 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
UIU-Net: U-Net in U-Net for Infrared Small Object Detection
Dec 02, 2022
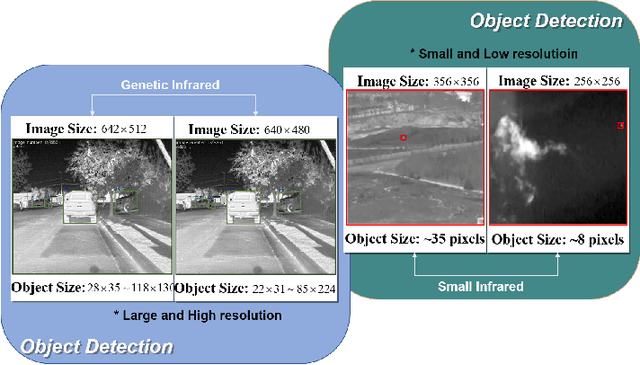
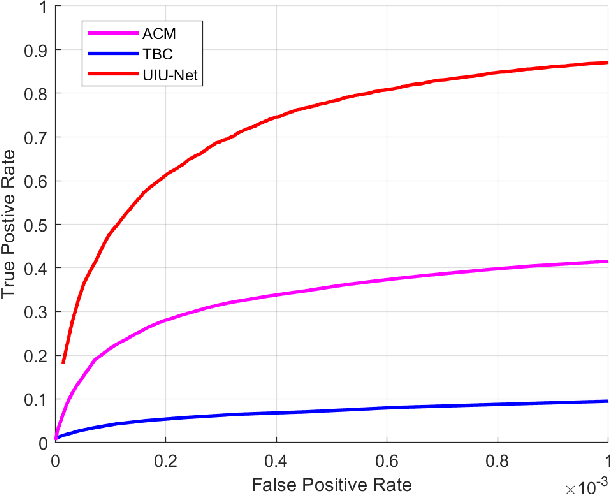
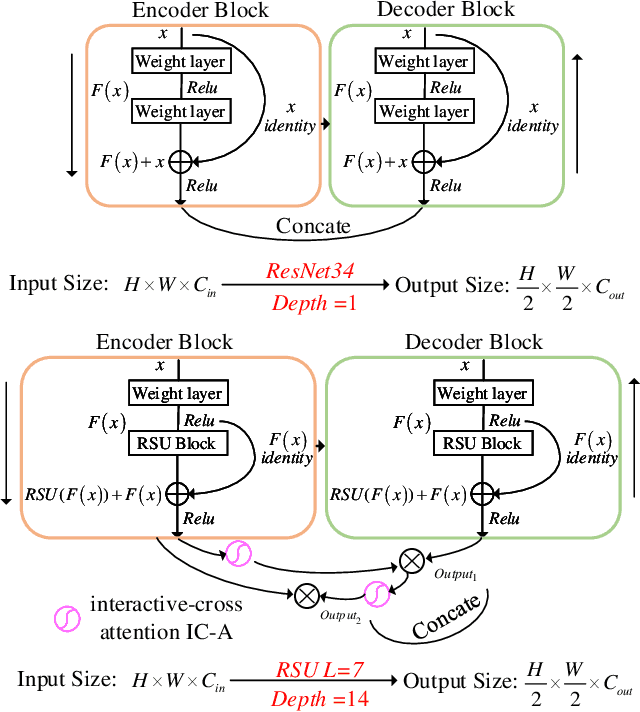
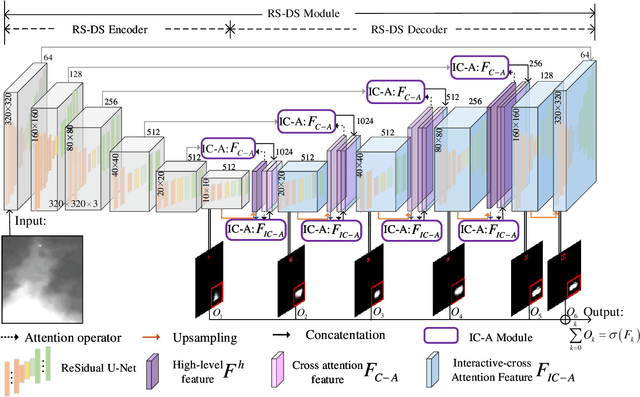
Learning-based infrared small object detection methods currently rely heavily on the classification backbone network. This tends to result in tiny object loss and feature distinguishability limitations as the network depth increases. Furthermore, small objects in infrared images are frequently emerged bright and dark, posing severe demands for obtaining precise object contrast information. For this reason, we in this paper propose a simple and effective ``U-Net in U-Net'' framework, UIU-Net for short, and detect small objects in infrared images. As the name suggests, UIU-Net embeds a tiny U-Net into a larger U-Net backbone, enabling the multi-level and multi-scale representation learning of objects. Moreover, UIU-Net can be trained from scratch, and the learned features can enhance global and local contrast information effectively. More specifically, the UIU-Net model is divided into two modules: the resolution-maintenance deep supervision (RM-DS) module and the interactive-cross attention (IC-A) module. RM-DS integrates Residual U-blocks into a deep supervision network to generate deep multi-scale resolution-maintenance features while learning global context information. Further, IC-A encodes the local context information between the low-level details and high-level semantic features. Extensive experiments conducted on two infrared single-frame image datasets, i.e., SIRST and Synthetic datasets, show the effectiveness and superiority of the proposed UIU-Net in comparison with several state-of-the-art infrared small object detection methods. The proposed UIU-Net also produces powerful generalization performance for video sequence infrared small object datasets, e.g., ATR ground/air video sequence dataset. The codes of this work are available openly at \url{https://github.com/danfenghong/IEEE_TIP_UIU-Net}.
