 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Visualizing the Relationship Between Encoded Linguistic Information and Task Performance
Mar 29, 2022
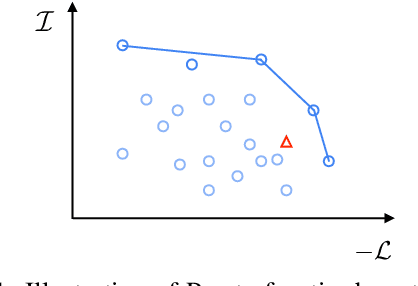
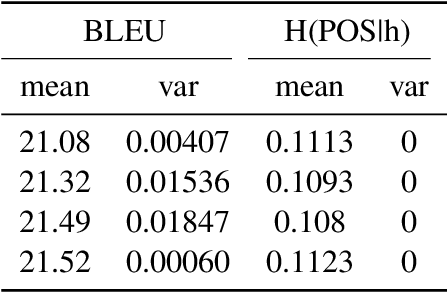
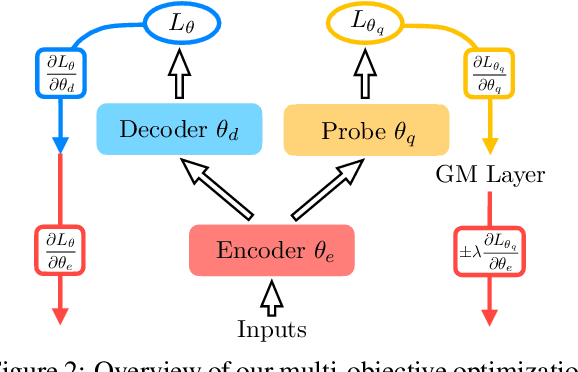
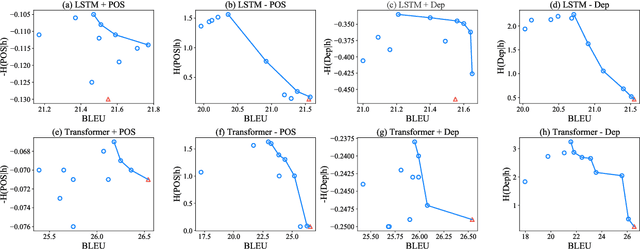
Probing is popular to analyze whether linguistic information can be captured by a well-trained deep neural model, but it is hard to answer how the change of the encoded linguistic information will affect task performance. To this end, we study the dynamic relationship between the encoded linguistic information and task performance from the viewpoint of Pareto Optimality. Its key idea is to obtain a set of models which are Pareto-optimal in terms of both objectives. From this viewpoint, we propose a method to optimize the Pareto-optimal models by formalizing it as a multi-objective optimization problem. We conduct experiments on two popular NLP tasks, i.e., machine translation and language modeling, and investigate the relationship between several kinds of linguistic information and task performances. Experimental results demonstrate that the proposed method is better than a baseline method. Our empirical findings suggest that some syntactic information is helpful for NLP tasks whereas encoding more syntactic information does not necessarily lead to better performance, because the model architecture is also an important factor.
