 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Converting OpenStreetMap Data to Road Networks for Downstream Applications
Dec 14, 2022
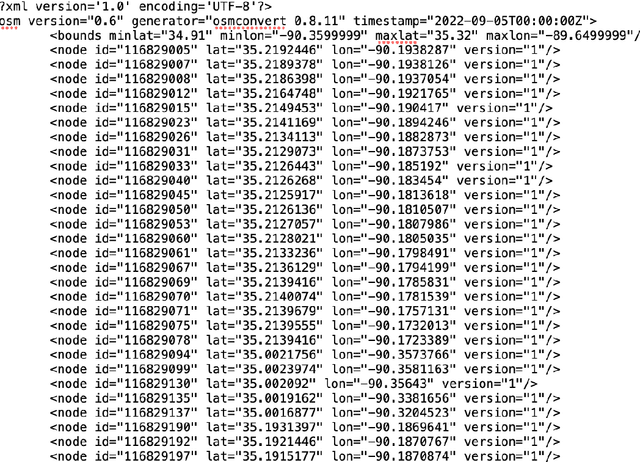
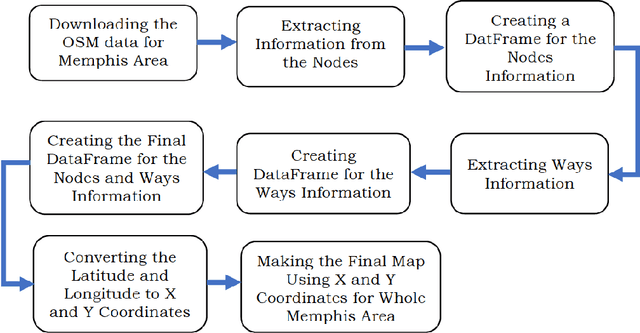
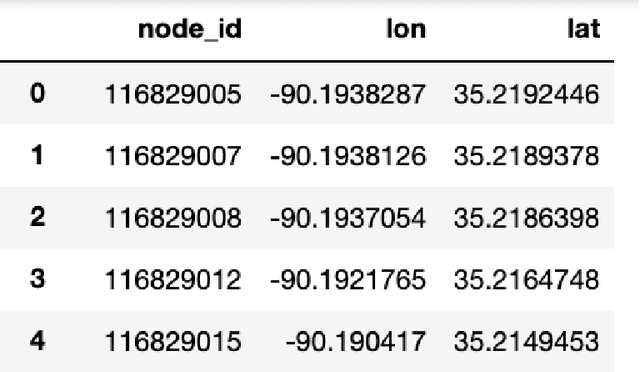
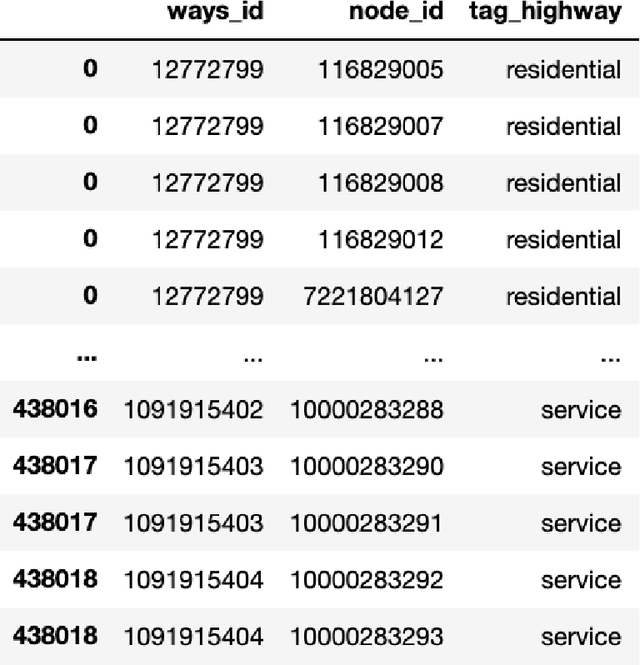
We study how to convert OpenStreetMap data to road networks for downstream applications. OpenStreetMap data has different formats. Extensible Markup Language (XML) is one of them. OSM data consist of nodes, ways, and relations. We process OSM XML data to extract the information of nodes and ways to obtain the map of streets of the Memphis area. We can use this map for different downstream applications.
