 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Context-Aware Target Classification with Hybrid Gaussian Process prediction for Cooperative Vehicle Safety systems
Dec 24, 2022
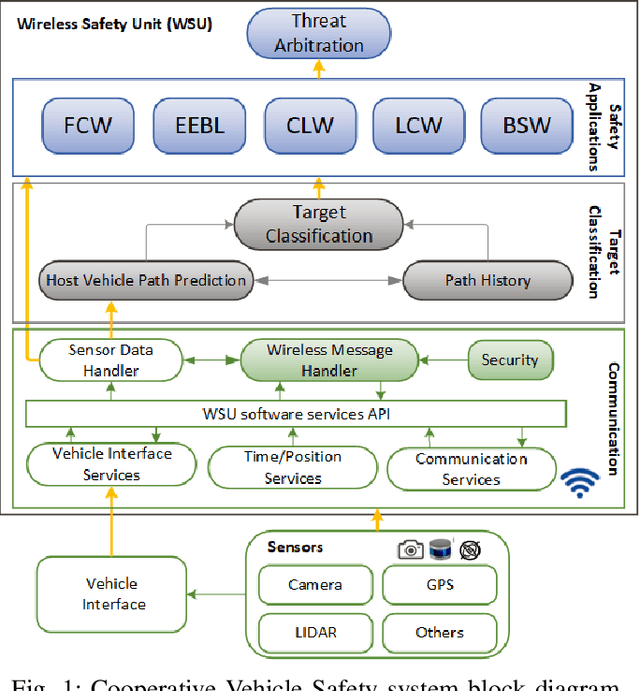
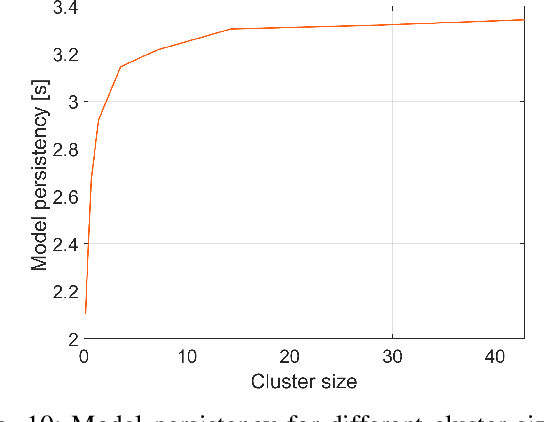
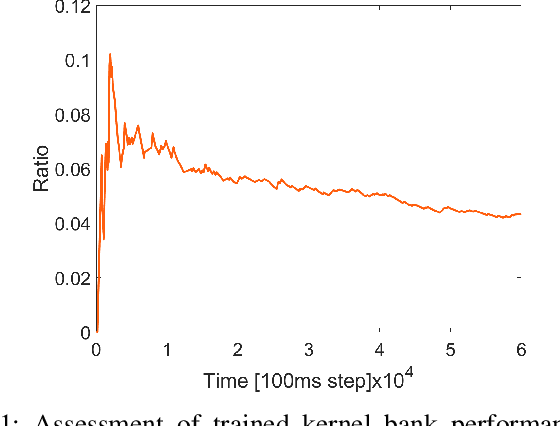
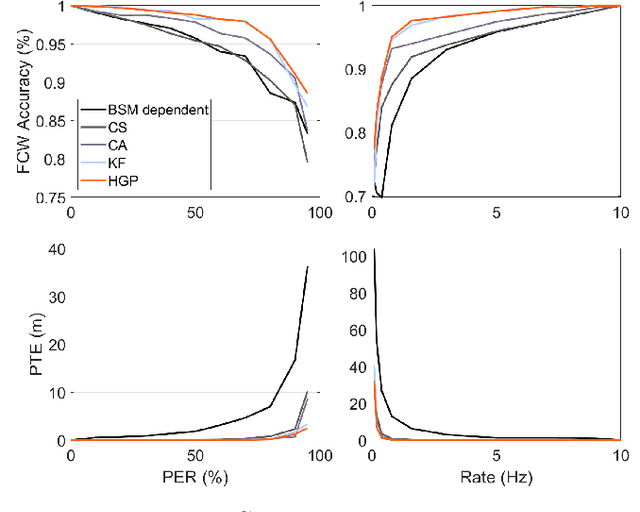
Vehicle-to-Everything (V2X) communication has been proposed as a potential solution to improve the robustness and safety of autonomous vehicles by improving coordination and removing the barrier of non-line-of-sight sensing. Cooperative Vehicle Safety (CVS) applications are tightly dependent on the reliability of the underneath data system, which can suffer from loss of information due to the inherent issues of their different components, such as sensors failures or the poor performance of V2X technologies under dense communication channel load. Particularly, information loss affects the target classification module and, subsequently, the safety application performance. To enable reliable and robust CVS systems that mitigate the effect of information loss, we proposed a Context-Aware Target Classification (CA-TC) module coupled with a hybrid learning-based predictive modeling technique for CVS systems. The CA-TC consists of two modules: A Context-Aware Map (CAM), and a Hybrid Gaussian Process (HGP) prediction system. Consequently, the vehicle safety applications use the information from the CA-TC, making them more robust and reliable. The CAM leverages vehicles path history, road geometry, tracking, and prediction; and the HGP is utilized to provide accurate vehicles' trajectory predictions to compensate for data loss (due to communication congestion) or sensor measurements' inaccuracies. Based on offline real-world data, we learn a finite bank of driver models that represent the joint dynamics of the vehicle and the drivers' behavior. We combine offline training and online model updates with on-the-fly forecasting to account for new possible driver behaviors. Finally, our framework is validated using simulation and realistic driving scenarios to confirm its potential in enhancing the robustness and reliability of CVS systems.