The Distributed Information Bottleneck reveals the explanatory structure of complex systems
Apr 15, 2022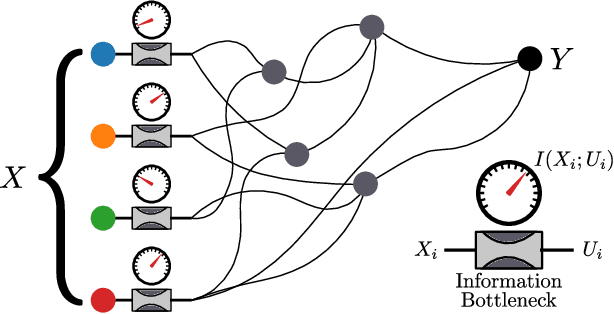
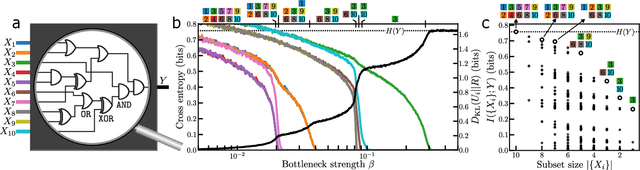
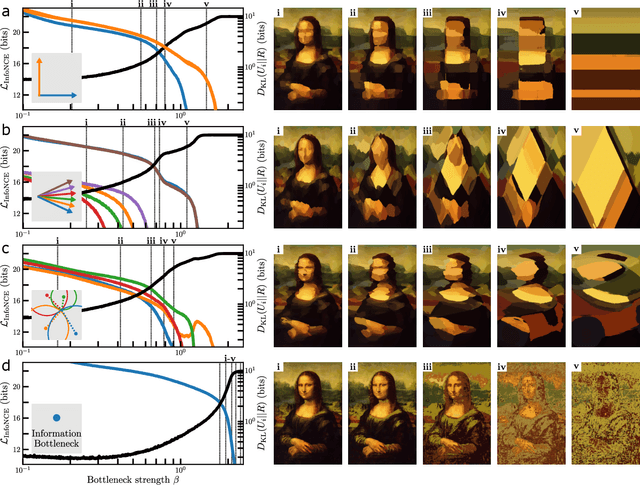
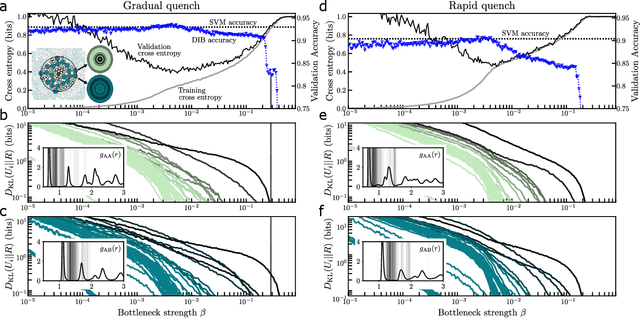
The fruits of science are relationships made comprehensible, often by way of approximation. While deep learning is an extremely powerful way to find relationships in data, its use in science has been hindered by the difficulty of understanding the learned relationships. The Information Bottleneck (IB) is an information theoretic framework for understanding a relationship between an input and an output in terms of a trade-off between the fidelity and complexity of approximations to the relationship. Here we show that a crucial modification -- distributing bottlenecks across multiple components of the input -- opens fundamentally new avenues for interpretable deep learning in science. The Distributed Information Bottleneck throttles the downstream complexity of interactions between the components of the input, deconstructing a relationship into meaningful approximations found through deep learning without requiring custom-made datasets or neural network architectures. Applied to a complex system, the approximations illuminate aspects of the system's nature by restricting -- and monitoring -- the information about different components incorporated into the approximation. We demonstrate the Distributed IB's explanatory utility in systems drawn from applied mathematics and condensed matter physics. In the former, we deconstruct a Boolean circuit into approximations that isolate the most informative subsets of input components without requiring exhaustive search. In the latter, we localize information about future plastic rearrangement in the static structure of a sheared glass, and find the information to be more or less diffuse depending on the system's preparation. By way of a principled scheme of approximations, the Distributed IB brings much-needed interpretability to deep learning and enables unprecedented analysis of information flow through a system.
Low-rank Tensor Assisted K-space Generative Model for Parallel Imaging Reconstruction
Dec 11, 2022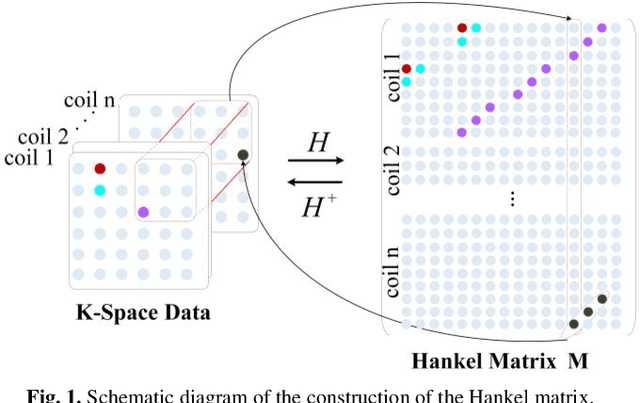
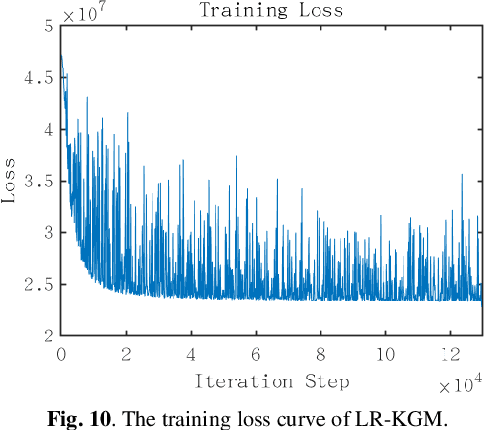
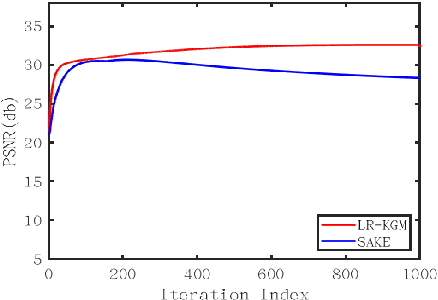
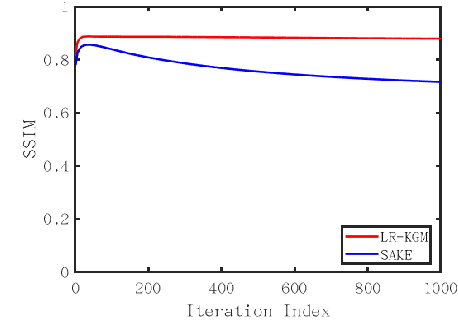
