 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MoE-Fusion: Instance Embedded Mixture-of-Experts for Infrared and Visible Image Fusion
Feb 02, 2023

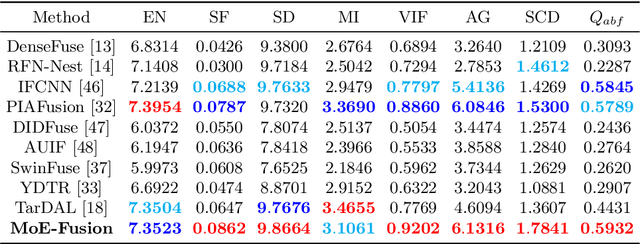
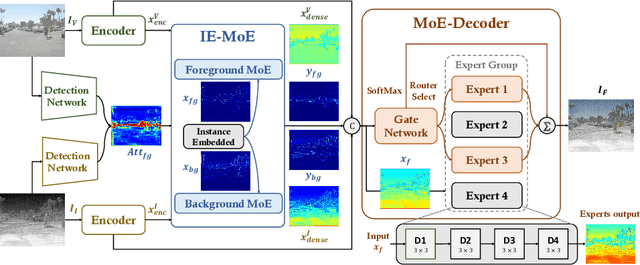
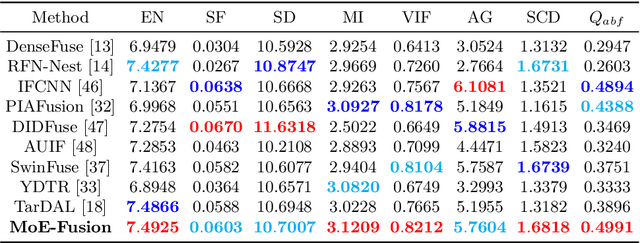
Infrared and visible image fusion can compensate for the incompleteness of single-modality imaging and provide a more comprehensive scene description based on cross-modal complementarity. Most works focus on learning the overall cross-modal features by high- and low-frequency constraints at the image level alone, ignoring the fact that cross-modal instance-level features often contain more valuable information. To fill this gap, we model cross-modal instance-level features by embedding instance information into a set of Mixture-of-Experts (MoEs) for the first time, prompting image fusion networks to specifically learn instance-level information. We propose a novel framework with instance embedded Mixture-of-Experts for infrared and visible image fusion, termed MoE-Fusion, which contains an instance embedded MoE group (IE-MoE), an MoE-Decoder, two encoders, and two auxiliary detection networks. By embedding the instance-level information learned in the auxiliary network, IE-MoE achieves specialized learning of cross-modal foreground and background features. MoE-Decoder can adaptively select suitable experts for cross-modal feature decoding and obtain fusion results dynamically. Extensive experiments show that our MoE-Fusion outperforms state-of-the-art methods in preserving contrast and texture details by learning instance-level information in cross-modal images.
