 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Novel Deep Reinforcement Learning Based Automated Stock Trading System Using Cascaded LSTM Networks
Dec 06, 2022
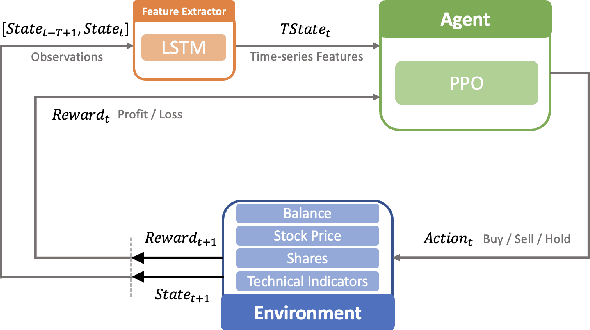
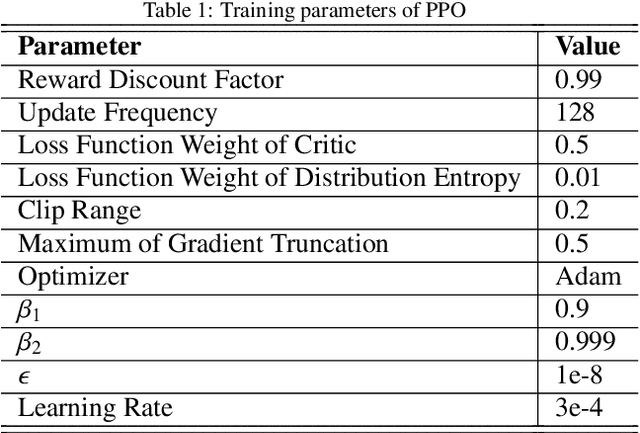
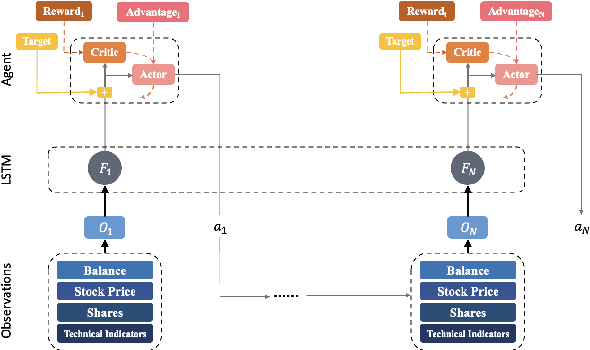

More and more stock trading strategies are constructed using deep reinforcement learning (DRL) algorithms, but DRL methods originally widely used in the gaming community are not directly adaptable to financial data with low signal-to-noise ratios and unevenness, and thus suffer from performance shortcomings. In this paper, to capture the hidden information, we propose a DRL based stock trading system using cascaded LSTM, which first uses LSTM to extract the time-series features from stock daily data, and then the features extracted are fed to the agent for training, while the strategy functions in reinforcement learning also use another LSTM for training. Experiments in DJI in the US market and SSE50 in the Chinese stock market show that our model outperforms previous baseline models in terms of cumulative returns and Sharp ratio, and this advantage is more significant in the Chinese stock market, a merging market. It indicates that our proposed method is a promising way to build a automated stock trading system.
