 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Physics-informed Diffusion Model for High-fidelity Flow Field Reconstruction
Nov 26, 2022
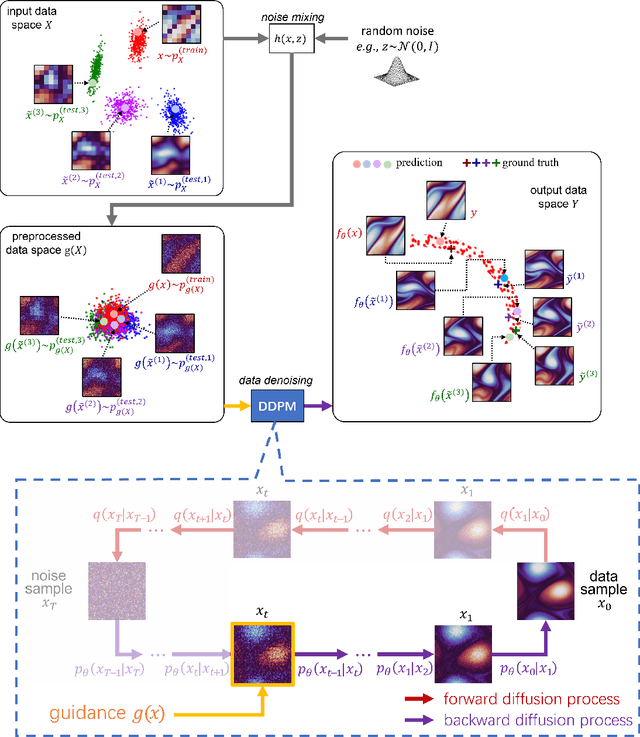

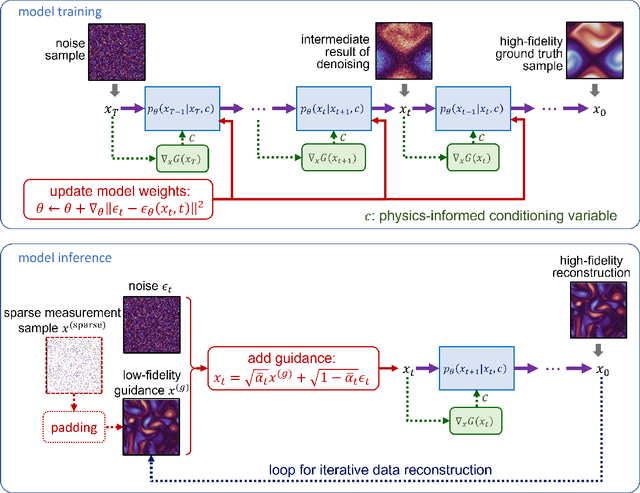
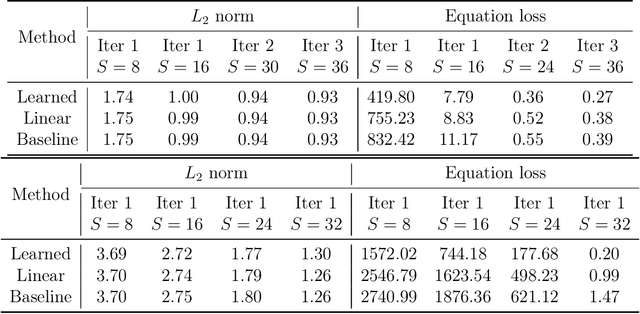
Machine learning models are gaining increasing popularity in the domain of fluid dynamics for their potential to accelerate the production of high-fidelity computational fluid dynamics data. However, many recently proposed machine learning models for high-fidelity data reconstruction require low-fidelity data for model training. Such requirement restrains the application performance of these models, since their data reconstruction accuracy would drop significantly if the low-fidelity input data used in model test has a large deviation from the training data. To overcome this restraint, we propose a diffusion model which only uses high-fidelity data at training. With different configurations, our model is able to reconstruct high-fidelity data from either a regular low-fidelity sample or a sparsely measured sample, and is also able to gain an accuracy increase by using physics-informed conditioning information from a known partial differential equation when that is available. Experimental results demonstrate that our model can produce accurate reconstruction results for 2d turbulent flows based on different input sources without retraining.