Traffic sign detection and recognition using event camera image reconstruction
Dec 16, 2022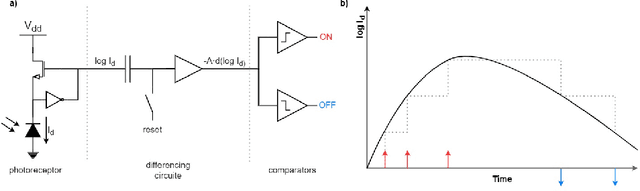
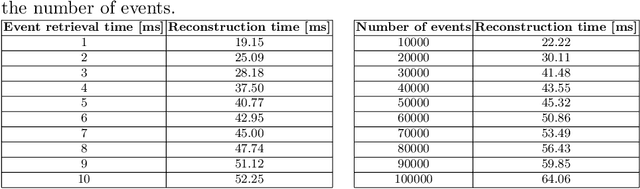

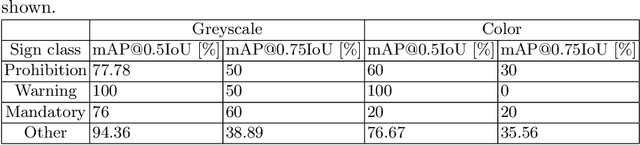
This paper presents a method for detection and recognition of traffic signs based on information extracted from an event camera. The solution used a FireNet deep convolutional neural network to reconstruct events into greyscale frames. Two YOLOv4 network models were trained, one based on greyscale images and the other on colour images. The best result was achieved for the model trained on the basis of greyscale images, achieving an efficiency of 87.03%.
Distributed Filtering with Value of Information Censoring
Apr 01, 2022
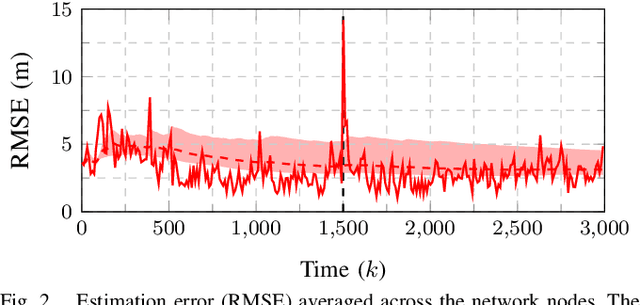
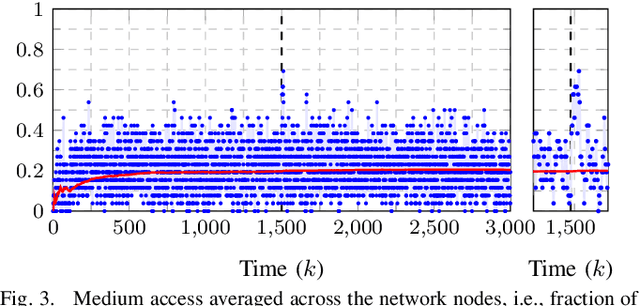
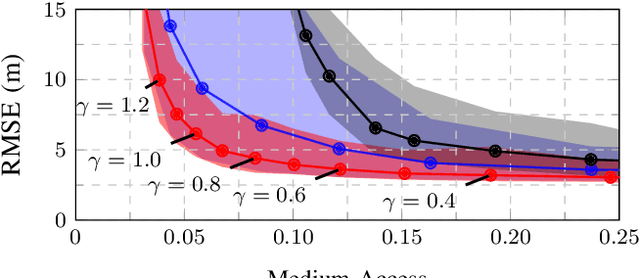
This work presents a distributed estimation algorithm that efficiently uses the available communication resources. The approach is based on Bayesian filtering that is distributed across a network by using the logarithmic opinion pool operator. Communication efficiency is achieved by having only agents with high Value of Information (VoI) share their estimates, and the algorithm provides a tunable trade-off between communication resources and estimation error. Under linear-Gaussian models the algorithm takes the form of a censored distributed Information filter, which guarantees the consistency of agent estimates. Importantly, consistent estimates are shown to play a crucial role in enabling the large reductions in communication usage provided by the VoI censoring approach. We verify the performance of the proposed method via complex simulations in a dynamic network topology and by experimental validation over a real ad-hoc wireless communication network. The results show the validity of using the proposed method to drastically reduce the communication costs of distributed estimation tasks.
