 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Variational Causal Inference
Sep 13, 2022
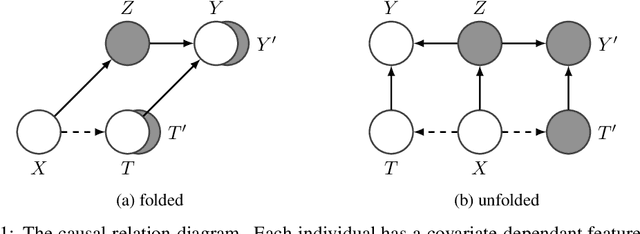
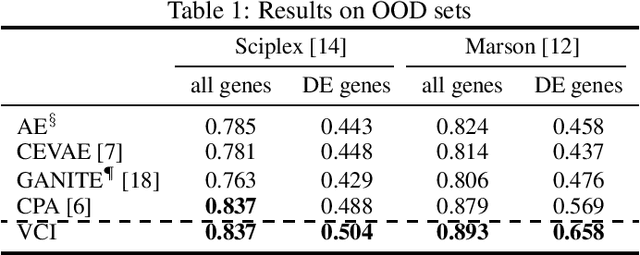
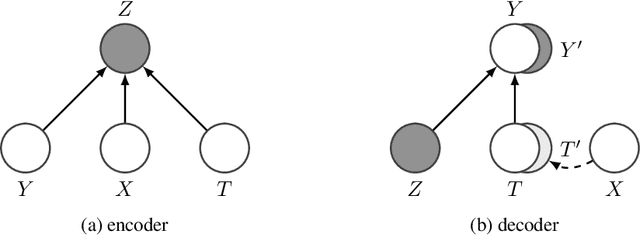
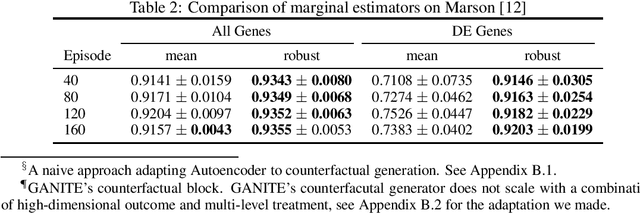
Estimating an individual's potential outcomes under counterfactual treatments is a challenging task for traditional causal inference and supervised learning approaches when the outcome is high-dimensional (e.g. gene expressions, impulse responses, human faces) and covariates are relatively limited. In this case, to construct one's outcome under a counterfactual treatment, it is crucial to leverage individual information contained in its observed factual outcome on top of the covariates. We propose a deep variational Bayesian framework that rigorously integrates two main sources of information for outcome construction under a counterfactual treatment: one source is the individual features embedded in the high-dimensional factual outcome; the other source is the response distribution of similar subjects (subjects with the same covariates) that factually received this treatment of interest.
GRAPHYP: A Scientific Knowledge Graph with Manifold Subnetworks of Communities. Detection of Scholarly Disputes in Adversarial Information Routes
May 03, 2022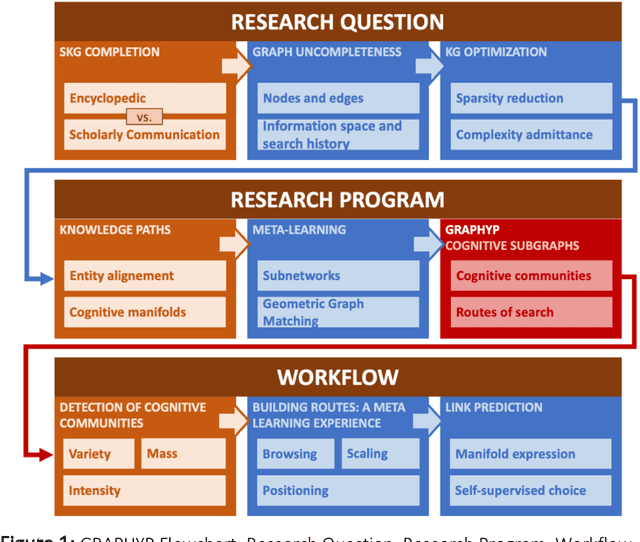

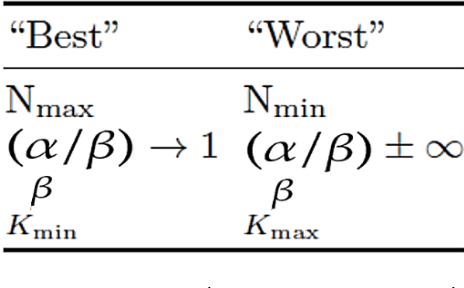
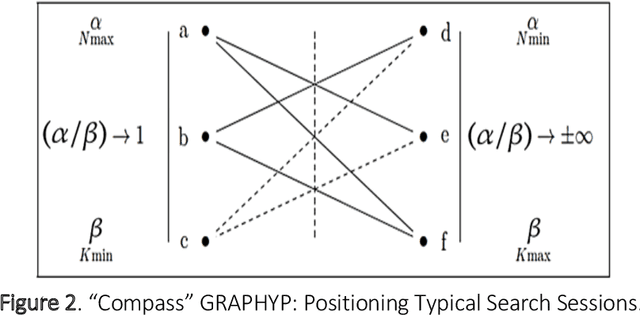