InstaGraM: Instance-level Graph Modeling for Vectorized HD Map Learning
Jan 10, 2023
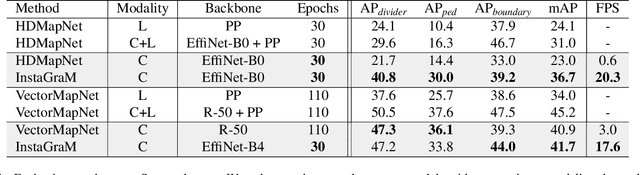
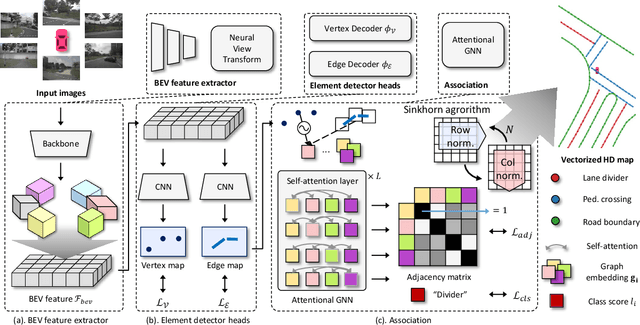
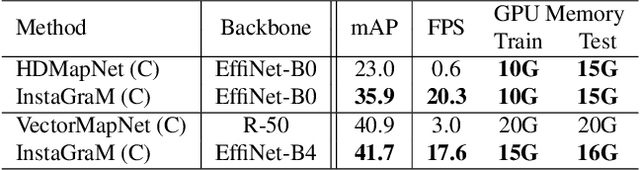
The construction of lightweight High-definition (HD) maps containing geometric and semantic information is of foremost importance for the large-scale deployment of autonomous driving. To automatically generate such type of map from a set of images captured by a vehicle, most works formulate this mapping as a segmentation problem, which implies heavy post-processing to obtain the final vectorized representation. Alternative techniques have the ability to generate an HD map in an end-to-end manner but rely on computationally expensive auto-regressive models. To bring camera-based to an applicable level, we propose InstaGraM, a fast end-to-end network generating a vectorized HD map via instance-level graph modeling of the map elements. Our strategy consists of three main stages: top-view feature extraction, road elements' vertices and edges detection, and conversion to a semantic vector representation. After top-down feature extraction, an encoder-decoder architecture is utilized to predict a set of vertices and edge maps of the road elements. Finally, these vertices along with edge maps are associated through an attentional graph neural network generating a semantic vectorized map. Instead of relying on a common segmentation approach, we propose to regress distance transform maps as they provide strong spatial relations and directional information between vertices. Comprehensive experiments on nuScenes dataset show that our proposed network outperforms HDMapNet by 13.7 mAP and achieves comparable accuracy with VectorMapNet 5x faster inference speed.