Effect of Variable Physical Numerologies on Link-Level Performance of 5G NR V2X
Mar 17, 2023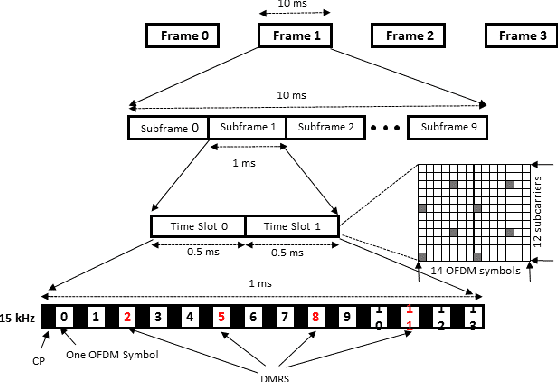
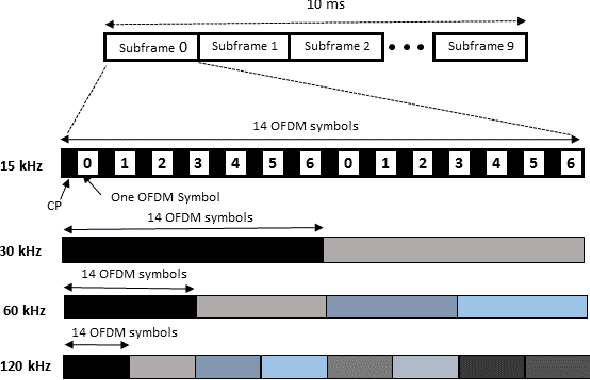
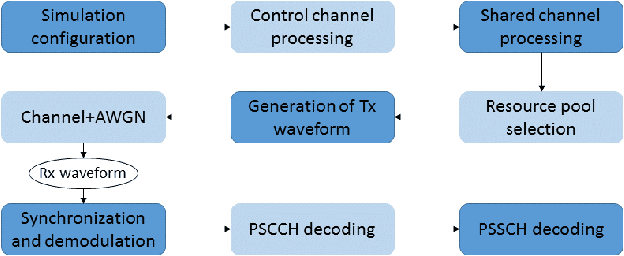
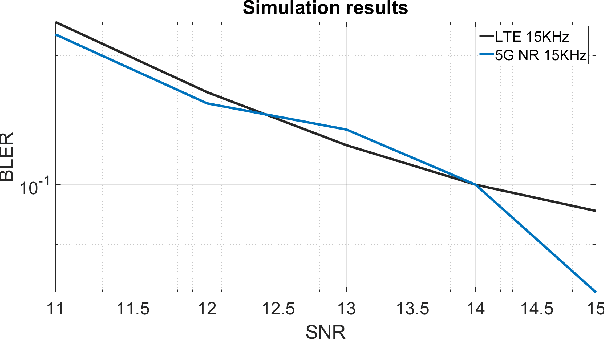
With technology and societal development, the 5th generation wireless communication (5G) contributes significantly to different societies like industries or academies. Vehicle-to-Everything (V2X) communication technology has been one of the leading services for 5G which has been applied in vehicles. It is used to exchange their status information with other traffic and traffic participants to increase traffic safety and efficiency. Cellular-V2X (C-V2X) is one of the emerging technologies to enable V2X communications. The first Long-Term Evolution (LTE) based C-V2X was released on the 3rd Generation Partnership Project (3GPP) standard. 3GPP is working towards the development of New Radio (NR) systems that it is called 5G NR V2X. One single numerology in LTE cannot satisfy most performance requirements because of the variety of deployment options and scenarios. For this reason, in order to meet the diverse requirements, the 5G NR Physical Layer (PHY) is designed to provide a highly flexible framework. Scalable Orthogonal Frequency-Division Multiplexing (OFDM) numerologies make flexibility possible. The term numerology refers to the PHY waveform parametrization and allows different Subcarrier Spacings (SCSs), symbols, and slot duration. This paper implements the Link-Level (LL) simulations of LTE C-V2X communication and 5G NR V2X communication where simulation results are used to compare similarities and differences between LTE and 5G NR. We detect the effect of variable PHY Numerologies of 5G NR on the LL performance of V2X. The simulation results show that the performance of 5G NR improved by using variable numerologies.