Although recent deep learning methods, especially generative models, have shown good performance in fast magnetic resonance imaging, there is still much room for improvement in high-dimensional generation. Considering that internal dimensions in score-based generative models have a critical impact on estimating the gradient of the data distribution, we present a new idea, low-rank tensor assisted k-space generative model (LR-KGM), for parallel imaging reconstruction. This means that we transform original prior information into high-dimensional prior information for learning. More specifically, the multi-channel data is constructed into a large Hankel matrix and the matrix is subsequently folded into tensor for prior learning. In the testing phase, the low-rank rotation strategy is utilized to impose low-rank constraints on tensor output of the generative network. Furthermore, we alternately use traditional generative iterations and low-rank high-dimensional tensor iterations for reconstruction. Experimental comparisons with the state-of-the-arts demonstrated that the proposed LR-KGM method achieved better performance.
Generalized Delayed Feedback Model with Post-Click Information in Recommender Systems
Jun 01, 2022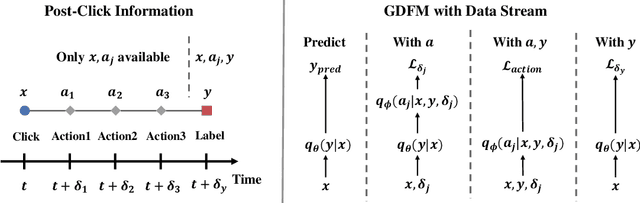
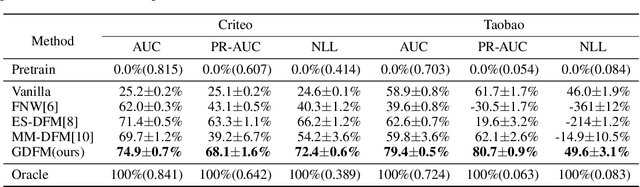
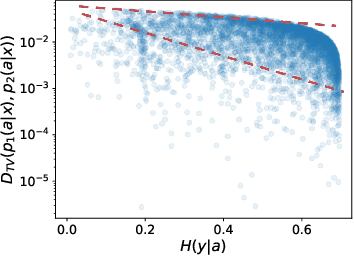
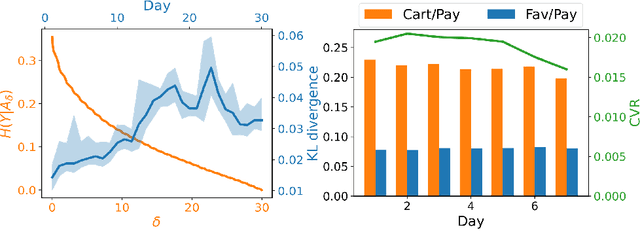
Predicting conversion rate (e.g., the probability that a user will purchase an item) is a fundamental problem in machine learning based recommender systems. However, accurate conversion labels are revealed after a long delay, which harms the timeliness of recommender systems. Previous literature concentrates on utilizing early conversions to mitigate such a delayed feedback problem. In this paper, we show that post-click user behaviors are also informative to conversion rate prediction and can be used to improve timeliness. We propose a generalized delayed feedback model (GDFM) that unifies both post-click behaviors and early conversions as stochastic post-click information, which could be utilized to train GDFM in a streaming manner efficiently. Based on GDFM, we further establish a novel perspective that the performance gap introduced by delayed feedback can be attributed to a temporal gap and a sampling gap. Inspired by our analysis, we propose to measure the quality of post-click information with a combination of temporal distance and sample complexity. The training objective is re-weighted accordingly to highlight informative and timely signals. We validate our analysis on public datasets, and experimental performance confirms the effectiveness of our method.