Time-aware Hyperbolic Graph Attention Network for Session-based Recommendation
Jan 10, 2023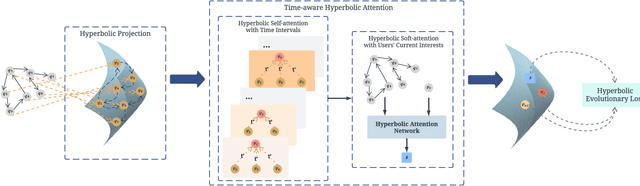


Session-based Recommendation (SBR) is to predict users' next interested items based on their previous browsing sessions. Existing methods model sessions as graphs or sequences to estimate user interests based on their interacted items to make recommendations. In recent years, graph-based methods have achieved outstanding performance on SBR. However, none of these methods consider temporal information, which is a crucial feature in SBR as it indicates timeliness or currency. Besides, the session graphs exhibit a hierarchical structure and are demonstrated to be suitable in hyperbolic geometry. But few papers design the models in hyperbolic spaces and this direction is still under exploration. In this paper, we propose Time-aware Hyperbolic Graph Attention Network (TA-HGAT) - a novel hyperbolic graph neural network framework to build a session-based recommendation model considering temporal information. More specifically, there are three components in TA-HGAT. First, a hyperbolic projection module transforms the item features into hyperbolic space. Second, the time-aware graph attention module models time intervals between items and the users' current interests. Third, an evolutionary loss at the end of the model provides an accurate prediction of the recommended item based on the given timestamp. TA-HGAT is built in a hyperbolic space to learn the hierarchical structure of session graphs. Experimental results show that the proposed TA-HGAT has the best performance compared to ten baseline models on two real-world datasets.
Membership Inference Attacks Against Latent Factor Model
Dec 15, 2022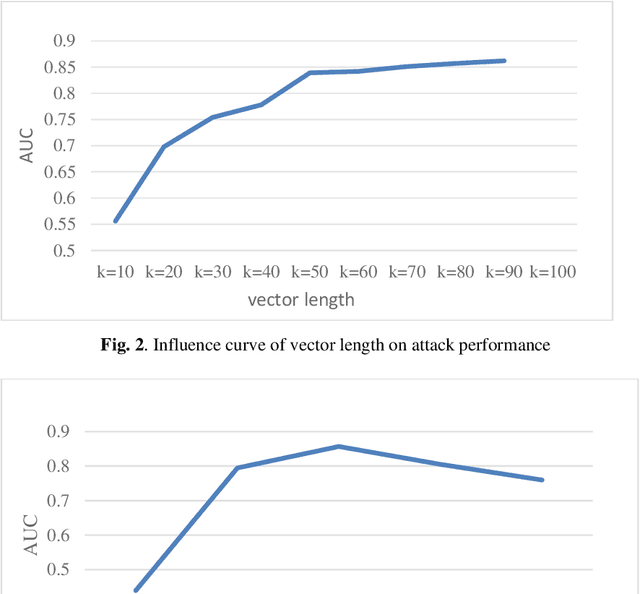
The advent of the information age has led to the problems of information overload and unclear demands. As an information filtering system, personalized recommendation systems predict users' behavior and preference for items and improves users' information acquisition efficiency. However, recommendation systems usually use highly sensitive user data for training. In this paper, we use the latent factor model as the recommender to get the list of recommended items, and we representing users from relevant items Compared with the traditional member inference against machine learning classifiers. We construct a multilayer perceptron model with two hidden layers as the attack model to complete the member inference. Moreover, a shadow recommender is established to derive the labeled training data for the attack model. The attack model is trained on the dataset generated by the shadow recommender and tested on the dataset generated by the target recommender. The experimental data show that the AUC index of our attack model can reach 0.857 on the real dataset MovieLens, which shows that the attack model has good performance.