Modeling Nonlinear Dynamics in Continuous Time with Inductive Biases on Decay Rates and/or Frequencies
Dec 26, 2022
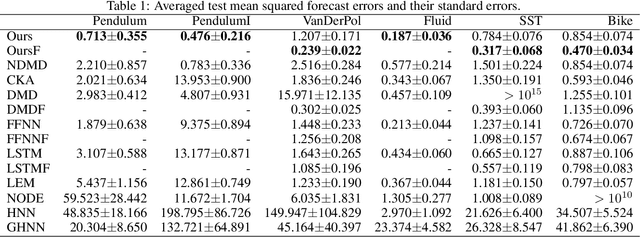
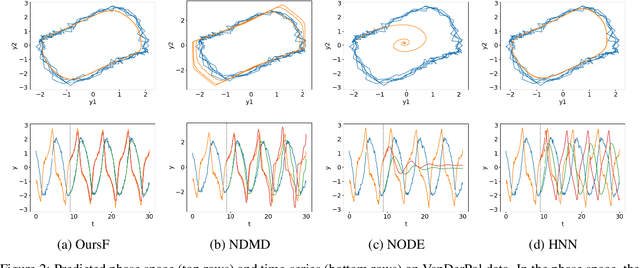

We propose a neural network-based model for nonlinear dynamics in continuous time that can impose inductive biases on decay rates and/or frequencies. Inductive biases are helpful for training neural networks especially when training data are small. The proposed model is based on the Koopman operator theory, where the decay rate and frequency information is used by restricting the eigenvalues of the Koopman operator that describe linear evolution in a Koopman space. We use neural networks to find an appropriate Koopman space, which are trained by minimizing multi-step forecasting and backcasting errors using irregularly sampled time-series data. Experiments on various time-series datasets demonstrate that the proposed method achieves higher forecasting performance given a single short training sequence than the existing methods.
Knowledge Base Completion using Web-Based Question Answering and Multimodal Fusion
Nov 15, 2022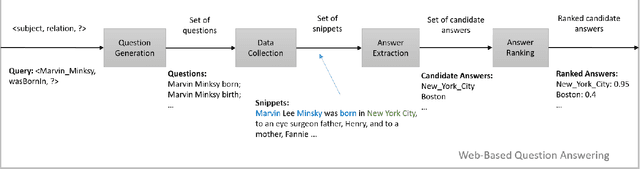
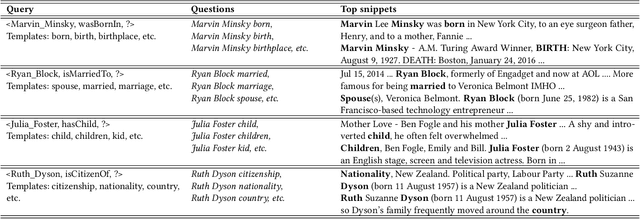
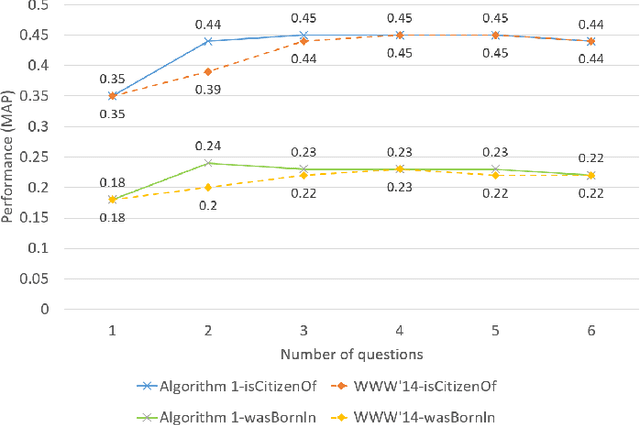

Over the past few years, large knowledge bases have been constructed to store massive amounts of knowledge. However, these knowledge bases are highly incomplete. To solve this problem, we propose a web-based question answering system system with multimodal fusion of unstructured and structured information, to fill in missing information for knowledge bases. To utilize unstructured information from the Web for knowledge base completion, we design a web-based question answering system using multimodal features and question templates to extract missing facts, which can achieve good performance with very few questions. To help improve extraction quality, the question answering system employs structured information from knowledge bases, such as entity types and entity-to-entity relatedness.