The cognitive manifold of published content is currently expanding in all areas of science. However, Scientific Knowledge Graphs (SKGs) only provide poor pictures of the adversarial directions and scientific controversies that feed the production of knowledge. In this Article, we tackle the understanding of the design of the information space of a cognitive representation of research activities, and of related bottlenecks that affect search interfaces, in the mapping of structured objects into graphs. We propose, with SKG GRAPHYP, a novel graph designed geometric architecture which optimizes both the detection of the knowledge manifold of "cognitive communities", and the representation of alternative paths to adversarial answers to a research question, for instance in the context of academic disputes. With a methodology for designing "Manifold Subnetworks of Cognitive Communities", GRAPHYP provides a classification of distinct search paths in a research field. Users are detected from the variety of their search practices and classified in "Cognitive communities" from the analysis of the search history of their logs of scientific documentation. The manifold of practices is expressed from metrics of differentiated uses by triplets of nodes shaped into symmetrical graph subnetworks, with the following three parameters: Mass, Intensity, and Variety.
MGTR: End-to-End Mutual Gaze Detection with Transformer
Sep 22, 2022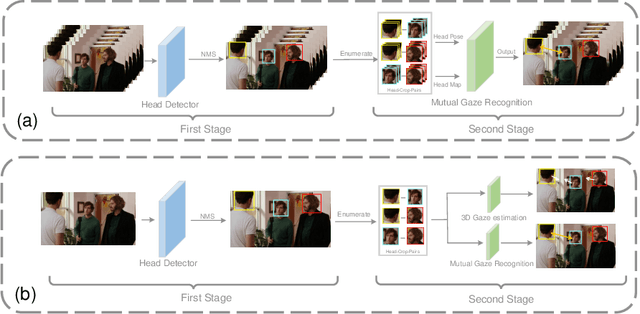
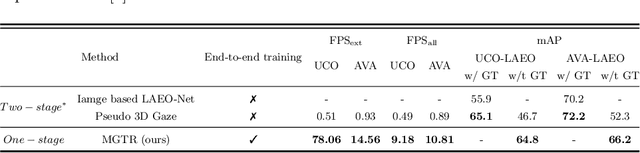
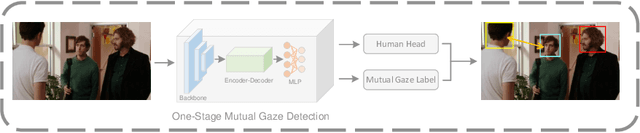
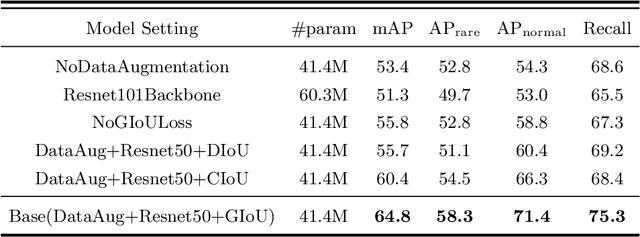