OLIA: an open-source digital lock-in amplifier
Nov 22, 2022
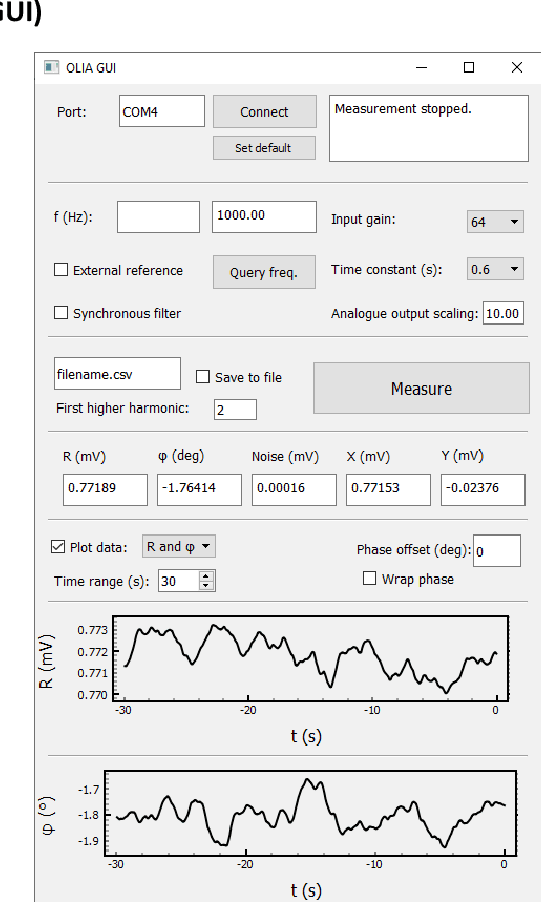
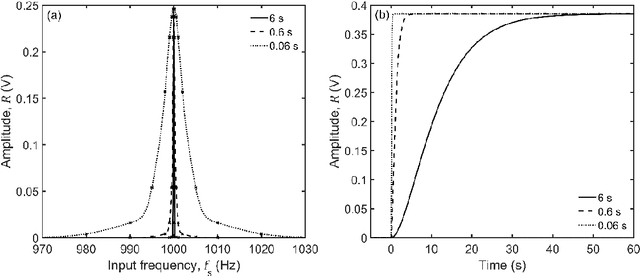
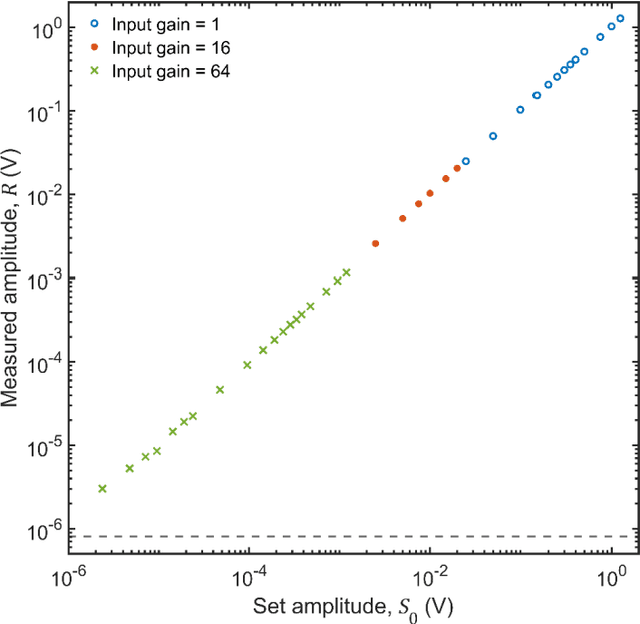
The Open Lock-In Amplifier (OLIA) is a microcontroller-based digital lock-in amplifier built from a small number of inexpensive and easily sourced electronic components. Despite its small credit card-sized form-factor and low build-cost of around US$35, OLIA is a capable instrument that offers many features associated with far costlier commercial devices. Key features include dual-phase lock-in detection at multiple harmonic frequencies up to 50 kHz, internal and external reference modes, adjustable levels of input gain, a choice between low-pass filtering and synchronous filtering, noise estimation, and a comprehensive programming interface for remote software control. OLIA comes with an optional optical breakout board that allows noise-tolerant optical detection down to the 40 pW level. OLIA and its breakout board are released here as open hardware, with technical diagrams, full parts-lists, and source-code for the firmware provided as Supporting Information.
