 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKDH-CAD: Knowledge-data hybrid CAD learning under data scarcity
Jun 01, 2026Deep learning in computer-aided design (CAD) remains fundamentally constrained by the data scarcity challenge: authentic CAD data is difficult to collect at scale, while synthetic data may not faithfully reflect real design practice. Rather than pursuing ever-larger CAD datasets, this paper alternatively treats CAD learning as a knowledge completion and calibration problem. It introduces KDH-CAD, a knowledge-data hybrid framework that integrates pretrained knowledge in foundation models, structured domain knowledge from textbooks/tutorials, and a very small amount of labeled CAD data. Domain knowledge is used to elicit and complete CAD-relevant concepts that are weakly expressed or under-represented in pretrained foundation models, while labeled CAD data calibrates these concepts in the latent space to account for task-specific geometric variability, without fine-tuning the foundation model. Experiments on real-world mechanical part classification show that KDH-CAD achieves strong performance in low-data regimes, reaching 92.6\% accuracy with only 250 training samples, 95.8\% with 1,000 samples, and continuing to improve with additional data. This matches or exceeds state-of-the-art performance that typically requires an order of magnitude more data. These results suggest that combining pretrained foundation models with structured domain knowledge can substantially reduce reliance on large-scale CAD datasets, providing a principled and practical direction for data-efficient CAD learning.
AirfoilGen: A valid-by-construction and performance-aware latent diffusion model for airfoil generation
May 21, 2026Airfoil shape design is a fundamental task in aerospace engineering, with a direct impact on flight stability and fuel consumption. Deep learning has recently emerged as a promising tool for this task, but existing deep generative approaches remain limited in both geometric validity and physical controllability. They offer little control over the generated shapes, yielding invalid geometries, and they typically do not condition effectively on aerodynamic performance. To address these issues, this paper proposes AirfoilGen, a valid-by-construction and performance-aware latent diffusion model for airfoil. It first introduces a novel airfoil representation scheme, the circle sweeping representation, to constrain the generative process so that output shapes respect essential airfoil characteristics. It then enables explicit control over aerodynamic performance (e.g., lift and drag coefficients) by operating in a learned latent space: a transformer model encodes airfoil shapes into vector embeddings, and a conditional diffusion model denoises Gaussian noise into these latent embeddings while incorporating target aerodynamic performance. In addition, this paper presents a new dataset of over 200,000 airfoils, which is substantially larger than the widely used UIUC airfoil dataset (1,650 airfoils) and more suitable for training modern deep generative models. Experiments demonstrate that AirfoilGen enables airfoil generation with far greater geometric validity and aerodynamic performance controllability than previously achievable, with an average performance-conditioning accuracy of 98.41%.
GLM-5: from Vibe Coding to Agentic Engineering
Feb 17, 2026We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
Boundary representation learning via Transformer
Apr 07, 2025



The recent rise of generative artificial intelligence (AI), powered by Transformer networks, has achieved remarkable success in natural language processing, computer vision, and graphics. However, the application of Transformers in computer-aided design (CAD), particularly for processing boundary representation (B-rep) models, remains largely unexplored. To bridge this gap, this paper introduces Boundary Representation Transformer (BRT), a novel method adapting Transformer for B-rep learning. B-rep models pose unique challenges due to their irregular topology and continuous geometric definitions, which are fundamentally different from the structured and discrete data Transformers are designed for. To address this, BRT proposes a continuous geometric embedding method that encodes B-rep surfaces (trimmed and untrimmed) into B\'ezier triangles, preserving their shape and continuity without discretization. Additionally, BRT employs a topology-aware embedding method that organizes these geometric embeddings into a sequence of discrete tokens suitable for Transformers, capturing both geometric and topological characteristics within B-rep models. This enables the Transformer's attention mechanism to effectively learn shape patterns and contextual semantics of boundary elements in a B-rep model. Extensive experiments demonstrate that BRT achieves state-of-the-art performance in part classification and feature recognition tasks.
PromptHash: Affinity-Prompted Collaborative Cross-Modal Learning for Adaptive Hashing Retrieval
Mar 20, 2025



Cross-modal hashing is a promising approach for efficient data retrieval and storage optimization. However, contemporary methods exhibit significant limitations in semantic preservation, contextual integrity, and information redundancy, which constrains retrieval efficacy. We present PromptHash, an innovative framework leveraging affinity prompt-aware collaborative learning for adaptive cross-modal hashing. We propose an end-to-end framework for affinity-prompted collaborative hashing, with the following fundamental technical contributions: (i) a text affinity prompt learning mechanism that preserves contextual information while maintaining parameter efficiency, (ii) an adaptive gated selection fusion architecture that synthesizes State Space Model with Transformer network for precise cross-modal feature integration, and (iii) a prompt affinity alignment strategy that bridges modal heterogeneity through hierarchical contrastive learning. To the best of our knowledge, this study presents the first investigation into affinity prompt awareness within collaborative cross-modal adaptive hash learning, establishing a paradigm for enhanced semantic consistency across modalities. Through comprehensive evaluation on three benchmark multi-label datasets, PromptHash demonstrates substantial performance improvements over existing approaches. Notably, on the NUS-WIDE dataset, our method achieves significant gains of 18.22% and 18.65% in image-to-text and text-to-image retrieval tasks, respectively. The code is publicly available at https://github.com/ShiShuMo/PromptHash.
3D-PreMise: Can Large Language Models Generate 3D Shapes with Sharp Features and Parametric Control?
Jan 12, 2024Recent advancements in implicit 3D representations and generative models have markedly propelled the field of 3D object generation forward. However, it remains a significant challenge to accurately model geometries with defined sharp features under parametric controls, which is crucial in fields like industrial design and manufacturing. To bridge this gap, we introduce a framework that employs Large Language Models (LLMs) to generate text-driven 3D shapes, manipulating 3D software via program synthesis. We present 3D-PreMise, a dataset specifically tailored for 3D parametric modeling of industrial shapes, designed to explore state-of-the-art LLMs within our proposed pipeline. Our work reveals effective generation strategies and delves into the self-correction capabilities of LLMs using a visual interface. Our work highlights both the potential and limitations of LLMs in 3D parametric modeling for industrial applications.
XVoxel-Based Parametric Design Optimization of Feature Models
Mar 17, 2023