Document-Level Abstractive Summarization
Dec 06, 2022
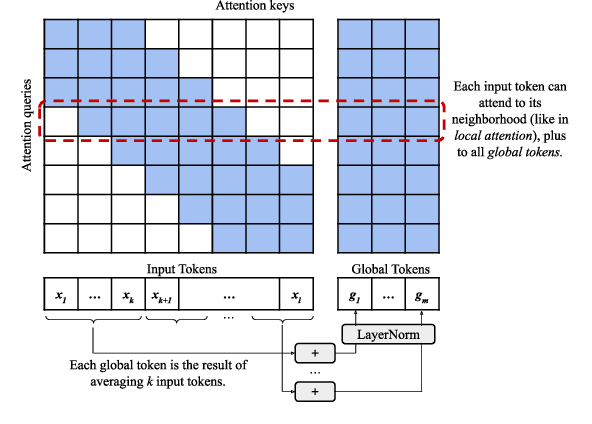
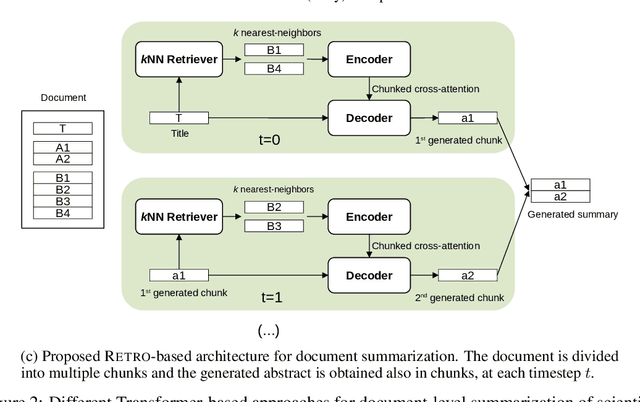

The task of automatic text summarization produces a concise and fluent text summary while preserving key information and overall meaning. Recent approaches to document-level summarization have seen significant improvements in recent years by using models based on the Transformer architecture. However, the quadratic memory and time complexities with respect to the sequence length make them very expensive to use, especially with long sequences, as required by document-level summarization. Our work addresses the problem of document-level summarization by studying how efficient Transformer techniques can be used to improve the automatic summarization of very long texts. In particular, we will use the arXiv dataset, consisting of several scientific papers and the corresponding abstracts, as baselines for this work. Then, we propose a novel retrieval-enhanced approach based on the architecture which reduces the cost of generating a summary of the entire document by processing smaller chunks. The results were below the baselines but suggest a more efficient memory a consumption and truthfulness.
DiSTRICT: Dialogue State Tracking with Retriever Driven In-Context Tuning
Dec 06, 2022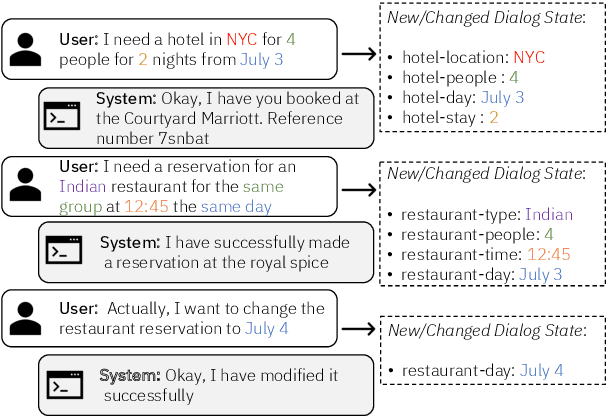
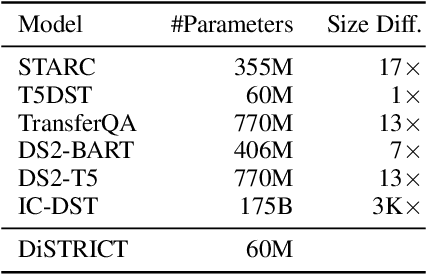
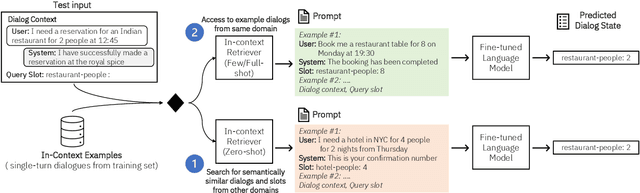
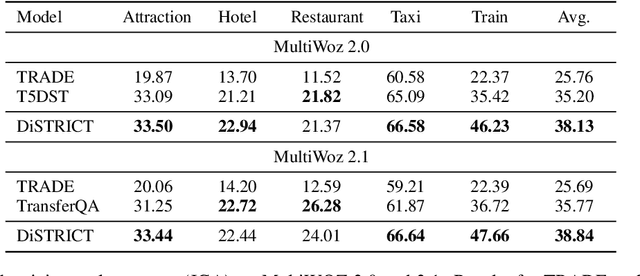
Dialogue State Tracking (DST), a key component of task-oriented conversation systems, represents user intentions by determining the values of pre-defined slots in an ongoing dialogue. Existing approaches use hand-crafted templates and additional slot information to fine-tune and prompt large pre-trained language models and elicit slot values from the dialogue context. Significant manual effort and domain knowledge is required to design effective prompts, limiting the generalizability of these approaches to new domains and tasks. In this work, we propose DiSTRICT, a generalizable in-context tuning approach for DST that retrieves highly relevant training examples for a given dialogue to fine-tune the model without any hand-crafted templates. Experiments with the MultiWOZ benchmark datasets show that DiSTRICT outperforms existing approaches in various zero-shot and few-shot settings using a much smaller model, thereby providing an important advantage for real-world deployments that often have limited resource availability.
