 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Reinforcement Learning for Autonomous Ground Vehicle Exploration Without A-Priori Maps
Jan 10, 2023
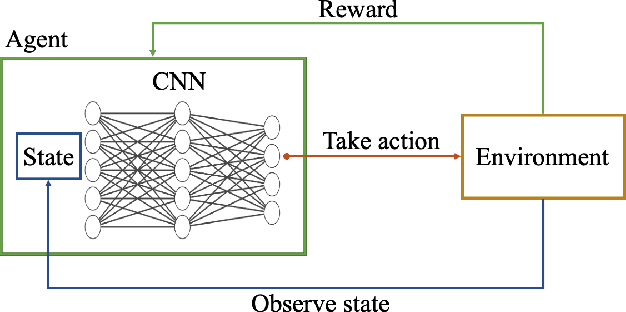
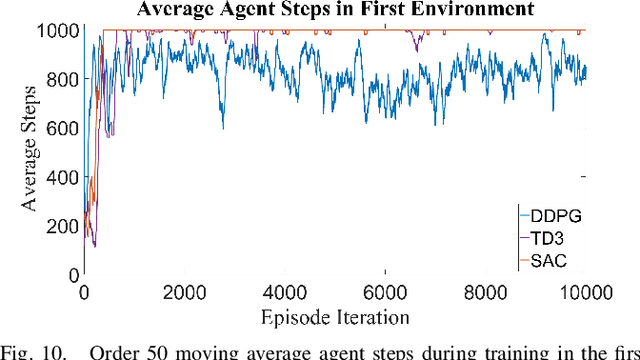
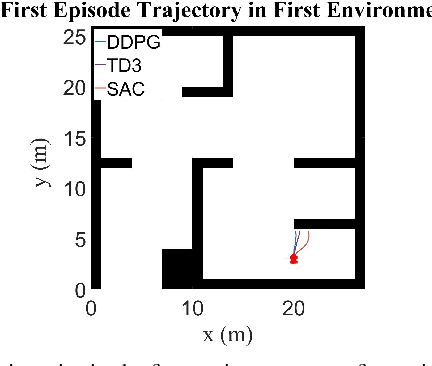
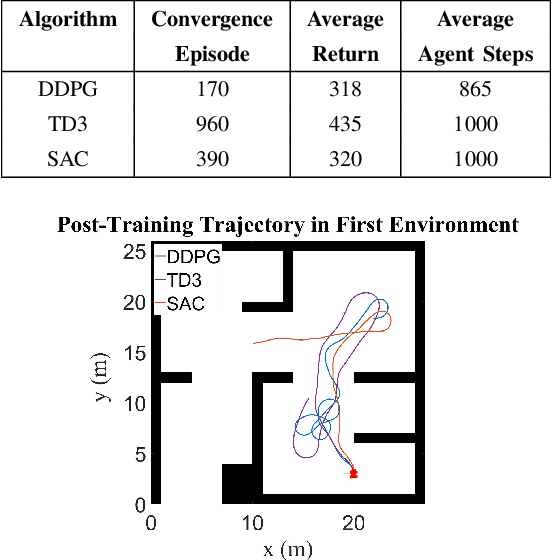
Autonomous Ground Vehicles (AGVs) are essential tools for a wide range of applications stemming from their ability to operate in hazardous environments with minimal human operator input. Efficient and effective motion planning is paramount for successful operation of AGVs. Conventional motion planning algorithms are dependent on prior knowledge of environment characteristics and offer limited utility in information poor, dynamically altering environments such as areas where emergency hazards like fire and earthquake occur, and unexplored subterranean environments such as tunnels and lava tubes on Mars. We propose a Deep Reinforcement Learning (DRL) framework for intelligent AGV exploration without a-priori maps utilizing Actor-Critic DRL algorithms to learn policies in continuous and high-dimensional action spaces, required for robotics applications. The DRL architecture comprises feedforward neural networks for the critic and actor representations in which the actor network strategizes linear and angular velocity control actions given current state inputs, that are evaluated by the critic network which learns and estimates Q-values to maximize an accumulated reward. Three off-policy DRL algorithms, DDPG, TD3 and SAC, are trained and compared in two environments of varying complexity, and further evaluated in a third with no prior training or knowledge of map characteristics. The agent is shown to learn optimal policies at the end of each training period to chart quick, efficient and collision-free exploration trajectories, and is extensible, capable of adapting to an unknown environment with no changes to network architecture or hyperparameters.
