 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersona Jailbreaking in Large Language Models
Jan 23, 2026Large Language Models (LLMs) are increasingly deployed in domains such as education, mental health and customer support, where stable and consistent personas are critical for reliability. Yet, existing studies focus on narrative or role-playing tasks and overlook how adversarial conversational history alone can reshape induced personas. Black-box persona manipulation remains unexplored, raising concerns for robustness in realistic interactions. In response, we introduce the task of persona editing, which adversarially steers LLM traits through user-side inputs under a black-box, inference-only setting. To this end, we propose PHISH (Persona Hijacking via Implicit Steering in History), the first framework to expose a new vulnerability in LLM safety that embeds semantically loaded cues into user queries to gradually induce reverse personas. We also define a metric to quantify attack success. Across 3 benchmarks and 8 LLMs, PHISH predictably shifts personas, triggers collateral changes in correlated traits, and exhibits stronger effects in multi-turn settings. In high-risk domains mental health, tutoring, and customer support, PHISH reliably manipulates personas, validated by both human and LLM-as-Judge evaluations. Importantly, PHISH causes only a small reduction in reasoning benchmark performance, leaving overall utility largely intact while still enabling significant persona manipulation. While current guardrails offer partial protection, they remain brittle under sustained attack. Our findings expose new vulnerabilities in personas and highlight the need for context-resilient persona in LLMs. Our codebase and dataset is available at: https://github.com/Jivnesh/PHISH
Vision-Aided Online A* Path Planning for Efficient and Safe Navigation of Service Robots
Nov 10, 2025The deployment of autonomous service robots in human-centric environments is hindered by a critical gap in perception and planning. Traditional navigation systems rely on expensive LiDARs that, while geometrically precise, are semantically unaware, they cannot distinguish a important document on an office floor from a harmless piece of litter, treating both as physically traversable. While advanced semantic segmentation exists, no prior work has successfully integrated this visual intelligence into a real-time path planner that is efficient enough for low-cost, embedded hardware. This paper presents a framework to bridge this gap, delivering context-aware navigation on an affordable robotic platform. Our approach centers on a novel, tight integration of a lightweight perception module with an online A* planner. The perception system employs a semantic segmentation model to identify user-defined visual constraints, enabling the robot to navigate based on contextual importance rather than physical size alone. This adaptability allows an operator to define what is critical for a given task, be it sensitive papers in an office or safety lines in a factory, thus resolving the ambiguity of what to avoid. This semantic perception is seamlessly fused with geometric data. The identified visual constraints are projected as non-geometric obstacles onto a global map that is continuously updated from sensor data, enabling robust navigation through both partially known and unknown environments. We validate our framework through extensive experiments in high-fidelity simulations and on a real-world robotic platform. The results demonstrate robust, real-time performance, proving that a cost-effective robot can safely navigate complex environments while respecting critical visual cues invisible to traditional planners.
Bin-picking of novel objects through category-agnostic-segmentation: RGB matters
Dec 27, 2023



This paper addresses category-agnostic instance segmentation for robotic manipulation, focusing on segmenting objects independent of their class to enable versatile applications like bin-picking in dynamic environments. Existing methods often lack generalizability and object-specific information, leading to grasp failures. We present a novel approach leveraging object-centric instance segmentation and simulation-based training for effective transfer to real-world scenarios. Notably, our strategy overcomes challenges posed by noisy depth sensors, enhancing the reliability of learning. Our solution accommodates transparent and semi-transparent objects which are historically difficult for depth-based grasping methods. Contributions include domain randomization for successful transfer, our collected dataset for warehouse applications, and an integrated framework for efficient bin-picking. Our trained instance segmentation model achieves state-of-the-art performance over WISDOM public benchmark [1] and also over the custom-created dataset. In a real-world challenging bin-picking setup our bin-picking framework method achieves 98% accuracy for opaque objects and 97% accuracy for non-opaque objects, outperforming the state-of-the-art baselines with a greater margin.
Aesthetics of Sanskrit Poetry from the Perspective of Computational Linguistics: A Case Study Analysis on Siksastaka
Aug 14, 2023


Sanskrit poetry has played a significant role in shaping the literary and cultural landscape of the Indian subcontinent for centuries. However, not much attention has been devoted to uncovering the hidden beauty of Sanskrit poetry in computational linguistics. This article explores the intersection of Sanskrit poetry and computational linguistics by proposing a roadmap of an interpretable framework to analyze and classify the qualities and characteristics of fine Sanskrit poetry. We discuss the rich tradition of Sanskrit poetry and the significance of computational linguistics in automatically identifying the characteristics of fine poetry. The proposed framework involves a human-in-the-loop approach that combines deterministic aspects delegated to machines and deep semantics left to human experts. We provide a deep analysis of Siksastaka, a Sanskrit poem, from the perspective of 6 prominent kavyashastra schools, to illustrate the proposed framework. Additionally, we provide compound, dependency, anvaya (prose order linearised form), meter, rasa (mood), alankar (figure of speech), and riti (writing style) annotations for Siksastaka and a web application to illustrate the poem's analysis and annotations. Our key contributions include the proposed framework, the analysis of Siksastaka, the annotations and the web application for future research. Link for interactive analysis: https://sanskritshala.github.io/shikshastakam/
Audio Bank: A High-Level Acoustic Signal Representation for Audio Event Recognition
Apr 11, 2023