People's looking at each other or mutual gaze is ubiquitous in our daily interactions, and detecting mutual gaze is of great significance for understanding human social scenes. Current mutual gaze detection methods focus on two-stage methods, whose inference speed is limited by the two-stage pipeline and the performance in the second stage is affected by the first one. In this paper, we propose a novel one-stage mutual gaze detection framework called Mutual Gaze TRansformer or MGTR to perform mutual gaze detection in an end-to-end manner. By designing mutual gaze instance triples, MGTR can detect each human head bounding box and simultaneously infer mutual gaze relationship based on global image information, which streamlines the whole process with simplicity. Experimental results on two mutual gaze datasets show that our method is able to accelerate mutual gaze detection process without losing performance. Ablation study shows that different components of MGTR can capture different levels of semantic information in images. Code is available at https://github.com/Gmbition/MGTR
Solving Reasoning Tasks with a Slot Transformer
Oct 20, 2022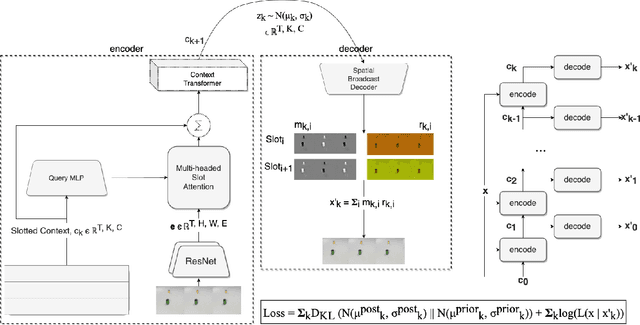
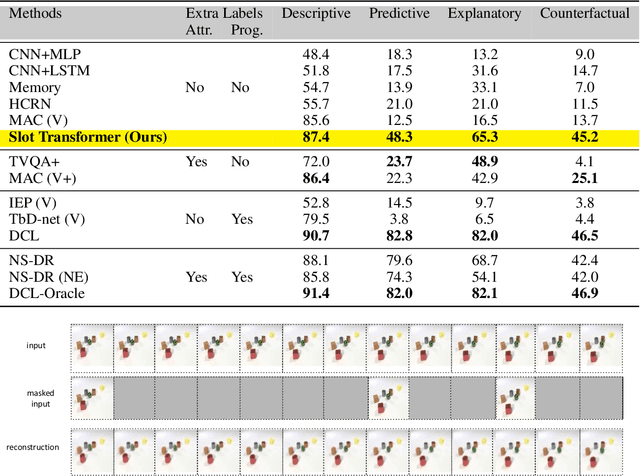
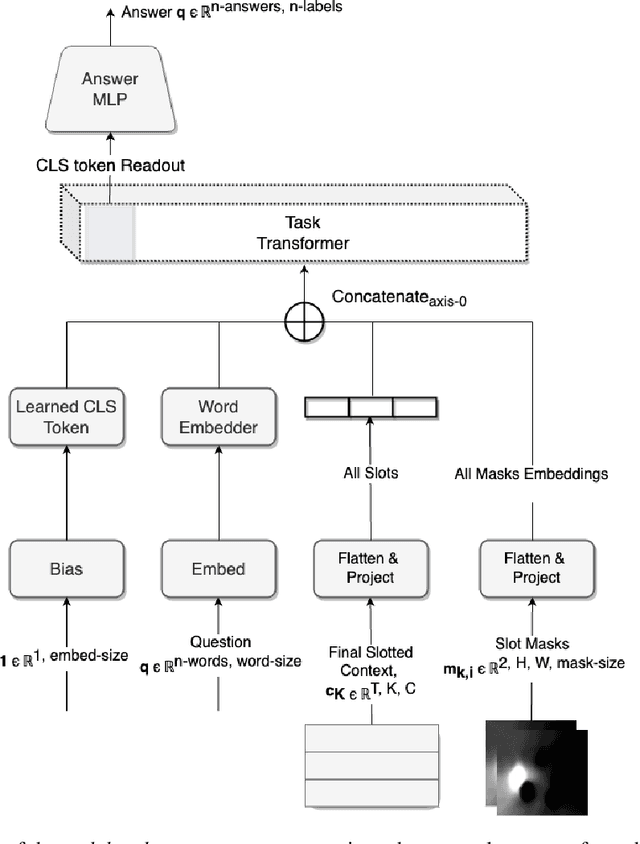
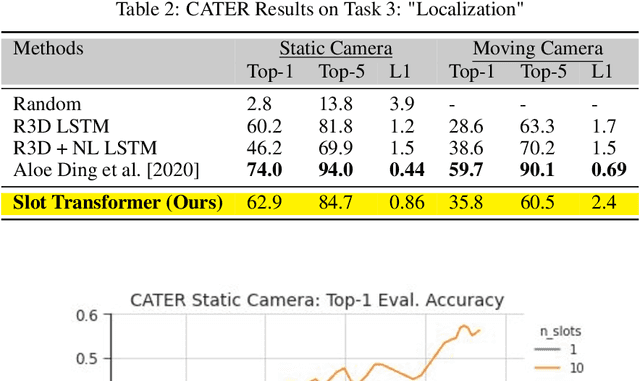
The ability to carve the world into useful abstractions in order to reason about time and space is a crucial component of intelligence. In order to successfully perceive and act effectively using senses we must parse and compress large amounts of information for further downstream reasoning to take place, allowing increasingly complex concepts to emerge. If there is any hope to scale representation learning methods to work