Parametric optimization is an important product design technique, especially in the context of the modern parametric feature-based CAD paradigm. Realizing its full potential, however, requires a closed loop between CAD and CAE (i.e., CAD/CAE integration) with automatic design modifications and simulation updates. Conventionally the approach of model conversion is often employed to form the loop, but this way of working is hard to automate and requires manual inputs. As a result, the overall optimization process is too laborious to be acceptable. To address this issue, a new method for parametric optimization is introduced in this paper, based on a unified model representation scheme called eXtended Voxels (XVoxels). This scheme hybridizes feature models and voxel models into a new concept of semantic voxels, where the voxel part is responsible for FEM solving, and the semantic part is responsible for high-level information to capture both design and simulation intents. As such, it can establish a direct mapping between design models and analysis models, which in turn enables automatic updates on simulation results for design modifications, and vice versa -- effectively a closed loop between CAD and CAE. In addition, robust and efficient geometric algorithms for manipulating XVoxel models and efficient numerical methods (based on the recent finite cell method) for simulating XVoxel models are provided. The presented method has been validated by a series of case studies of increasing complexity to demonstrate its effectiveness. In particular, a computational efficiency improvement of up to 55.8 times the existing FCM method has been seen.
Deep Learning Assisted Optimization for 3D Reconstruction from Single 2D Line Drawings
Sep 07, 2022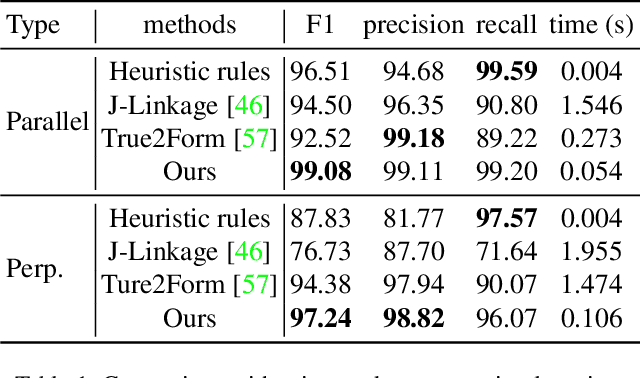
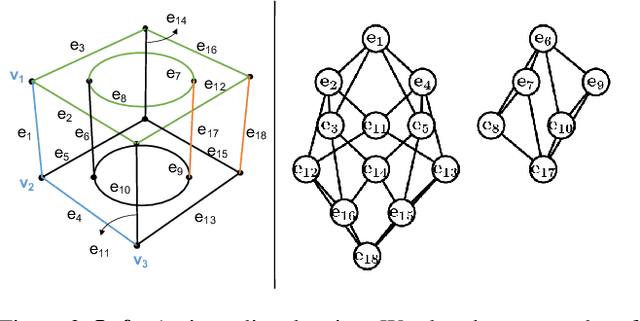
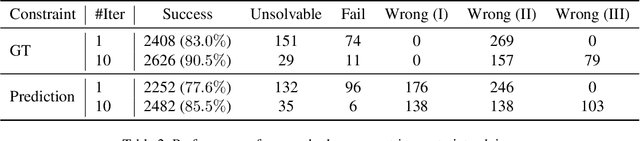
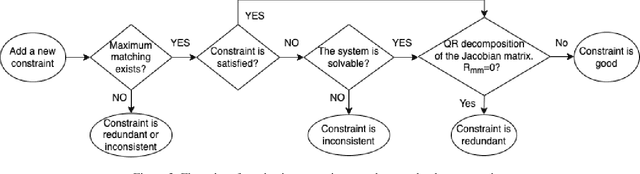
In this paper, we revisit the long-standing problem of automatic reconstruction of 3D objects from single line drawings. Previous optimization-based methods can generate compact and accurate 3D models, but their success rates depend heavily on the ability to (i) identifying a sufficient set of true geometric constraints, and (ii) choosing a good initial value for the numerical optimization. In view of these challenges, we propose to train deep neural networks to detect pairwise relationships among geometric entities (i.e., edges) in the 3D object, and to predict initial depth value of the vertices. Our experiments on a large dataset of CAD models show that, by leveraging deep learning in a geometric constraint solving pipeline, the success rate of optimization-based 3D reconstruction can be significantly improved.