Automatic audio event recognition plays a pivotal role in making human robot interaction more closer and has a wide applicability in industrial automation, control and surveillance systems. Audio event is composed of intricate phonic patterns which are harmonically entangled. Audio recognition is dominated by low and mid-level features, which have demonstrated their recognition capability but they have high computational cost and low semantic meaning. In this paper, we propose a new computationally efficient framework for audio recognition. Audio Bank, a new high-level representation of audio, is comprised of distinctive audio detectors representing each audio class in frequency-temporal space. Dimensionality of the resulting feature vector is reduced using non-negative matrix factorization preserving its discriminability and rich semantic information. The high audio recognition performance using several classifiers (SVM, neural network, Gaussian process classification and k-nearest neighbors) shows the effectiveness of the proposed method.
SanskritShala: A Neural Sanskrit NLP Toolkit with Web-Based Interface for Pedagogical and Annotation Purposes
Feb 19, 2023



We present a neural Sanskrit Natural Language Processing (NLP) toolkit named SanskritShala (a school of Sanskrit) to facilitate computational linguistic analyses for several tasks such as word segmentation, morphological tagging, dependency parsing, and compound type identification. Our systems currently report state-of-the-art performance on available benchmark datasets for all tasks. SanskritShala is deployed as a web-based application, which allows a user to get real-time analysis for the given input. It is built with easy-to-use interactive data annotation features that allow annotators to correct the system predictions when it makes mistakes. We publicly release the source codes of the 4 modules included in the toolkit, 7 word embedding models that have been trained on publicly available Sanskrit corpora and multiple annotated datasets such as word similarity, relatedness, categorization, analogy prediction to assess intrinsic properties of word embeddings. So far as we know, this is the first neural-based Sanskrit NLP toolkit that has a web-based interface and a number of NLP modules. We are sure that the people who are willing to work with Sanskrit will find it useful for pedagogical and annotative purposes. SanskritShala is available at: https://cnerg.iitkgp.ac.in/sanskritshala. The demo video of our platform can be accessed at: https://youtu.be/x0X31Y9k0mw4.
A Novel Multi-Task Learning Approach for Context-Sensitive Compound Type Identification in Sanskrit
Aug 22, 2022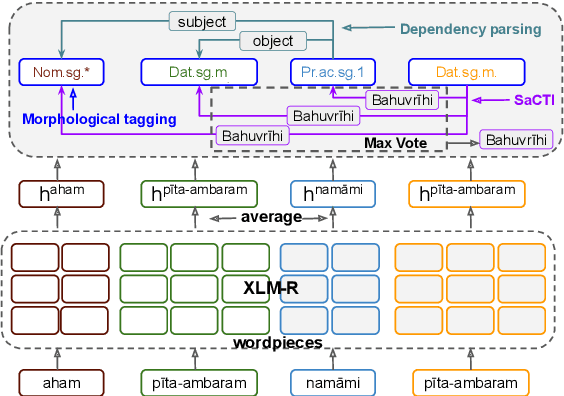
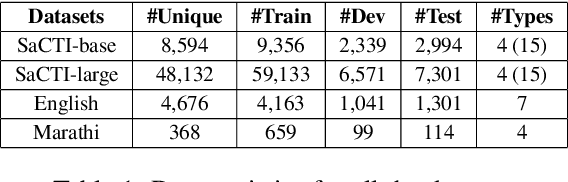
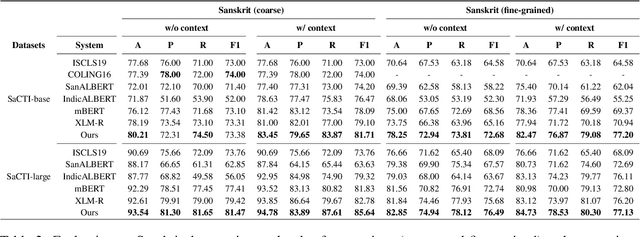
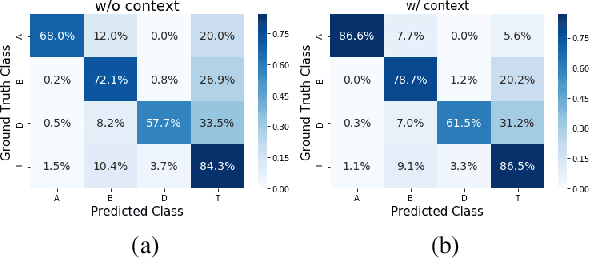
The phenomenon of compounding is ubiquitous in Sanskrit. It serves for achieving brevity in expressing thoughts, while simultaneously enriching the lexical and structural formation of the language. In this work, we focus on the Sanskrit Compound Type Identification (SaCTI) task, where we consider the problem of identifying semantic relations between the components of a compound word. Earlier approaches solely rely on the lexical information obtained from the components and ignore the most crucial contextual and syntactic information useful for SaCTI. However, the SaCTI task is challenging primarily due to the implicitly encoded context-sensitive semantic relation between the compound components. Thus, we propose a novel multi-task learning architecture which incorporates the contextual information and enriches the complementary syntactic information using morphological tagging and dependency parsing as two auxiliary tasks. Experiments on the benchmark datasets for SaCTI show 6.1 points (Accuracy) and 7.7 points (F1-score) absolute gain compared to the state-of-the-art system. Further, our multi-lingual experiments demonstrate the efficacy of the proposed architecture in English and Marathi languages.The code and datasets are publicly available at https://github.com/ashishgupta2598/SaCTI