Stat-weight: Improving the Estimator of Interleaved Methods Outcomes with Statistical Hypothesis Testing
Mar 17, 2023Interleaving is an online evaluation approach for information retrieval systems that compares the effectiveness of ranking functions in interpreting the users' implicit feedback. Previous work such as Hofmann et al (2011) has evaluated the most promising interleaved methods at the time, on uniform distributions of queries. In the real world, ordinarily, there is an unbalanced distribution of repeated queries that follows a long-tailed users' search demand curve. The more a query is executed, by different users (or in different sessions), the higher the probability of collecting implicit feedback (interactions/clicks) on the related search results. This paper first aims to replicate the Team Draft Interleaving accuracy evaluation on uniform query distributions and then focuses on assessing how this method generalizes to long-tailed real-world scenarios. The reproducibility work raised interesting considerations on how the winning ranking function for each query should impact the overall winner for the entire evaluation. Based on what was observed, we propose that not all the queries should contribute to the final decision in equal proportion. As a result of these insights, we designed two variations of the $\Delta_{AB}$ score winner estimator that assign to each query a credit based on statistical hypothesis testing. To replicate, reproduce and extend the original work, we have developed from scratch a system that simulates a search engine and users' interactions from datasets from the industry. Our experiments confirm our intuition and show that our methods are promising in terms of accuracy, sensitivity, and robustness to noise.
* This preprint has not undergone peer review (when applicable) or any post-submission improvements or corrections. The Version of Record of this contribution is published in Advances in Information Retrieval 45th European Conference on Information Retrieval, ECIR 2023, Dublin, Ireland, April, 2023, Proceedings, Part III, and is available online at https://doi.org/10.1007/978-3-031-28241-6_2
XVoxel-Based Parametric Design Optimization of Feature Models
Mar 17, 2023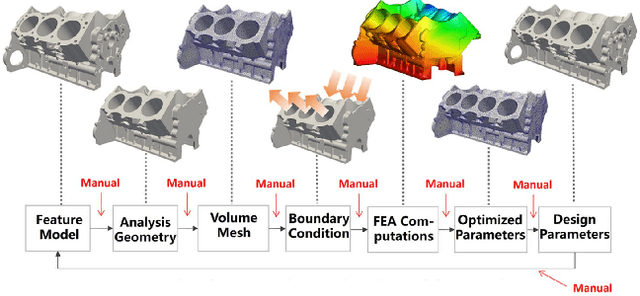
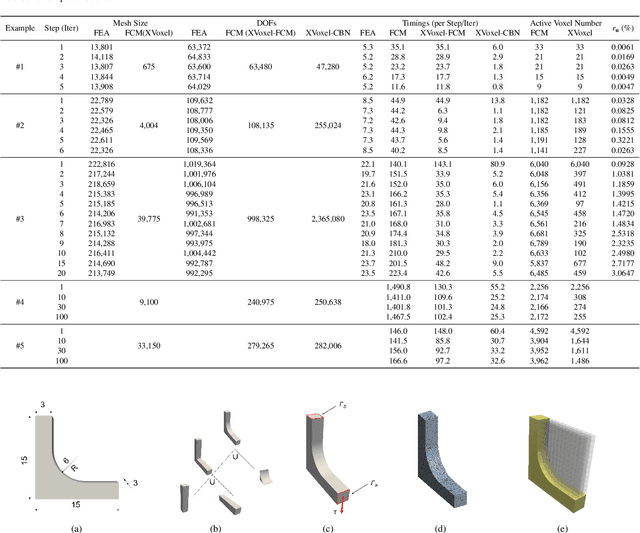
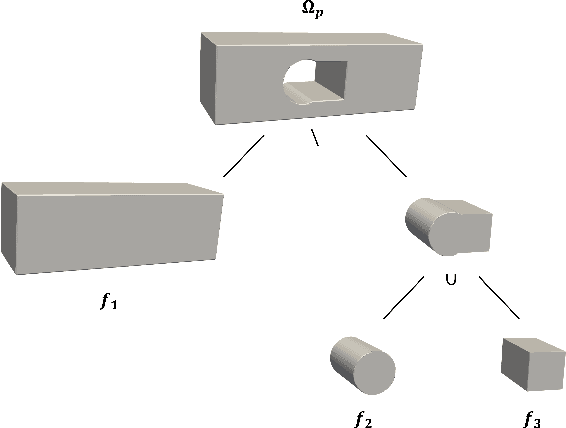

Parametric optimization is an important product design technique, especially in the context of the modern parametric feature-based CAD paradigm. Realizing its full potential, however, requires a closed loop between CAD and CAE (i.e., CAD/CAE integration) with automatic design modifications and simulation updates. Conventionally the approach of model conversion is often employed to form the loop, but this way of working is hard to automate and requires manual inputs. As a result, the overall optimization process is too laborious to be acceptable. To address this issue, a new method for parametric optimization is introduced in this paper, based on a unified model representation scheme called eXtended Voxels (XVoxels). This scheme hybridizes feature models and voxel models into a new concept of semantic voxels, where the voxel part is responsible for FEM solving, and the semantic part is responsible for high-level information to capture both design and simulation intents. As such, it can establish a direct mapping between design models and analysis models, which in turn enables automatic updates on simulation results for design modifications, and vice versa -- effectively a closed loop between CAD and CAE. In addition, robust and efficient geometric algorithms for manipulating XVoxel models and efficient numerical methods (based on the recent finite cell method) for simulating XVoxel models are provided. The presented method has been validated by a series of case studies of increasing complexity to demonstrate its effectiveness. In particular, a computational efficiency improvement of up to 55.8 times the existing FCM method has been seen.
