 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Probabilistic Variational Causal Effect as A new Theory for Causal Reasoning
Aug 28, 2022
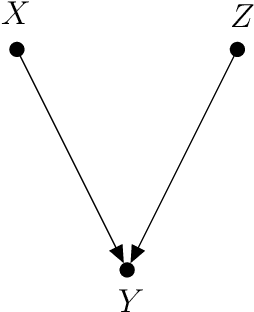
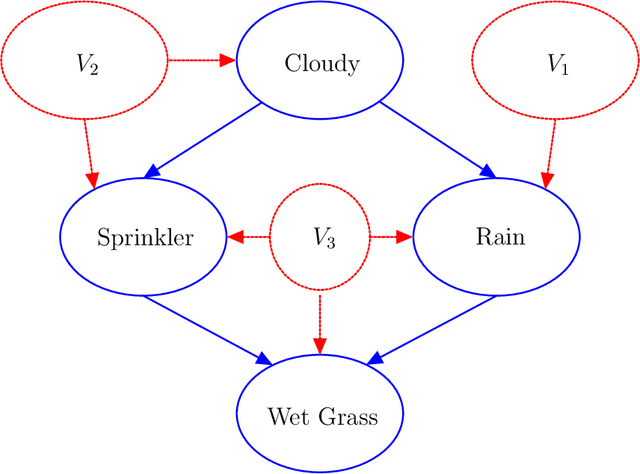
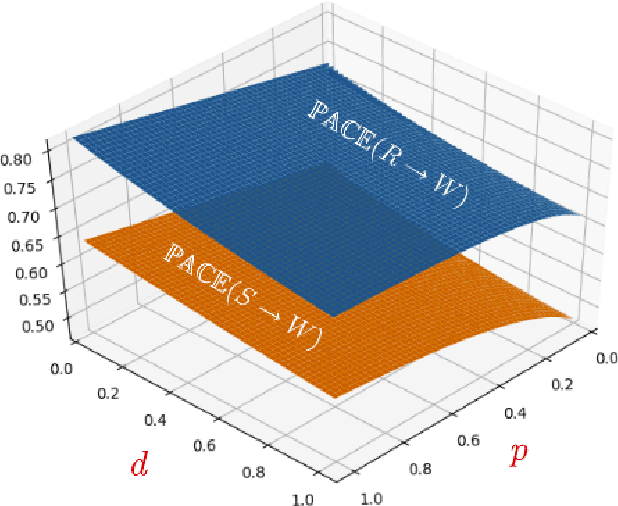
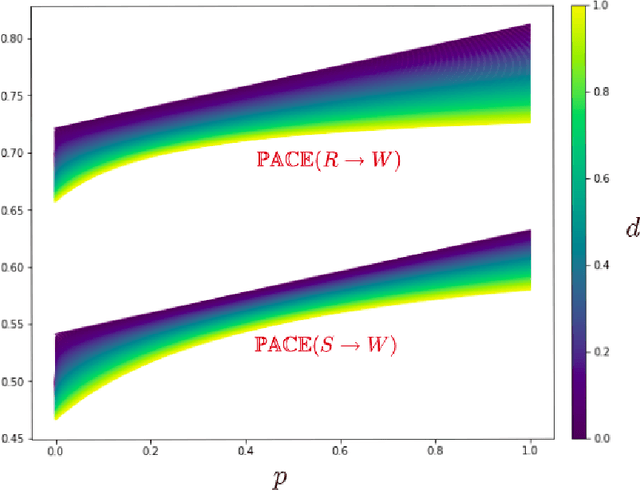
In this paper, we introduce a new causal framework capable of dealing with probabilistic and non-probabilistic problems. Indeed, we provide a formula called Probabilistic vAriational Causal Effect (PACE). Our formula of causal effect uses the idea of total variation of a function integrated with probability theory. PACE has a parameter $d$ determining the degree of being probabilistic. The lower values of $d$ refer to the scenarios that rare cases are important. In contrast, with the higher values of $d$, our model deals with the problems that are in nature probabilistic. Hence, instead of a single value for causal effect, we provide a causal effect vector by discretizing $d$. We also address the problem of computing counterfactuals in causal reasoning. We compare our model to the Pearl model, the mutual information model, the conditional mutual information model, and the Janzing et al. model by investigating several examples.