Video Surveillance System Incorporating Expert Decision-making Process: A Case Study on Detecting Calving Signs in Cattle
Jan 10, 2023
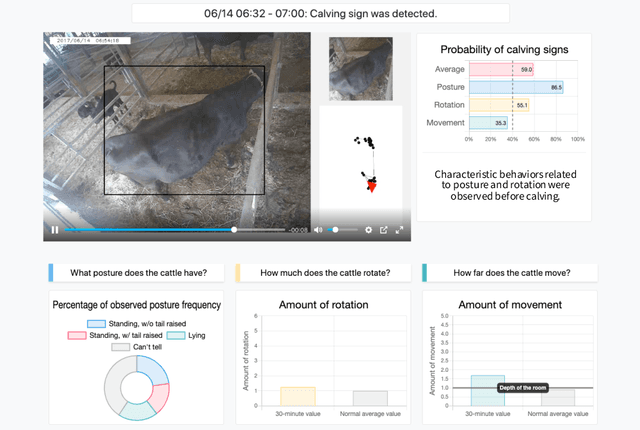
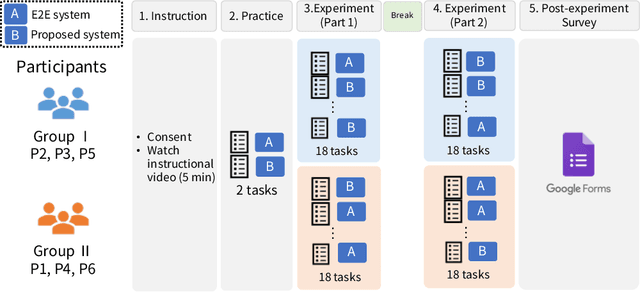

Through a user study in the field of livestock farming, we verify the effectiveness of an XAI framework for video surveillance systems. The systems can be made interpretable by incorporating experts' decision-making processes. AI systems are becoming increasingly common in real-world applications, especially in fields related to human decision-making, and its interpretability is necessary. However, there are still relatively few standard methods for assessing and addressing the interpretability of machine learning-based systems in real-world applications. In this study, we examine the framework of a video surveillance AI system that presents the reasoning behind predictions by incorporating experts' decision-making processes with rich domain knowledge of the notification target. While general black-box AI systems can only present final probability values, the proposed framework can present information relevant to experts' decisions, which is expected to be more helpful for their decision-making. In our case study, we designed a system for detecting signs of calving in cattle based on the proposed framework and evaluated the system through a user study (N=6) with people involved in livestock farming. A comparison with the black-box AI system revealed that many participants referred to the presented reasons for the prediction results, and five out of six participants selected the proposed system as the system they would like to use in the future. It became clear that we need to design a user interface that considers the reasons for the prediction results.