IMCI: Integrate Multi-view Contextual Information for Fact Extraction and Verification
Aug 30, 2022

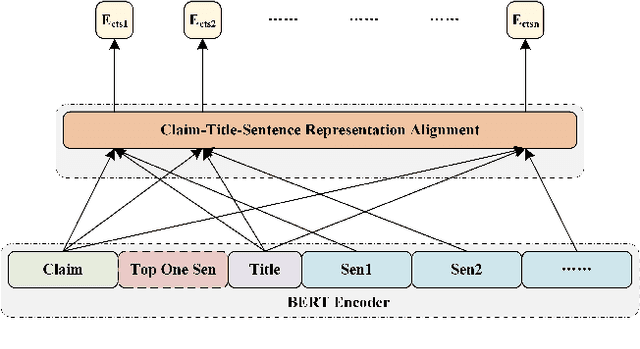

With the rapid development of automatic fake news detection technology, fact extraction and verification (FEVER) has been attracting more attention. The task aims to extract the most related fact evidences from millions of open-domain Wikipedia documents and then verify the credibility of corresponding claims. Although several strong models have been proposed for the task and they have made great progress, we argue that they fail to utilize multi-view contextual information and thus cannot obtain better performance. In this paper, we propose to integrate multi-view contextual information (IMCI) for fact extraction and verification. For each evidence sentence, we define two kinds of context, i.e. intra-document context and inter-document context}. Intra-document context consists of the document title and all the other sentences from the same document. Inter-document context consists of all other evidences which may come from different documents. Then we integrate the multi-view contextual information to encode the evidence sentences to handle the task. Our experimental results on FEVER 1.0 shared task show that our IMCI framework makes great progress on both fact extraction and verification, and achieves state-of-the-art performance with a winning FEVER score of 72.97% and label accuracy of 75.84% on the online blind test set. We also conduct ablation study to detect the impact of multi-view contextual information. Our codes will be released at https://github.com/phoenixsecularbird/IMCI.