Dynamically Modular and Sparse General Continual Learning
Jan 02, 2023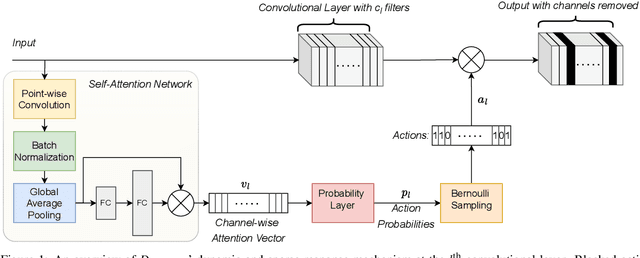
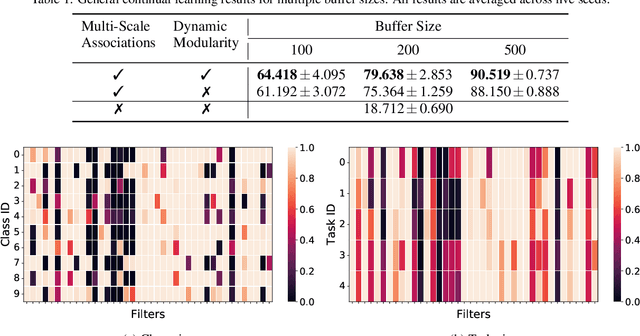
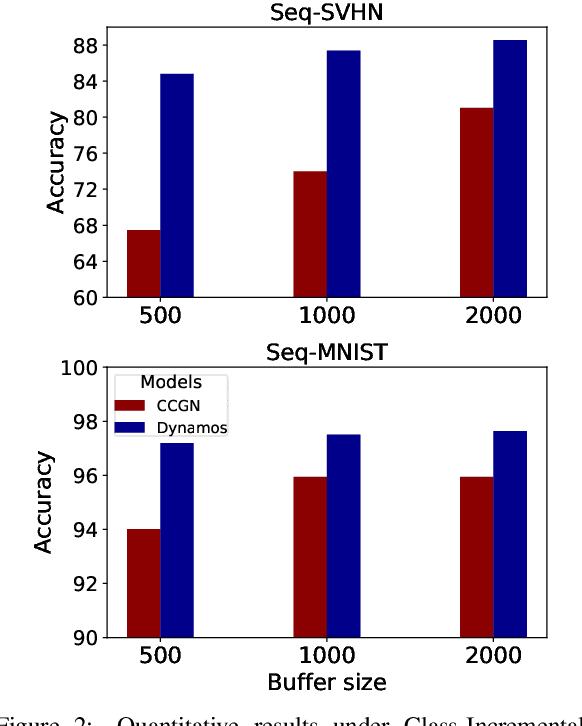
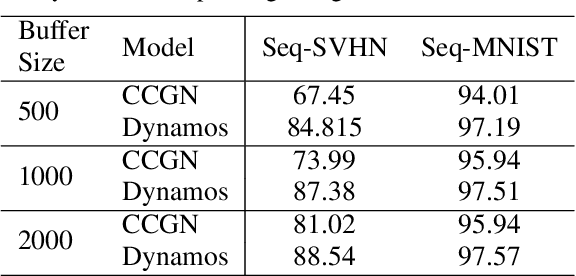
Real-world applications often require learning continuously from a stream of data under ever-changing conditions. When trying to learn from such non-stationary data, deep neural networks (DNNs) undergo catastrophic forgetting of previously learned information. Among the common approaches to avoid catastrophic forgetting, rehearsal-based methods have proven effective. However, they are still prone to forgetting due to task-interference as all parameters respond to all tasks. To counter this, we take inspiration from sparse coding in the brain and introduce dynamic modularity and sparsity (Dynamos) for rehearsal-based general continual learning. In this setup, the DNN learns to respond to stimuli by activating relevant subsets of neurons. We demonstrate the effectiveness of Dynamos on multiple datasets under challenging continual learning evaluation protocols. Finally, we show that our method learns representations that are modular and specialized, while maintaining reusability by activating subsets of neurons with overlaps corresponding to the similarity of stimuli.
