 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy4OOD: A Knowledge-Guided World Model for Policy Intervention Simulation against the Opioid Overdose Crisis
Feb 12, 2026The opioid epidemic remains one of the most severe public health crises in the United States, yet evaluating policy interventions before implementation is difficult: multiple policies interact within a dynamic system where targeting one risk pathway may inadvertently amplify another. We argue that effective opioid policy evaluation requires three capabilities -- forecasting future outcomes under current policies, counterfactual reasoning about alternative past decisions, and optimization over candidate interventions -- and propose to unify them through world modeling. We introduce Policy4OOD, a knowledge-guided spatio-temporal world model that addresses three core challenges: what policies prescribe, where effects manifest, and when effects unfold.Policy4OOD jointly encodes policy knowledge graphs, state-level spatial dependencies, and socioeconomic time series into a policy-conditioned Transformer that forecasts future opioid outcomes.Once trained, the world model serves as a simulator: forecasting requires only a forward pass, counterfactual analysis substitutes alternative policy encodings in the historical sequence, and policy optimization employs Monte Carlo Tree Search over the learned simulator. To support this framework, we construct a state-level monthly dataset (2019--2024) integrating opioid mortality, socioeconomic indicators, and structured policy encodings. Experiments demonstrate that spatial dependencies and structured policy knowledge significantly improve forecasting accuracy, validating each architectural component and the potential of world modeling for data-driven public health decision support.
Graph Foundation Models: A Comprehensive Survey
May 21, 2025Graph-structured data pervades domains such as social networks, biological systems, knowledge graphs, and recommender systems. While foundation models have transformed natural language processing, vision, and multimodal learning through large-scale pretraining and generalization, extending these capabilities to graphs -- characterized by non-Euclidean structures and complex relational semantics -- poses unique challenges and opens new opportunities. To this end, Graph Foundation Models (GFMs) aim to bring scalable, general-purpose intelligence to structured data, enabling broad transfer across graph-centric tasks and domains. This survey provides a comprehensive overview of GFMs, unifying diverse efforts under a modular framework comprising three key components: backbone architectures, pretraining strategies, and adaptation mechanisms. We categorize GFMs by their generalization scope -- universal, task-specific, and domain-specific -- and review representative methods, key innovations, and theoretical insights within each category. Beyond methodology, we examine theoretical foundations including transferability and emergent capabilities, and highlight key challenges such as structural alignment, heterogeneity, scalability, and evaluation. Positioned at the intersection of graph learning and general-purpose AI, GFMs are poised to become foundational infrastructure for open-ended reasoning over structured data. This survey consolidates current progress and outlines future directions to guide research in this rapidly evolving field. Resources are available at https://github.com/Zehong-Wang/Awesome-Foundation-Models-on-Graphs.
BenchmarkCards: Large Language Model and Risk Reporting
Oct 16, 2024


Large language models (LLMs) offer powerful capabilities but also introduce significant risks. One way to mitigate these risks is through comprehensive pre-deployment evaluations using benchmarks designed to test for specific vulnerabilities. However, the rapidly expanding body of LLM benchmark literature lacks a standardized method for documenting crucial benchmark details, hindering consistent use and informed selection. BenchmarkCards addresses this gap by providing a structured framework specifically for documenting LLM benchmark properties rather than defining the entire evaluation process itself. BenchmarkCards do not prescribe how to measure or interpret benchmark results (e.g., defining ``correctness'') but instead offer a standardized way to capture and report critical characteristics like targeted risks and evaluation methodologies, including properties such as bias and fairness. This structured metadata facilitates informed benchmark selection, enabling researchers to choose appropriate benchmarks and promoting transparency and reproducibility in LLM evaluation.