AERO: Audio Super Resolution in the Spectral Domain
Nov 22, 2022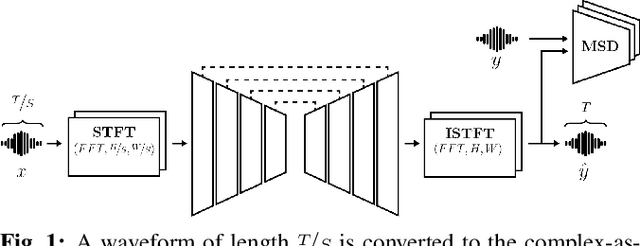
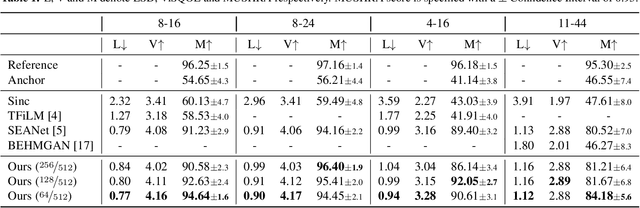
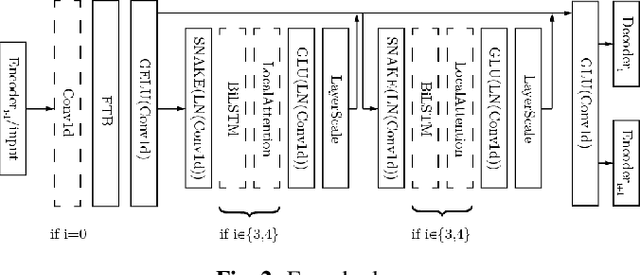
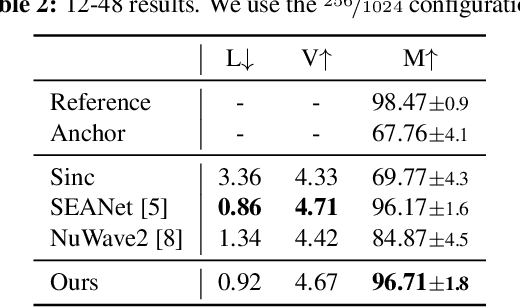
We present AERO, a audio super-resolution model that processes speech and music signals in the spectral domain. AERO is based on an encoder-decoder architecture with U-Net like skip connections. We optimize the model using both time and frequency domain loss functions. Specifically, we consider a set of reconstruction losses together with perceptual ones in the form of adversarial and feature discriminator loss functions. To better handle phase information the proposed method operates over the complex-valued spectrogram using two separate channels. Unlike prior work which mainly considers low and high frequency concatenation for audio super-resolution, the proposed method directly predicts the full frequency range. We demonstrate high performance across a wide range of sample rates considering both speech and music. AERO outperforms the evaluated baselines considering Log-Spectral Distance, ViSQOL, and the subjective MUSHRA test. Audio samples and code are available at https://pages.cs.huji.ac.il/adiyoss-lab/aero
Domain Alignment and Temporal Aggregation for Unsupervised Video Object Segmentation
Nov 22, 2022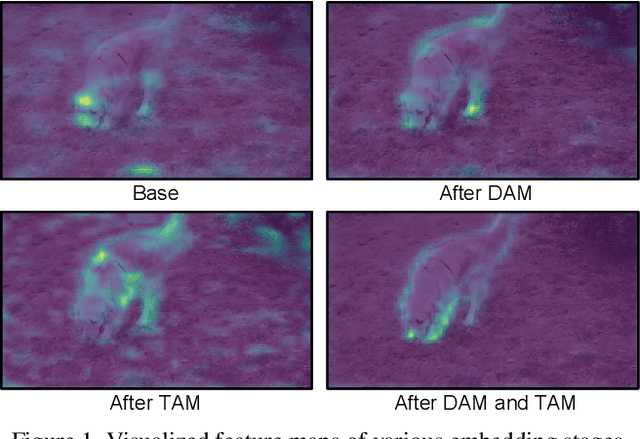
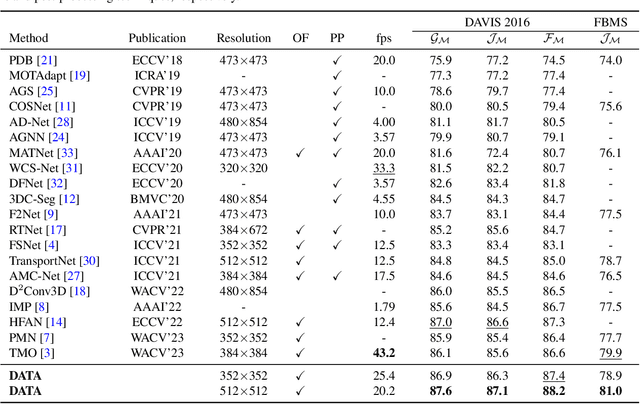
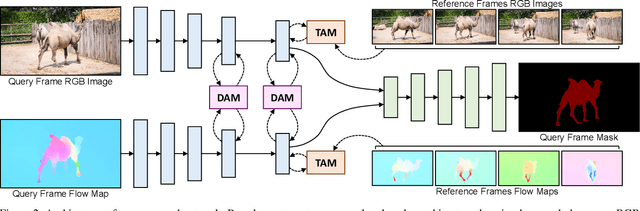
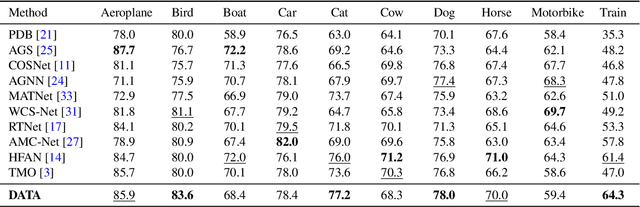
Unsupervised video object segmentation aims at detecting and segmenting the most salient object in videos. In recent times, two-stream approaches that collaboratively leverage appearance cues and motion cues have attracted extensive attention thanks to their powerful performance. However, there are two limitations faced by those methods: 1) the domain gap between appearance and motion information is not well considered; and 2) long-term temporal coherence within a video sequence is not exploited. To overcome these limitations, we propose a domain alignment module (DAM) and a temporal aggregation