TERRA: Beam Management for Outdoor mm-Wave Networks
Jan 10, 2023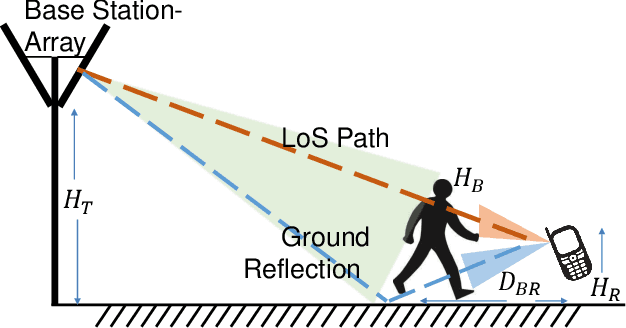
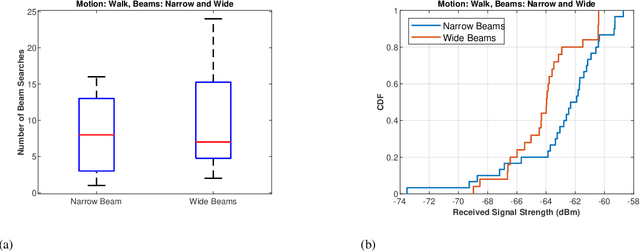
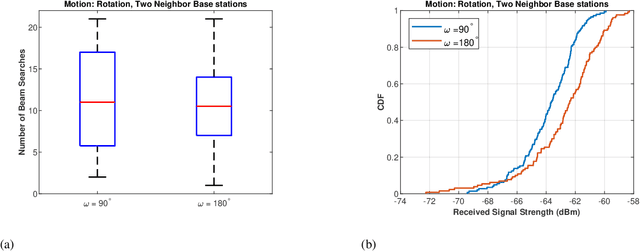
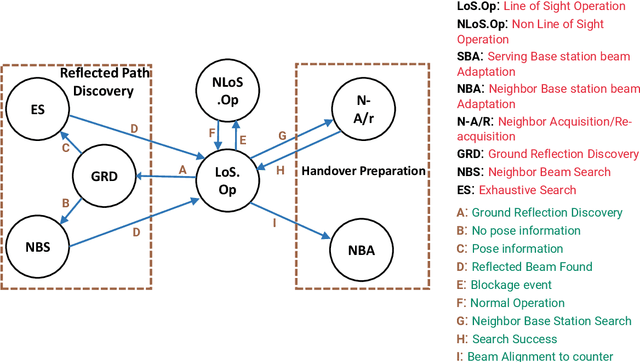
mm-Wave communication systems use narrow directional beams due to the spectrum's characteristic nature: high path and penetration losses. The mobile and the base station primarily employ beams in line of sight (LoS) direction and when needed in non-line of sight direction. Beam management protocol adapts the base station and mobile side beam direction during user mobility and to sustain the link during blockages. To avoid outage in transient pedestrian blockage of the LoS path, the mobile uses reflected or NLoS path available in indoor environments. Reflected paths can sustain time synchronization and maintain connectivity during temporary blockages. In outdoor environments, such reflections may not be available and prior work relied on dense base station deployment or co-ordinated multi-point access to address outage problem. Instead of dense and hence cost-intensive network deployments, we found experimentally that the mobile can capitalize on ground reflection. We developed TERRA protocol to effectively handle mobile side beam direction during transient blockage events. TERRA avoids outage during pedestrian blockages 84.5 $\%$ of the time in outdoor environments on concrete and gravel surfaces. TERRA also enables the mobile to perform a soft handover to a reserve neighbor base station in the event of a permanent blockage, without requiring any side information, unlike the existing works. Evaluations show that TERRA maintains received signal strength close to the optimal solution while keeping track of the neighbor base station.
Traceable Automatic Feature Transformation via Cascading Actor-Critic Agents
Dec 31, 2022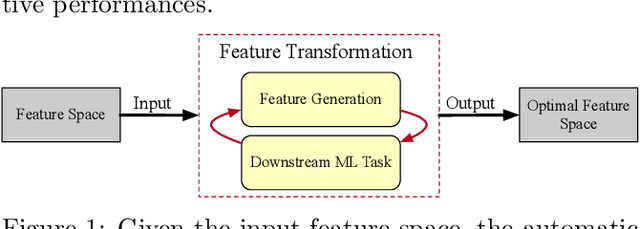
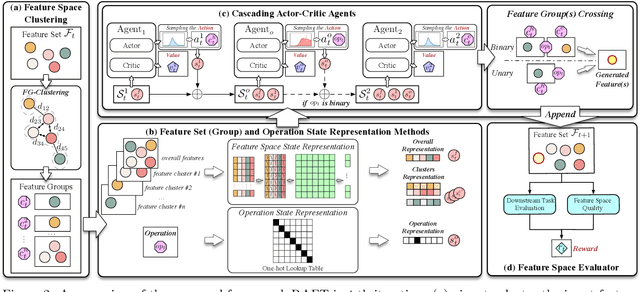
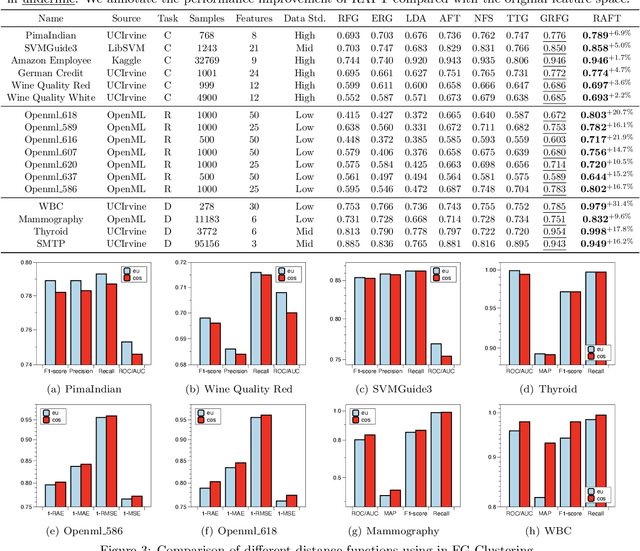
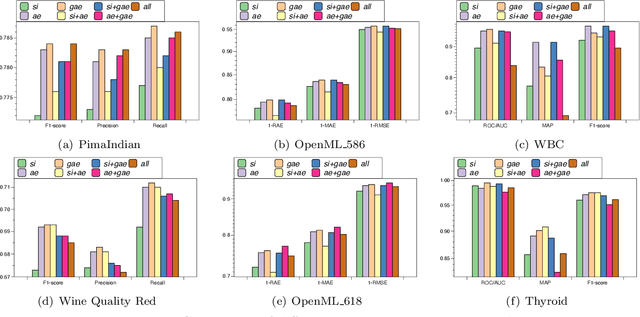
