 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DAGAD: Data Augmentation for Graph Anomaly Detection
Oct 18, 2022
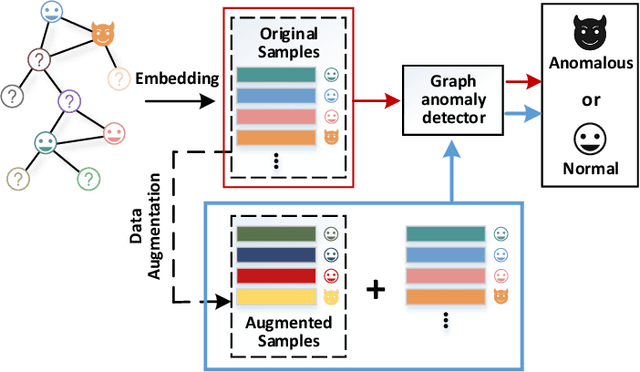
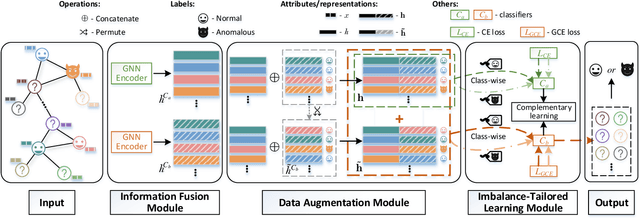
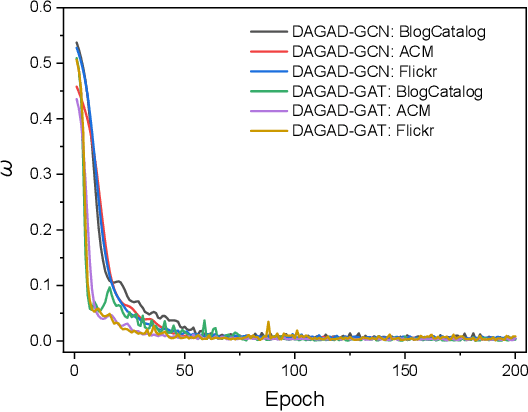
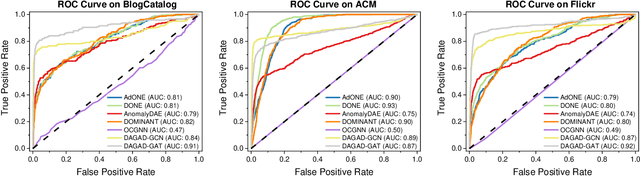
Graph anomaly detection in this paper aims to distinguish abnormal nodes that behave differently from the benign ones accounting for the majority of graph-structured instances. Receiving increasing attention from both academia and industry, yet existing research on this task still suffers from two critical issues when learning informative anomalous behavior from graph data. For one thing, anomalies are usually hard to capture because of their subtle abnormal behavior and the shortage of background knowledge about them, which causes severe anomalous sample scarcity. Meanwhile, the overwhelming majority of objects in real-world graphs are normal, bringing the class imbalance problem as well. To bridge the gaps, this paper devises a novel Data Augmentation-based Graph Anomaly Detection (DAGAD) framework for attributed graphs, equipped with three specially designed modules: 1) an information fusion module employing graph neural network encoders to learn representations, 2) a graph data augmentation module that fertilizes the training set with generated samples, and 3) an imbalance-tailored learning module to discriminate the distributions of the minority (anomalous) and majority (normal) classes. A series of experiments on three datasets prove that DAGAD outperforms ten state-of-the-art baseline detectors concerning various mostly-used metrics, together with an extensive ablation study validating the strength of our proposed modules.