Multi-view Graph Convolutional Networks with Differentiable Node Selection
Dec 09, 2022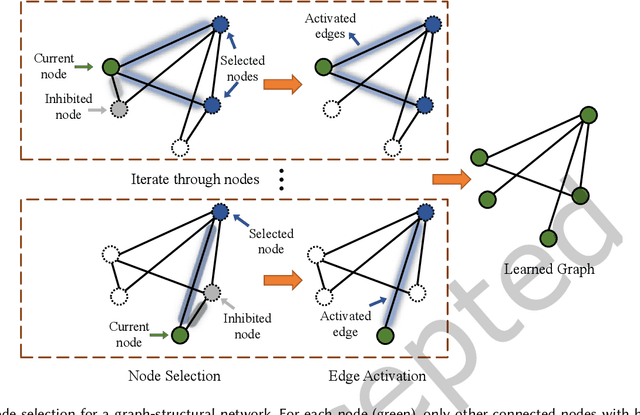

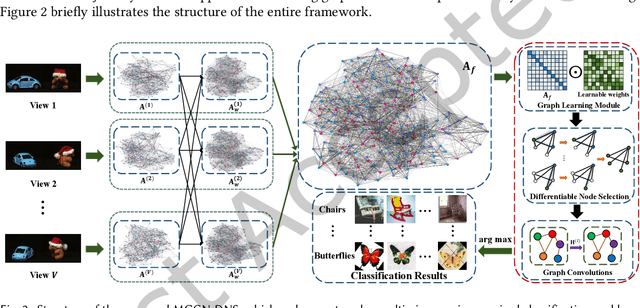
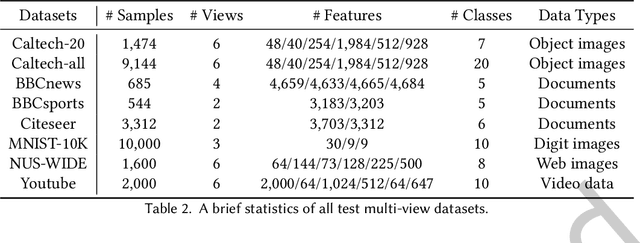
Multi-view data containing complementary and consensus information can facilitate representation learning by exploiting the intact integration of multi-view features. Because most objects in real world often have underlying connections, organizing multi-view data as heterogeneous graphs is beneficial to extracting latent information among different objects. Due to the powerful capability to gather information of neighborhood nodes, in this paper, we apply Graph Convolutional Network (GCN) to cope with heterogeneous-graph data originating from multi-view data, which is still under-explored in the field of GCN. In order to improve the quality of network topology and alleviate the interference of noises yielded by graph fusion, some methods undertake sorting operations before the graph convolution procedure. These GCN-based methods generally sort and select the most confident neighborhood nodes for each vertex, such as picking the top-k nodes according to pre-defined confidence values. Nonetheless, this is problematic due to the non-differentiable sorting operators and inflexible graph embedding learning, which may result in blocked gradient computations and undesired performance. To cope with these issues, we propose a joint framework dubbed Multi-view Graph Convolutional Network with Differentiable Node Selection (MGCN-DNS), which is constituted of an adaptive graph fusion layer, a graph learning module and a differentiable node selection schema. MGCN-DNS accepts multi-channel graph-structural data as inputs and aims to learn more robust graph fusion through a differentiable neural network. The effectiveness of the proposed method is verified by rigorous comparisons with considerable state-of-the-art approaches in terms of multi-view semi-supervised classification tasks.