Investigating Strategies for Clause Recommendation
Jan 21, 2023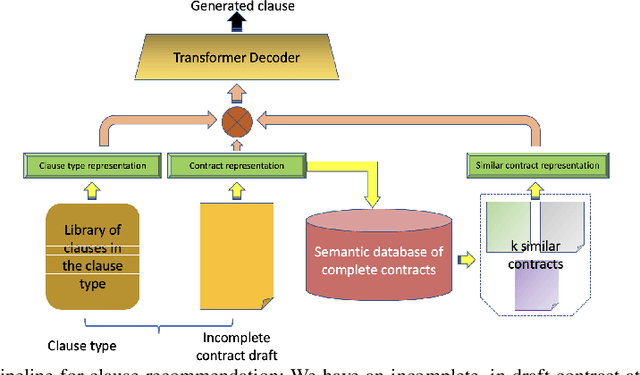
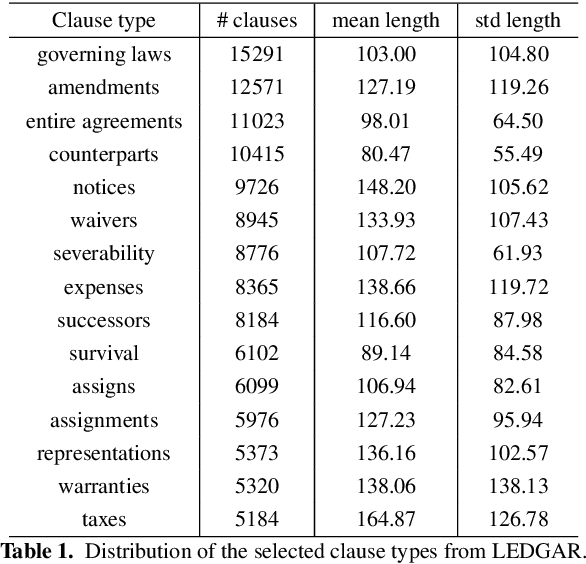
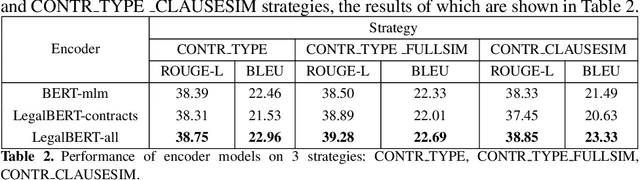
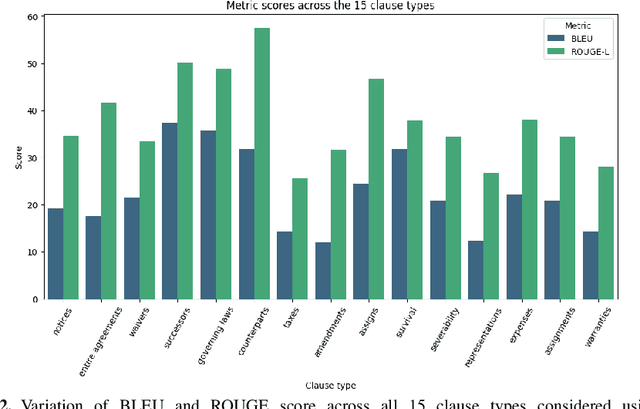
Clause recommendation is the problem of recommending a clause to a legal contract, given the context of the contract in question and the clause type to which the clause should belong. With not much prior work being done toward the generation of legal contracts, this problem was proposed as a first step toward the bigger problem of contract generation. As an open-ended text generation problem, the distinguishing characteristics of this problem lie in the nature of legal language as a sublanguage and the considerable similarity of textual content within the clauses of a specific type. This similarity aspect in legal clauses drives us to investigate the importance of similar contracts' representation for recommending clauses. In our work, we experiment with generating clauses for 15 commonly occurring clause types in contracts expanding upon the previous work on this problem and analyzing clause recommendations in varying settings using information derived from similar contracts.
* Published in Legal Knowledge and Information Systems (JURIX) 2022. (10 pages, 4 figures)
Is Signed Message Essential for Graph Neural Networks?