A Transferable Intersection Reconstruction Network for Traffic Speed Prediction
Jul 22, 2022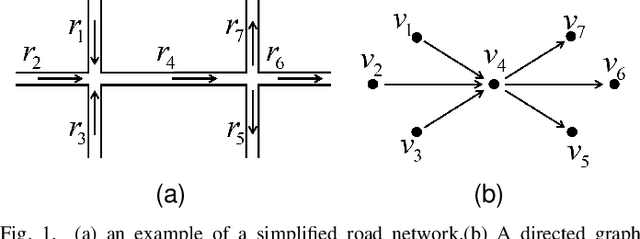
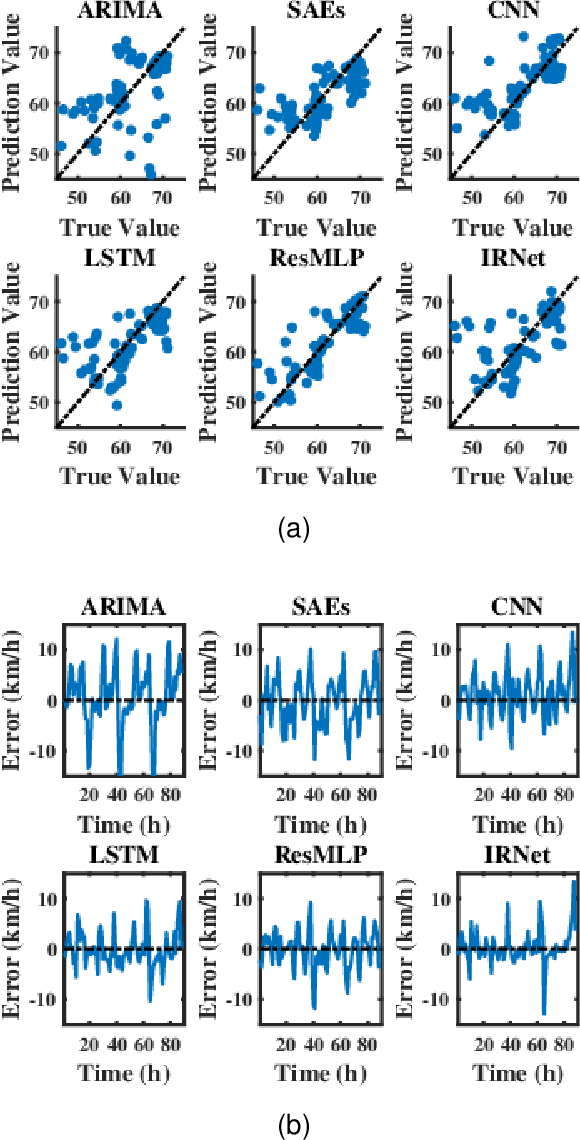
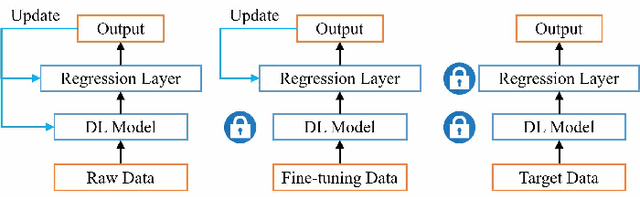
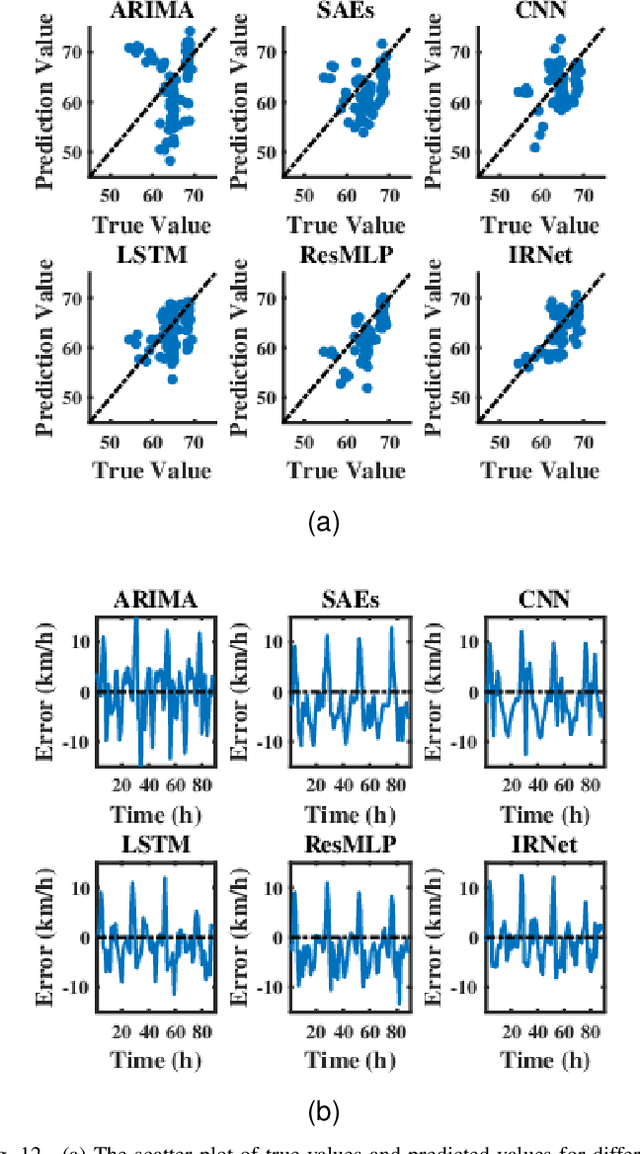
Traffic speed prediction is the key to many valuable applications, and it is also a challenging task because of its various influencing factors. Recent work attempts to obtain more information through various hybrid models, thereby improving the prediction accuracy. However, the spatial information acquisition schemes of these methods have two-level differentiation problems. Either the modeling is simple but contains little spatial information, or the modeling is complete but lacks flexibility. In order to introduce more spatial information on the basis of ensuring flexibility, this paper proposes IRNet (Transferable Intersection Reconstruction Network). First, this paper reconstructs the intersection into a virtual intersection with the same structure, which simplifies the topology of the road network. Then, the spatial information is subdivided into intersection information and sequence information of traffic flow direction, and spatiotemporal features are obtained through various models. Third, a self-attention mechanism is used to fuse spatiotemporal features for prediction. In the comparison experiment with the baseline, not only the prediction effect, but also the transfer performance has obvious advantages.