Neural Machine Translation with Contrastive Translation Memories
Dec 06, 2022
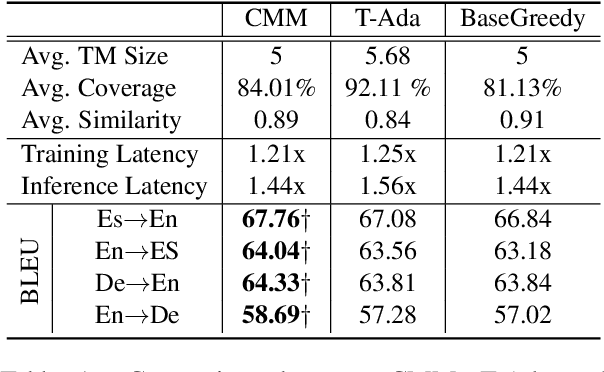
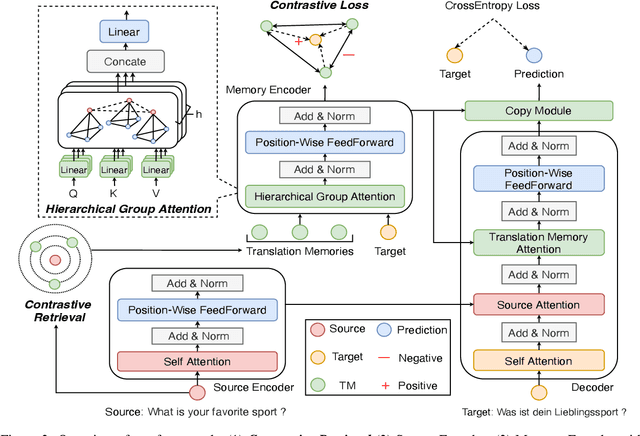
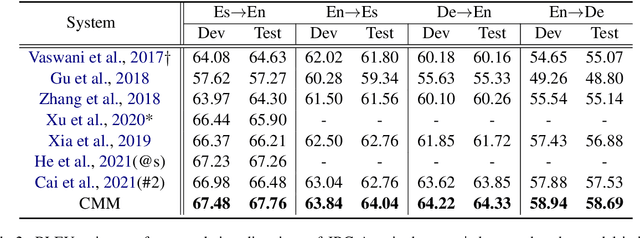
Retrieval-augmented Neural Machine Translation models have been successful in many translation scenarios. Different from previous works that make use of mutually similar but redundant translation memories~(TMs), we propose a new retrieval-augmented NMT to model contrastively retrieved translation memories that are holistically similar to the source sentence while individually contrastive to each other providing maximal information gains in three phases. First, in TM retrieval phase, we adopt a contrastive retrieval algorithm to avoid redundancy and uninformativeness of similar translation pieces. Second, in memory encoding stage, given a set of TMs we propose a novel Hierarchical Group Attention module to gather both local context of each TM and global context of the whole TM set. Finally, in training phase, a Multi-TM contrastive learning objective is introduced to learn salient feature of each TM with respect to target sentence. Experimental results show that our framework obtains improvements over strong baselines on the benchmark datasets.