Fast Explainability via Feasible Concept Sets Generator
May 29, 2024



A long-standing dilemma prevents the broader application of explanation methods: general applicability and inference speed. On the one hand, existing model-agnostic explanation methods usually make minimal pre-assumptions about the prediction models to be explained. Still, they require additional queries to the model through propagation or back-propagation to approximate the models' behaviors, resulting in slow inference and hindering their use in time-sensitive tasks. On the other hand, various model-dependent explanations have been proposed that achieve low-cost, fast inference but at the expense of limiting their applicability to specific model structures. In this study, we bridge the gap between the universality of model-agnostic approaches and the efficiency of model-specific approaches by proposing a novel framework without assumptions on the prediction model's structures, achieving high efficiency during inference and allowing for real-time explanations. To achieve this, we first define explanations through a set of human-comprehensible concepts and propose a framework to elucidate model predictions via minimal feasible concept sets. Second, we show that a minimal feasible set generator can be learned as a companion explainer to the prediction model, generating explanations for predictions. Finally, we validate this framework by implementing a novel model-agnostic method that provides robust explanations while facilitating real-time inference. Our claims are substantiated by comprehensive experiments, highlighting the effectiveness and efficiency of our approach.
Post-Fair Federated Learning: Achieving Group and Community Fairness in Federated Learning via Post-processing
May 28, 2024



Federated Learning (FL) is a distributed machine learning framework in which a set of local communities collaboratively learn a shared global model while retaining all training data locally within each community. Two notions of fairness have recently emerged as important issues for federated learning: group fairness and community fairness. Group fairness requires that a model's decisions do not favor any particular group based on a set of legally protected attributes such as race or gender. Community fairness requires that global models exhibit similar levels of performance (accuracy) across all collaborating communities. Both fairness concepts can coexist within an FL framework, but the existing literature has focused on either one concept or the other. This paper proposes and analyzes a post-processing fair federated learning (FFL) framework called post-FFL. Post-FFL uses a linear program to simultaneously enforce group and community fairness while maximizing the utility of the global model. Because Post-FFL is a post-processing approach, it can be used with existing FL training pipelines whose convergence properties are well understood. This paper uses post-FFL on real-world datasets to mimic how hospital networks, for example, use federated learning to deliver community health care. Theoretical results bound the accuracy lost when post-FFL enforces both notion of fairness. Experimental results illustrate that post-FFL simultaneously improves both group and community fairness in FL. Moreover, post-FFL outperforms the existing in-processing fair federated learning in terms of improving both notions of fairness, communication efficiency and computation cost.
Conformalized Selective Regression
Feb 26, 2024Should prediction models always deliver a prediction? In the pursuit of maximum predictive performance, critical considerations of reliability and fairness are often overshadowed, particularly when it comes to the role of uncertainty. Selective regression, also known as the "reject option," allows models to abstain from predictions in cases of considerable uncertainty. Initially proposed seven decades ago, approaches to selective regression have mostly focused on distribution-based proxies for measuring uncertainty, particularly conditional variance. However, this focus neglects the significant influence of model-specific biases on a model's performance. In this paper, we propose a novel approach to selective regression by leveraging conformal prediction, which provides grounded confidence measures for individual predictions based on model-specific biases. In addition, we propose a standardized evaluation framework to allow proper comparison of selective regression approaches. Via an extensive experimental approach, we demonstrate how our proposed approach, conformalized selective regression, demonstrates an advantage over multiple state-of-the-art baselines.
Privacy-Preserving Data Synthetisation for Secure Information Sharing
Dec 01, 2022



We can protect user data privacy via many approaches, such as statistical transformation or generative models. However, each of them has critical drawbacks. On the one hand, creating a transformed data set using conventional techniques is highly time-consuming. On the other hand, in addition to long training phases, recent deep learning-based solutions require significant computational resources. In this paper, we propose PrivateSMOTE, a technique designed for competitive effectiveness in protecting cases at maximum risk of re-identification while requiring much less time and computational resources. It works by synthetic data generation via interpolation to obfuscate high-risk cases while minimizing data utility loss of the original data. Compared to multiple conventional and state-of-the-art privacy-preservation methods on 20 data sets, PrivateSMOTE demonstrates competitive results in re-identification risk. Also, it presents similar or higher predictive performance than the baselines, including generative adversarial networks and variational autoencoders, reducing their energy consumption and time requirements by a minimum factor of 9 and 12, respectively.