Effectiveness of Delivered Information Trade Study
Feb 28, 2022
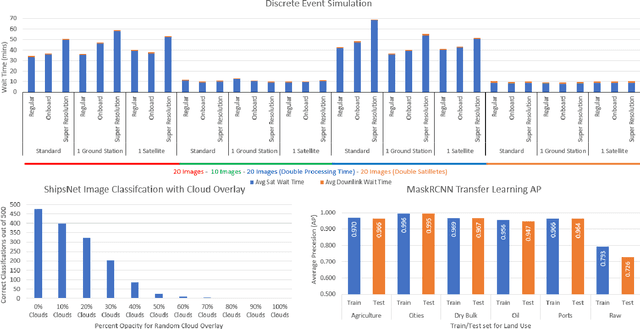

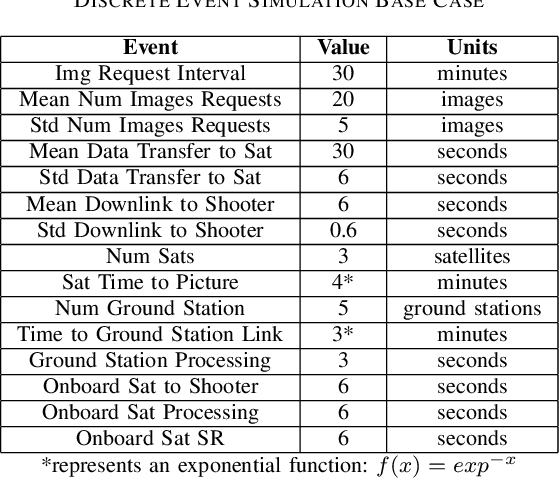
The sensor to shooter timeline is affected by two main variables: satellite positioning and asset positioning. Speeding up satellite positioning by adding more sensors or by decreasing processing time is important only if there is a prepared shooter, otherwise the main source of time is getting the shooter into position. However, the intelligence community should work towards the exploitation of sensors to the highest speed and effectiveness possible. Achieving a high effectiveness while keeping speed high is a tradeoff that must be considered in the sensor to shooter timeline. In this paper we investigate two main ideas, increasing the effectiveness of satellite imagery through image manipulation and how on-board image manipulation would affect the sensor to shooter timeline. We cover these ideas in four scenarios: Discrete Event Simulation of onboard processing versus ground station processing, quality of information with cloud cover removal, information improvement with super resolution, and data reduction with image to caption. This paper will show how image manipulation techniques such as Super Resolution, Cloud Removal, and Image to Caption will improve the quality of delivered information in addition to showing how those processes effect the sensor to shooter timeline.