Efficient 3D Reconstruction, Streaming and Visualization of Static and Dynamic Scene Parts for Multi-client Live-telepresence in Large-scale Environments
Nov 25, 2022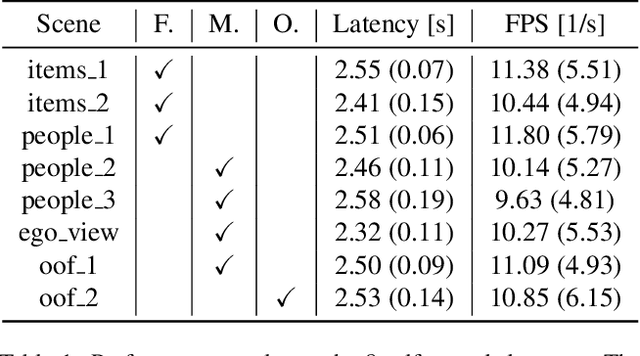
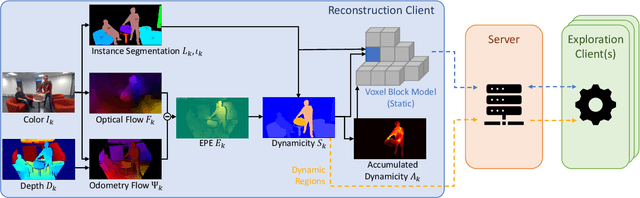
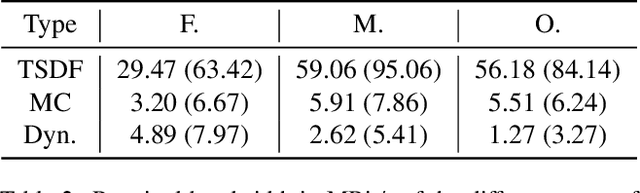

Despite the impressive progress of telepresence systems for room-scale scenes with static and dynamic scene entities, expanding their capabilities to scenarios with larger dynamic environments beyond a fixed size of a few squaremeters remains challenging. In this paper, we aim at sharing 3D live-telepresence experiences in large-scale environments beyond room scale with both static and dynamic scene entities at practical bandwidth requirements only based on light-weight scene capture with a single moving consumer-grade RGB-D camera. To this end, we present a system which is built upon a novel hybrid volumetric scene representation in terms of the combination of a voxel-based scene representation for the static contents, that not only stores the reconstructed surface geometry but also contains information about the object semantics as well as their accumulated dynamic movement over time, and a point-cloud-based representation for dynamic scene parts, where the respective separation from static parts is achieved based on semantic and instance information extracted for the input frames. With an independent yet simultaneous streaming of both static and dynamic content, where we seamlessly integrate potentially moving but currently static scene entities in the static model until they are becoming dynamic again, as well as the fusion of static and dynamic data at the remote client, our system is able to achieve VR-based live-telepresence at interactive rates. Our evaluation demonstrates the potential of our novel approach in terms of visual quality, performance, and ablation studies regarding involved design choices.
Improving Graph Neural Networks at Scale: Combining Approximate PageRank and CoreRank
Nov 08, 2022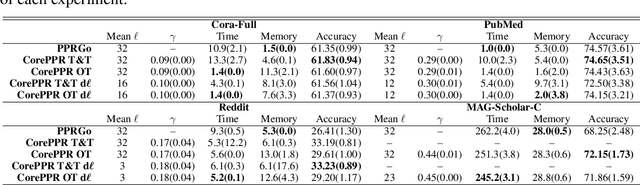
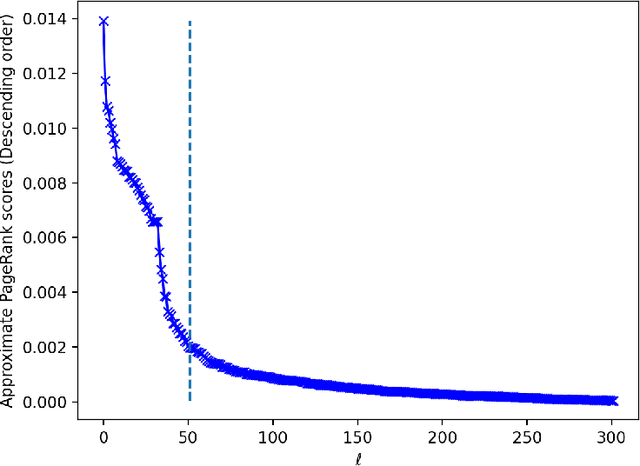
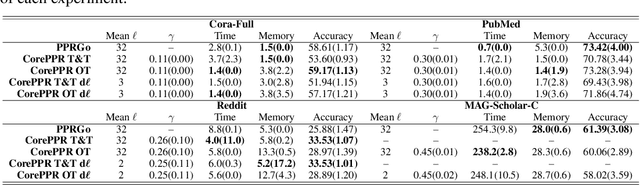
Graph Neural Networks (GNNs) have achieved great successes in many learning tasks performed on graph structures. Nonetheless, to propagate information GNNs rely on a message passing scheme which can become prohibitively expensive when working with industrial-scale graphs. Inspired by the PPRGo model, we propose the CorePPR model, a scalable solution that utilises a learnable convex combination of the approximate personalised PageRank and the CoreRank to diffuse multi-hop neighbourhood information in GNNs. Additionally, we incorporate a dynamic mechanism to select the most influential neighbours for a particular node which reduces training time while preserving the performance of the model. Overall, we demonstrate that CorePPR outperforms PPRGo, particularly on large graphs where selecting the most influential nodes is particularly relevant for scalability. Our code is publicly available at: https://github.com/arielramos97/CorePPR.