Convergence of the mini-batch SIHT algorithm
Sep 29, 2022The Iterative Hard Thresholding (IHT) algorithm has been considered extensively as an effective deterministic algorithm for solving sparse optimizations. The IHT algorithm benefits from the information of the batch (full) gradient at each point and this information is a crucial key for the convergence analysis of the generated sequence. However, this strength becomes a weakness when it comes to machine learning and high dimensional statistical applications because calculating the batch gradient at each iteration is computationally expensive or impractical. Fortunately, in these applications the objective function has a summation structure that can be taken advantage of to approximate the batch gradient by the stochastic mini-batch gradient. In this paper, we study the mini-batch Stochastic IHT (SIHT) algorithm for solving the sparse optimizations. As opposed to previous works where increasing and variable mini-batch size is necessary for derivation, we fix the mini-batch size according to a lower bound that we derive and show our work. To prove stochastic convergence of the objective value function we first establish a critical sparse stochastic gradient descent property. Using this stochastic gradient descent property we show that the sequence generated by the stochastic mini-batch SIHT is a supermartingale sequence and converges with probability one. Unlike previous work we do not assume the function to be a restricted strongly convex. To the best of our knowledge, in the regime of sparse optimization, this is the first time in the literature that it is shown that the sequence of the stochastic function values converges with probability one by fixing the mini-batch size for all steps.
Spatiotemporal-Enhanced Network for Click-Through Rate Prediction in Location-based Services
Sep 20, 2022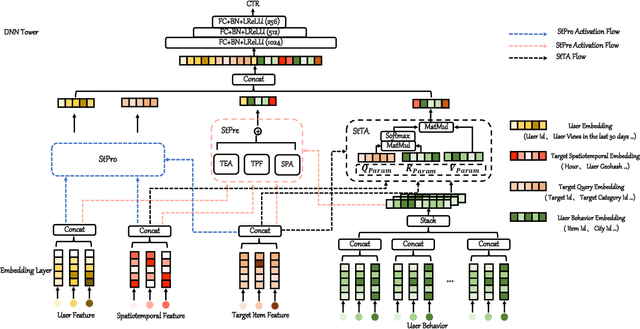
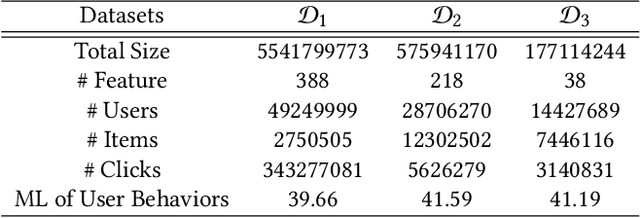
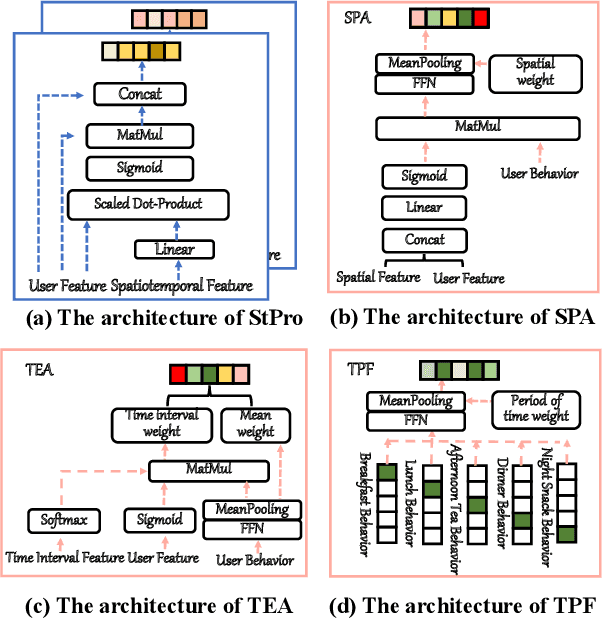
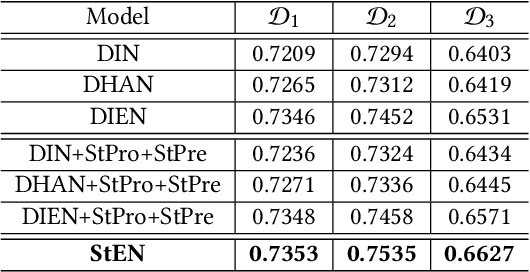
In Location-Based Services(LBS), user behavior naturally has a strong dependence on the spatiotemporal information, i.e., in different geographical locations and at different times, user click behavior will change significantly. Appropriate spatiotemporal enhancement modeling of user click behavior and large-scale sparse attributes is key to building an LBS model. Although most of existing methods have been proved to be effective, they are difficult to apply to takeaway scenarios due to insufficient modeling of spatiotemporal information. In this paper, we address this challenge by seeking to explicitly model the timing and locations of interactions and proposing a Spatiotemporal-Enhanced Network, namely StEN. In particular, StEN applies a Spatiotemporal Profile Activation module to capture common spatiotemporal preference through attribute features. A Spatiotemporal Preference Activation is further applied to model the personalized spatiotemporal preference embodied by behaviors in detail. Moreover, a Spatiotemporal-aware Target Attention mechanism is adopted to generate different parameters for target attention at different locations and times, thereby improving the personalized spatiotemporal awareness of the model.Comprehensive experiments are conducted on three large-scale industrial datasets, and the results demonstrate the state-of-the-art performance of our methods. In addition, we have also released an industrial dataset for takeaway industry to make up for the lack of public datasets in this community.