GBMST: An Efficient Minimum Spanning Tree Clustering Based on Granular-Ball
Mar 02, 2023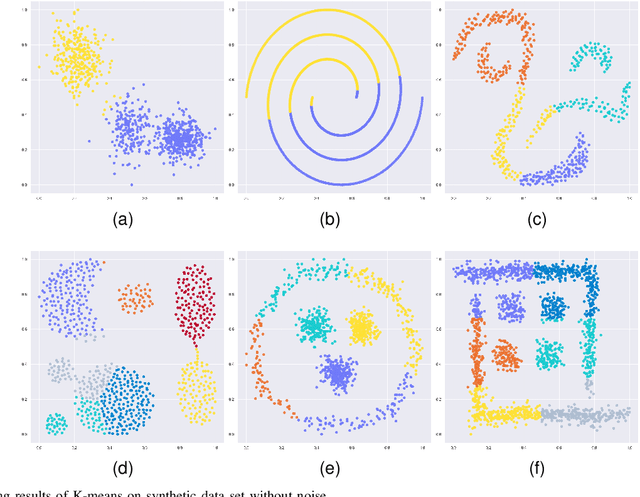
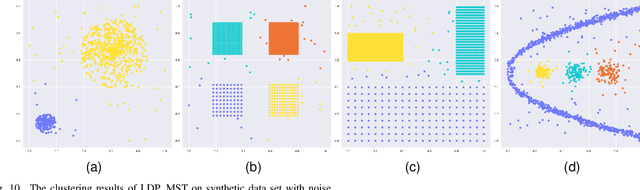
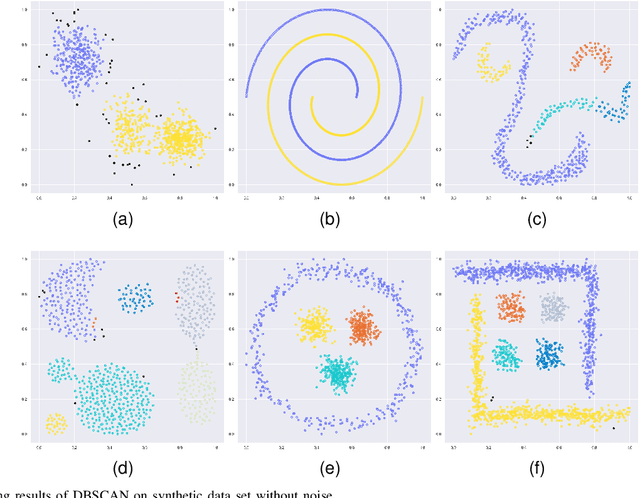
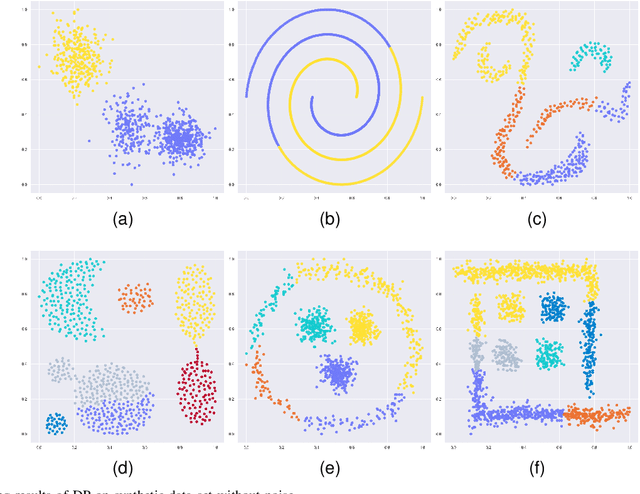
Most of the existing clustering methods are based on a single granularity of information, such as the distance and density of each data. This most fine-grained based approach is usually inefficient and susceptible to noise. Therefore, we propose a clustering algorithm that combines multi-granularity Granular-Ball and minimum spanning tree (MST). We construct coarsegrained granular-balls, and then use granular-balls and MST to implement the clustering method based on "large-scale priority", which can greatly avoid the influence of outliers and accelerate the construction process of MST. Experimental results on several data sets demonstrate the power of the algorithm. All codes have been released at https://github.com/xjnine/GBMST.