Understanding CNN Fragility When Learning With Imbalanced Data
Oct 17, 2022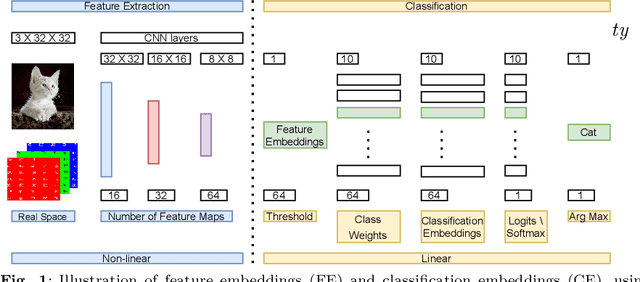
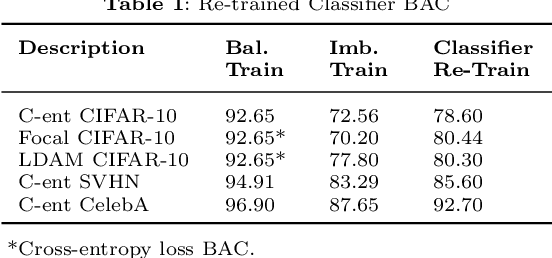
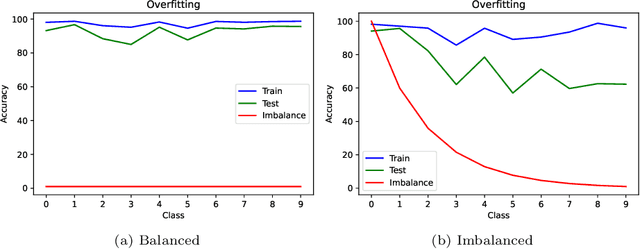
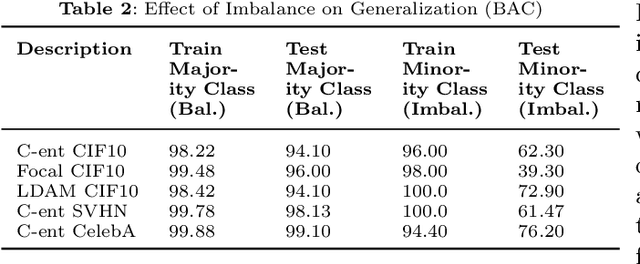
Convolutional neural networks (CNNs) have achieved impressive results on imbalanced image data, but they still have difficulty generalizing to minority classes and their decisions are difficult to interpret. These problems are related because the method by which CNNs generalize to minority classes, which requires improvement, is wrapped in a blackbox. To demystify CNN decisions on imbalanced data, we focus on their latent features. Although CNNs embed the pattern knowledge learned from a training set in model parameters, the effect of this knowledge is contained in feature and classification embeddings (FE and CE). These embeddings can be extracted from a trained model and their global, class properties (e.g., frequency, magnitude and identity) can be analyzed. We find that important information regarding the ability of a neural network to generalize to minority classes resides in the class top-K CE and FE. We show that a CNN learns a limited number of class top-K CE per category, and that their number and magnitudes vary based on whether the same class is balanced or imbalanced. This calls into question whether a CNN has learned intrinsic class features, or merely frequently occurring ones that happen to exist in the sampled class distribution. We also hypothesize that latent class diversity is as important as the number of class examples, which has important implications for re-sampling and cost-sensitive methods. These methods generally focus on rebalancing model weights, class numbers and margins; instead of diversifying class latent features through augmentation. We also demonstrate that a CNN has difficulty generalizing to test data if the magnitude of its top-K latent features do not match the training set. We use three popular image datasets and two cost-sensitive algorithms commonly employed in imbalanced learning for our experiments.
