthcare, human-machine interaction etc.This article comparatively introduces passive radar based and channel state information (CSI) based approaches. For each means, the primary design principles, signal processing and representative applications scenarios are shown. At last, some opportunities and challenges of Wi-Fi sensing are pointed out for the sake of stepping closer to the practitioners and end-users.
Information Directed Sampling for Sparse Linear Bandits
May 29, 2021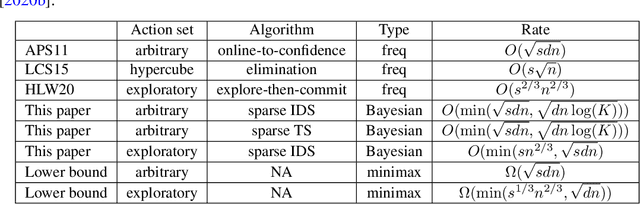
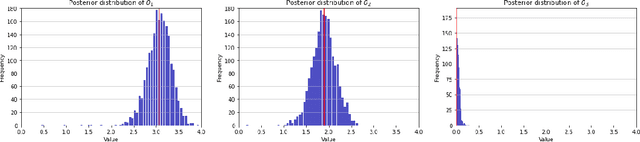
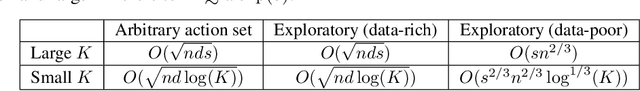
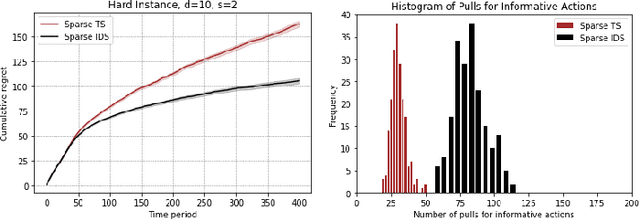
Stochastic sparse linear bandits offer a practical model for high-dimensional online decision-making problems and have a rich information-regret structure. In this work we explore the use of information-directed sampling (IDS), which naturally balances the information-regret trade-off. We develop a class of information-theoretic Bayesian regret bounds that nearly match existing lower bounds on a variety of problem instances, demonstrating the adaptivity of IDS. To efficiently implement sparse IDS, we propose an empirical Bayesian approach for sparse posterior sampling using a spike-and-slab Gaussian-Laplace prior. Numerical results demonstrate significant regret reductions by sparse IDS relative to several baselines.