DDeMON: Ontology-based function prediction by Deep Learning from Dynamic Multiplex Networks
Feb 08, 2023
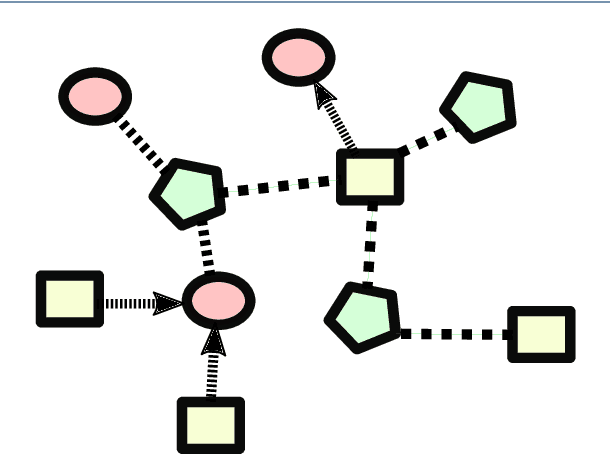
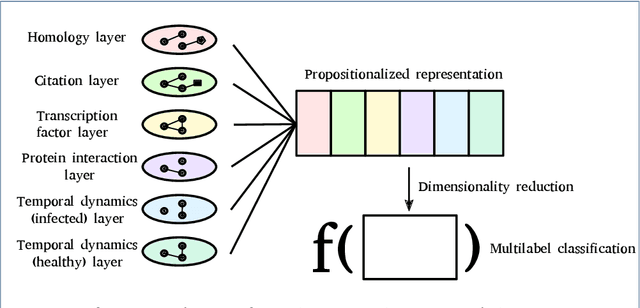
Biological systems can be studied at multiple levels of information, including gene, protein, RNA and different interaction networks levels. The goal of this work is to explore how the fusion of systems' level information with temporal dynamics of gene expression can be used in combination with non-linear approximation power of deep neural networks to predict novel gene functions in a non-model organism potato \emph{Solanum tuberosum}. We propose DDeMON (Dynamic Deep learning from temporal Multiplex Ontology-annotated Networks), an approach for scalable, systems-level inference of function annotation using time-dependent multiscale biological information. The proposed method, which is capable of considering billions of potential links between the genes of interest, was applied on experimental gene expression data and the background knowledge network to reliably classify genes with unknown function into five different functional ontology categories, linked to the experimental data set. Predicted novel functions of genes were validated using extensive protein domain search approach.
Participatory Systems for Personalized Prediction
Feb 08, 2023
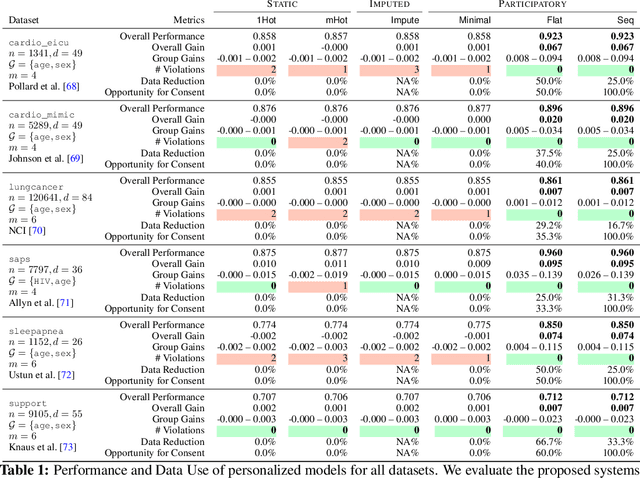
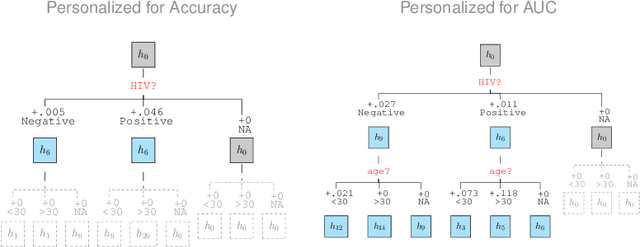
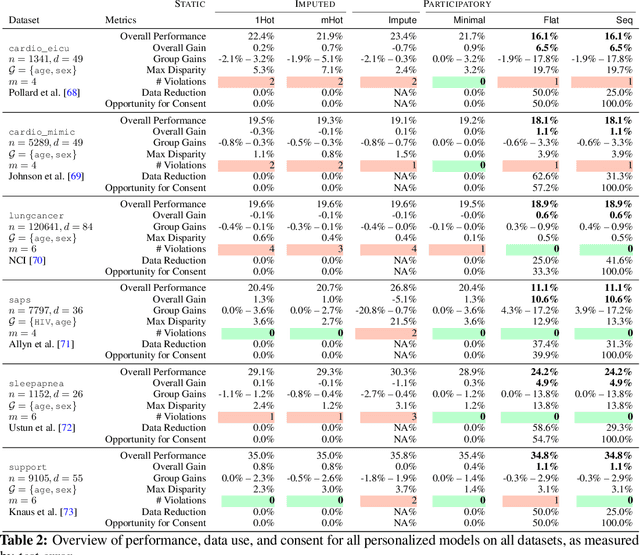
Machine learning models are often personalized based on information that is protected, sensitive, self-reported, or costly to acquire. These models use information about people, but do not facilitate nor inform their \emph{consent}. Individuals cannot opt out of reporting information that a model needs to personalize their predictions, nor tell if they would benefit from personalization in the first place. In this work, we introduce