Jan 21, 2023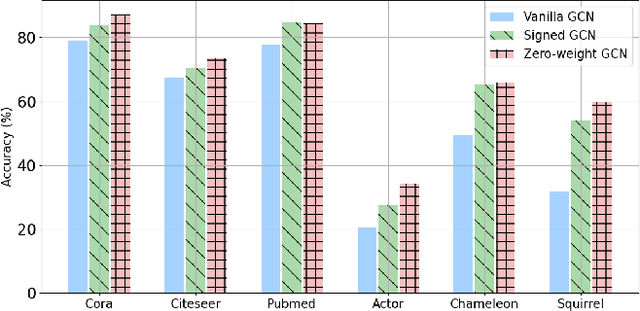

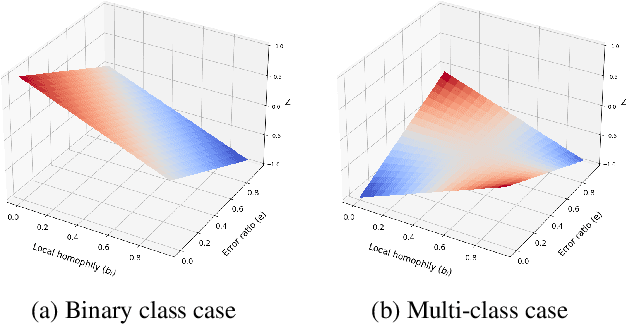
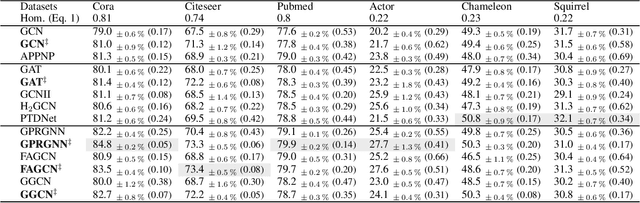
Message-passing Graph Neural Networks (GNNs), which collect information from adjacent nodes, achieve satisfying results on homophilic graphs. However, their performances are dismal in heterophilous graphs, and many researchers have proposed a plethora of schemes to solve this problem. Especially, flipping the sign of edges is rooted in a strong theoretical foundation, and attains significant performance enhancements. Nonetheless, previous analyses assume a binary class scenario and they may suffer from confined applicability. This paper extends the prior understandings to multi-class scenarios and points out two drawbacks: (1) the sign of multi-hop neighbors depends on the message propagation paths and may incur inconsistency, (2) it also increases the prediction uncertainty (e.g., conflict evidence) which can impede the stability of the algorithm. Based on the theoretical understanding, we introduce a novel strategy that is applicable to multi-class graphs. The proposed scheme combines confidence calibration to secure robustness while reducing uncertainty. We show the efficacy of our theorem through extensive experiments on six benchmark graph datasets.
Unifying Structure Reasoning and Language Model Pre-training for Complex Reasoning