Russia-Ukraine war: Modeling and Clustering the Sentiments Trends of Various Countries
Jan 02, 2023
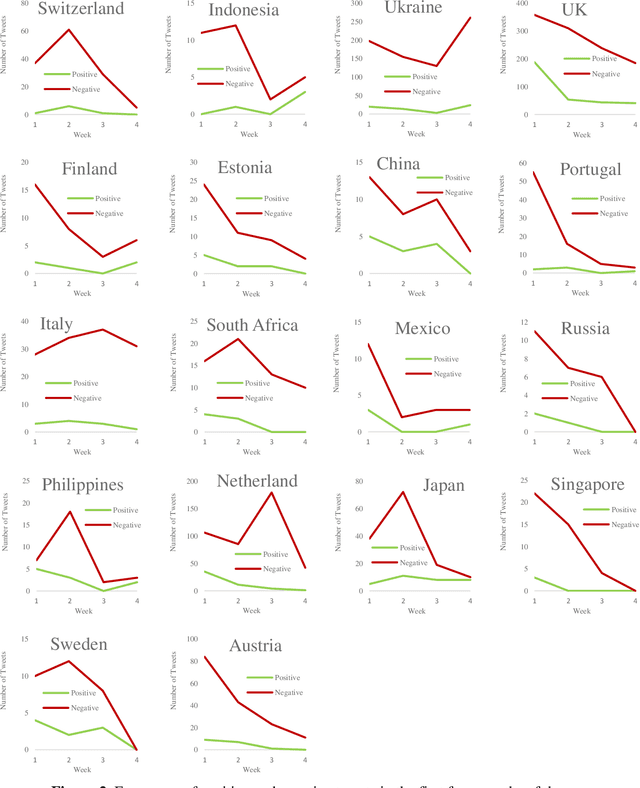
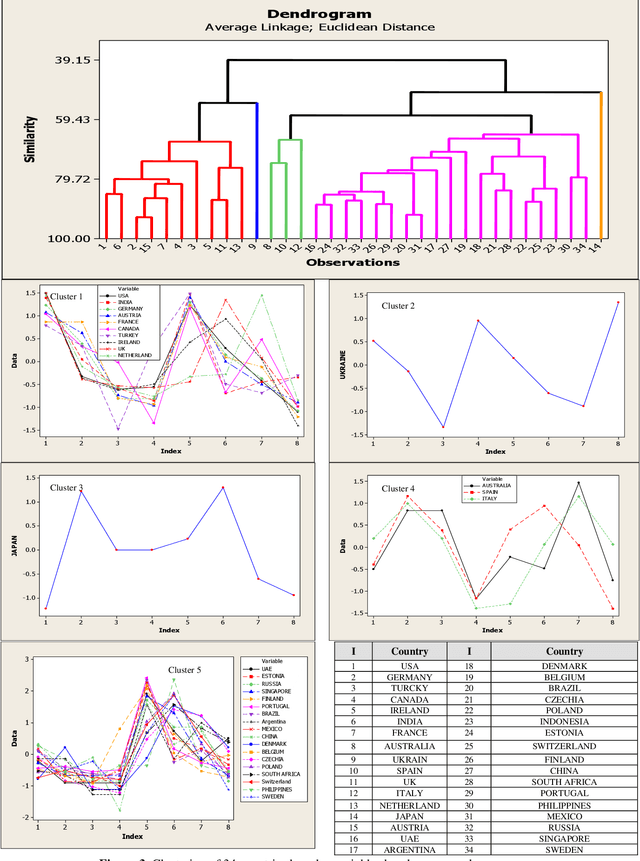
With Twitter's growth and popularity, a huge number of views are shared by users on various topics, making this platform a valuable information source on various political, social, and economic issues. This paper investigates English tweets on the Russia-Ukraine war to analyze trends reflecting users' opinions and sentiments regarding the conflict. The tweets' positive and negative sentiments are analyzed using a BERT-based model, and the time series associated with the frequency of positive and negative tweets for various countries is calculated. Then, we propose a method based on the neighborhood average for modeling and clustering the time series of countries. The clustering results provide valuable insight into public opinion regarding this conflict. Among other things, we can mention the similar thoughts of users from the United States, Canada, the United Kingdom, and most Western European countries versus the shared views of Eastern European, Scandinavian, Asian, and South American nations toward the conflict.