a new family of prediction models, called \emph{participatory systems}, that allow individuals to opt into personalization at prediction time. We present a model-agnostic algorithm to learn participatory systems for supervised learning tasks where models are personalized with categorical group attributes. We conduct a comprehensive empirical study of participatory systems in clinical prediction tasks, comparing them to common approaches for personalization and imputation. Our results demonstrate that participatory systems can facilitate and inform consent in a way that improves performance and privacy across all groups who report personal data.
AugDiff: Diffusion based Feature Augmentation for Multiple Instance Learning in Whole Slide Image
Mar 11, 2023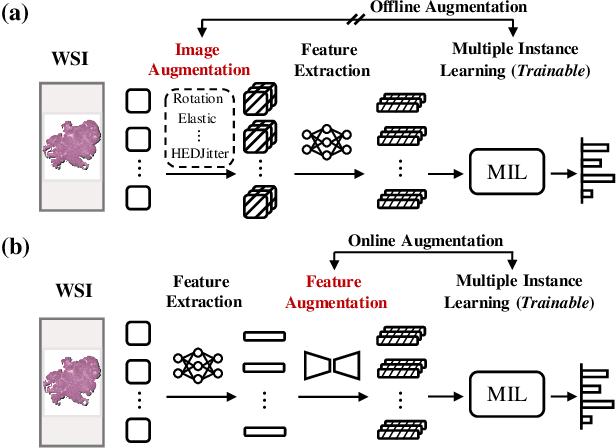
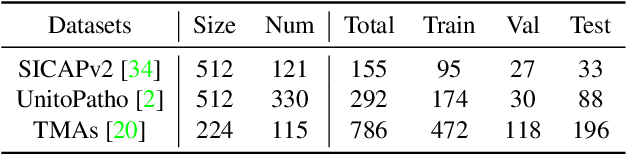
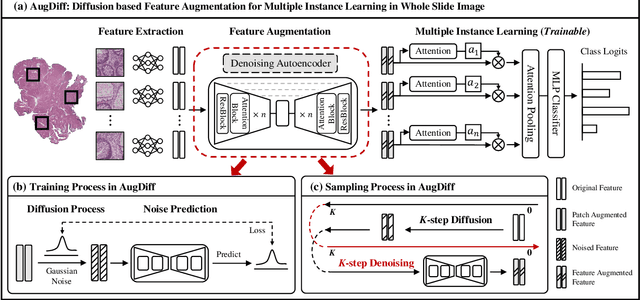
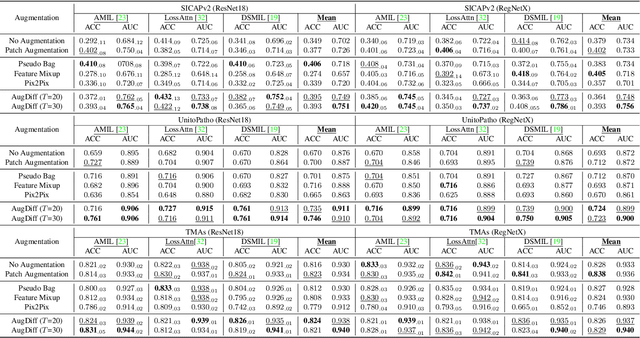
Multiple Instance Learning (MIL), a powerful strategy for weakly supervised learning, is able to perform various prediction tasks on gigapixel Whole Slide Images (WSIs). However, the tens of thousands of patches in WSIs usually incur a vast computational burden for image augmentation, limiting the MIL model's improvement in performance. Currently, the feature augmentation-based MIL framework is a promising solution, while existing methods such as Mixup often produce unrealistic features. To explore a more efficient and practical augmentation method, we introduce the Diffusion Model (DM) into MIL for the first time and propose a feature augmentation framework called AugDiff. Specifically, we employ the generation diversity of DM to improve the quality of feature augmentation and the step-by-step generation property to control the retention of semantic information. We conduct extensive experiments over three distinct cancer datasets, two different feature extractors, and