Jan 21, 2023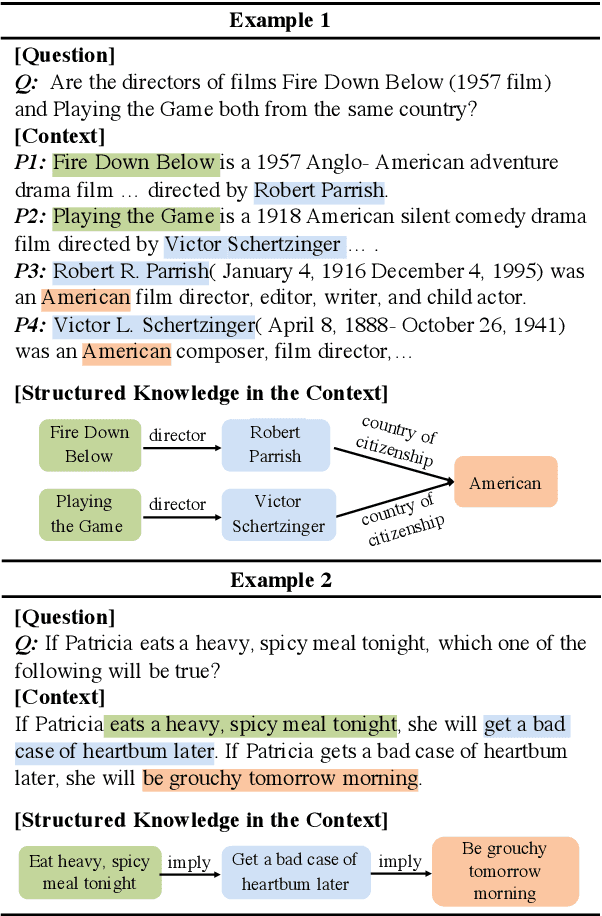
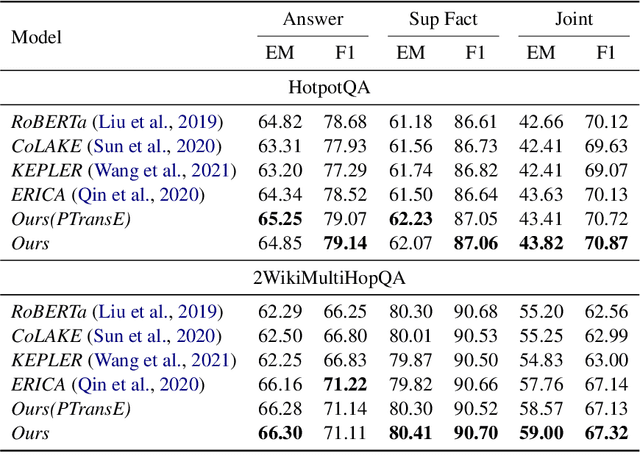

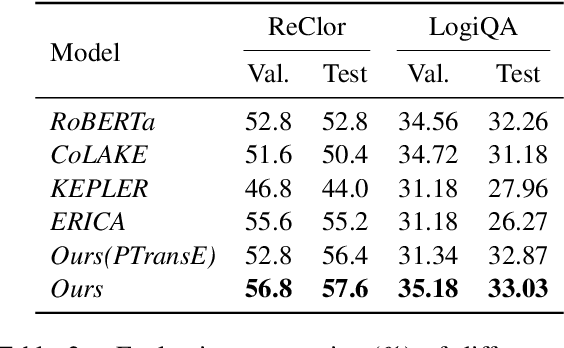
Recent knowledge enhanced pre-trained language models have shown remarkable performance on downstream tasks by incorporating structured knowledge from external sources into language models. However, they usually suffer from a heterogeneous information alignment problem and a noisy knowledge injection problem. For complex reasoning, the contexts contain rich knowledge that typically exists in complex and sparse forms. In order to model structured knowledge in the context and avoid these two problems, we propose to unify structure reasoning and language model pre-training. It identifies four types of elementary knowledge structures from contexts to construct structured queries, and utilizes the box embedding method to conduct explicit structure reasoning along queries during language modeling. To fuse textual and structured semantics, we utilize contextual language representations of knowledge structures to initialize their box embeddings for structure reasoning. We conduct experiments on complex language reasoning and knowledge graph (KG) reasoning tasks. The results show that our model can effectively enhance the performance of complex reasoning of both language and KG modalities.