What Makes Convolutional Models Great on Long Sequence Modeling?
Oct 17, 2022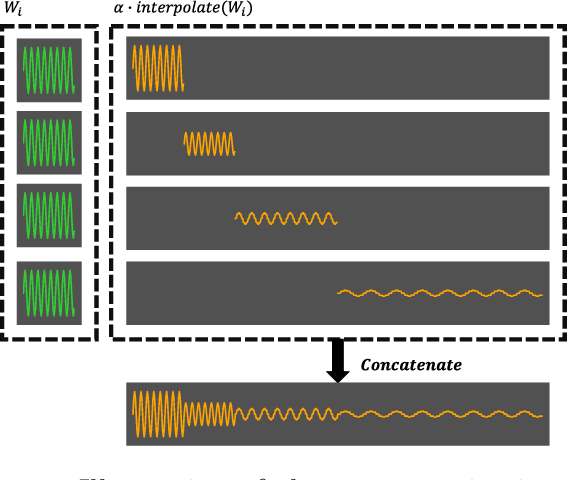
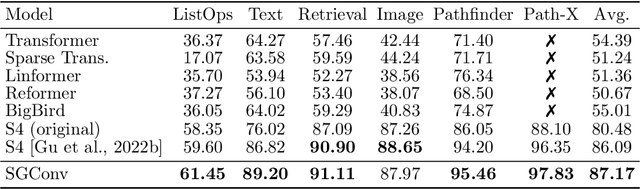
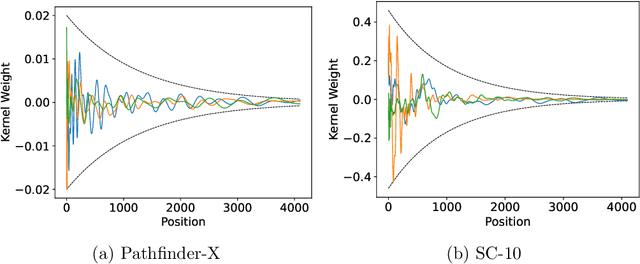
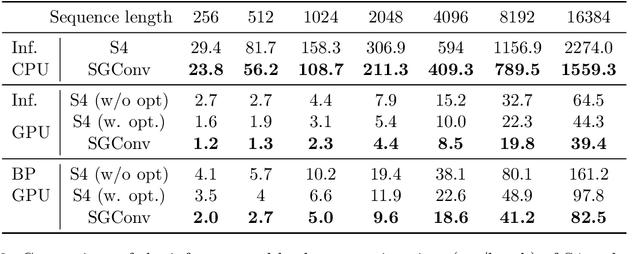
Convolutional models have been widely used in multiple domains. However, most existing models only use local convolution, making the model unable to handle long-range dependency efficiently. Attention overcomes this problem by aggregating global information but also makes the computational complexity quadratic to the sequence length. Recently, Gu et al. [2021] proposed a model called S4 inspired by the state space model. S4 can be efficiently implemented as a global convolutional model whose kernel size equals the input sequence length. S4 can model much longer sequences than Transformers and achieve significant gains over SoTA on several long-range tasks. Despite its empirical success, S4 is involved. It requires sophisticated parameterization and initialization schemes. As a result, S4 is less intuitive and hard to use. Here we aim to demystify S4 and extract basic principles that contribute to the success of S4 as a global convolutional model. We focus on the structure of the convolution kernel and identify two critical but intuitive principles enjoyed by S4 that are sufficient to make up an effective global convolutional model: 1) The parameterization of the convolutional kernel needs to be efficient in the sense that the number of parameters should scale sub-linearly with sequence length. 2) The kernel needs to satisfy a decaying structure that the weights for convolving with closer neighbors are larger than the more distant ones. Based on the two principles, we propose a simple yet effective convolutional model called Structured Global Convolution (SGConv). SGConv exhibits strong empirical performance over several tasks: 1) With faster speed, SGConv surpasses S4 on Long Range Arena and Speech Command datasets. 2) When plugging SGConv into standard language and vision models, it shows the potential to improve both efficiency and performance.