Feature transformation for AI is an essential task to boost the effectiveness and interpretability of machine learning (ML). Feature transformation aims to transform original data to identify an optimal feature space that enhances the performances of a downstream ML model. Existing studies either combines preprocessing, feature selection, and generation skills to empirically transform data, or automate feature transformation by machine intelligence, such as reinforcement learning. However, existing studies suffer from: 1) high-dimensional non-discriminative feature space; 2) inability to represent complex situational states; 3) inefficiency in integrating local and global feature information. To fill the research gap, we formulate the feature transformation task as an iterative, nested process of feature generation and selection, where feature generation is to generate and add new features based on original features, and feature selection is to remove redundant features to control the size of feature space. Finally, we present extensive experiments and case studies to illustrate 24.7\% improvements in F1 scores compared with SOTAs and robustness in high-dimensional data.
Application Of ADNN For Background Subtraction In Smart Surveillance System
Dec 31, 2022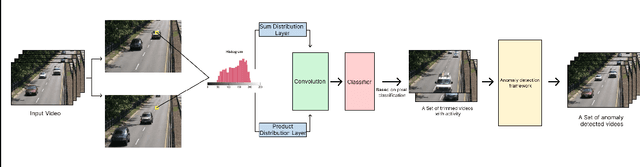
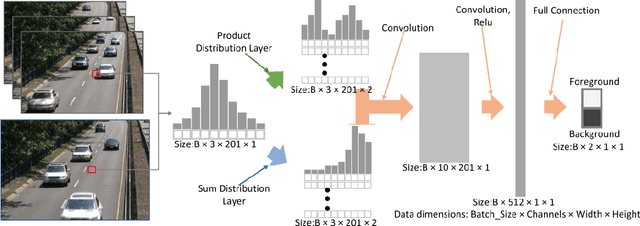
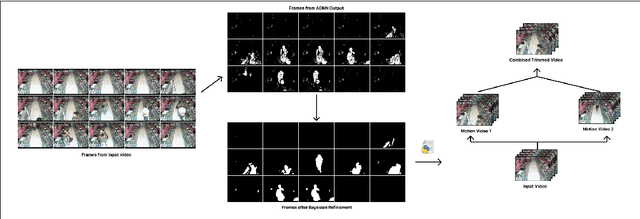
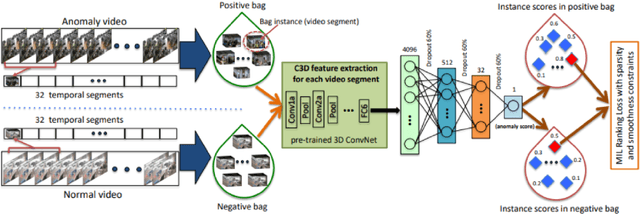
Object movement identification is one of the most researched problems in the field of computer vision. In this task, we try to classify a pixel as foreground or background. Even though numerous traditional machine learning and deep learning methods already exist for this problem, the two major issues with most of them are the need for large amounts of ground truth data and their inferior performance on unseen videos. Since every pixel of every frame has to be labeled, acquiring large amounts of data for these techniques gets rather expensive. Recently, Zhao et al. [1] proposed one of a kind Arithmetic Distribution Neural Network (ADNN) for universal background subtraction which utilizes probability information from the histogram of temporal pixels and achieves promising results. Building onto this work, we developed an intelligent video surveillance system that uses ADNN architecture for motion detection, trims the video with parts only containing motion, and performs anomaly detection on the trimmed video.