CCPrompt: Counterfactual Contrastive Prompt-Tuning for Many-Class Classification
Nov 11, 2022
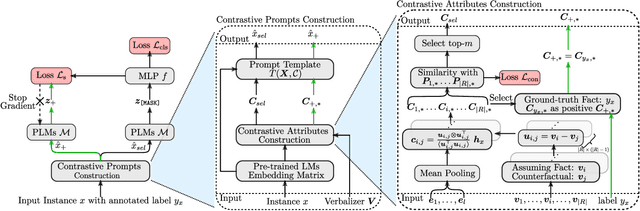
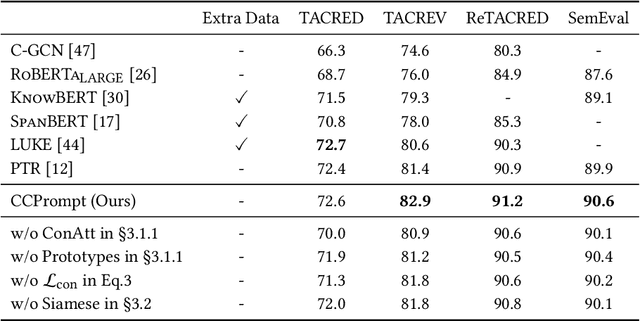
With the success of the prompt-tuning paradigm in Natural Language Processing (NLP), various prompt templates have been proposed to further stimulate specific knowledge for serving downstream tasks, e.g., machine translation, text generation, relation extraction, and so on. Existing prompt templates are mainly shared among all training samples with the information of task description. However, training samples are quite diverse. The sharing task description is unable to stimulate the unique task-related information in each training sample, especially for tasks with the finite-label space. To exploit the unique task-related information, we imitate the human decision process which aims to find the contrastive attributes between the objective factual and their potential counterfactuals. Thus, we propose the \textbf{C}ounterfactual \textbf{C}ontrastive \textbf{Prompt}-Tuning (CCPrompt) approach for many-class classification, e.g., relation classification, topic classification, and entity typing. Compared with simple classification tasks, these tasks have more complex finite-label spaces and are more rigorous for prompts. First of all, we prune the finite label space to construct fact-counterfactual pairs. Then, we exploit the contrastive attributes by projecting training instances onto every fact-counterfactual pair. We further set up global prototypes corresponding with all contrastive attributes for selecting valid contrastive attributes as additional tokens in the prompt template. Finally, a simple Siamese representation learning is employed to enhance the robustness of the model. We conduct experiments on relation classification, topic classification, and entity typing tasks in both fully supervised setting and few-shot setting. The results indicate that our model outperforms former baselines.