Linkless Link Prediction via Relational Distillation
Oct 19, 2022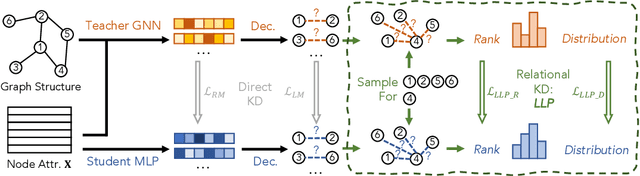
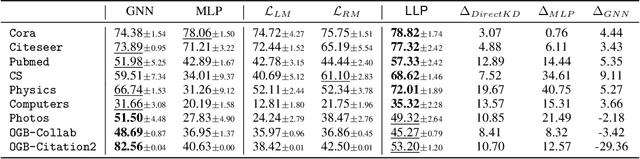
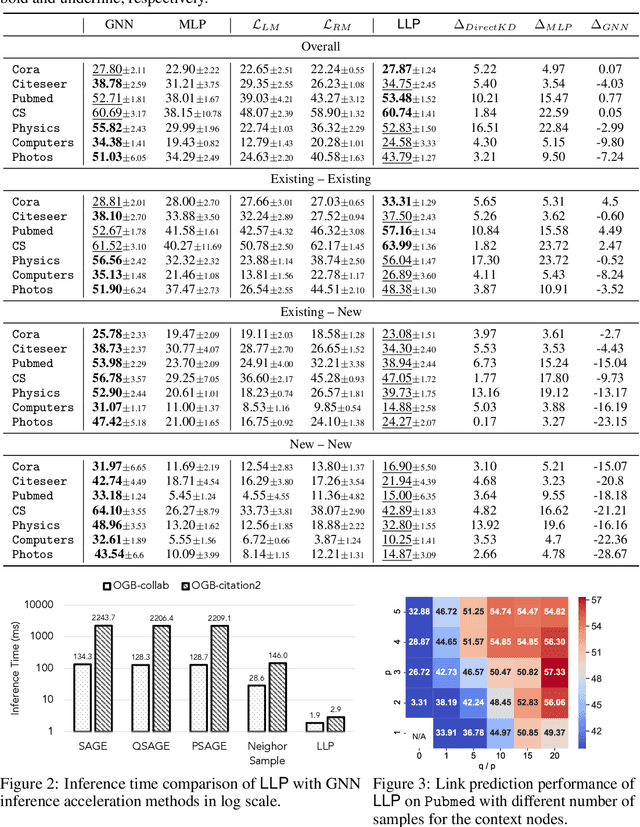
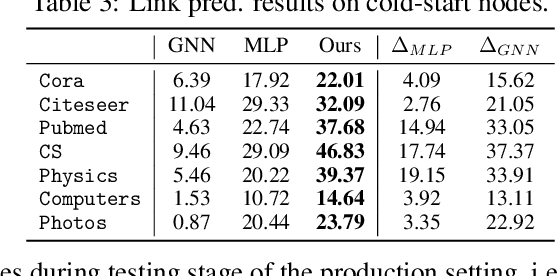
Graph Neural Networks (GNNs) have been widely used on graph data and have shown exceptional performance in the task of link prediction. Despite their effectiveness, GNNs often suffer from high latency due to non-trivial neighborhood data dependency in practical deployments. To address this issue, researchers have proposed methods based on knowledge distillation (KD) to transfer the knowledge from teacher GNNs to student MLPs, which are known to be efficient even with industrial scale data, and have shown promising results on node classification. Nonetheless, using KD to accelerate link prediction is still unexplored. In this work, we start with exploring two direct analogs of traditional KD for link prediction, i.e., predicted logit-based matching and node representation-based matching. Upon observing direct KD analogs do not perform well for link prediction, we propose a relational KD framework, Linkless Link Prediction (LLP). Unlike simple KD methods that match independent link logits or node representations, LLP distills relational knowledge that is centered around each (anchor) node to the student MLP. Specifically, we propose two matching strategies that complement each other: rank-based matching and distribution-based matching. Extensive experiments demonstrate that LLP boosts the link prediction performance of MLPs with significant margins, and even outperforms the teacher GNNs on 6 out of 9 benchmarks. LLP also achieves a 776.37x speedup in link prediction inference compared to GNNs on the large scale OGB-Citation2 dataset.