Cutting-Splicing data augmentation: A novel technology for medical image segmentation
Oct 17, 2022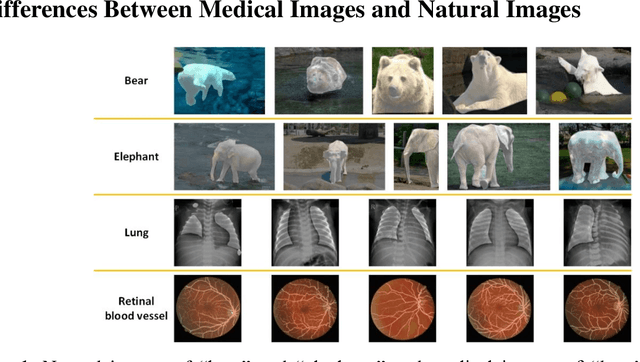
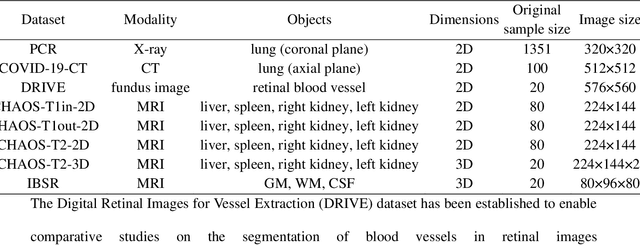
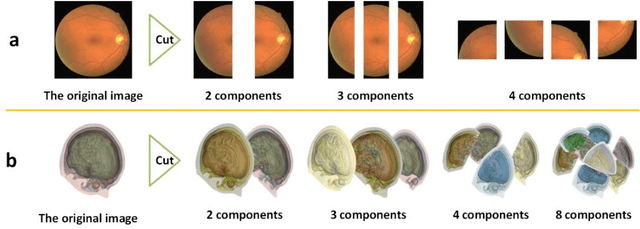
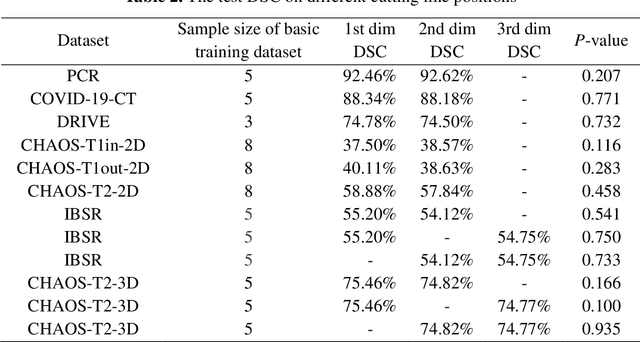
Background: Medical images are more difficult to acquire and annotate than natural images, which results in data augmentation technologies often being used in medical image segmentation tasks. Most data augmentation technologies used in medical segmentation were originally developed on natural images and do not take into account the characteristic that the overall layout of medical images is standard and fixed. Methods: Based on the characteristics of medical images, we developed the cutting-splicing data augmentation (CS-DA) method, a novel data augmentation technology for medical image segmentation. CS-DA augments the dataset by splicing different position components cut from different original medical images into a new image. The characteristics of the medical image result in the new image having the same layout as and similar appearance to the original image. Compared with classical data augmentation technologies, CS-DA is simpler and more robust. Moreover, CS-DA does not introduce any noise or fake information into the newly created image. Results: To explore the properties of CS-DA, many experiments are conducted on eight diverse datasets. On the training dataset with the small sample size, CS-DA can effectively increase the performance of the segmentation model. When CS-DA is used together with classical data augmentation technologies, the performance of the segmentation model can be further improved and is much better than that of CS-DA and classical data augmentation separately. We also explored the influence of the number of components, the position of the cutting line, and the splicing method on the CS-DA performance. Conclusions: The excellent performance of CS-DA in the experiment has confirmed the effectiveness of CS-DA, and provides a new data augmentation idea for the small sample segmentation task.
Data Augmentation for Depression Detection Using Skeleton-Based Gait Information
Jan 04, 2022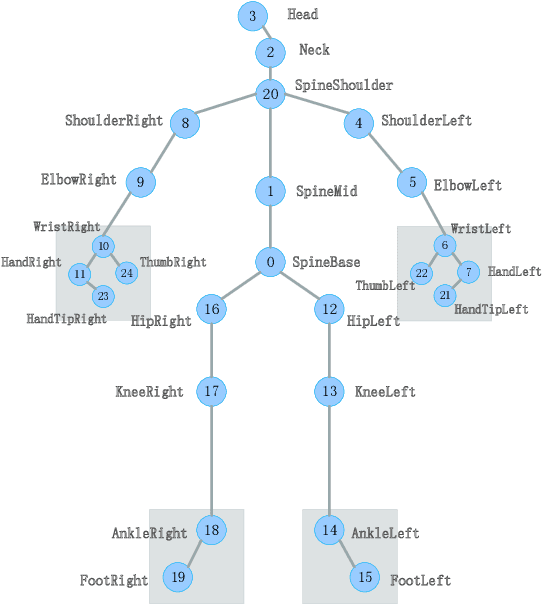
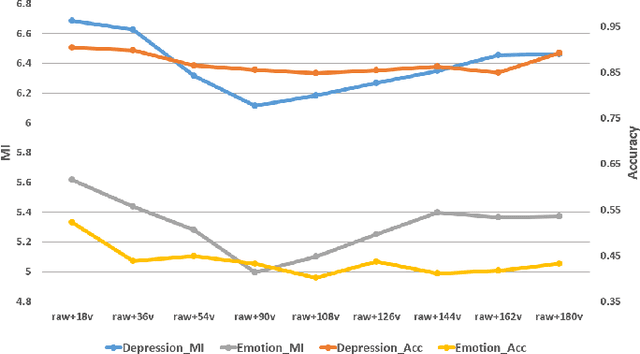