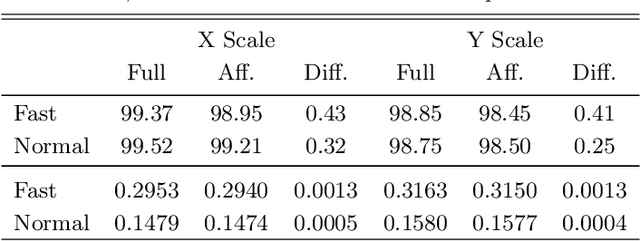
Accurate and Efficient Stereo Matching via Attention Concatenation Volume
Sep 27, 2022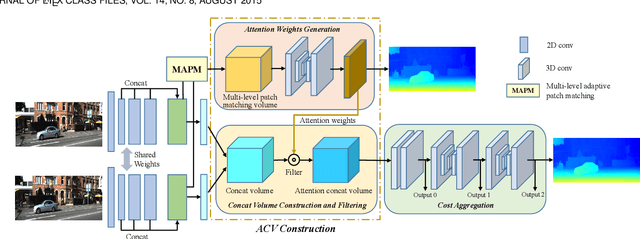

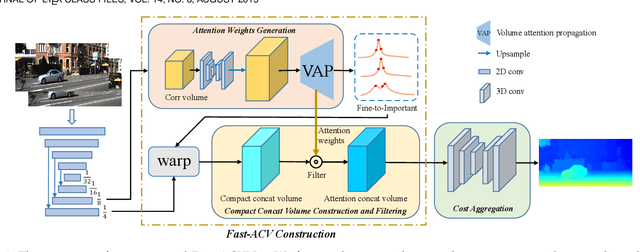
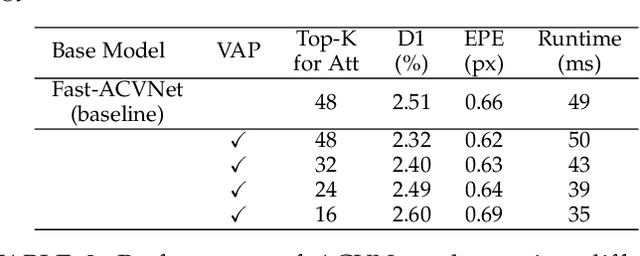
Stereo matching is a fundamental building block for many vision and robotics applications. An informative and concise cost volume representation is vital for stereo matching of high accuracy and efficiency. In this paper, we present a novel cost volume construction method, named attention concatenation volume (ACV), which generates attention weights from correlation clues to suppress redundant information and enhance matching-related information in the concatenation volume. The ACV can be seamlessly embedded into most stereo matching networks, the resulting networks can use a more lightweight aggregation network and meanwhile achieve higher accuracy. We further design a fast version of ACV to enable real-time performance, named Fast-ACV, which generates high likelihood disparity hypotheses and the corresponding attention weights from low-resolution correlation clues to significantly reduce computational and memory cost and meanwhile maintain a satisfactory accuracy. The core idea of our Fast-ACV is volume attention propagation (VAP) which can automatically select accurate correlation values from an upsampled correlation volume and propagate these accurate values to the surroundings pixels with ambiguous correlation clues. Furthermore, we design a highly accurate network ACVNet and a real-time network Fast-ACVNet based on our ACV and Fast-ACV respectively, which achieve the state-of-the-art performance on several benchmarks (i.e., our ACVNet ranks the 2nd on KITTI 2015 and Scene Flow, and the 3rd on KITTI 2012 and ETH3D among all the published methods; our Fast-ACVNet outperforms almost all state-of-the-art real-time methods on Scene Flow, KITTI 2012 and 2015 and meanwhile has better generalization ability)
The Impact of Missing Velocity Information in Dynamic Obstacle Avoidance based on Deep Reinforcement Learning
Dec 23, 2021

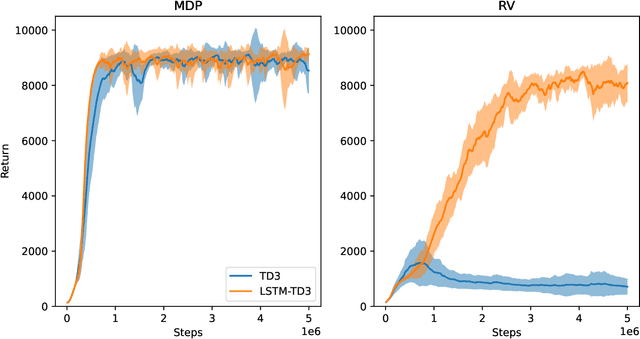

We introduce a novel approach to dynamic obstacle avoidance based on Deep Reinforcement Learning by defining a traffic type independent environment with variable complexity. Filling a gap in the current literature, we thoroughly investigate the effect of missing velocity information on an agent's performance in obstacle avoidance tasks. This is a crucial issue in practice since several sensors yield only positional information of