 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiGraspNet: A Multitask 3D Vision Model for Multi-gripper Robotic Grasping
Feb 06, 2026Vision-based models for robotic grasping automate critical, repetitive, and draining industrial tasks. Existing approaches are typically limited in two ways: they either target a single gripper and are potentially applied on costly dual-arm setups, or rely on custom hybrid grippers that require ad-hoc learning procedures with logic that cannot be transferred across tasks, restricting their general applicability. In this work, we present MultiGraspNet, a novel multitask 3D deep learning method that predicts feasible poses simultaneously for parallel and vacuum grippers within a unified framework, enabling a single robot to handle multiple end effectors. The model is trained on the richly annotated GraspNet-1Billion and SuctionNet-1Billion datasets, which have been aligned for the purpose, and generates graspability masks quantifying the suitability of each scene point for successful grasps. By sharing early-stage features while maintaining gripper-specific refiners, MultiGraspNet effectively leverages complementary information across grasping modalities, enhancing robustness and adaptability in cluttered scenes. We characterize MultiGraspNet's performance with an extensive experimental analysis, demonstrating its competitiveness with single-task models on relevant benchmarks. We run real-world experiments on a single-arm multi-gripper robotic setup showing that our approach outperforms the vacuum baseline, grasping 16% percent more seen objects and 32% more of the novel ones, while obtaining competitive results for the parallel task.
Doc2Graph: a Task Agnostic Document Understanding Framework based on Graph Neural Networks
Aug 23, 2022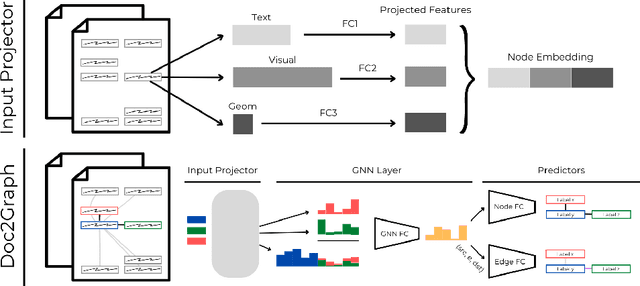


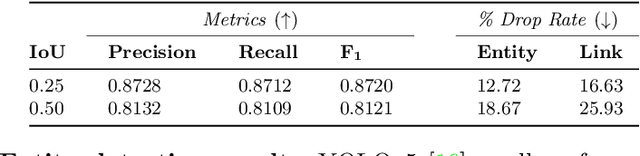
Geometric Deep Learning has recently attracted significant interest in a wide range of machine learning fields, including document analysis. The application of Graph Neural Networks (GNNs) has become crucial in various document-related tasks since they can unravel important structural patterns, fundamental in key information extraction processes. Previous works in the literature propose task-driven models and do not take into account the full power of graphs. We propose Doc2Graph, a task-agnostic document understanding framework based on a GNN model, to solve different tasks given different types of documents. We evaluated our approach on two challenging datasets for key information extraction in form understanding, invoice layout analysis and table detection. Our code is freely accessible on https://github.com/andreagemelli/doc2graph.