Understanding CNN Fragility When Learning With Imbalanced Data
Oct 17, 2022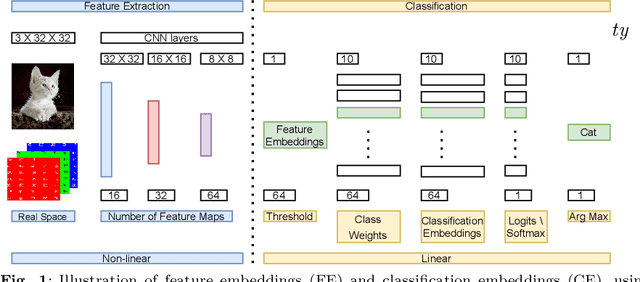
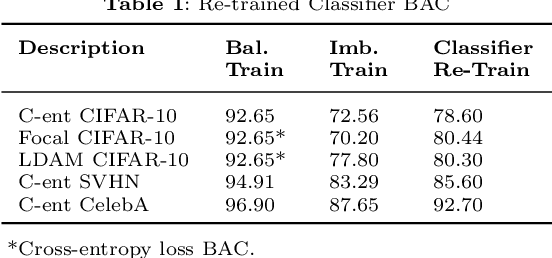
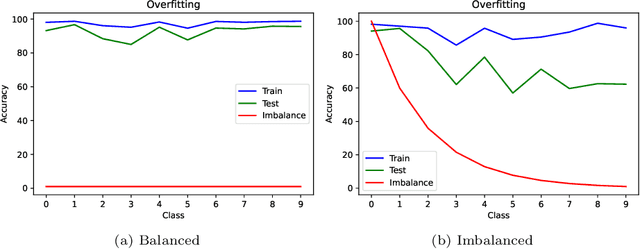
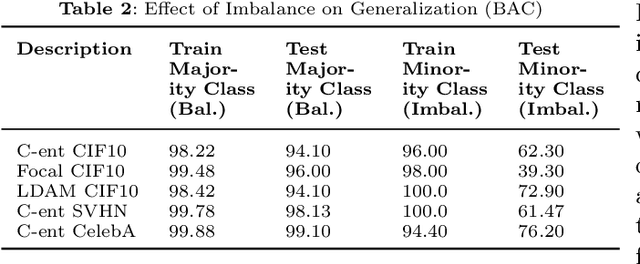
Convolutional neural networks (CNNs) have achieved impressive results on imbalanced image data, but they still have difficulty generalizing to minority classes and their decisions are difficult to interpret. These problems are related because the method by which CNNs generalize to minority classes, which requires improvement, is wrapped in a blackbox. To demystify CNN decisions on imbalanced data, we focus on their latent features. Although CNNs embed the pattern knowledge learned from a training set in model parameters, the effect of this knowledge is contained in feature and classification embeddings (FE and CE). These embeddings can be extracted from a trained model and their global, class properties (e.g., frequency, magnitude and identity) can be analyzed. We find that important information regarding the ability of a neural network to generalize to minority classes resides in the class top-K CE and FE. We show that a CNN learns a limited number of class top-K CE per category, and that their number and magnitudes vary based on whether the same class is balanced or imbalanced. This calls into question whether a CNN has learned intrinsic class features, or merely frequently occurring ones that happen to exist in the sampled class distribution. We also hypothesize that latent class diversity is as important as the number of class examples, which has important implications for re-sampling and cost-sensitive methods. These methods generally focus on rebalancing model weights, class numbers and margins; instead of diversifying class latent features through augmentation. We also demonstrate that a CNN has difficulty generalizing to test data if the magnitude of its top-K latent features do not match the training set. We use three popular image datasets and two cost-sensitive algorithms commonly employed in imbalanced learning for our experiments.