CompactIE: Compact Facts in Open Information Extraction
May 05, 2022
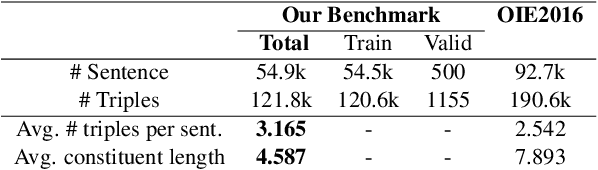
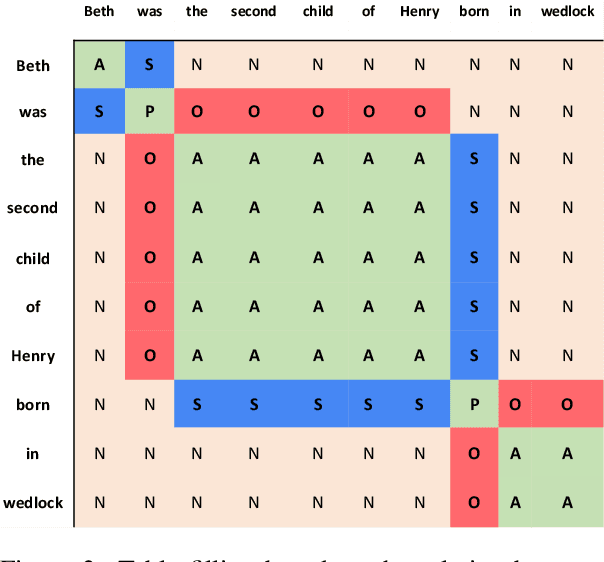

A major drawback of modern neural OpenIE systems and benchmarks is that they prioritize high coverage of information in extractions over compactness of their constituents. This severely limits the usefulness of OpenIE extractions in many downstream tasks. The utility of extractions can be improved if extractions are compact and share constituents. To this end, we study the problem of identifying compact extractions with neural-based methods. We propose CompactIE, an OpenIE system that uses a novel pipelined approach to produce compact extractions with overlapping constituents. It first detects constituents of the extractions and then links them to build extractions. We train our system on compact extractions obtained by processing existing benchmarks. Our experiments on CaRB and Wire57 datasets indicate that CompactIE finds 1.5x-2x more compact extractions than previous systems, with high precision, establishing a new state-of-the-art performance in OpenIE.