Corn Yield Prediction based on Remotely Sensed Variables Using Variational Autoencoder and Multiple Instance Regression
Nov 23, 2022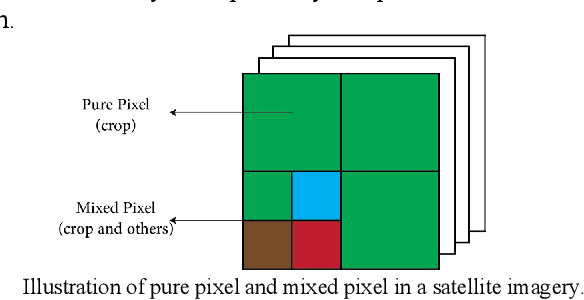
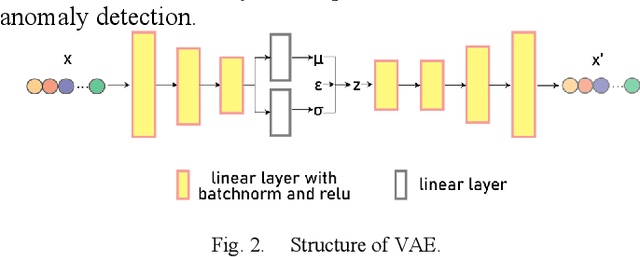
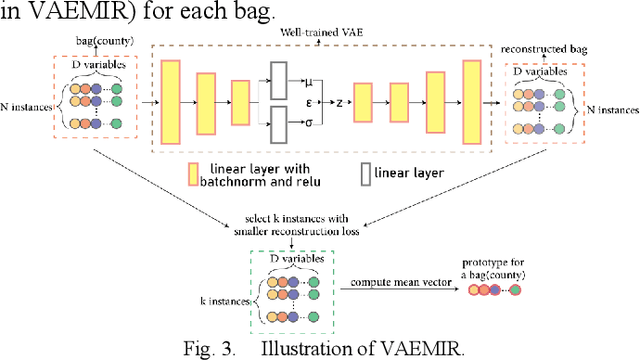
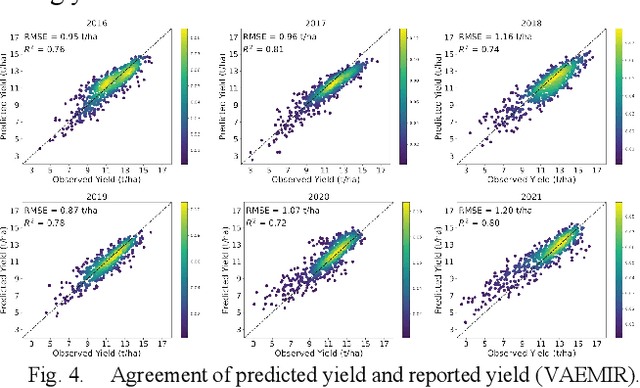
In the U.S., corn is the most produced crop and has been an essential part of the American diet. To meet the demand for supply chain management and regional food security, accurate and timely large-scale corn yield prediction is attracting more attention in precision agriculture. Recently, remote sensing technology and machine learning methods have been widely explored for crop yield prediction. Currently, most county-level yield prediction models use county-level mean variables for prediction, ignoring much detailed information. Moreover, inconsistent spatial resolution between crop area and satellite sensors results in mixed pixels, which may decrease the prediction accuracy. Only a few works have addressed the mixed pixels problem in large-scale crop yield prediction. To address the information loss and mixed pixels problem, we developed a variational autoencoder (VAE) based multiple instance regression (MIR) model for large-scaled corn yield prediction. We use all unlabeled data to train a VAE and the well-trained VAE for anomaly detection. As a preprocess method, anomaly detection can help MIR find a better representation of every bag than traditional MIR methods, thus better performing in large-scale corn yield prediction. Our experiments showed that variational autoencoder based multiple instance regression (VAEMIR) outperformed all baseline methods in large-scale corn yield prediction. Though a suitable meta parameter is required, VAEMIR shows excellent potential in feature learning and extraction for large-scale corn yield prediction.