objects or vehicles. We evaluate frequently-applied approaches in scenarios of partial observability, namely the incorporation of recurrency in the deep neural networks and simple frame-stacking. For our analysis, we rely on state-of-the-art model-free deep RL algorithms. The lack of velocity information is found to significantly impact the performance of an agent. Both approaches - recurrency and frame-stacking - cannot consistently replace missing velocity information in the observation space. However, in simplified scenarios, they can significantly boost performance and stabilize the overall training procedure.
Large-Scale Spatial Cross-Calibration of Hinode/SOT-SP and SDO/HMI
Sep 29, 2022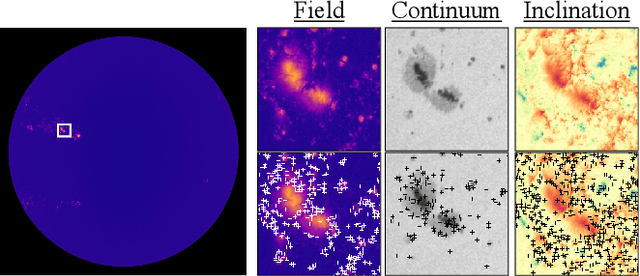
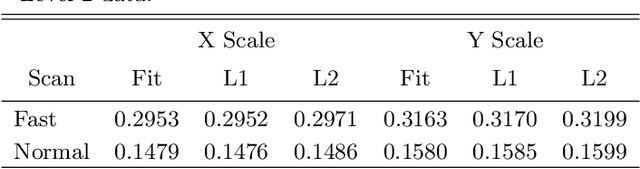
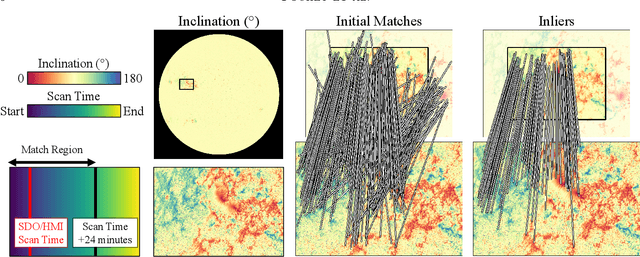
We investigate the cross-calibration of the Hinode/SOT-SP and SDO/HMI instrument meta-data, specifically the correspondence of the scaling and pointing information. Accurate calibration of these datasets gives the correspondence needed by inter-instrument studies and learning-based magnetogram systems, and is required for physically-meaningful photospheric magnetic field vectors. We approach the problem by robustly fitting geometric models on correspondences between images from each instrument's pipeline. This technique is common in computer vision, but several critical details are required when using scanning slit spectrograph data like Hinode/SOT-SP. We apply this technique to data spanning a decade of the Hinode mission. Our results suggest corrections to the published Level 2 Hinode/SOT-SP data. First, an analysis on approximately 2,700 scans suggests that the reported pixel size in Hinode/SOT-SP Level 2 data is incorrect by around 1%. Second, analysis of over 12,000 scans show that the pointing information is often incorrect by dozens of arcseconds with a strong bias. Regression of these corrections indicates that thermal effects have caused secular and cyclic drift in Hinode/SOT-SP pointing data over its mission. We offer two solutions. First, direct co-alignment with SDO/HMI data via our procedure can improve alignments for many Hinode/SOT-SP scans. Second, since the pointing errors are predictable, simple post-hoc corrections can substantially improve the pointing. We conclude by illustrating the impact of this updated calibration on derived physical data products needed for research and interpretation. Among other things, our results suggest that the pointing errors induce a hemispheric bias in estimates of radial current density.