Robust Transformer with Locality Inductive Bias and Feature Normalization
Jan 27, 2023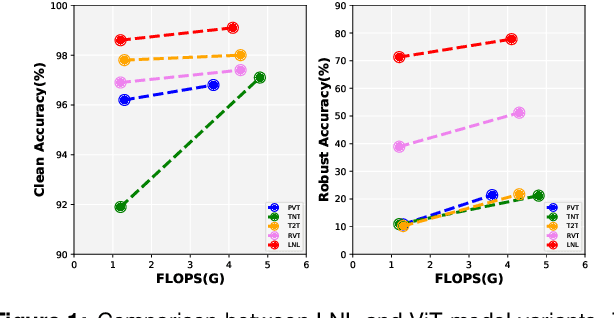
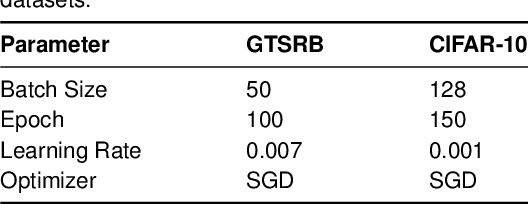
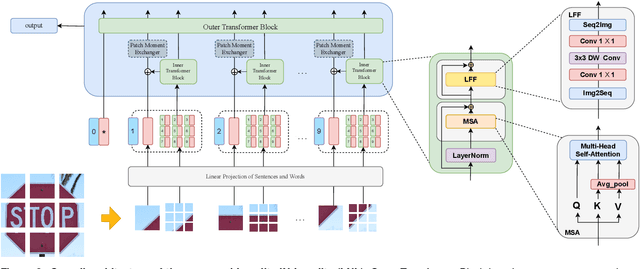
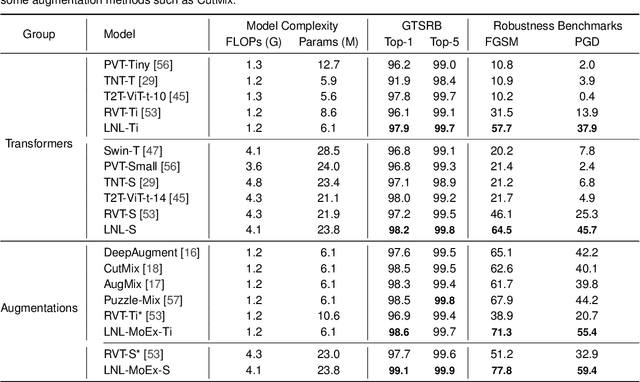
Vision transformers have been demonstrated to yield state-of-the-art results on a variety of computer vision tasks using attention-based networks. However, research works in transformers mostly do not investigate robustness/accuracy trade-off, and they still struggle to handle adversarial perturbations. In this paper, we explore the robustness of vision transformers against adversarial perturbations and try to enhance their robustness/accuracy trade-off in white box attack settings. To this end, we propose Locality iN Locality (LNL) transformer model. We prove that the locality introduction to LNL contributes to the robustness performance since it aggregates local information such as lines, edges, shapes, and even objects. In addition, to further improve the robustness performance, we encourage LNL to extract training signal from the moments (a.k.a., mean and standard deviation) and the normalized features. We validate the effectiveness and generality of LNL by achieving state-of-the-art results in terms of accuracy and robustness metrics on German Traffic Sign Recognition Benchmark (GTSRB) and Canadian Institute for Advanced Research (CIFAR-10). More specifically, for traffic sign classification, the proposed LNL yields gains of 1.1% and ~35% in terms of clean and robustness accuracy compared to the state-of-the-art studies.
* 9 pages, 3 Figures, 6 Tables
ARiADNE: A Reinforcement learning approach using Attention-based Deep Networks for Exploration
Jan 27, 2023
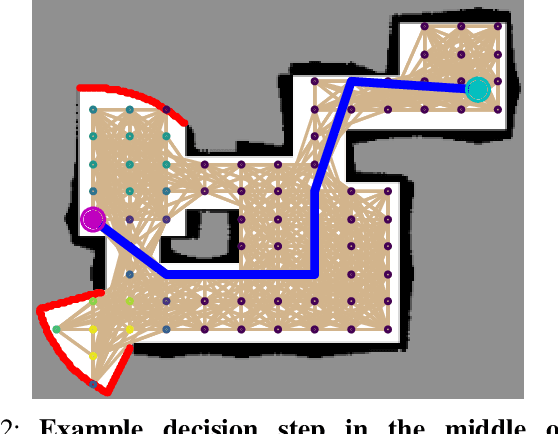
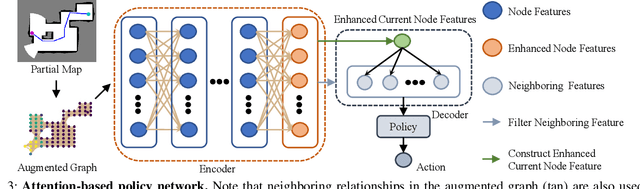

In autonomous robot exploration tasks, a mobile robot needs to actively explore and map an unknown environment as fast as possible. Since the environment is being revealed during exploration, the robot needs to frequently re-plan its path online, as new information is acquired by onboard sensors and used to update its partial map. While state-of-the-art exploration planners are frontier- and sampling-based, encouraged by the recent development in deep reinforcement learning (DRL), we propose ARiADNE, an attention-based neural approach to obtain real-time, non-myopic path planning for autonomous exploration. ARiADNE is able to learn dependencies at multiple spatial scales between areas of the agent's partial map, and implicitly predict potential gains associated with exploring those areas. This allows the agent to sequence movement actions that balance the natural trade-off between exploitation/refinement of the map in known areas and exploration of new areas. We experimentally demonstrate that our method outperforms both learning and non-learning state-of-the-art baselines in terms of average trajectory length to complete exploration in hundreds of simplified 2D indoor scenarios. We further validate our approach in high-fidelity Robot Operating System (ROS) simulations, where we consider a real sensor model and a realistic low-level motion controller, toward deployment on real robots.