The Internet of Senses: Building on Semantic Communications and Edge Intelligence
Dec 21, 2022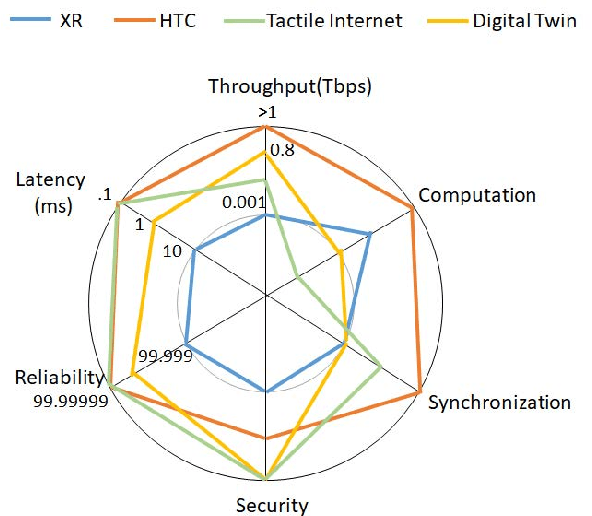
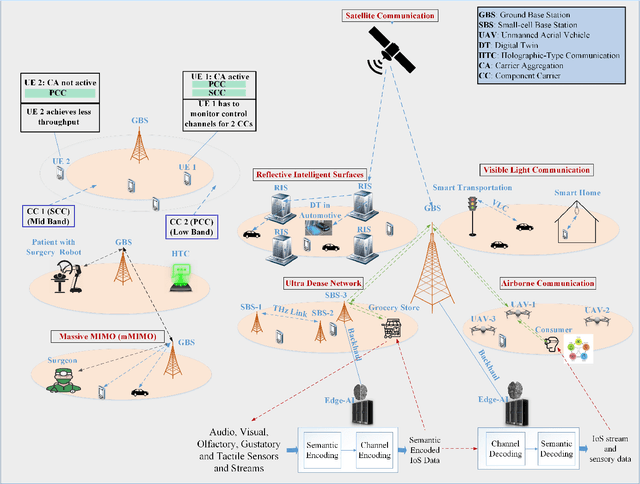
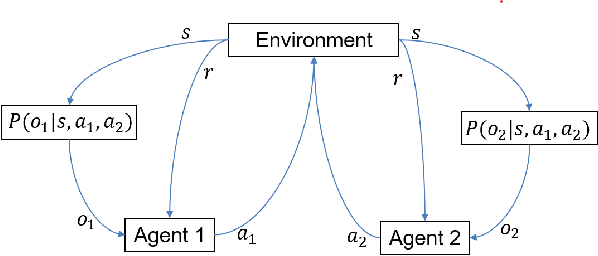
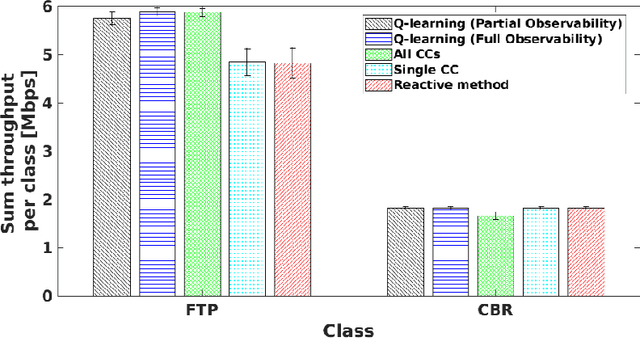
The Internet of Senses (IoS) holds the promise of flawless telepresence-style communication for all human `receptors' and therefore blurs the difference of virtual and real environments. We commence by highlighting the compelling use cases empowered by the IoS and also the key network requirements. We then elaborate on how the emerging semantic communications and Artificial Intelligence (AI)/Machine Learning (ML) paradigms along with 6G technologies may satisfy the requirements of IoS use cases. On one hand, semantic communications can be applied for extracting meaningful and significant information and hence efficiently exploit the resources and for harnessing a priori information at the receiver to satisfy IoS requirements. On the other hand, AI/ML facilitates frugal network resource management by making use of the enormous amount of data generated in IoS edge nodes and devices, as well as by optimizing the IoS performance via intelligent agents. However, the intelligent agents deployed at the edge are not completely aware of each others' decisions and the environments of each other, hence they operate in a partially rather than fully observable environment. Therefore, we present a case study of Partially Observable Markov Decision Processes (POMDP) for improving the User Equipment (UE) throughput and energy consumption, as they are imperative for IoS use cases, using Reinforcement Learning for astutely activating and deactivating the component carriers in carrier aggregation. Finally, we outline the challenges and open issues of IoS implementations and employing semantic communications, edge intelligence as well as learning under partial observability in the IoS context.