Covertly Controlling a Linear System
Dec 02, 2022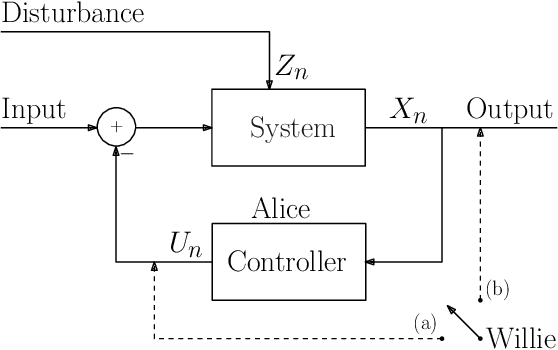
Consider the problem of covertly controlling a linear system. In this problem, Alice desires to control (stabilize or change the behavior of) a linear system, while keeping an observer, Willie, unable to decide if the system is indeed being controlled or not. We formally define the problem, under a model where Willie can only observe the system's output. Focusing on AR(1) systems, we show that when Willie observes the system's output through a clean channel, an inherently unstable linear system can not be covertly stabilized. However, an inherently stable linear system can be covertly controlled, in the sense of covertly changing its parameter or resetting its memory. Moreover, we give positive and negative results for two important controllers: a minimal-information controller, where Alice is allowed to use only $1$ bit per sample, and a maximal-information controller, where Alice is allowed to view the real-valued output. Unlike covert communication, where the trade-off is between rate and covertness, the results reveal an interesting \emph{three--fold} trade--off in covert control: the amount of information used by the controller, control performance and covertness.
Active SLAM: A Review On Last Decade
Dec 22, 2022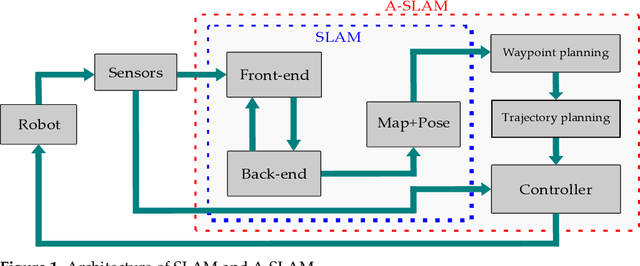
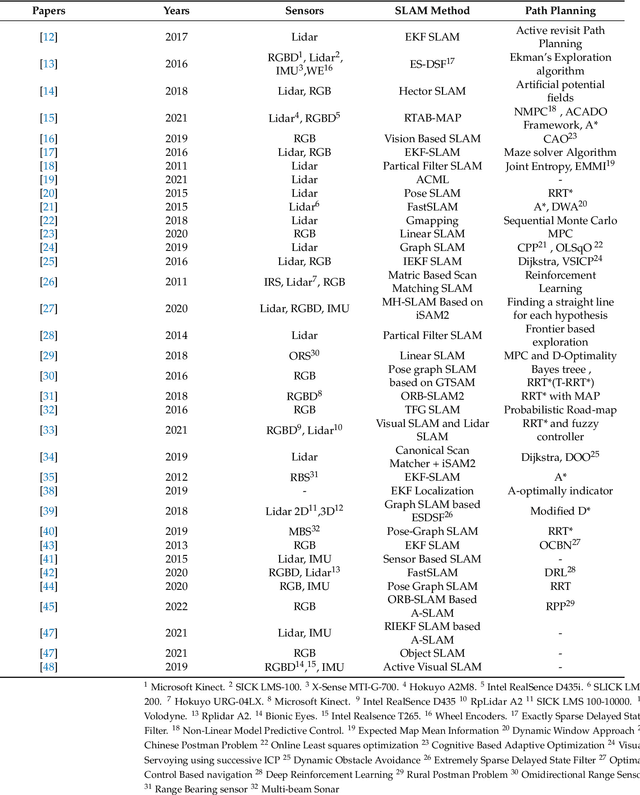
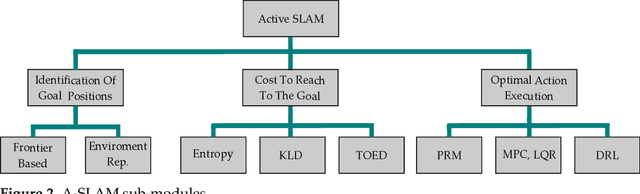
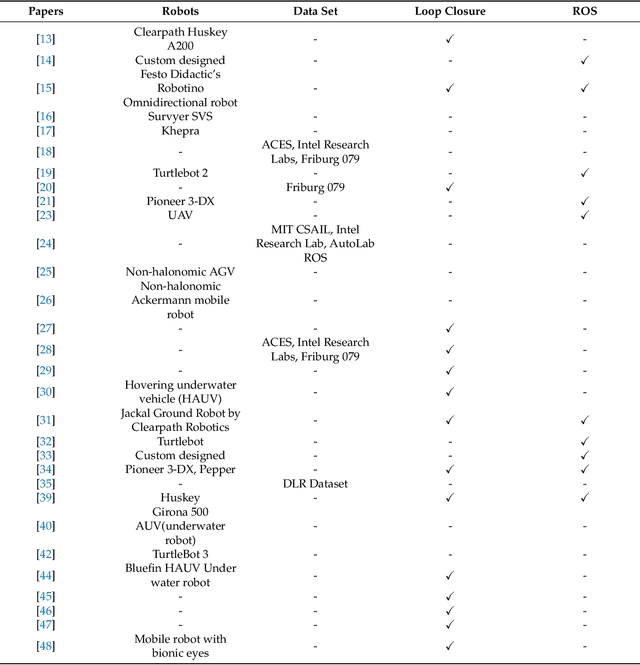