Contextual Decision Trees
Jul 13, 2022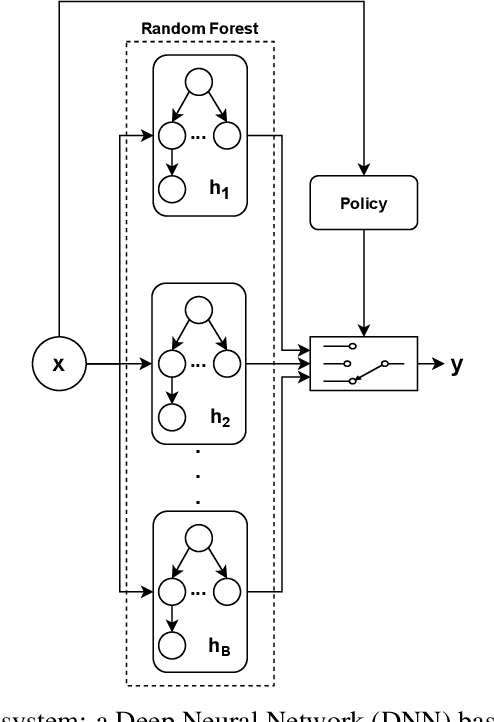
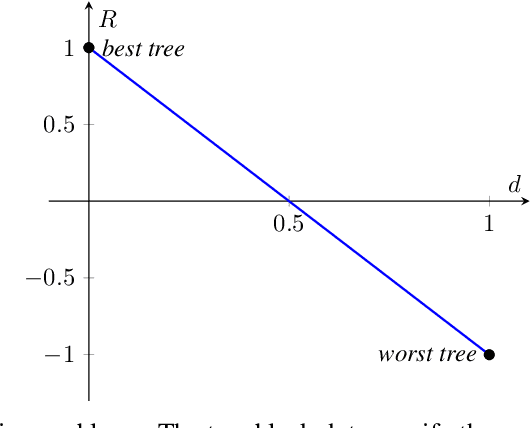

Focusing on Random Forests, we propose a multi-armed contextual bandit recommendation framework for feature-based selection of a single shallow tree of the learned ensemble. The trained system, which works on top of the Random Forest, dynamically identifies a base predictor that is responsible for providing the final output. In this way, we obtain local interpretations by observing the rules of the recommended tree. The carried out experiments reveal that our dynamic method is superior to an independent fitted CART decision tree and comparable to the whole black-box Random Forest in terms of predictive performances.
A Robust Initialization of Residual Blocks for Effective ResNet Training without Batch Normalization