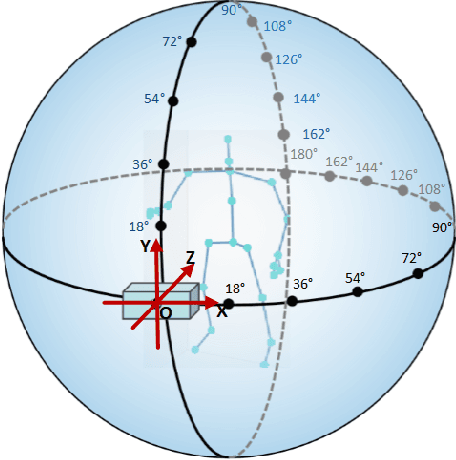
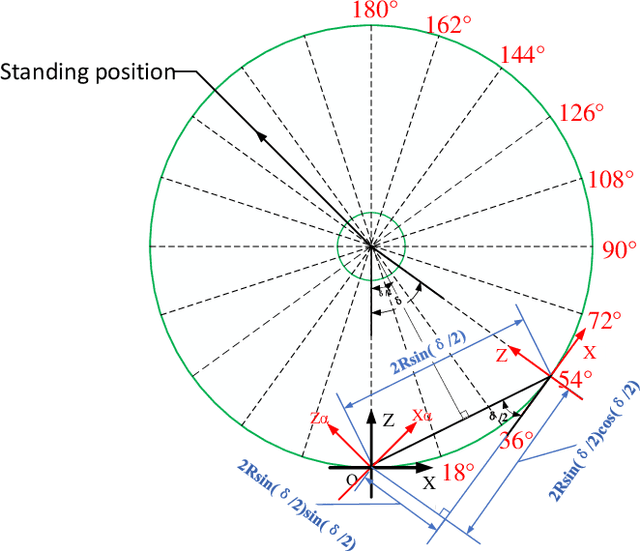
In recent years, the incidence of depression is rising rapidly worldwide, but large-scale depression screening is still challenging. Gait analysis provides a non-contact, low-cost, and efficient early screening method for depression. However, the early screening of depression based on gait analysis lacks sufficient effective sample data. In this paper, we propose a skeleton data augmentation method for assessing the risk of depression. First, we propose five techniques to augment skeleton data and apply them to depression and emotion datasets. Then, we divide augmentation methods into two types (non-noise augmentation and noise augmentation) based on the mutual information and the classification accuracy. Finally, we explore which augmentation strategies can capture the characteristics of human skeleton data more effectively. Experimental results show that the augmented training data set that retains more of the raw skeleton data properties determines the performance of the detection model. Specifically, rotation augmentation and channel mask augmentation make the depression detection accuracy reach 92.15% and 91.34%, respectively.
Doc2Graph: a Task Agnostic Document Understanding Framework based on Graph Neural Networks
Aug 23, 2022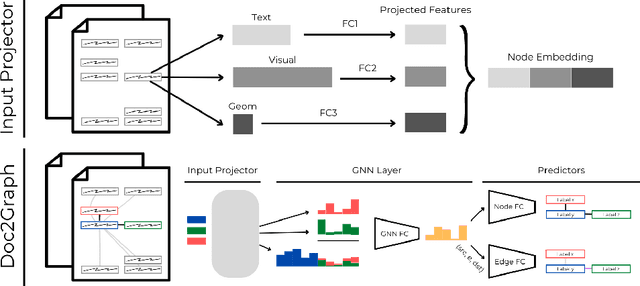


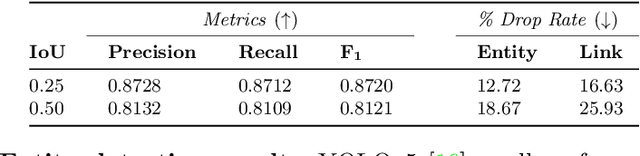
Geometric Deep Learning has recently attracted significant interest in a wide range of machine learning fields, including document analysis. The application of Graph Neural Networks (GNNs) has become crucial in various document-related tasks since they can unravel important structural patterns, fundamental in key information extraction processes. Previous works in the literature propose task-driven models and do not take into account the full power of graphs. We propose Doc2Graph, a task-agnostic document understanding framework based on a GNN model, to solve different tasks given different types of documents. We evaluated our approach on two challenging datasets for key information extraction in form understanding, invoice layout analysis and table detection. Our code is freely accessible on https://github.com/andreagemelli/doc2graph.