I2MVFormer: Large Language Model Generated Multi-View Document Supervision for Zero-Shot Image Classification
Dec 05, 2022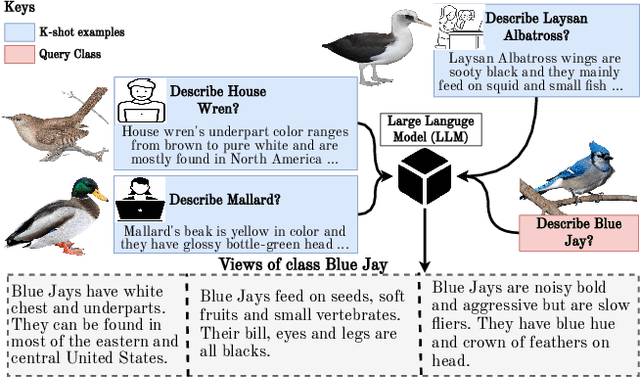
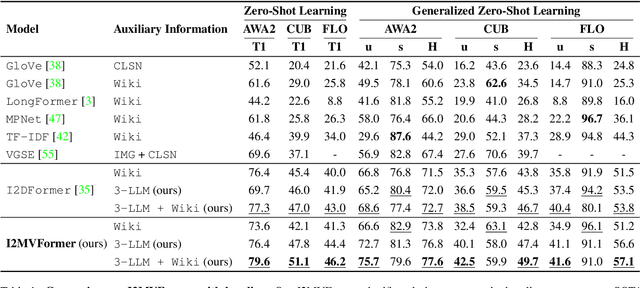
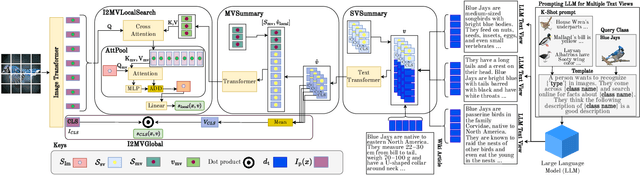

Recent works have shown that unstructured text (documents) from online sources can serve as useful auxiliary information for zero-shot image classification. However, these methods require access to a high-quality source like Wikipedia and are limited to a single source of information. Large Language Models (LLM) trained on web-scale text show impressive abilities to repurpose their learned knowledge for a multitude of tasks. In this work, we provide a novel perspective on using an LLM to provide text supervision for a zero-shot image classification model. The LLM is provided with a few text descriptions from different annotators as examples. The LLM is conditioned on these examples to generate multiple text descriptions for each class(referred to as views). Our proposed model, I2MVFormer, learns multi-view semantic embeddings for zero-shot image classification with these class views. We show that each text view of a class provides complementary information allowing a model to learn a highly discriminative class embedding. Moreover, we show that I2MVFormer is better at consuming the multi-view text supervision from LLM compared to baseline models. I2MVFormer establishes a new state-of-the-art on three public benchmark datasets for zero-shot image classification with unsupervised semantic embeddings.