Dec 23, 2021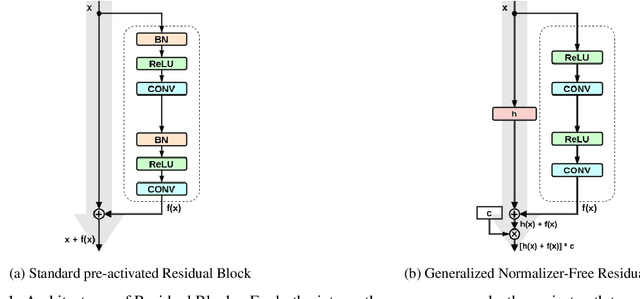
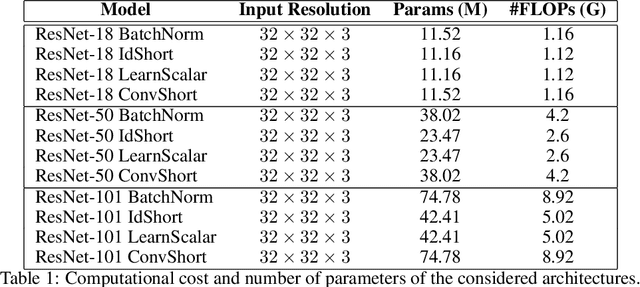
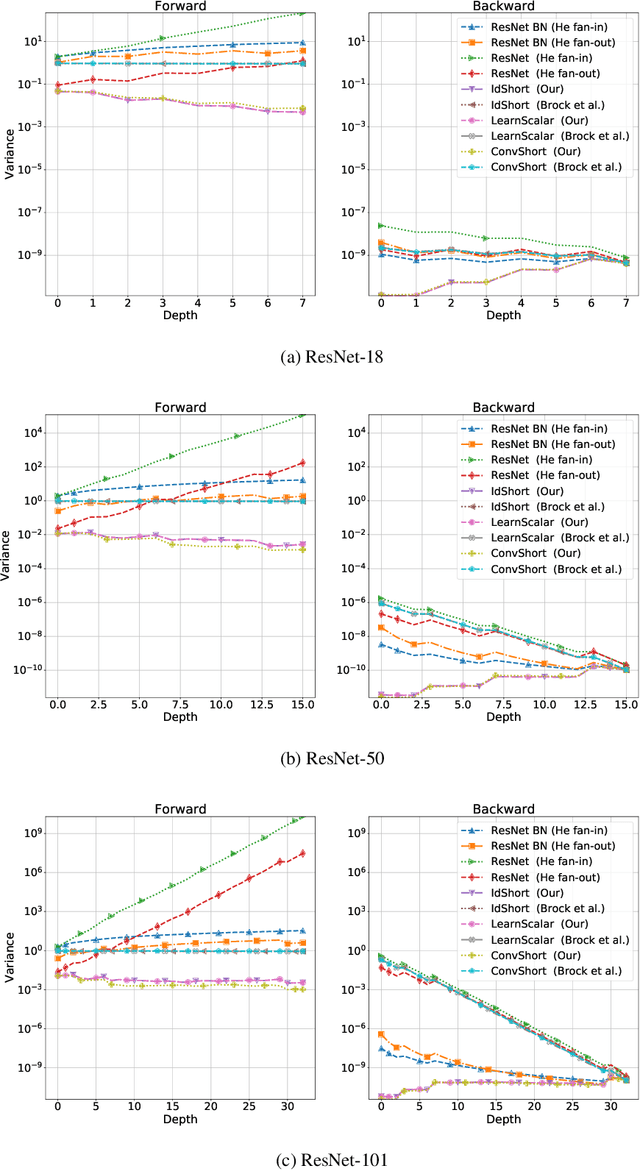
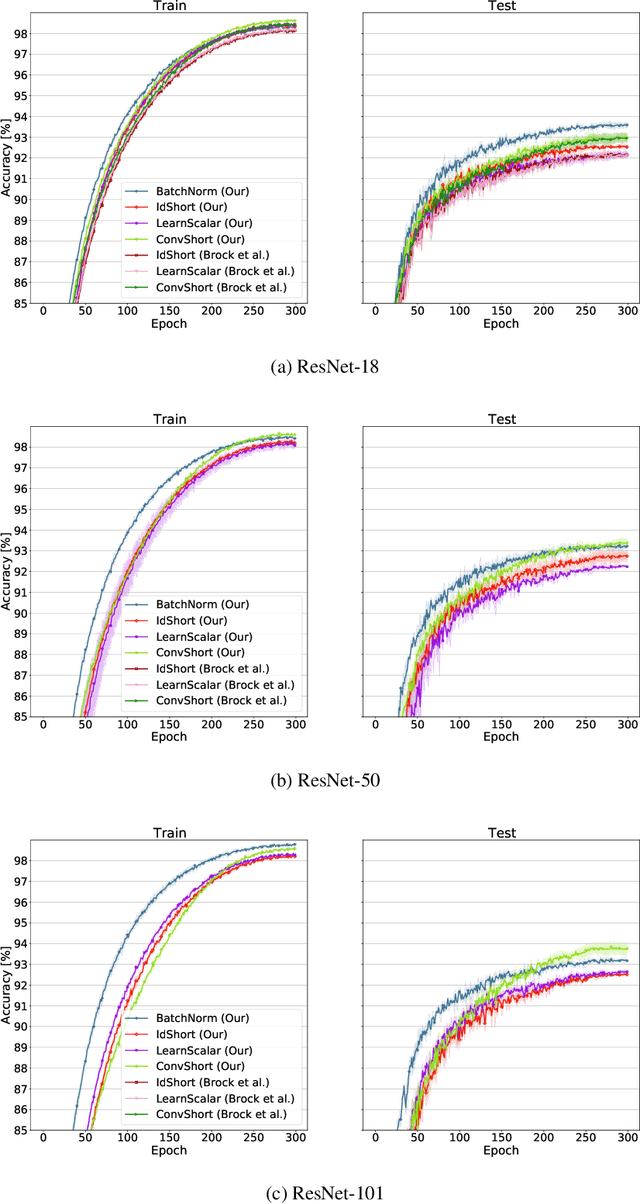
Batch Normalization is an essential component of all state-of-the-art neural networks architectures. However, since it introduces many practical issues, much recent research has been devoted to designing normalization-free architectures. In this paper, we show that weights initialization is key to train ResNet-like normalization-free networks. In particular, we propose a slight modification to the summation operation of a block output to the skip connection branch, so that the whole network is correctly initialized. We show that this modified architecture achieves competitive results on CIFAR-10 without further regularization nor algorithmic modifications.