This article presents a novel review of Active SLAM (A-SLAM) research conducted in the last decade. We discuss the formulation, application, and methodology applied in A-SLAM for trajectory generation and control action selection using information theory based approaches. Our extensive qualitative and quantitative analysis highlights the approaches, scenarios, configurations, types of robots, sensor types, dataset usage, and path planning approaches of A-SLAM research. We conclude by presenting the limitations and proposing future research possibilities. We believe that this survey will be helpful to researchers in understanding the various methods and techniques applied to A-SLAM formulation.
Data-centric Artificial Intelligence
Dec 22, 2022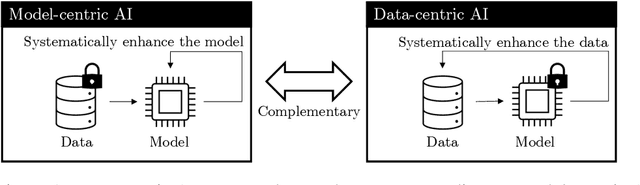
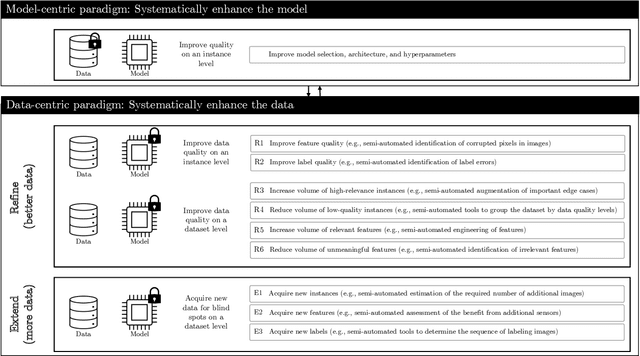
Data-centric artificial intelligence (data-centric AI) represents an emerging paradigm emphasizing that the systematic design and engineering of data is essential for building effective and efficient AI-based systems. The objective of this article is to introduce practitioners and researchers from the field of Information Systems (IS) to data-centric AI. We define relevant terms, provide key characteristics to contrast the data-centric paradigm to the model-centric one, and introduce a framework for data-centric AI. We distinguish data-centric AI from related concepts and discuss its longer-term implications for the IS community.