The Architectural Bottleneck Principle
Nov 11, 2022
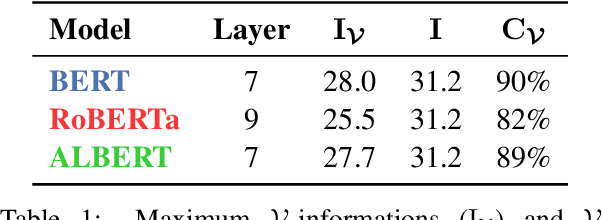
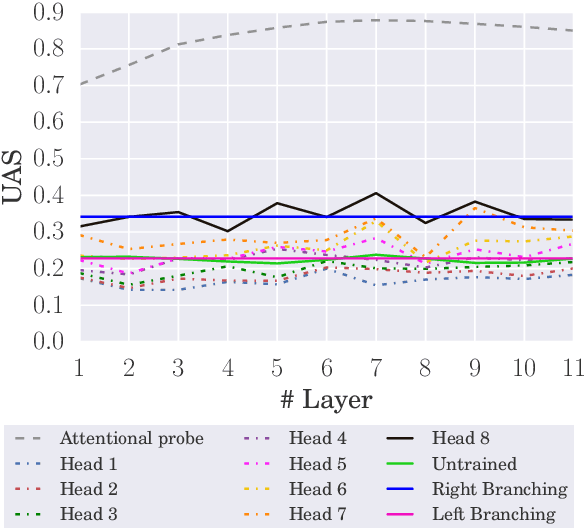
In this paper, we seek to measure how much information a component in a neural network could extract from the representations fed into it. Our work stands in contrast to prior probing work, most of which investigates how much information a model's representations contain. This shift in perspective leads us to propose a new principle for probing, the architectural bottleneck principle: In order to estimate how much information a given component could extract, a probe should look exactly like the component. Relying on this principle, we estimate how much syntactic information is available to transformers through our attentional probe, a probe that exactly resembles a transformer's self-attention head. Experimentally, we find that, in three models (BERT, ALBERT, and RoBERTa), a sentence's syntax tree is mostly extractable by our probe, suggesting these models have access to syntactic information while composing their contextual representations. Whether this information is actually used by these models, however, remains an open question.
SemanticBEVFusion: Rethink LiDAR-Camera Fusion in Unified Bird's-Eye View Representation for 3D Object Detection
Dec 09, 2022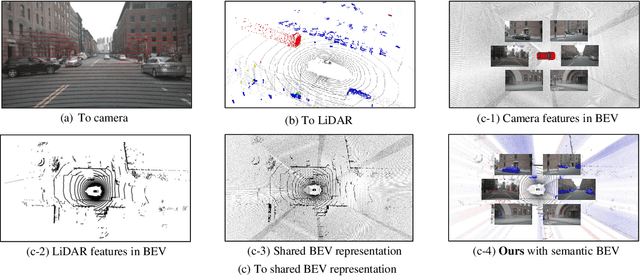
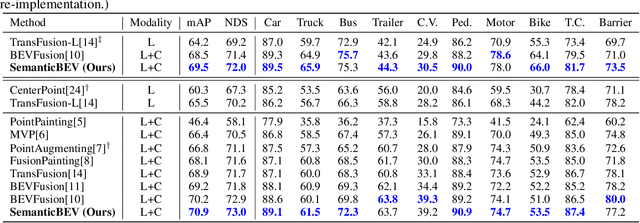
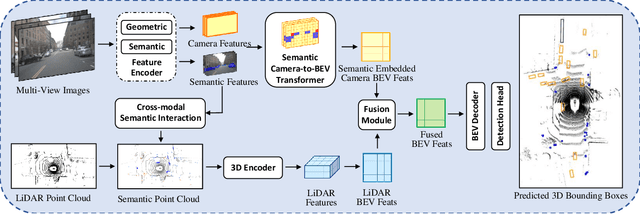
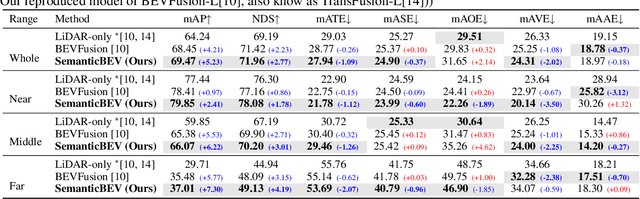
LiDAR and camera are two essential sensors for 3D object detection in autonomous driving. LiDAR provides accurate and reliable 3D geometry information while the camera provides rich texture with color. Despite the increasing popularity of fusing these two complementary sensors, the challenge remains in how to effectively fuse 3D LiDAR point cloud with 2D camera images. Recent methods focus on point-level fusion which paints the LiDAR point cloud with camera features in the perspective view or bird's-eye view (BEV)-level fusion which unifies multi-modality features in the BEV representation. In this paper, we rethink these