with real world scenes and temporal dynamics then there must be a way to learn accurate, concise, and composable abstractions across time. We present the Slot Transformer, an architecture that leverages slot attention, transformers and iterative variational inference on video scene data to infer such representations. We evaluate the Slot Transformer on CLEVRER, Kinetics-600 and CATER datesets and demonstrate that the approach allows us to develop robust modeling and reasoning around complex behaviours as well as scores on these datasets that compare favourably to existing baselines. Finally we evaluate the effectiveness of key components of the architecture, the model's representational capacity and its ability to predict from incomplete input.
MCTNet: A Multi-Scale CNN-Transformer Network for Change Detection in Optical Remote Sensing Images
Oct 14, 2022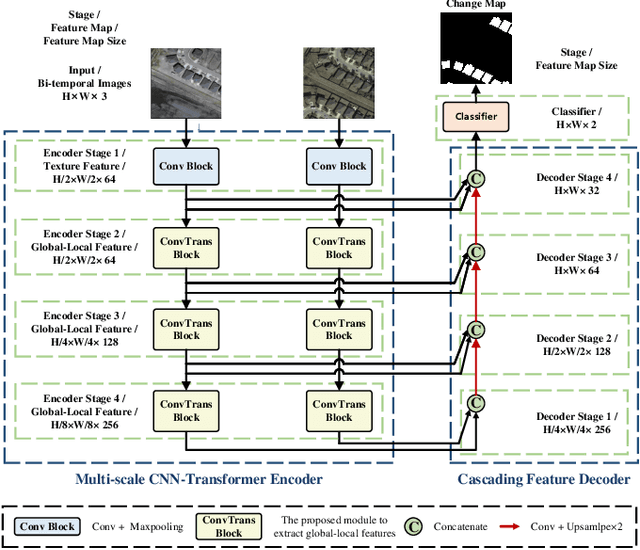
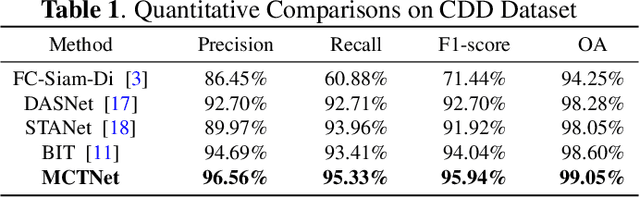
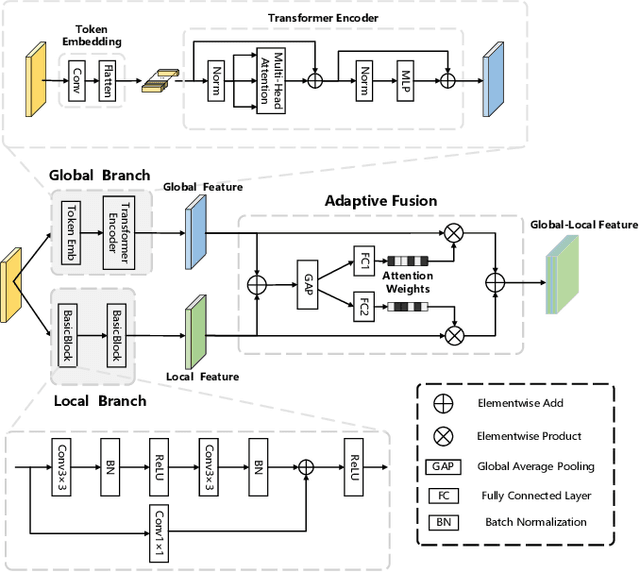
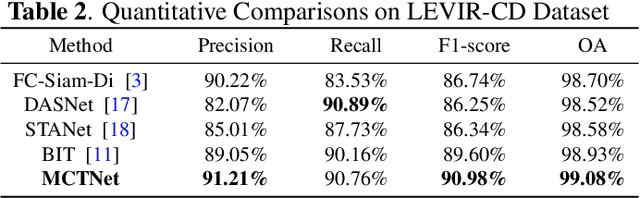
For the task of change detection (CD) in remote sensing images, deep convolution neural networks (CNNs)-based methods have recently aggregated transformer modules to improve the capability of global feature extraction. However, they suffer degraded CD performance on small changed areas due to the simple single-scale integration of deep CNNs and transformer modules. To address this issue, we propose a hybrid network based on multi-scale CNN-transformer structure, termed MCTNet, where the multi-scale global and local information are exploited to enhance the