ILSGAN: Independent Layer Synthesis for Unsupervised Foreground-Background Segmentation
Nov 28, 2022
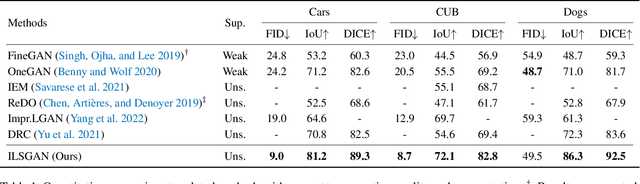
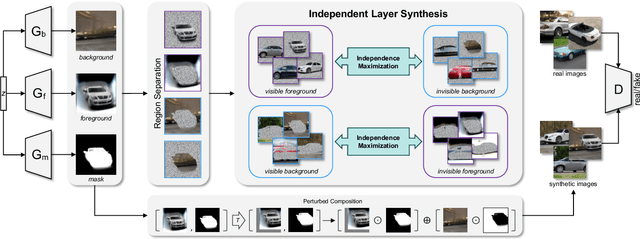
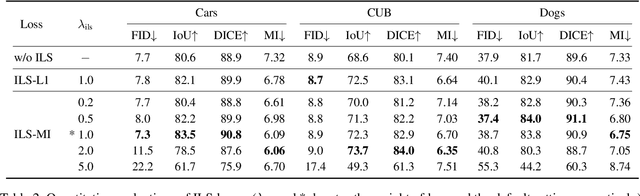
Unsupervised foreground-background segmentation aims at extracting salient objects from cluttered backgrounds, where Generative Adversarial Network (GAN) approaches, especially layered GANs, show great promise. However, without human annotations, they are typically prone to produce foreground and background layers with non-negligible semantic and visual confusion, dubbed "information leakage", resulting in notable degeneration of the generated segmentation mask. To alleviate this issue, we propose a simple-yet-effective explicit layer independence modeling approach, termed Independent Layer Synthesis GAN (ILSGAN), pursuing independent foreground-background layer generation by encouraging their discrepancy. Specifically, it targets minimizing the mutual information between visible and invisible regions of the foreground and background to spur interlayer independence. Through in-depth theoretical and experimental analyses, we justify that explicit layer independence modeling is critical to suppressing information leakage and contributes to impressive segmentation performance gains. Also, our ILSGAN achieves strong state-of-the-art generation quality and segmentation performance on complex real-world data.
Discovery of partial differential equations from highly noisy and sparse data with physics-informed information criterion
Aug 05, 2022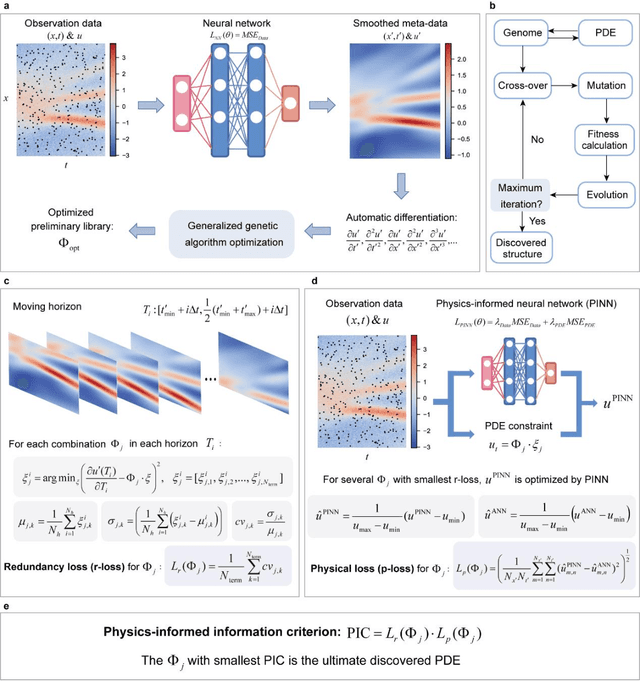
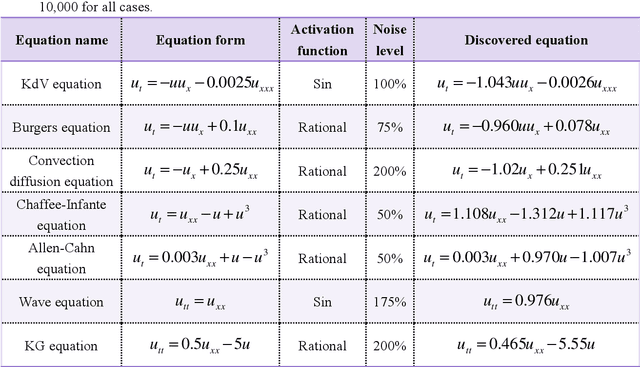
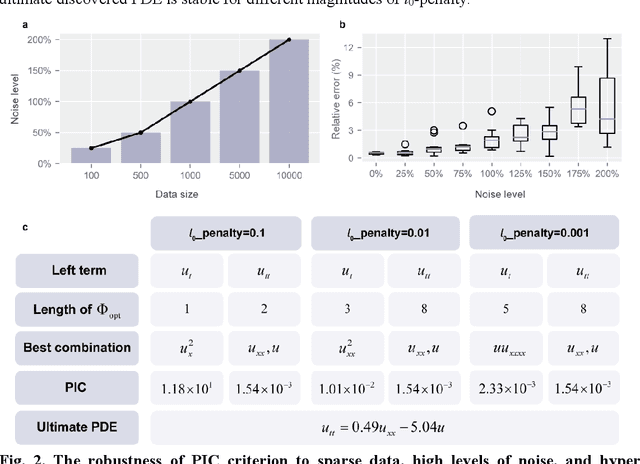

Data-driven discovery of PDEs has made tremendous progress recently, and many canonical PDEs have been discovered successfully for proof-of-concept. However, determining the most proper PDE without prior references remains challenging in terms of practical applications. In this work, a physics-informed information criterion (PIC) is proposed to measure the parsimony and precision of the discovered PDE synthetically. The proposed PIC achieves state-of-the-art