On semi shift invariant graph filters
Sep 28, 2022
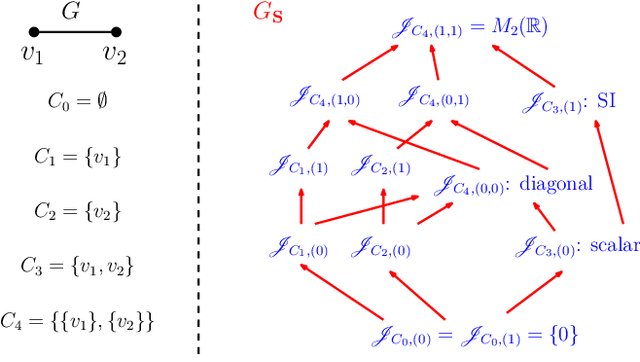
In graph signal processing, one of the most important subjects is the study of filters, i.e., linear transformations that capture relations between graph signals. One of the most important families of filters is the space of shift invariant filters, defined as transformations commute with a preferred graph shift operator. Shift invariant filters have a wide range of applications in graph signal processing and graph neural networks. A shift invariant filter can be interpreted geometrically as an information aggregation procedure (from local neighborhood), and can be computed easily using matrix multiplication. However, there are still drawbacks to using solely shift invariant filters in applications, such as being restrictively homogeneous. In this paper, we generalize shift invariant filters by introducing and studying semi shift invariant filters. We give an application of semi shift invariant filters with a new signal processing framework, the subgraph signal processing. Moreover, we also demonstrate how semi shift invariant filters can be used in graph neural networks.
Galaxy Spin Classification I: Z-wise vs S-wise Spirals With Chirality Equivariant Residual Network
Oct 09, 2022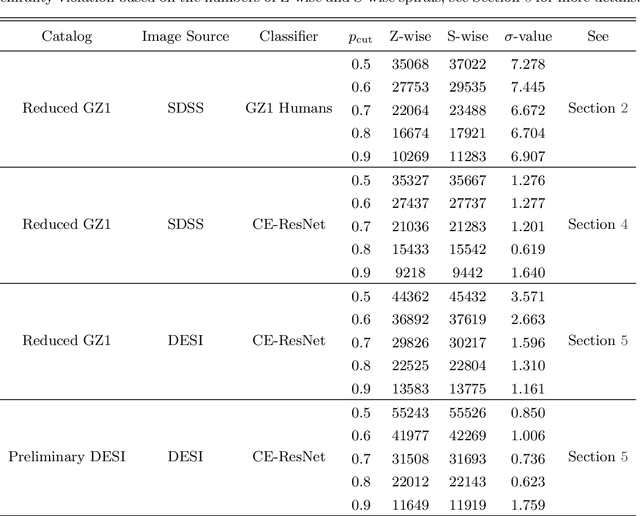
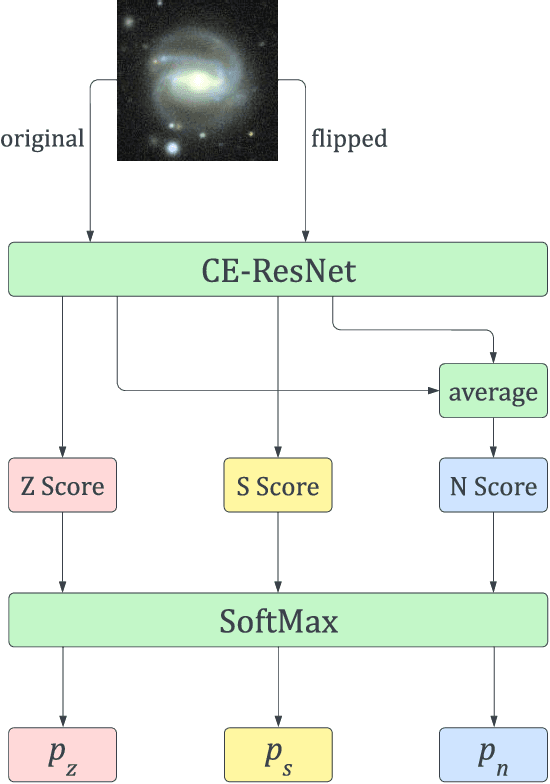
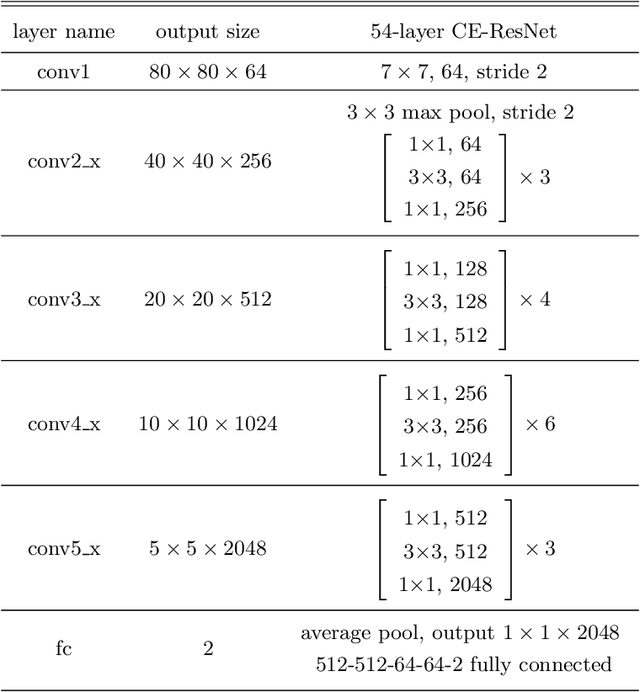

The angular momentum of galaxies (galaxy spin) contains rich information about the initial condition of the Universe, yet it is challenging to efficiently measure the spin direction for the tremendous amount of galaxies that are being mapped by the ongoing and forthcoming cosmological surveys. We present a machine learning based classifier for the Z-wise vs S-wise spirals, which can help to break the degeneracy in the galaxy spin direction measurement. The proposed Chirality Equivariant Residual Network (CE-ResNet) is manifestly equivariant under a reflection of the input image, which guarantees that there is no inherent asymmetry between the Z-wise and S-wise probability estimators. We train the model with Sloan Digital Sky Survey (SDSS) images, with the training labels given by the Galaxy Zoo 1 (GZ1) project. A combination of data