 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Science Classroom Discourse Analysis through Joint Multi-Task Learning for Reasoning-Component Classification
Apr 22, 2026Analyzing the reasoning patterns of students in science classrooms is critical for understanding knowledge construction mechanism and improving instructional practice to maximize cognitive engagement, yet manual coding of classroom discourse at scale remains prohibitively labor-intensive. We present an automated discourse analysis system (ADAS) that jointly classifies teacher and student utterances along two complementary dimensions: Utterance Type and Reasoning Component derived from our prior CDAT framework. To address severe label imbalance among minority classes, we (1) stratify-resplit the annotated corpus, (2) apply LLM-based synthetic data augmentation targeting minority classes, and (3) train a dual-probe head RoBERTa-base classifier. A zero-shot GPT-5.4 baseline achieves macro-F1 of 0.467 on UT and 0.476 on RC, establishing meaningful upper bounds for prompt-only approaches motivating fine-tuning. Beyond classification, we conduct discourse pattern analyses including UTxRC co-occurrence profiling, Cognitive Complexity Index (CCI) computation per session, lag-sequential analysis, and IRF chain analysis, revealing that teacher Feedback-with-Question (Fq) moves are the most consistent antecedents of student inferential reasoning (SR-I). Our results demonstrate that LLM-based augmentation meaningfully improves UT minority-class recognition, and that the structural simplicity of the RC task makes it tractable even for lexical baselines.
Automated Domain Question Mapping (DQM) with Educational Learning Materials
Jan 11, 2026Concept maps have been widely utilized in education to depict knowledge structures and the interconnections between disciplinary concepts. Nonetheless, devising a computational method for automatically constructing a concept map from unstructured educational materials presents challenges due to the complexity and variability of educational content. We focus primarily on two challenges: (1) the lack of disciplinary concepts that are specifically designed for multi-level pedagogical purposes from low-order to high-order thinking, and (2) the limited availability of labeled data concerning disciplinary concepts and their interrelationships. To tackle these challenges, this research introduces an innovative approach for constructing Domain Question Maps (DQMs), rather than traditional concept maps. By formulating specific questions aligned with learning objectives, DQMs enhance knowledge representation and improve readiness for learner engagement. The findings indicate that the proposed method can effectively generate educational questions and discern hierarchical relationships among them, leading to structured question maps that facilitate personalized and adaptive learning in downstream applications.
YouLeQD: Decoding the Cognitive Complexity of Questions and Engagement in Online Educational Videos from Learners' Perspectives
Jan 20, 2025Questioning is a fundamental aspect of education, as it helps assess students' understanding, promotes critical thinking, and encourages active engagement. With the rise of artificial intelligence in education, there is a growing interest in developing intelligent systems that can automatically generate and answer questions and facilitate interactions in both virtual and in-person education settings. However, to develop effective AI models for education, it is essential to have a fundamental understanding of questioning. In this study, we created the YouTube Learners' Questions on Bloom's Taxonomy Dataset (YouLeQD), which contains learner-posed questions from YouTube lecture video comments. Along with the dataset, we developed two RoBERTa-based classification models leveraging Large Language Models to detect questions and analyze their cognitive complexity using Bloom's Taxonomy. This dataset and our findings provide valuable insights into the cognitive complexity of learner-posed questions in educational videos and their relationship with interaction metrics. This can aid in the development of more effective AI models for education and improve the overall learning experience for students.
A Survey on Conversational Search and Applications in Biomedicine
Nov 28, 2022


This paper aims to provide a radical rundown on Conversation Search (ConvSearch), an approach to enhance the information retrieval method where users engage in a dialogue for the information-seeking tasks. In this survey, we predominantly focused on the human interactive characteristics of the ConvSearch systems, highlighting the operations of the action modules, likely the Retrieval system, Question-Answering, and Recommender system. We labeled various ConvSearch research problems in knowledge bases, natural language processing, and dialogue management systems along with the action modules. We further categorized the framework to ConvSearch and the application is directed toward biomedical and healthcare fields for the utilization of clinical social technology. Finally, we conclude by talking through the challenges and issues of ConvSearch, particularly in Bio-Medicine. Our main aim is to provide an integrated and unified vision of the ConvSearch components from different fields, which benefit the information-seeking process in healthcare systems.