A Survey on Conversational Search and Applications in Biomedicine
Nov 28, 2022
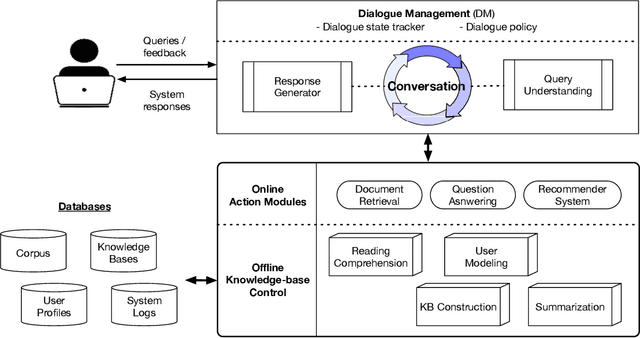
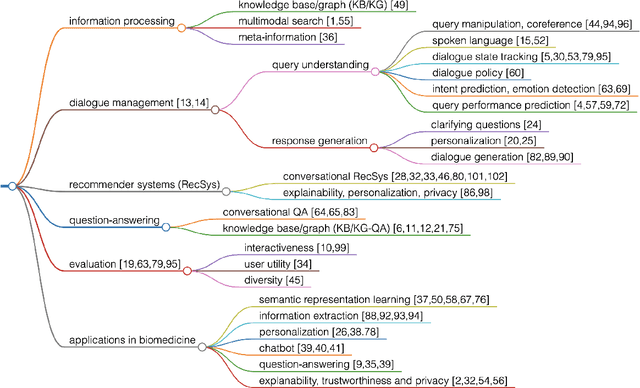
This paper aims to provide a radical rundown on Conversation Search (ConvSearch), an approach to enhance the information retrieval method where users engage in a dialogue for the information-seeking tasks. In this survey, we predominantly focused on the human interactive characteristics of the ConvSearch systems, highlighting the operations of the action modules, likely the Retrieval system, Question-Answering, and Recommender system. We labeled various ConvSearch research problems in knowledge bases, natural language processing, and dialogue management systems along with the action modules. We further categorized the framework to ConvSearch and the application is directed toward biomedical and healthcare fields for the utilization of clinical social technology. Finally, we conclude by talking through the challenges and issues of ConvSearch, particularly in Bio-Medicine. Our main aim is to provide an integrated and unified vision of the ConvSearch components from different fields, which benefit the information-seeking process in healthcare systems.
Named Entity and Relation Extraction with Multi-Modal Retrieval
Dec 03, 2022
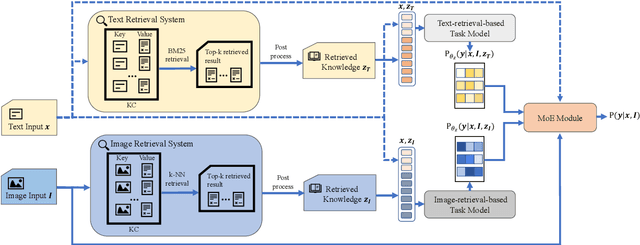
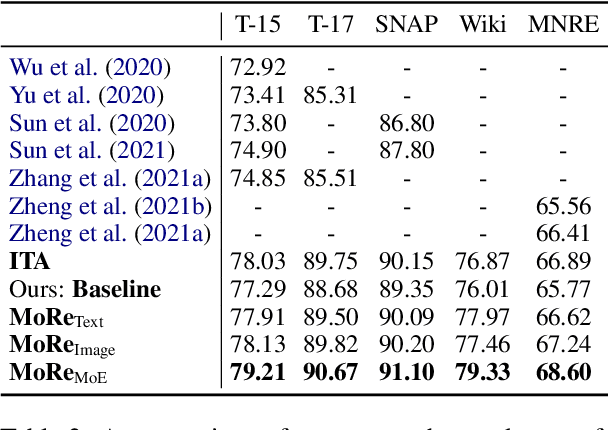
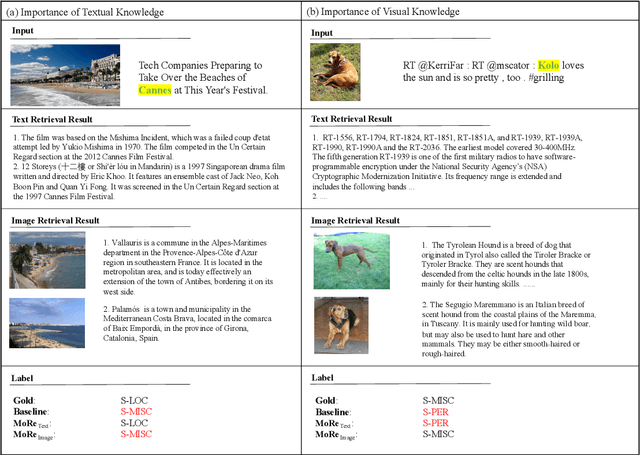
Multi-modal named entity recognition (NER) and relation extraction (RE) aim to leverage relevant image information to improve the performance of NER and RE. Most existing efforts largely focused on directly extracting potentially useful information from images (such as pixel-level features, identified objects, and associated captions). However, such extraction processes may not be knowledge aware, resulting in information that may not be highly relevant. In this paper, we propose a novel Multi-modal Retrieval based framework (MoRe). MoRe contains a text retrieval module and an image-based retrieval module, which retrieve related knowledge of the input text and image in the knowledge corpus respectively. Next, the retrieval results are sent to the textual and visual models respectively for predictions. Finally, a Mixture of Experts (MoE) module combines the predictions from the two models to make the final decision. Our experiments show that both our textual model and visual model can achieve state-of-the-art performance on four multi-modal NER datasets and one multi-modal RE dataset. With MoE, the model performance can be further improved and our analysis demonstrates the benefits of integrating both textual and visual cues for such tasks.