robustness to highly noisy and sparse data on seven canonical PDEs from different physical scenes, which confirms its ability to handle difficult situations. The PIC is also employed to discover unrevealed macroscale governing equations from microscopic simulation data in an actual physical scene. The results show that the discovered macroscale PDE is precise and parsimonious, and satisfies underlying symmetries, which facilitates understanding and simulation of the physical process. The proposition of PIC enables practical applications of PDE discovery in discovering unrevealed governing equations in broader physical scenes.
Fair Ranking with Noisy Protected Attributes
Nov 30, 2022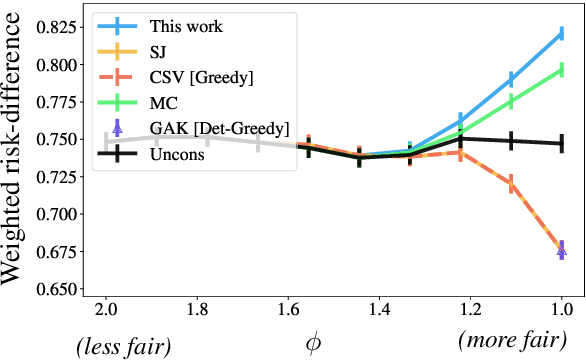
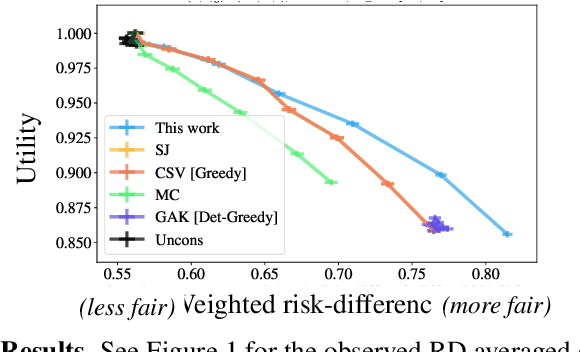
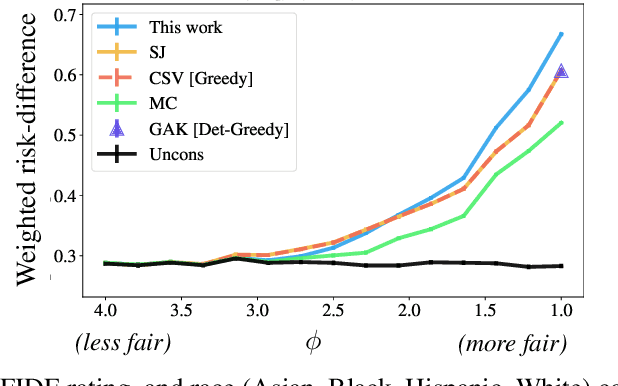
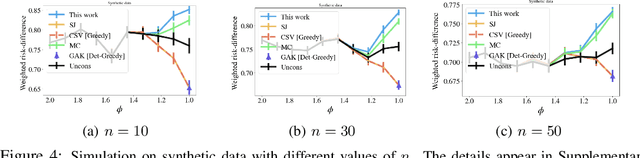
The fair-ranking problem, which asks to rank a given set of items to maximize utility subject to group fairness constraints, has received attention in the fairness, information retrieval, and machine learning literature. Recent works, however, observe that errors in socially-salient (including protected) attributes of items can significantly undermine fairness guarantees of existing fair-ranking algorithms and raise the problem of mitigating the effect of such errors. We study the fair-ranking problem under a model where socially-salient attributes of items are randomly and independently perturbed. We present a fair-ranking framework that incorporates group fairness requirements along with probabilistic information about perturbations in socially-salient attributes. We provide provable guarantees on the fairness and utility attainable by our framework and show that it is information-theoretically impossible to significantly beat these guarantees. Our framework works for multiple non-disjoint attributes and a general class of fairness constraints that includes proportional and equal representation. Empirically, we observe that, compared to baselines, our algorithm outputs rankings with higher fairness, and has a similar or better fairness-utility trade-off compared to baselines.