three prevalent MIL algorithms to evaluate the performance of AugDiff. Ablation study and visualization further verify the effectiveness. Moreover, we highlight AugDiff's higher-quality augmented feature over image augmentation and its superiority over self-supervised learning. The generalization over external datasets indicates its broader applications.
Trust your neighbours: Penalty-based constraints for model calibration
Mar 11, 2023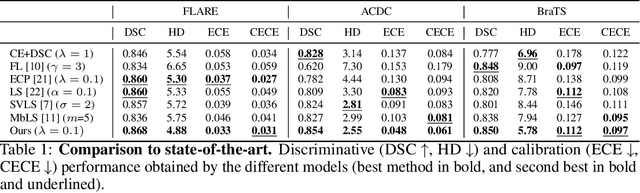
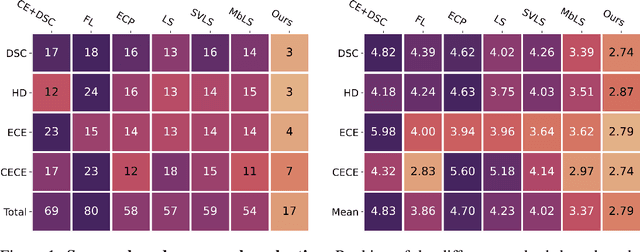

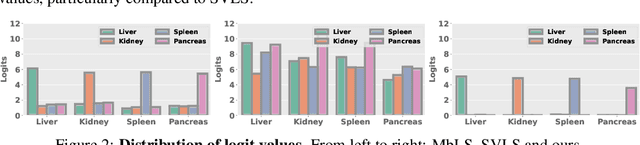
Ensuring reliable confidence scores from deep networks is of pivotal importance in critical decision-making systems, notably in the medical domain. While recent literature on calibrating deep segmentation networks has led to significant progress, their uncertainty is usually modeled by leveraging the information of individual pixels, which disregards the local structure of the object of interest. In particular, only the recent Spatially Varying Label Smoothing (SVLS) approach addresses this issue by softening the pixel label assignments with a discrete spatial Gaussian kernel. In this work, we first present a constrained optimization perspective of SVLS and demonstrate that it enforces an implicit constraint on soft class proportions of surrounding pixels. Furthermore, our analysis shows that SVLS lacks a mechanism to balance the contribution of the constraint with the primary objective, potentially hindering the optimization process. Based on these observations, we propose a principled and simple solution based on equality constraints on the logit values, which enables to control explicitly both the enforced constraint and the weight of the penalty, offering more flexibility. Comprehensive experiments on a variety of well-known segmentation benchmarks demonstrate the superior performance of the proposed approach.