robustness of the CD performance on changed areas with different sizes. Especially, we design the ConvTrans block to adaptively aggregate global features from transformer modules and local features from CNN layers, which provides abundant global-local features with different scales. Experimental results demonstrate that our MCTNet achieves better detection performance than existing state-of-the-art CD methods.
Deep Learning based Super-Resolution for Medical Volume Visualization with Direct Volume Rendering
Oct 14, 2022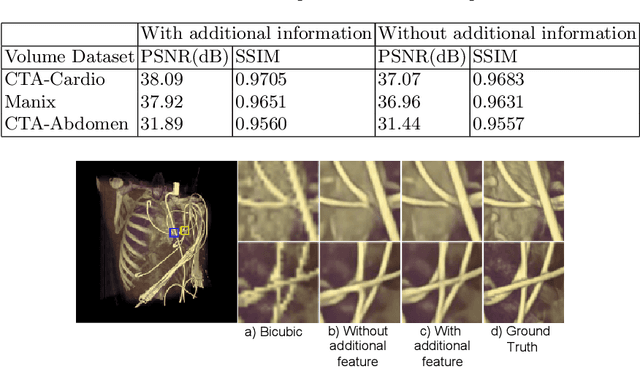
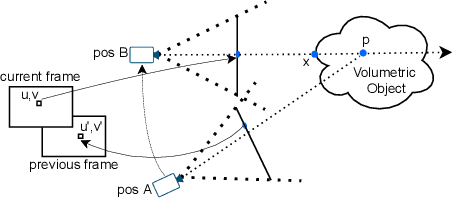


Modern-day display systems demand high-quality rendering. However, rendering at higher resolution requires a large number of data samples and is computationally expensive. Recent advances in deep learning-based image and video super-resolution techniques motivate us to investigate such networks for high-fidelity upscaling of frames rendered at a lower resolution to a higher resolution. While our work focuses on super-resolution of medical volume visualization performed with direct volume rendering, it is also applicable for volume visualization with other rendering techniques. We propose a learning-based technique where our proposed system uses color information along with other supplementary features gathered from our volume renderer to learn efficient upscaling of a low-resolution rendering to a higher-resolution space. Furthermore, to improve temporal stability, we also implement the temporal reprojection technique for accumulating history samples in volumetric rendering.