A Pre-Trained BERT Model for Android Applications
Dec 12, 2022

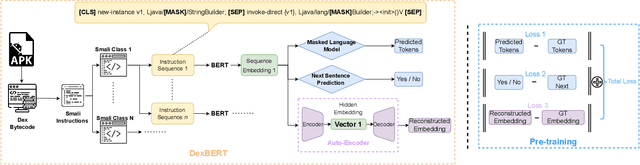
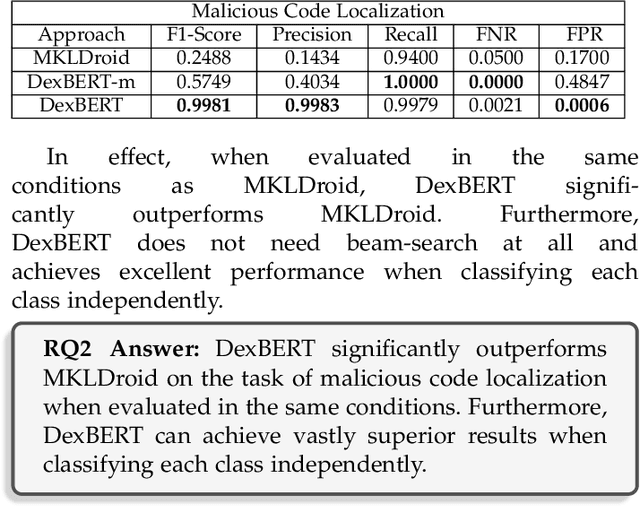
The automation of an increasingly large number of software engineering tasks is becoming possible thanks to Machine Learning (ML). One foundational building block in the application of ML to software artifacts is the representation of these artifacts (e.g., source code or executable code) into a form that is suitable for learning. Many studies have leveraged representation learning, delegating to ML itself the job of automatically devising suitable representations. Yet, in the context of Android problems, existing models are either limited to coarse-grained whole-app level (e.g., apk2vec) or conducted for one specific downstream task (e.g., smali2vec). Our work is part of a new line of research that investigates effective, task-agnostic, and fine-grained universal representations of bytecode to mitigate both of these two limitations. Such representations aim to capture information relevant to various low-level downstream tasks (e.g., at the class-level). We are inspired by the field of Natural Language Processing, where the problem of universal representation was addressed by building Universal Language Models, such as BERT, whose goal is to capture abstract semantic information about sentences, in a way that is reusable for a variety of tasks. We propose DexBERT, a BERT-like Language Model dedicated to representing chunks of DEX bytecode, the main binary format used in Android applications. We empirically assess whether DexBERT is able to model the DEX language and evaluate the suitability of our model in two distinct class-level software engineering tasks: Malicious Code Localization and Defect Prediction. We also experiment with strategies to deal with the problem of catering to apps having vastly different sizes, and we demonstrate one example of using our technique to investigate what information is relevant to a given task.