Improved Biomedical Word Embeddings in the Transformer Era
Dec 24, 2020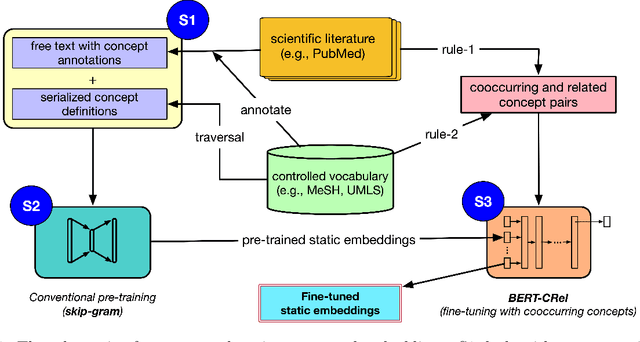

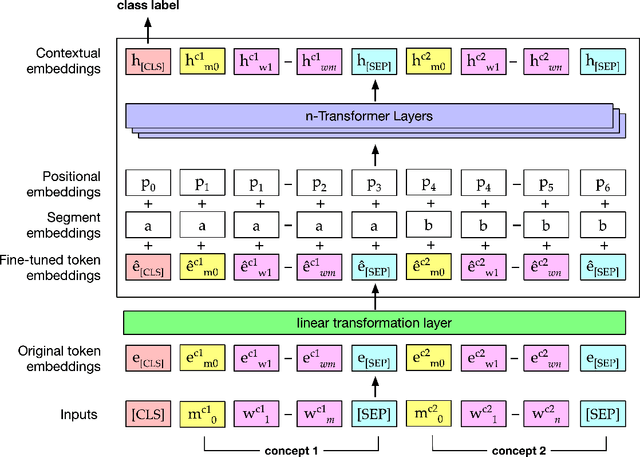
Biomedical word embeddings are usually pre-trained on free text corpora with neural methods that capture local and global distributional properties. They are leveraged in downstream tasks using various neural architectures that are designed to optimize task-specific objectives that might further tune such embeddings. Since 2018, however, there is a marked shift from these static embeddings to contextual embeddings motivated by language models (e.g., ELMo, transformers such as BERT, and ULMFiT). These dynamic embeddings have the added benefit of being able to distinguish homonyms and acronyms given their context. However, static embeddings are still relevant in low resource settings (e.g., smart devices, IoT elements) and to study lexical semantics from a computational linguistics perspective. In this paper, we jointly learn word and concept embeddings by first using the skip-gram method and further fine-tuning them with correlational information manifesting in co-occurring Medical Subject Heading (MeSH) concepts in biomedical citations. This fine-tuning is accomplished with the BERT transformer architecture in the two-sentence input mode with a classification objective that captures MeSH pair co-occurrence. In essence, we repurpose a transformer architecture (typically used to generate dynamic embeddings) to improve static embeddings using concept correlations. We conduct evaluations of these tuned static embeddings using multiple datasets for word relatedness developed by previous efforts. Without selectively culling concepts and terms (as was pursued by previous efforts), we believe we offer the most exhaustive evaluation of static embeddings to date with clear performance improvements across the board. We provide our code and embeddings for public use for downstream applications and research endeavors: https://github.com/bionlproc/BERT-CRel-Embeddings
Literature Retrieval for Precision Medicine with Neural Matching and Faceted Summarization
Dec 17, 2020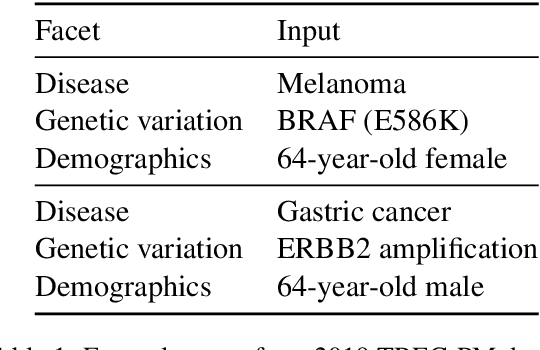
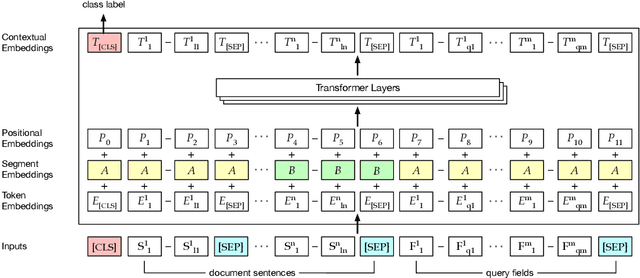
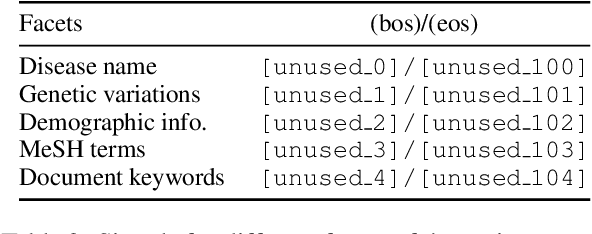
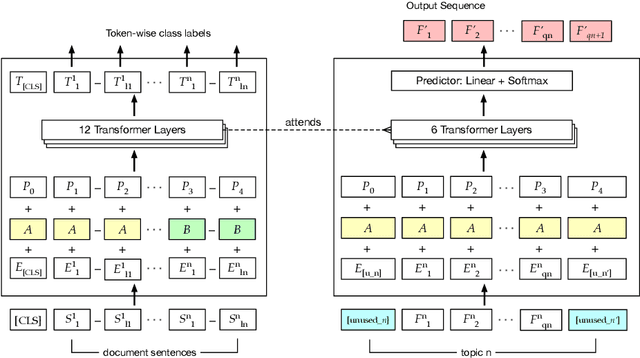
Information retrieval (IR) for precision medicine (PM) often involves looking for multiple pieces of evidence that characterize a patient case. This typically includes at least the name of a condition and a genetic variation that applies to the patient. Other factors such as demographic attributes, comorbidities, and social determinants may also be pertinent. As such, the retrieval problem is often formulated as ad hoc search but with multiple facets (e.g., disease, mutation) that may need to be incorporated. In this paper, we present a document reranking approach that combines neural query-document matching and text summarization toward such retrieval scenarios. Our architecture builds on the basic BERT model with three specific components for reranking: (a). document-query matching (b). keyword extraction and (c). facet-conditioned abstractive summarization. The outcomes of (b) and (c) are used to essentially transform a candidate document into a concise summary that can be compared with the query at hand to compute a relevance score. Component (a) directly generates a matching score of a candidate document for a query. The full architecture benefits from the complementary potential of document-query matching and the novel document transformation approach based on summarization along PM facets. Evaluations using NIST's TREC-PM track datasets (2017--2019) show that our model achieves state-of-the-art performance. To foster reproducibility, our code is made available here: https://github.com/bionlproc/text-summ-for-doc-retrieval.