A Novel Multi-Task Learning Approach for Context-Sensitive Compound Type Identification in Sanskrit
Aug 22, 2022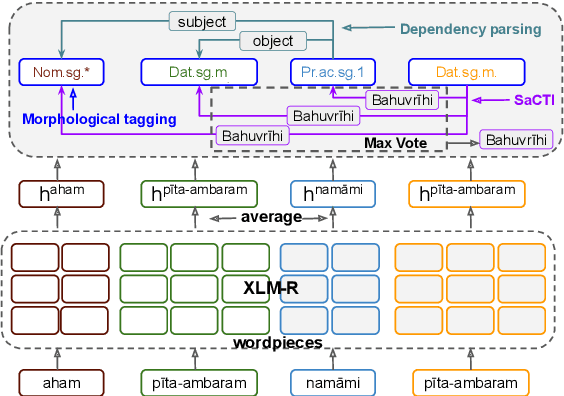
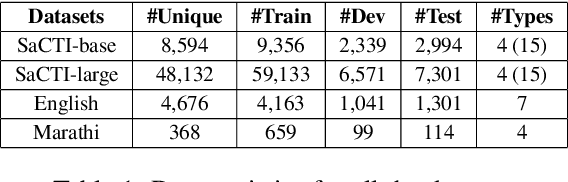
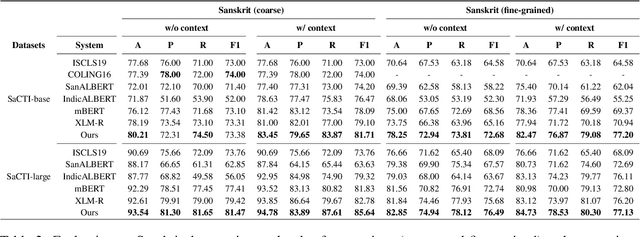
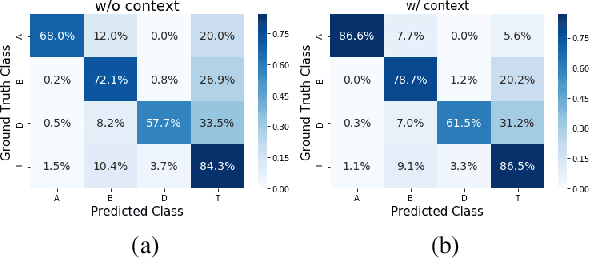
The phenomenon of compounding is ubiquitous in Sanskrit. It serves for achieving brevity in expressing thoughts, while simultaneously enriching the lexical and structural formation of the language. In this work, we focus on the Sanskrit Compound Type Identification (SaCTI) task, where we consider the problem of identifying semantic relations between the components of a compound word. Earlier approaches solely rely on the lexical information obtained from the components and ignore the most crucial contextual and syntactic information useful for SaCTI. However, the SaCTI task is challenging primarily due to the implicitly encoded context-sensitive semantic relation between the compound components. Thus, we propose a novel multi-task learning architecture which incorporates the contextual information and enriches the complementary syntactic information using morphological tagging and dependency parsing as two auxiliary tasks. Experiments on the benchmark datasets for SaCTI show 6.1 points (Accuracy) and 7.7 points (F1-score) absolute gain compared to the state-of-the-art system. Further, our multi-lingual experiments demonstrate the efficacy of the proposed architecture in English and Marathi languages.The code and datasets are publicly available at https://github.com/ashishgupta2598/SaCTI
Which is the best model for my data?