Computer Vision for Transit Travel Time Prediction: An End-to-End Framework Using Roadside Urban Imagery
Dec 13, 2022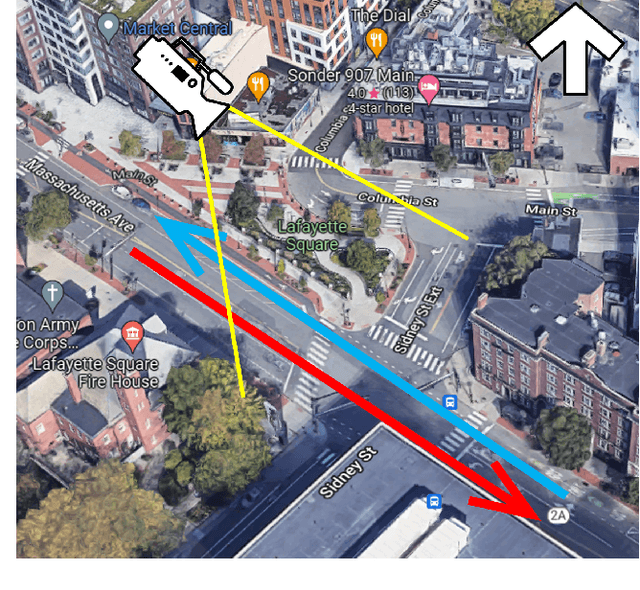


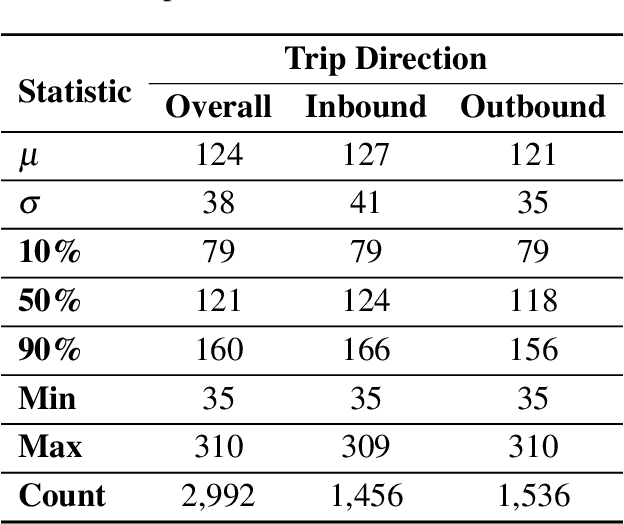
Accurate travel time estimation is paramount for providing transit users with reliable schedules and dependable real-time information. This paper is the first to utilize roadside urban imagery for direct transit travel time prediction. We propose and evaluate an end-to-end framework integrating traditional transit data sources with a roadside camera for automated roadside image data acquisition, labeling, and model training to predict transit travel times across a segment of interest. First, we show how the GTFS real-time data can be utilized as an efficient activation mechanism for a roadside camera unit monitoring a segment of interest. Second, AVL data is utilized to generate ground truth labels for the acquired images based on the observed transit travel time percentiles across the camera-monitored segment during the time of image acquisition. Finally, the generated labeled image dataset is used to train and thoroughly evaluate a Vision Transformer (ViT) model to predict a discrete transit travel time range (band). The results illustrate that the ViT model is able to learn image features and contents that best help it deduce the expected travel time range with an average validation accuracy ranging between 80%-85%. We assess the interpretability of the ViT model's predictions and showcase how this discrete travel time band prediction can subsequently improve continuous transit travel time estimation. The workflow and results presented in this study provide an end-to-end, scalable, automated, and highly efficient approach for integrating traditional transit data sources and roadside imagery to improve the estimation of transit travel duration. This work also demonstrates the value of incorporating real-time information from computer-vision sources, which are becoming increasingly accessible and can have major implications for improving operations and passenger real-time information.