Contrastive Masked Autoencoders for Self-Supervised Video Hashing
Nov 21, 2022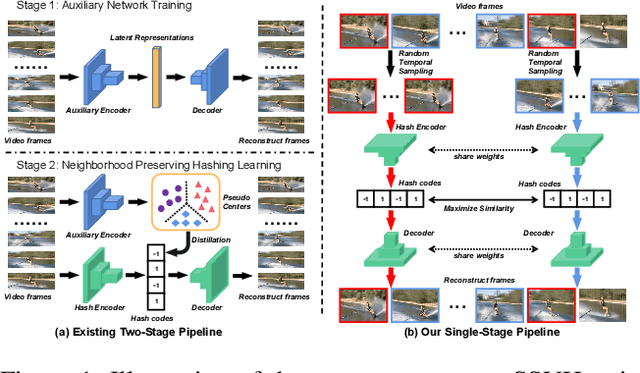

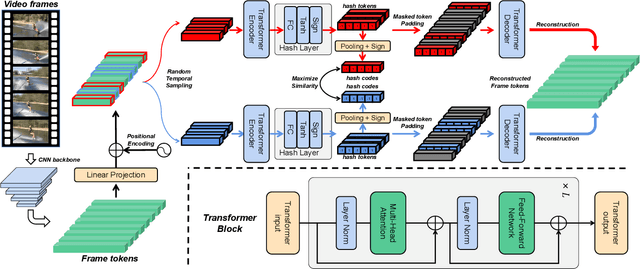
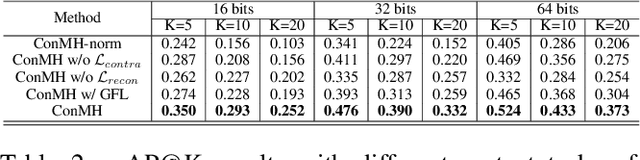
Self-Supervised Video Hashing (SSVH) models learn to generate short binary representations for videos without ground-truth supervision, facilitating large-scale video retrieval efficiency and attracting increasing research attention. The success of SSVH lies in the understanding of video content and the ability to capture the semantic relation among unlabeled videos. Typically, state-of-the-art SSVH methods consider these two points in a two-stage training pipeline, where they firstly train an auxiliary network by instance-wise mask-and-predict tasks and secondly train a hashing model to preserve the pseudo-neighborhood structure transferred from the auxiliary network. This consecutive training strategy is inflexible and also unnecessary. In this paper, we propose a simple yet effective one-stage SSVH method called ConMH, which incorporates video semantic information and video similarity relationship understanding in a single stage. To capture video semantic information for better hashing learning, we adopt an encoder-decoder structure to reconstruct the video from its temporal-masked frames. Particularly, we find that a higher masking ratio helps video understanding. Besides, we fully exploit the similarity relationship between videos by maximizing agreement between two augmented views of a video, which contributes to more discriminative and robust hash codes. Extensive experiments on three large-scale video datasets (\ie, FCVID, ActivityNet and YFCC) indicate that ConMH achieves state-of-the-art results. Code is available at https://github.com/huangmozhi9527/ConMH.
Hyperspectral Demosaicing of Snapshot Camera Images Using Deep Learning
Nov 21, 2022Spectral imaging technologies have rapidly evolved during the past decades. The recent development of single-camera-one-shot techniques for hyperspectral imaging allows multiple spectral bands to be captured simultaneously (3x3, 4x4 or 5x5 mosaic), opening up a wide range of applications. Examples include intraoperative imaging, agricultural field inspection and food quality assessment. To capture images across a wide spectrum range, i.e. to achieve high spectral resolution, the sensor design sacrifices spatial resolution. With increasing mosaic size, this effect becomes increasingly detrimental. Furthermore, demosaicing is challenging. Without incorporating edge, shape, and object information during interpolation, chromatic artifacts are likely to appear in the obtained images. Recent approaches use neural networks for demosaicing, enabling direct information extraction from image data. However, obtaining training data for these approaches poses a challenge as well. This work proposes a parallel neural network based demosaicing procedure trained on a new ground truth dataset captured in a controlled environment by a hyperspectral snapshot camera with a 4x4 mosaic pattern. The dataset is a combination of real captured scenes with images from publicly available data adapted to the 4x4 mosaic pattern. To obtain real world ground-truth data, we performed multiple camera captures with 1-pixel shifts in order to compose the entire data cube. Experiments show that the proposed network outperforms state-of-art networks.
* German Conference on Pattern Recognition (GCPR) 2022