A Kernel Approach for PDE Discovery and Operator Learning
Oct 14, 2022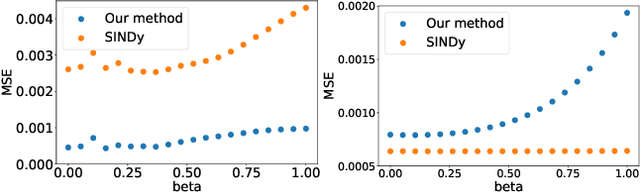
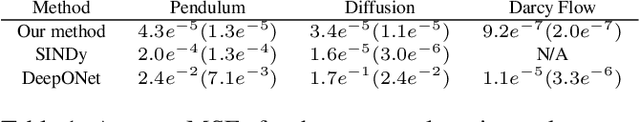
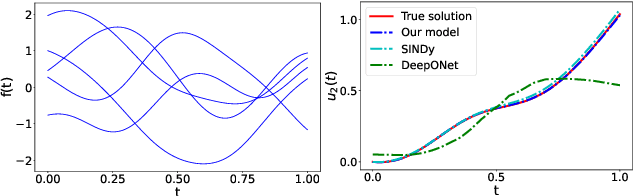
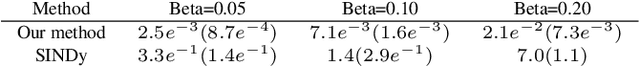
This article presents a three-step framework for learning and solving partial differential equations (PDEs) using kernel methods. Given a training set consisting of pairs of noisy PDE solutions and source/boundary terms on a mesh, kernel smoothing is utilized to denoise the data and approximate derivatives of the solution. This information is then used in a kernel regression model to learn the algebraic form of the PDE. The learned PDE is then used within a kernel based solver to approximate the solution of the PDE with a new source/boundary term, thereby constituting an operator learning framework. The proposed method is mathematically interpretable and amenable to analysis, and convenient to implement. Numerical experiments compare the method to state-of-the-art algorithms and demonstrate its superior performance on small amounts of training data and for PDEs with spatially variable coefficients.
Keypoint Cascade Voting for Point Cloud Based 6DoF Pose Estimation
Oct 14, 2022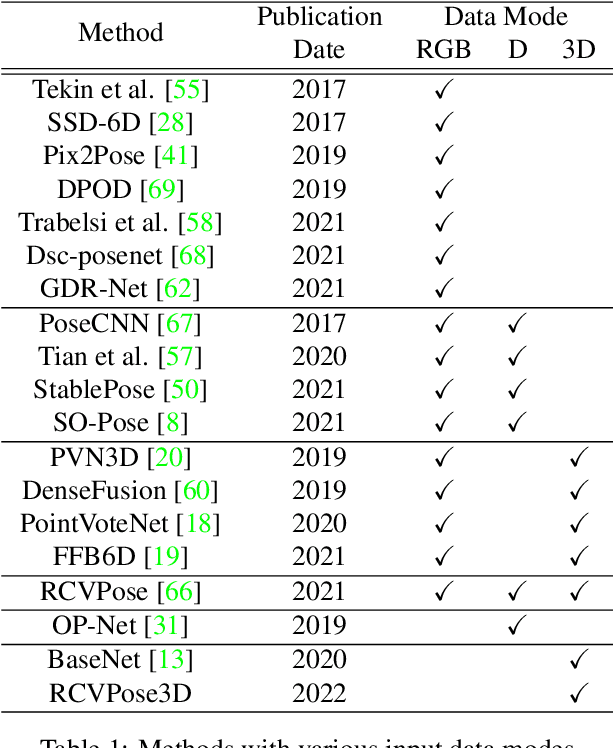
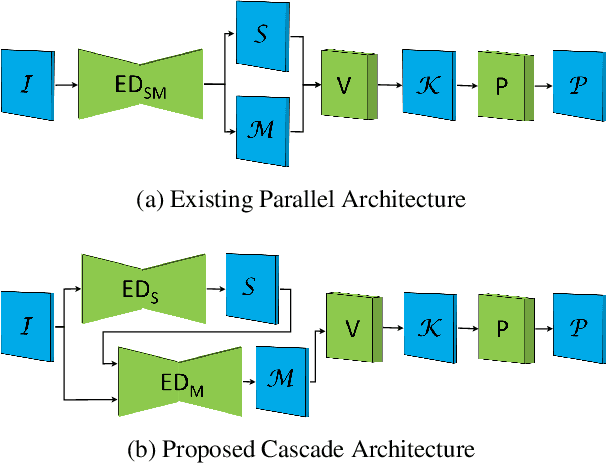
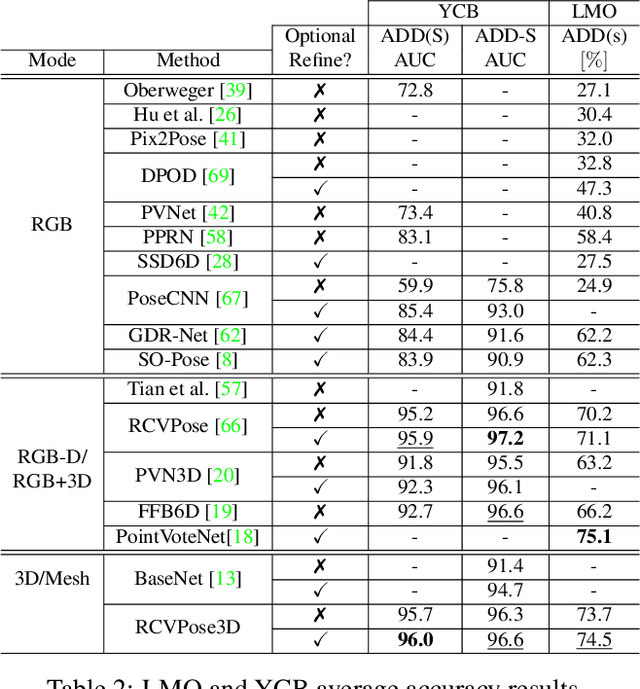
We propose a novel keypoint voting 6DoF object pose estimation method, which takes pure unordered point cloud geometry as input without RGB information. The proposed cascaded keypoint voting method, called RCVPose3D, is based upon a novel architecture which separates the task of semantic segmentation from that of keypoint regression, thereby increasing the effectiveness of both and improving the ultimate performance. The method also introduces a pairwise