module (TAM). DAM resolves the domain gap between two modalities by forcing the values to be in the same range using a cross-correlation mechanism. TAM captures long-term coherence by extracting and leveraging global cues of a video. On public benchmark datasets, our proposed approach demonstrates its effectiveness, outperforming all existing methods by a substantial margin.
A Novel Autonomous Robotics System for Aquaculture Environment Monitoring
Nov 08, 2022
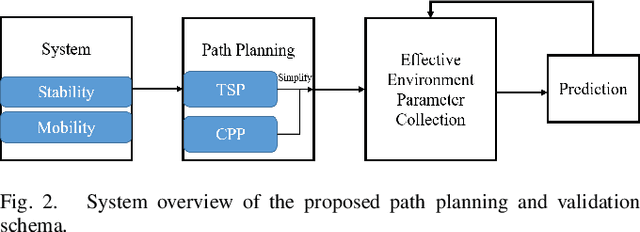
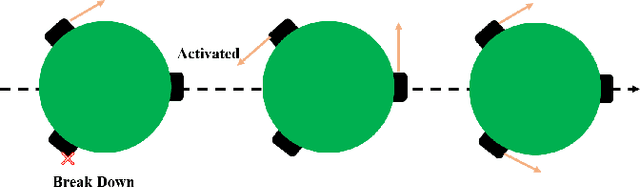
Implementing fully automatic unmanned surface vehicles (USVs) monitoring water quality is challenging since effectively collecting environmental data while keeping the platform stable and environmental-friendly is hard to approach. To address this problem, we construct a USV that can automatically navigate an efficient path to sample water quality parameters in order to monitor the aquatic environment. The detection device needs to be stable enough to resist a hostile environment or climates while enormous volumes will disturb the aquaculture environment. Meanwhile, planning an efficient path for information collecting needs to deal with the contradiction between the restriction of energy and the amount of information in the coverage region. To tackle with mentioned challenges, we provide a USV platform that can perfectly balance mobility, stability, and portability attributed to its special round-shape structure and redundancy motion design. For informative planning, we combined the TSP and CPP algorithms to construct an optimistic plan for collecting more data within a certain range and limiting energy restrictions.We designed a fish existence prediction scenario to verify the novel system in both simulation experiments and field experiments. The novel aquaculture environment monitoring system significantly reduces the burden of manual operation in the fishery inspection field. Additionally, the simplicity of the sensor setup and the minimal cost of the platform enables its other possible applications in aquatic exploration and commercial utilization.