Deep Supervised Information Bottleneck Hashing for Cross-modal Retrieval based Computer-aided Diagnosis
May 06, 2022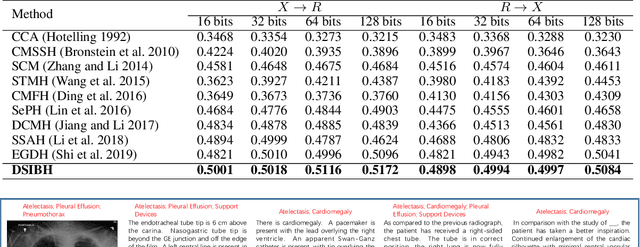
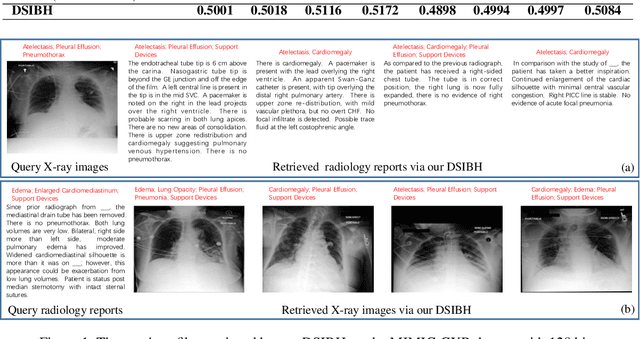
Mapping X-ray images, radiology reports, and other medical data as binary codes in the common space, which can assist clinicians to retrieve pathology-related data from heterogeneous modalities (i.e., hashing-based cross-modal medical data retrieval), provides a new view to promot computeraided diagnosis. Nevertheless, there remains a barrier to boost medical retrieval accuracy: how to reveal the ambiguous semantics of medical data without the distraction of superfluous information. To circumvent this drawback, we propose Deep Supervised Information Bottleneck Hashing (DSIBH), which effectively strengthens the discriminability of hash codes. Specifically, the Deep Deterministic Information Bottleneck (Yu, Yu, and Principe 2021) for single modality is extended to the cross-modal scenario. Benefiting from this, the superfluous information is reduced, which facilitates the discriminability of hash codes. Experimental results demonstrate the superior accuracy of the proposed DSIBH compared with state-of-the-arts in cross-modal medical data retrieval tasks.
* 7 pages, 1 figure
Inductive Attention for Video Action Anticipation
Dec 17, 2022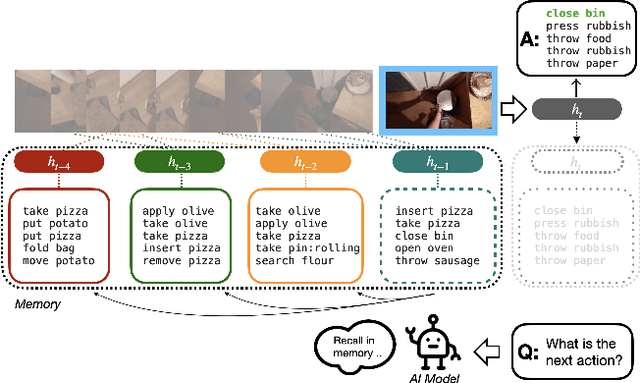
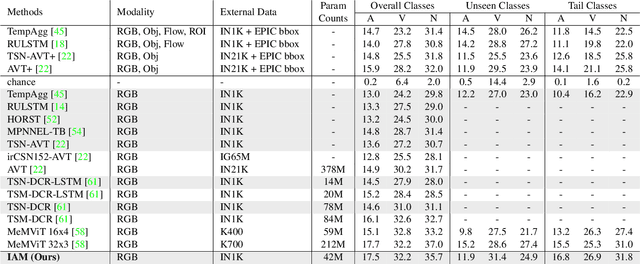
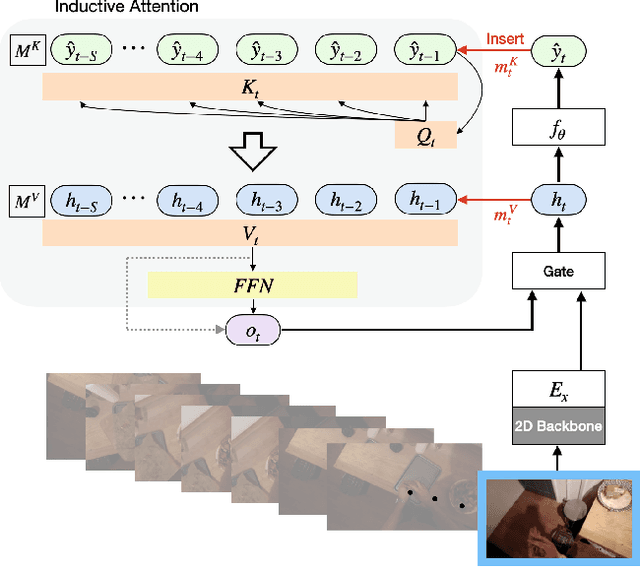
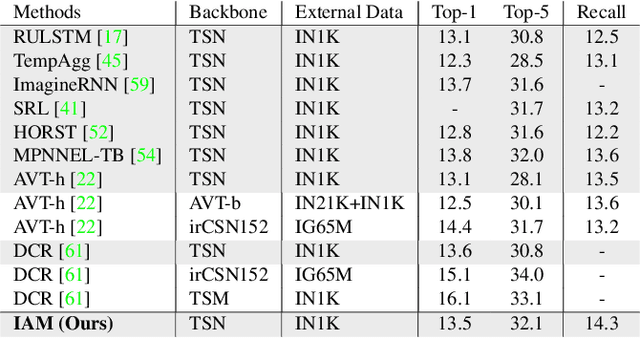
Anticipating future actions based on video observations is an important task in video understanding, which would be useful for some precautionary systems that require response time to react before an event occurs. Since the input in action anticipation is only pre-action frames, models do not have enough information about the target action; moreover, similar pre-action frames may lead to different futures. Consequently, any solution using existing action recognition models can only be suboptimal. Recently, researchers have proposed using a longer video context to remedy the insufficient information in pre-action intervals, as well as the self-attention to query past relevant moments to address the anticipation problem. However, the indirect use of video input features as the query might