constraint in between different keypoints to the loss function when regressing the quantity for keypoint estimation, which is shown to be effective, as well as a novel Voter Confident Score which enhances both the learning and inference stages. Our proposed RCVPose3D achieves state-of-the-art performance on the Occlusion LINEMOD (74.5%) and YCB-Video (96.9%) datasets, outperforming existing pure RGB and RGB-D based methods, as well as being competitive with RGB plus point cloud methods.
Dense-TNT: Efficient Vehicle Type Classification Neural Network Using Satellite Imagery
Sep 27, 2022
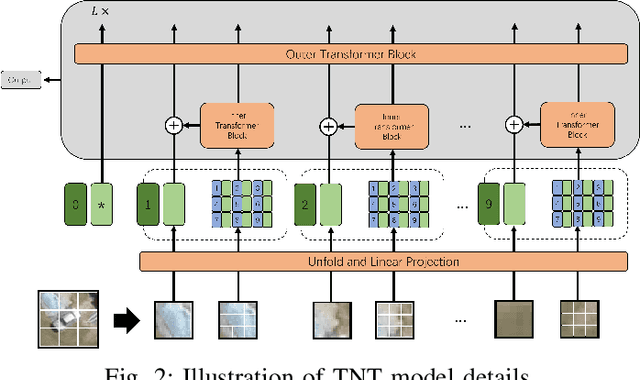
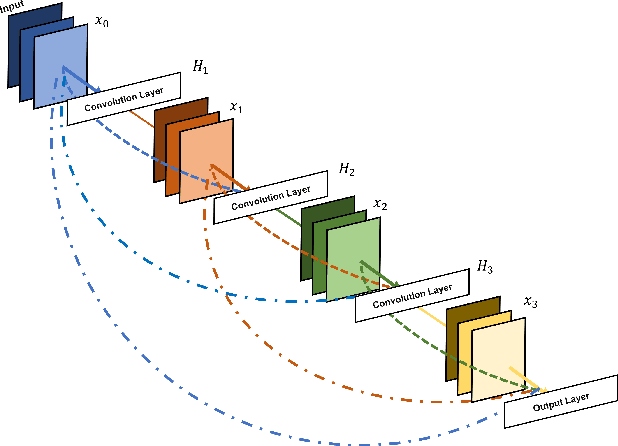
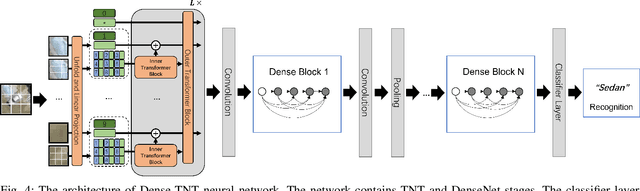
Accurate vehicle type classification serves a significant role in the intelligent transportation system. It is critical for ruler to understand the road conditions and usually contributive for the traffic light control system to response correspondingly to alleviate traffic congestion. New technologies and comprehensive data sources, such as aerial photos and remote sensing data, provide richer and high-dimensional information. Also, due to the rapid development of deep neural network technology, image based vehicle classification methods can better extract underlying objective features when processing data. Recently, several deep learning models have been proposed to solve the problem. However, traditional pure convolutional based approaches have constraints on global information extraction, and the complex environment, such as bad weather, seriously limits the recognition capability. To improve the vehicle type classification capability under complex environment, this study proposes a novel Densely Connected Convolutional Transformer in Transformer Neural Network (Dense-TNT) framework for the vehicle type classification by stacking Densely Connected Convolutional Network (DenseNet) and Transformer in Transformer (TNT) layers. Three-region vehicle data and four different weather conditions are deployed for recognition capability evaluation. Experimental findings validate the recognition ability of our proposed vehicle classification model with little decay, even under the heavy foggy weather condition.
Enforcing the consensus between Trajectory Optimization and Policy Learning for precise robot control
Sep 19, 2022
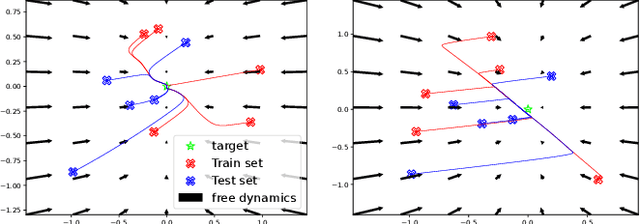
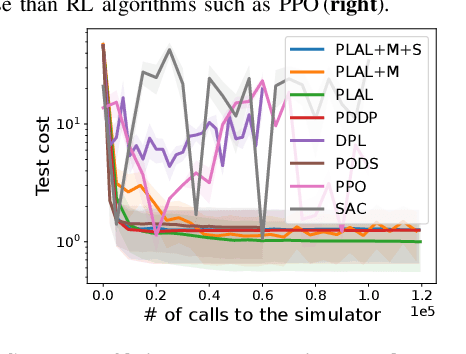
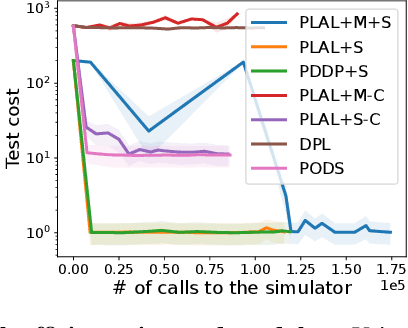
Reinforcement learning (RL) and trajectory optimization (TO) present strong complementary advantages. On one hand, RL approaches are able to learn global control policies directly from data, but generally require large sample sizes to properly converge towards feasible policies. On the other hand, TO methods are able to exploit gradient-based information extracted from simulators to quickly converge towards a locally optimal control trajectory which is only valid within the vicinity of the solution. Over the past decade, several approaches have aimed to adequately combine the two classes of methods in order to obtain the best of both worlds. Following on from this line of research, we propose several improvements on top of these approaches to learn global control policies quicker, notably by leveraging sensitivity information stemming from TO methods via Sobolev learning, and augmented Lagrangian techniques to enforce the consensus between TO and policy learning. We evaluate the benefits of these improvements on various classical tasks in robotics through comparison with existing approaches in the literature.