Hierarchical3D Adapters for Long Video-to-text Summarization
Oct 10, 2022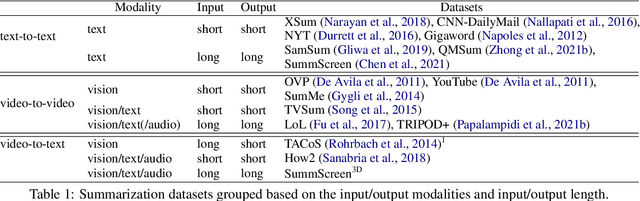
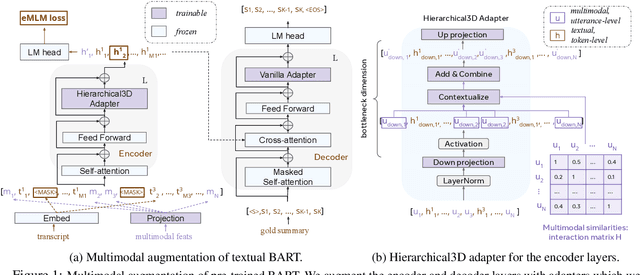
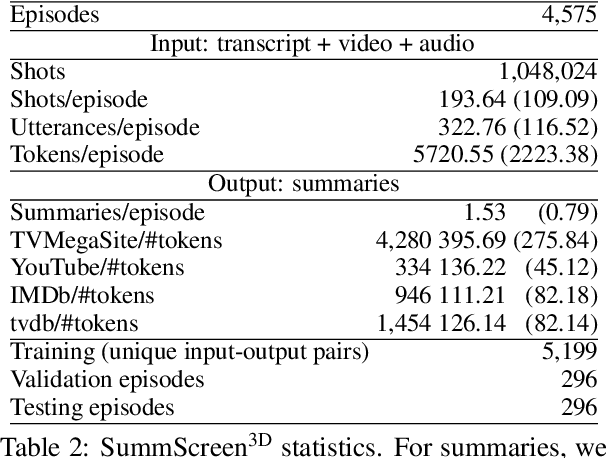
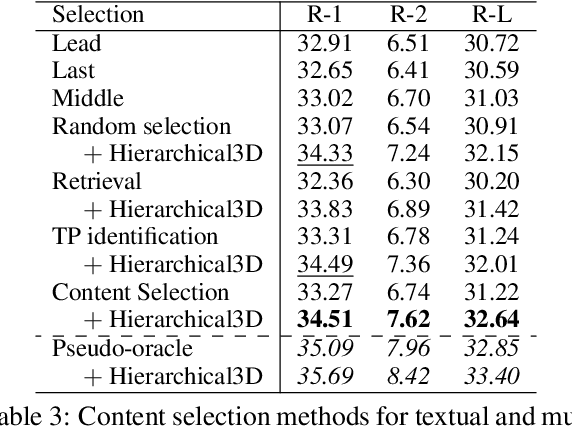
In this paper, we focus on video-to-text summarization and investigate how to best utilize multimodal information for summarizing long inputs (e.g., an hour-long TV show) into long outputs (e.g., a multi-sentence summary). We extend SummScreen (Chen et al., 2021), a dialogue summarization dataset consisting of transcripts of TV episodes with reference summaries, and create a multimodal variant by collecting corresponding full-length videos. We incorporate multimodal information into a pre-trained textual summarizer efficiently using adapter modules augmented with a hierarchical structure while tuning only 3.8\% of model parameters. Our experiments demonstrate that multimodal information offers superior performance over more memory-heavy and fully fine-tuned textual summarization methods.