Oct 26, 2022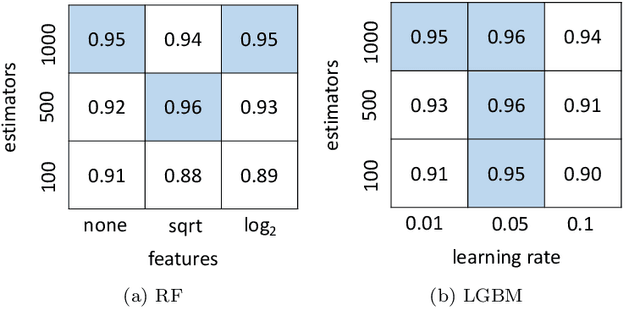

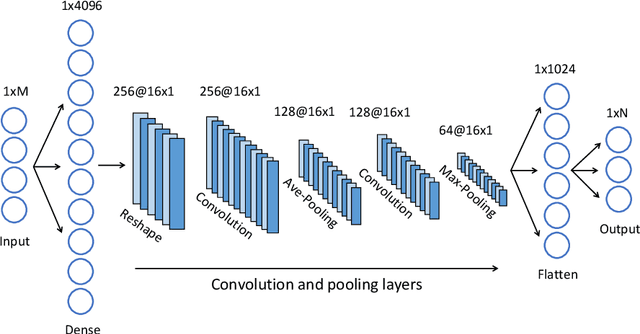

In this paper, we tackle the problem of selecting the optimal model for a given structured pattern classification dataset. In this context, a model can be understood as a classifier and a hyperparameter configuration. The proposed meta-learning approach purely relies on machine learning and involves four major steps. Firstly, we present a concise collection of 62 meta-features that address the problem of information cancellation when aggregation measure values involving positive and negative measurements. Secondly, we describe two different approaches for synthetic data generation intending to enlarge the training data. Thirdly, we fit a set of pre-defined classification models for each classification problem while optimizing their hyperparameters using grid search. The goal is to create a meta-dataset such that each row denotes a multilabel instance describing a specific problem. The features of these meta-instances denote the statistical properties of the generated datasets, while the labels encode the grid search results as binary vectors such that best-performing models are positively labeled. Finally, we tackle the model selection problem with several multilabel classifiers, including a Convolutional Neural Network designed to handle tabular data. The simulation results show that our meta-learning approach can correctly predict an optimal model for 91% of the synthetic datasets and for 87% of the real-world datasets. Furthermore, we noticed that most meta-classifiers produced better results when using our meta-features. Overall, our proposal differs from other meta-learning approaches since it tackles the algorithm selection and hyperparameter tuning problems in a single step. Toward the end, we perform a feature importance analysis to determine which statistical features drive the model selection mechanism.
EW-Tune: A Framework for Privately Fine-Tuning Large Language Models with Differential Privacy