previous fusion strategies and analyze their information loss and influences on geometric and semantic features. We present SemanticBEVFusion to deeply fuse camera features with LiDAR features in a unified BEV representation while maintaining per-modality strengths for 3D object detection. Our method achieves state-of-the-art performance on the large-scale nuScenes dataset, especially for challenging distant objects. The code will be made publicly available.
Deep Reinforcement Learning for Autonomous Ground Vehicle Exploration Without A-Priori Maps
Jan 10, 2023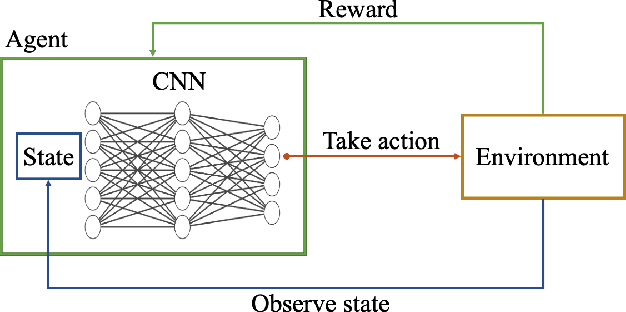
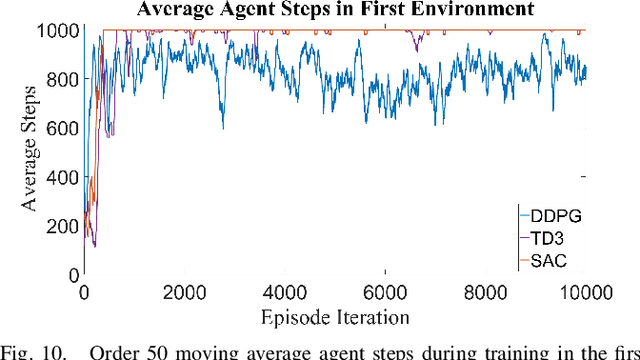
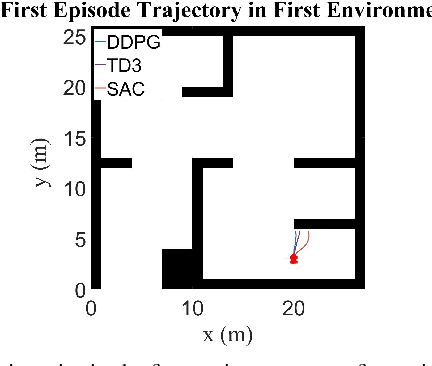
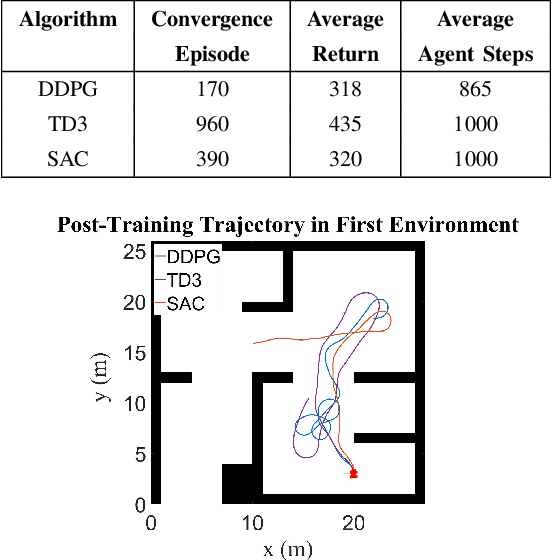
Autonomous Ground Vehicles (AGVs) are essential tools for a wide range of applications stemming from their ability to operate in hazardous environments with minimal human operator input. Efficient and effective motion planning is paramount for successful operation of AGVs. Conventional motion planning algorithms are dependent on prior knowledge of environment characteristics and offer limited utility in information poor, dynamically altering environments such as areas where emergency hazards like fire and earthquake occur, and unexplored subterranean environments such as tunnels and lava tubes on Mars. We propose a Deep Reinforcement Learning (DRL) framework for intelligent AGV exploration without a-priori maps utilizing Actor-Critic DRL algorithms to learn policies in continuous and high-dimensional action spaces, required for robotics applications. The DRL architecture comprises feedforward neural networks for the critic and actor representations in which the actor network strategizes linear and angular velocity control actions given current state inputs, that are evaluated by the critic network which learns and estimates Q-values to maximize an accumulated reward. Three off-policy DRL algorithms, DDPG, TD3 and SAC, are trained and compared in two environments of varying complexity, and further evaluated in a third with no prior training or knowledge of map characteristics. The agent is shown to learn optimal policies at the end of each training period to chart quick, efficient and collision-free exploration trajectories, and is extensible, capable of adapting to an unknown environment with no changes to network architecture or hyperparameters.