Heterogeneous Graph Sparsification for Efficient Representation Learning
Nov 14, 2022
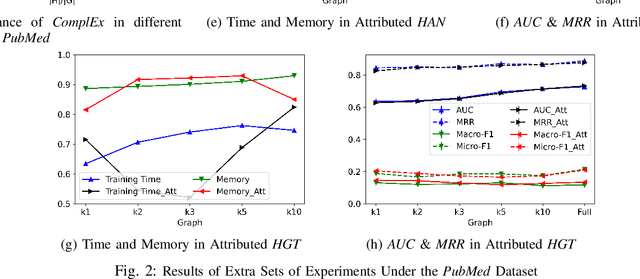
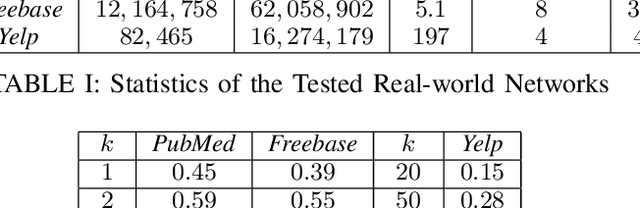
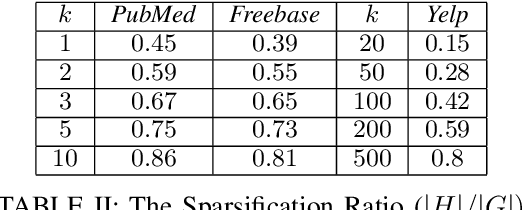
Graph sparsification is a powerful tool to approximate an arbitrary graph and has been used in machine learning over homogeneous graphs. In heterogeneous graphs such as knowledge graphs, however, sparsification has not been systematically exploited to improve efficiency of learning tasks. In this work, we initiate the study on heterogeneous graph sparsification and develop sampling-based algorithms for constructing sparsifiers that are provably sparse and preserve important information in the original graphs. We have performed extensive experiments to confirm that the proposed method can improve time and space complexities of representation learning while achieving comparable, or even better performance in subsequent graph learning tasks based on the learned embedding.
A deep learning framework to generate realistic population and mobility data
Nov 14, 2022
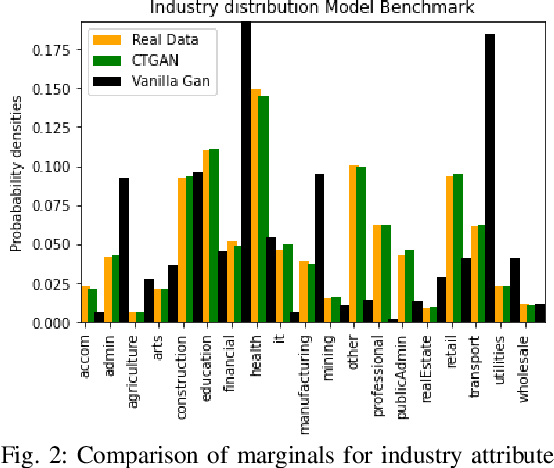
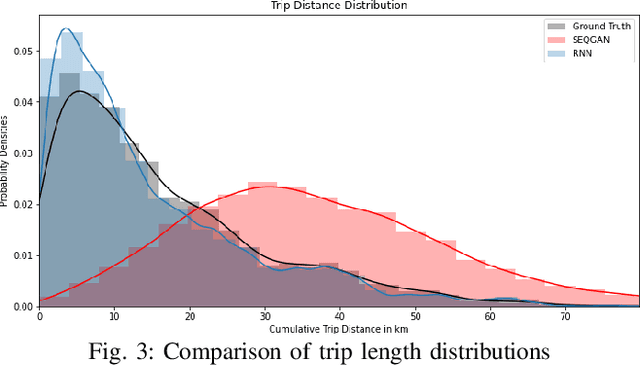
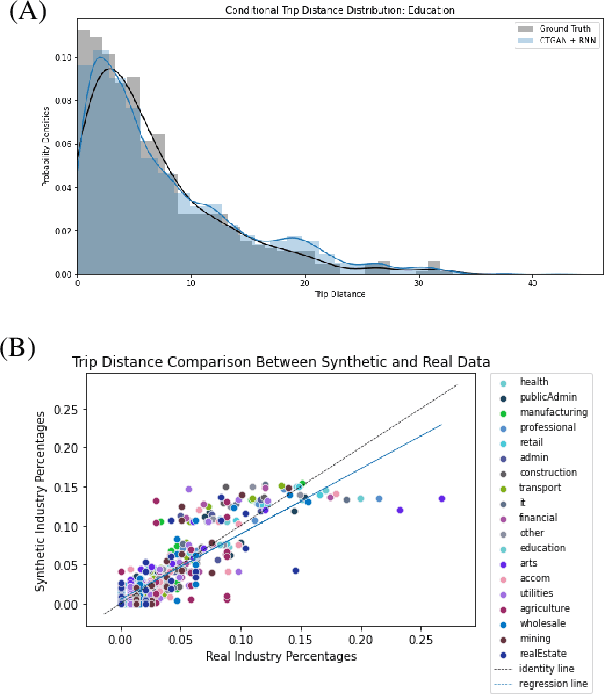
Census and Household Travel Survey datasets are regularly collected from households and individuals and provide information on their daily travel behavior with demographic and economic characteristics. These datasets have important applications ranging from travel demand estimation to agent-based modeling. However, they often represent a limited sample of the population due to privacy concerns or are given aggregated. Synthetic data augmentation is a promising avenue in addressing these challenges. In this paper, we propose a framework to generate a synthetic population that includes both socioeconomic features (e.g., age, sex, industry) and trip chains (i.e., activity locations). Our model is tested and compared with other recently proposed models on multiple assessment metrics.