Boosting Graph Neural Networks via Adaptive Knowledge Distillation
Oct 12, 2022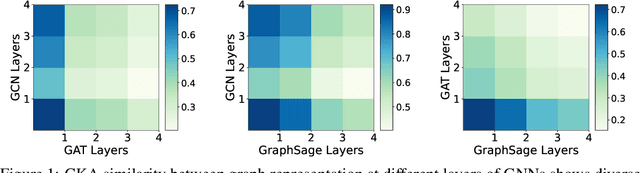
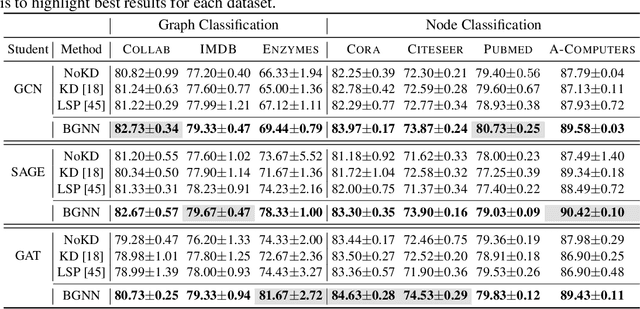
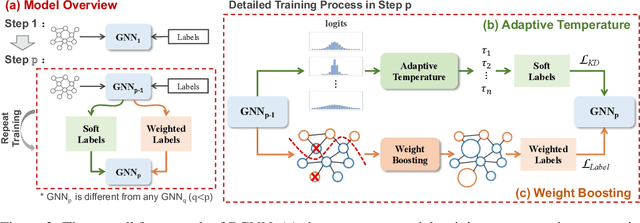
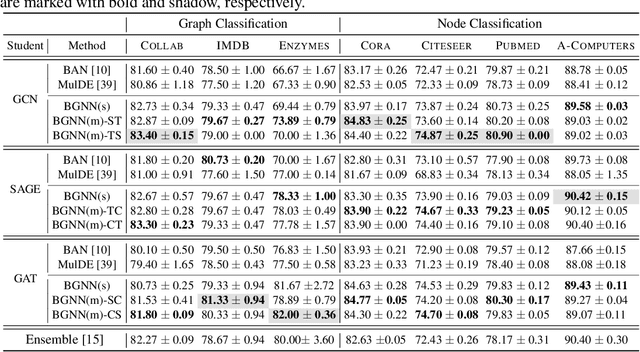
Graph neural networks (GNNs) have shown remarkable performance on diverse graph mining tasks. Although different GNNs can be unified as the same message passing framework, they learn complementary knowledge from the same graph. Knowledge distillation (KD) is developed to combine the diverse knowledge from multiple models. It transfers knowledge from high-capacity teachers to a lightweight student. However, to avoid oversmoothing, GNNs are often shallow, which deviates from the setting of KD. In this context, we revisit KD by separating its benefits from model compression and emphasizing its power of transferring knowledge. To this end, we need to tackle two challenges: how to transfer knowledge from compact teachers to a student with the same capacity; and, how to exploit student GNN's own strength to learn knowledge. In this paper, we propose a novel adaptive KD framework, called BGNN, which sequentially transfers knowledge from multiple GNNs into a student GNN. We also introduce an adaptive temperature module and a weight boosting module. These modules guide the student to the appropriate knowledge for effective learning. Extensive experiments have demonstrated the effectiveness of BGNN. In particular, we achieve up to 3.05% improvement for node classification and 7.67% improvement for graph classification over vanilla GNNs.