Learning Informative Representation for Fairness-aware Multivariate Time-series Forecasting: A Group-based Perspective
Jan 27, 2023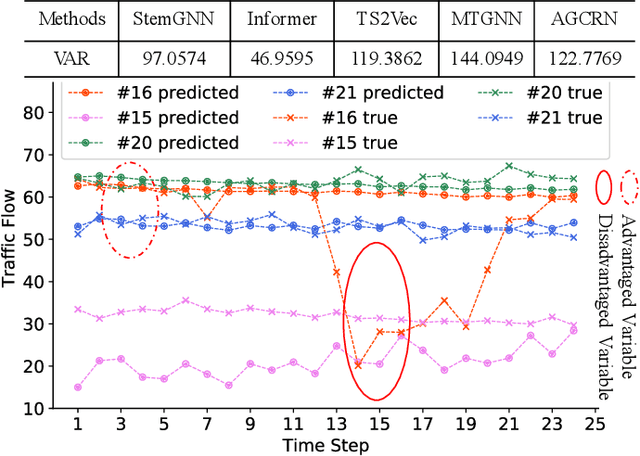
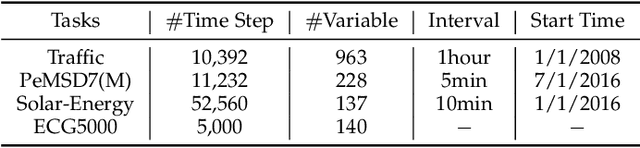
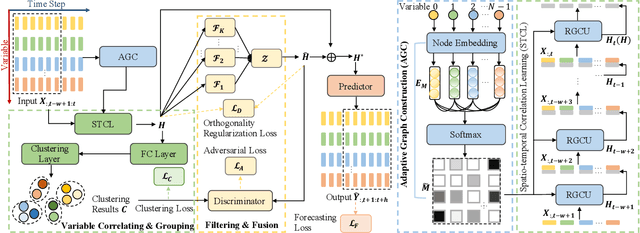

Multivariate time series (MTS) forecasting has penetrated and benefited our daily life. However, the unfair forecasting of MTSs not only degrades their practical benefit but even brings about serious potential risk. Such unfair MTS forecasting may be attributed to variable disparity leading to advantaged and disadvantaged variables. This issue has rarely been studied in the existing MTS forecasting models. To address this significant gap, we formulate the MTS fairness modeling problem as learning informative representations attending to both advantaged and disadvantaged variables. Accordingly, we propose a novel framework, named FairFor, for fairness-aware MTS forecasting. FairFor is based on adversarial learning to generate both group-irrelevant and -relevant representations for the downstream forecasting. FairFor first adopts the recurrent graph convolution to capture spatio-temporal variable correlations and to group variables by leveraging a spectral relaxation of the K-means objective. Then, it utilizes a novel filtering & fusion module to filter the group-relevant information and generate group-irrelevant representations by orthogonality regularization. The group-irrelevant and -relevant representations form highly informative representations, facilitating to share the knowledge from advantaged variables to disadvantaged variables and guarantee fairness. Extensive experiments on four public datasets demonstrate the FairFor effectiveness for fair forecasting and significant performance improvement.