Why Did the Chicken Cross the Road? Rephrasing and Analyzing Ambiguous Questions in VQA
Nov 14, 2022Resolving ambiguities in questions is key to successfully answering them. Focusing on questions about images, we create a dataset of ambiguous examples; we annotate these examples, grouping the answers by the underlying question they address and rephrasing the question for each group to reduce ambiguity. An analysis of our data reveals a linguistically-aligned ontology of reasons for ambiguity in visual questions. We then develop an English question-generation model which we demonstrate via automatic and human evaluation produces less ambiguous questions. We further show that the question generation objective we use allows the model to integrate answer group information without any direct supervision.
HP-GMN: Graph Memory Networks for Heterophilous Graphs
Oct 15, 2022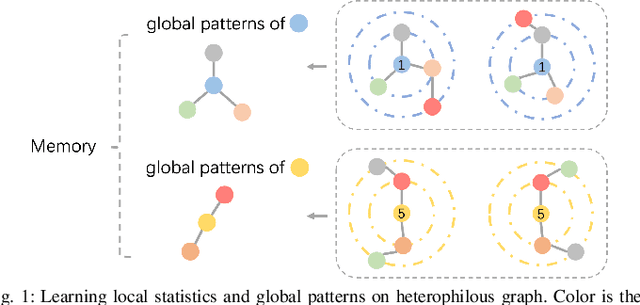
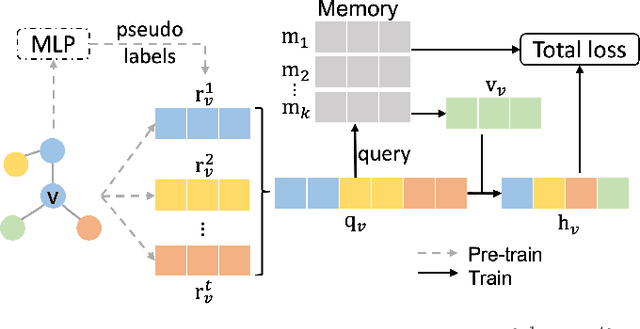
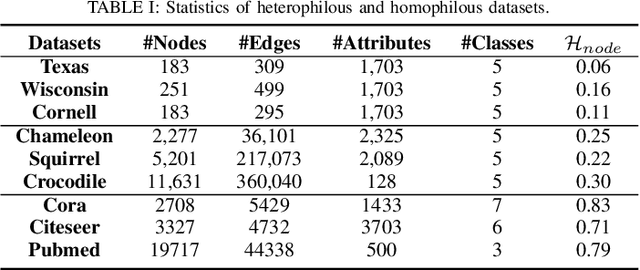
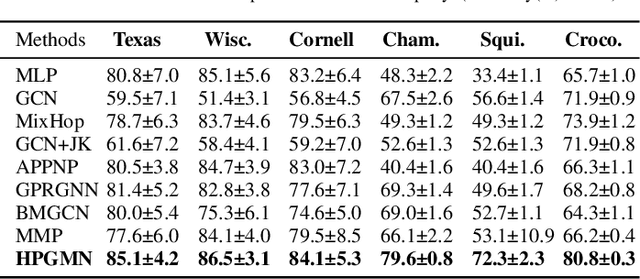
Graph neural networks (GNNs) have achieved great success in various graph problems. However, most GNNs are Message Passing Neural Networks (MPNNs) based on the homophily assumption, where nodes with the same label are connected in graphs. Real-world problems bring us heterophily problems, where nodes with different labels are connected in graphs. MPNNs fail to address the heterophily problem because they mix information from different distributions and are not good at capturing global patterns. Therefore, we investigate a novel Graph Memory Networks model on Heterophilous Graphs (HP-GMN) to the heterophily problem in this paper. In HP-GMN, local information and global patterns are learned by local statistics and the memory to facilitate the prediction. We further propose regularization terms to help the memory learn global information. We conduct extensive experiments to show that our method achieves state-of-the-art performance on both homophilous and heterophilous graphs.