Oct 26, 2022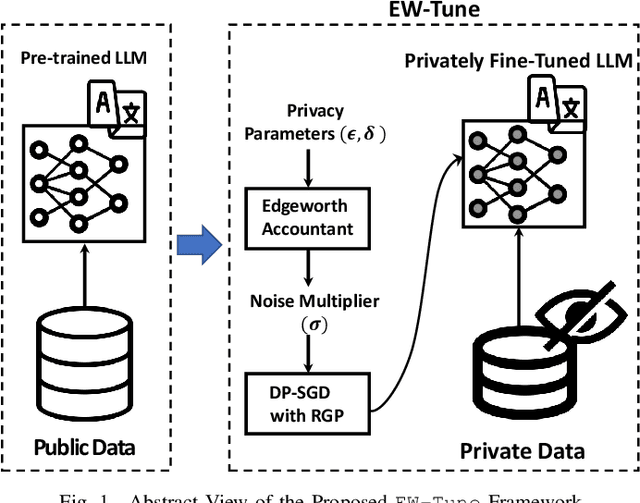
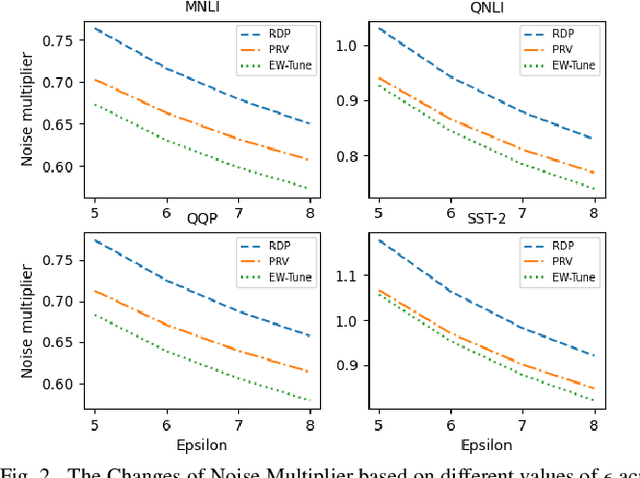

Pre-trained Large Language Models (LLMs) are an integral part of modern AI that have led to breakthrough performances in complex AI tasks. Major AI companies with expensive infrastructures are able to develop and train these large models with billions and millions of parameters from scratch. Third parties, researchers, and practitioners are increasingly adopting these pre-trained models and fine-tuning them on their private data to accomplish their downstream AI tasks. However, it has been shown that an adversary can extract/reconstruct the exact training samples from these LLMs, which can lead to revealing personally identifiable information. The issue has raised deep concerns about the privacy of LLMs. Differential privacy (DP) provides a rigorous framework that allows adding noise in the process of training or fine-tuning LLMs such that extracting the training data becomes infeasible (i.e., with a cryptographically small success probability). While the theoretical privacy guarantees offered in most extant studies assume learning models from scratch through many training iterations in an asymptotic setting, this assumption does not hold in fine-tuning scenarios in which the number of training iterations is significantly smaller. To address the gap, we present \ewtune, a DP framework for fine-tuning LLMs based on Edgeworth accountant with finite-sample privacy guarantees. Our results across four well-established natural language understanding (NLU) tasks show that while \ewtune~adds privacy guarantees to LLM fine-tuning process, it directly contributes to decreasing the induced noise to up to 5.6\% and improves the state-of-the-art LLMs performance by up to 1.1\% across all NLU tasks. We have open-sourced our implementations for wide adoption and public testing purposes.
Constrained Approximate Similarity Search on Proximity Graph