Video Surveillance System Incorporating Expert Decision-making Process: A Case Study on Detecting Calving Signs in Cattle
Jan 10, 2023
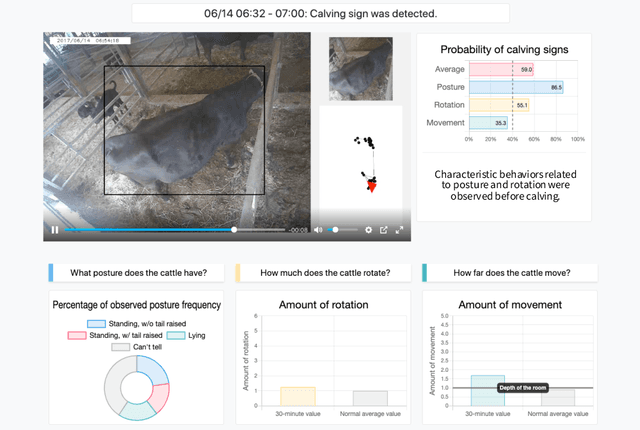
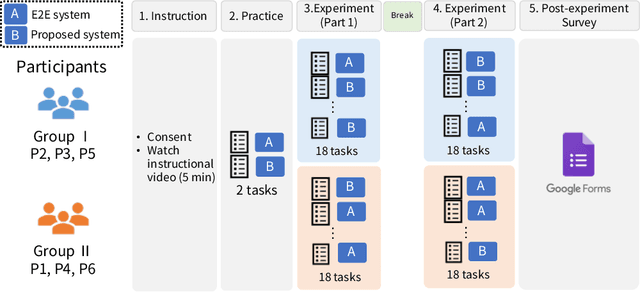

Through a user study in the field of livestock farming, we verify the effectiveness of an XAI framework for video surveillance systems. The systems can be made interpretable by incorporating experts' decision-making processes. AI systems are becoming increasingly common in real-world applications, especially in fields related to human decision-making, and its interpretability is necessary. However, there are still relatively few standard methods for assessing and addressing the interpretability of machine learning-based systems in real-world applications. In this study, we examine the framework of a video surveillance AI system that presents the reasoning behind predictions by incorporating experts' decision-making processes with rich domain knowledge of the notification target. While general black-box AI systems can only present final probability values, the proposed framework can present information relevant to experts' decisions, which is expected to be more helpful for their decision-making. In our case study, we designed a system for detecting signs of calving in cattle based on the proposed framework and evaluated the system through a user study (N=6) with people involved in livestock farming. A comparison with the black-box AI system revealed that many participants referred to the presented reasons for the prediction results, and five out of six participants selected the proposed system as the system they would like to use in the future. It became clear that we need to design a user interface that considers the reasons for the prediction results.