be inefficient, as it only serves as the proxy to the anticipation goal. To this end, we propose an inductive attention model, which transparently uses prior prediction as the query to derive the anticipation result by induction from past experience. Our method naturally considers the uncertainty of multiple futures via the many-to-many association. On the large-scale egocentric video datasets, our model not only shows consistently better performance than state of the art using the same backbone, and is competitive to the methods that employ a stronger backbone, but also superior efficiency in less model parameters.
Learning Support and Trivial Prototypes for Interpretable Image Classification
Jan 08, 2023

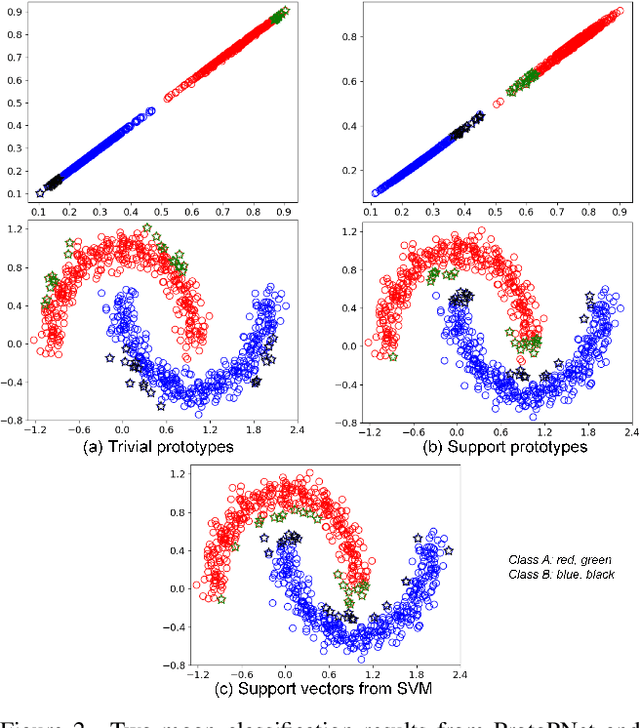

Prototypical part network (ProtoPNet) methods have been designed to achieve interpretable classification by associating predictions with a set of training prototypes, which we refer to as trivial (i.e., easy-to-learn) prototypes because they are trained to lie far from the classification boundary in the feature space. Note that it is possible to make an analogy between ProtoPNet and support vector machine (SVM) given that the classification from both methods relies on computing similarity with a set of training points (i.e., trivial prototypes in ProtoPNet, and support vectors in SVM). However, while trivial prototypes are located far from the classification boundary, support vectors are located close to this boundary, and we argue that this discrepancy with the well-established SVM theory can result in ProtoPNet models with suboptimal classification accuracy. In this paper, we aim to improve the classification accuracy of ProtoPNet with a new method to learn support prototypes that lie near the classification boundary in the feature space, as suggested by the SVM theory. In addition, we target the improvement of classification interpretability with a new model, named ST-ProtoPNet, which exploits our support prototypes and the trivial prototypes to provide complementary interpretability information. Experimental results on CUB-200-2011, Stanford Cars, and Stanford Dogs datasets demonstrate that the proposed method achieves state-of-the-art classification accuracy and produces more visually meaningful and diverse prototypes.