augmentation tricks are used during the training, making the model more robust to be applied to other surveys. We find a $\sim\!30\%$ increase of both types of spirals when Dark Energy Spectroscopic Instrument (DESI) images are used for classification, due to the better imaging quality of DESI. We verify that the $\sim\!7\sigma$ difference between the numbers of Z-wise and S-wise spirals is due to human bias, since the discrepancy drops to $<\!1.8\sigma$ with our CE-ResNet classification results. We discuss the potential systematics that are relevant to the future cosmological applications.
Adaptive Distribution Calibration for Few-Shot Learning with Hierarchical Optimal Transport
Oct 09, 2022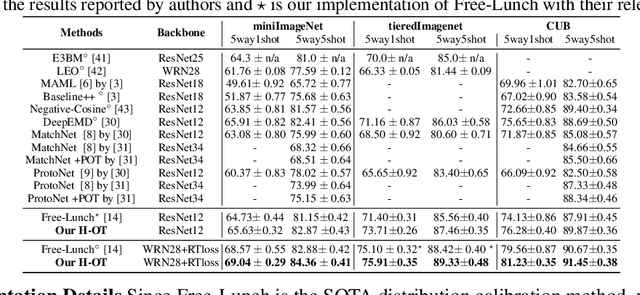
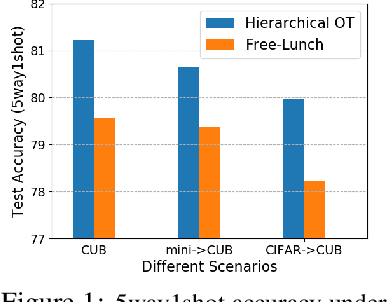
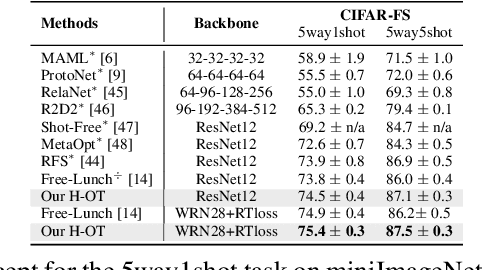

Few-shot classification aims to learn a classifier to recognize unseen classes during training, where the learned model can easily become over-fitted based on the biased distribution formed by only a few training examples. A recent solution to this problem is calibrating the distribution of these few sample classes by transferring statistics from the base classes with sufficient examples, where how to decide the transfer weights from base classes to novel classes is the key. However, principled approaches for learning the transfer weights have not been carefully studied. To this end, we propose a novel distribution calibration method by learning the adaptive weight matrix between novel samples and base classes, which is built upon a hierarchical Optimal Transport (H-OT) framework. By minimizing the high-level OT distance between novel samples and base classes, we can view the learned transport plan as the adaptive weight information for transferring the statistics of base classes. The learning of the cost function between a base class and novel class in the high-level OT leads to the introduction of the low-level OT, which considers the weights of all the data samples in the base class. Experimental results on standard benchmarks demonstrate that our proposed plug-and-play model outperforms competing approaches and owns desired cross-domain generalization ability, indicating the effectiveness of the learned adaptive weights.