Oct 26, 2022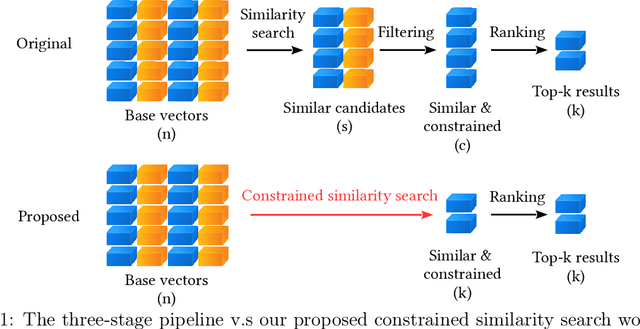
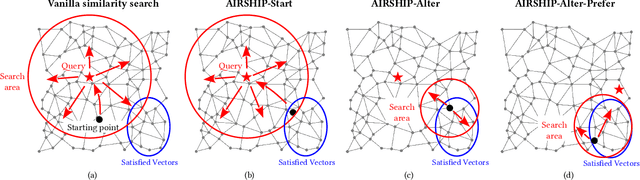
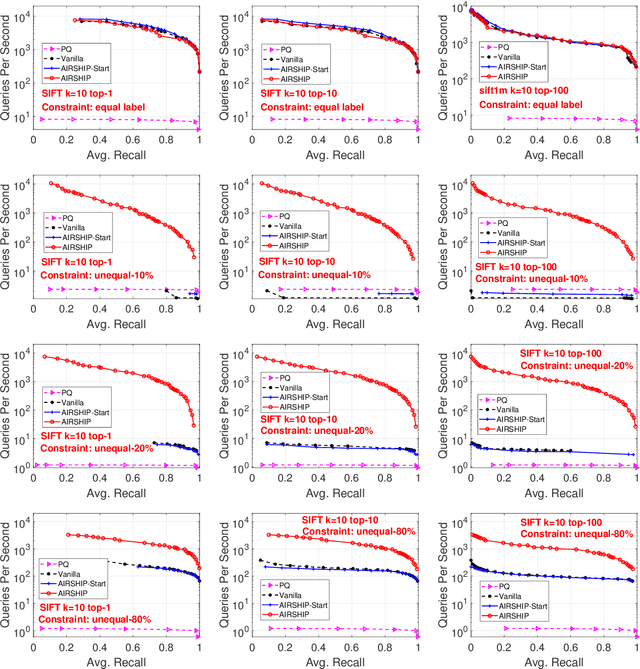
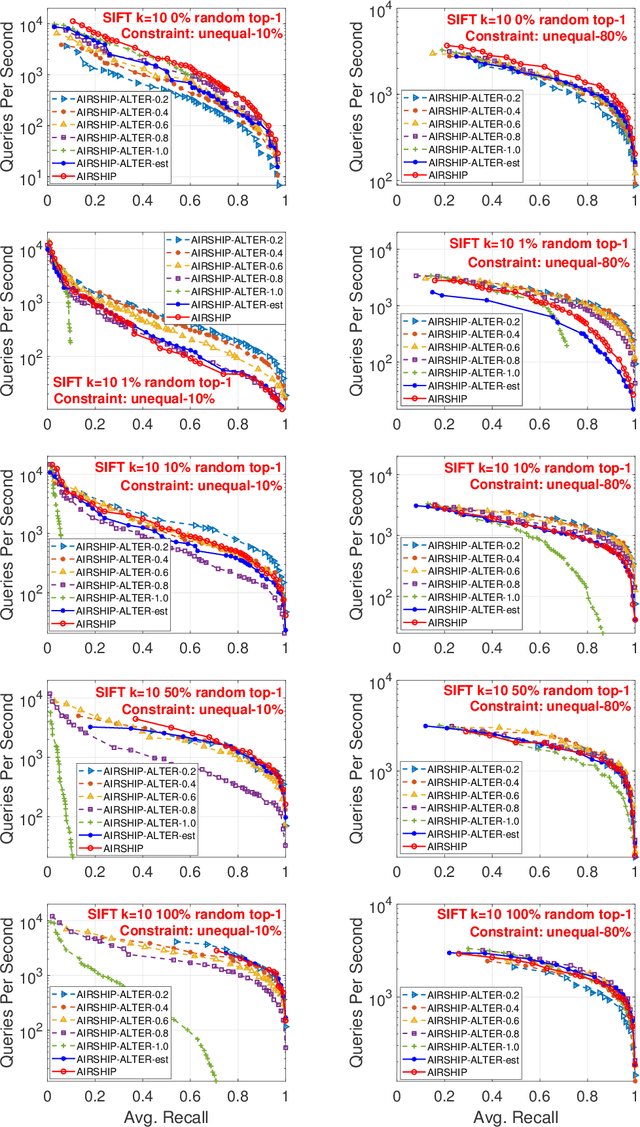
Search engines and recommendation systems are built to efficiently display relevant information from those massive amounts of candidates. Typically a three-stage mechanism is employed in those systems: (i) a small collection of items are first retrieved by (e.g.,) approximate near neighbor search algorithms; (ii) then a collection of constraints are applied on the retrieved items; (iii) a fine-grained ranking neural network is employed to determine the final recommendation. We observe a major defect of the original three-stage pipeline: Although we only target to retrieve $k$ vectors in the final recommendation, we have to preset a sufficiently large $s$ ($s > k$) for each query, and ``hope'' the number of survived vectors after the filtering is not smaller than $k$. That is, at least $k$ vectors in the $s$ similar candidates satisfy the query constraints. In this paper, we investigate this constrained similarity search problem and attempt to merge the similarity search stage and the filtering stage into one single search operation. We introduce AIRSHIP, a system that integrates a user-defined function filtering into the similarity search framework. The proposed system does not need to build extra indices nor require prior knowledge of the query constraints. We propose three optimization strategies: (1) starting point selection, (2) multi-direction search, and (3) biased priority queue selection. Experimental evaluations on both synthetic and real data confirm the effectiveness of the proposed AIRSHIP algorithm. We focus on constrained graph-based approximate near neighbor (ANN) search in this study, in part because graph-based ANN is known to achieve excellent performance. We believe it is also possible to develop constrained hashing-based ANN or constrained quantization-based ANN.