Multivariate Powered Dirichlet Hawkes Process
Dec 13, 2022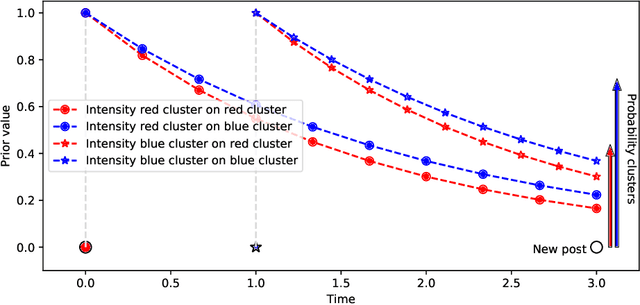
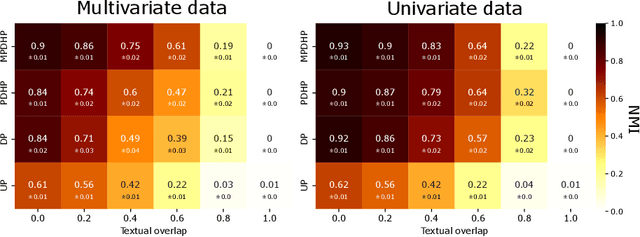
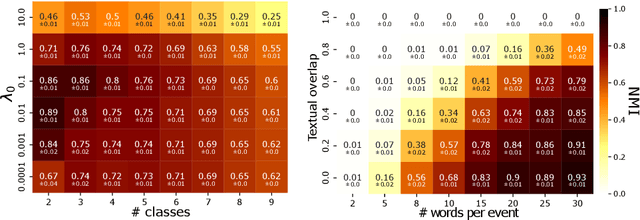
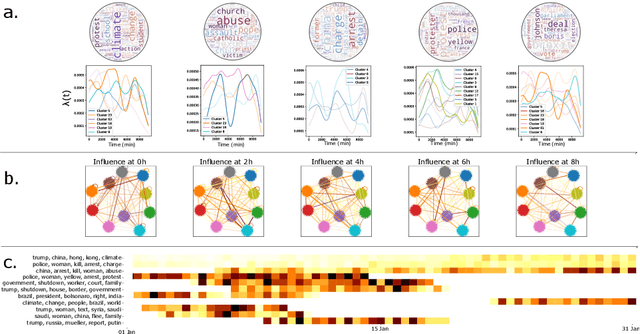
The publication time of a document carries a relevant information about its semantic content. The Dirichlet-Hawkes process has been proposed to jointly model textual information and publication dynamics. This approach has been used with success in several recent works, and extended to tackle specific challenging problems --typically for short texts or entangled publication dynamics. However, the prior in its current form does not allow for complex publication dynamics. In particular, inferred topics are independent from each other --a publication about finance is assumed to have no influence on publications about politics, for instance. In this work, we develop the Multivariate Powered Dirichlet-Hawkes Process (MPDHP), that alleviates this assumption. Publications about various topics can now influence each other. We detail and overcome the technical challenges that arise from considering interacting topics. We conduct a systematic evaluation of MPDHP on a range of synthetic datasets to define its application domain and limitations. Finally, we develop a use case of the MPDHP on Reddit data. At the end of this article, the interested reader will know how and when to use MPDHP, and when not to.