 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GeneGPT: Teaching Large Language Models to Use NCBI Web APIs
Apr 19, 2023

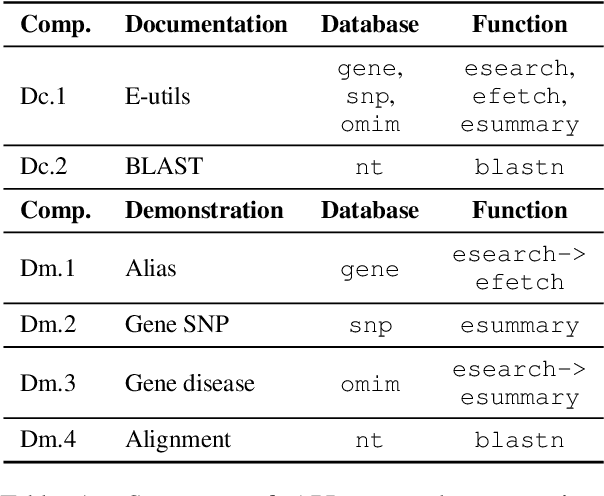
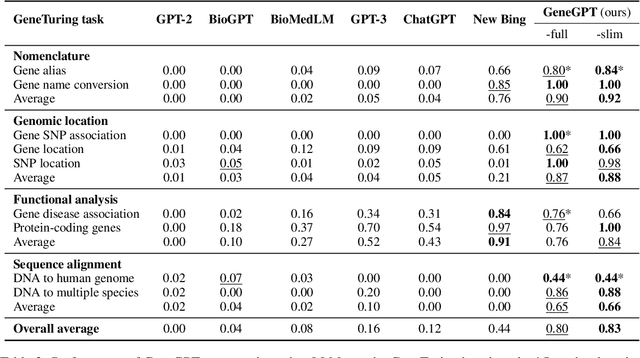

In this paper, we present GeneGPT, a novel method for teaching large language models (LLMs) to use the Web Application Programming Interfaces (APIs) of the National Center for Biotechnology Information (NCBI) and answer genomics questions. Specifically, we prompt Codex (code-davinci-002) to solve the GeneTuring tests with few-shot URL requests of NCBI API calls as demonstrations for in-context learning. During inference, we stop the decoding once a call request is detected and make the API call with the generated URL. We then append the raw execution results returned by NCBI APIs to the generated texts and continue the generation until the answer is found or another API call is detected. Our preliminary results show that GeneGPT achieves state-of-the-art results on three out of four one-shot tasks and four out of five zero-shot tasks in the GeneTuring dataset. Overall, GeneGPT achieves a macro-average score of 0.76, which is much higher than retrieval-augmented LLMs such as the New Bing (0.44), biomedical LLMs such as BioMedLM (0.08) and BioGPT (0.04), as well as other LLMs such as GPT-3 (0.16) and ChatGPT (0.12).
Evaluating Verifiability in Generative Search Engines
Apr 19, 2023


Generative search engines directly generate responses to user queries, along with in-line citations. A prerequisite trait of a trustworthy generative search engine is verifiability, i.e., systems should cite comprehensively (high citation recall; all statements are fully supported by citations) and accurately (high citation precision; every cite supports its associated statement). We conduct human evaluation to audit four popular generative search engines -- Bing Chat, NeevaAI, perplexity.ai, and YouChat -- across a diverse set of queries from a variety of sources (e.g., historical Google user queries, dynamically-collected open-ended questions on Reddit, etc.). We find that responses from existing generative search engines are fluent and appear informative, but frequently contain unsupported statements and inaccurate citations: on average, a mere 51.5% of generated sentences are fully supported by citations and only 74.5% of citations support their associated sentence. We believe that these results are concerningly low for systems that may serve as a primary tool for information-seeking users, especially given their facade of trustworthiness. We hope that our results further motivate the development of trustworthy generative search engines and help researchers and users better understand the shortcomings of existing commercial systems.
An Offline Metric for the Debiasedness of Click Models
Apr 19, 2023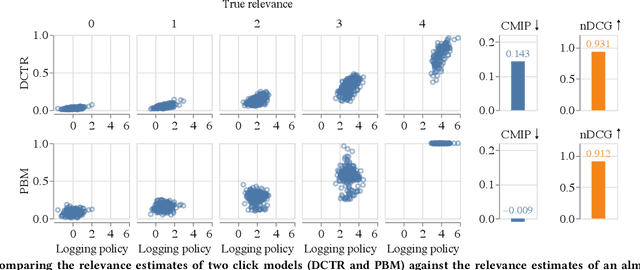
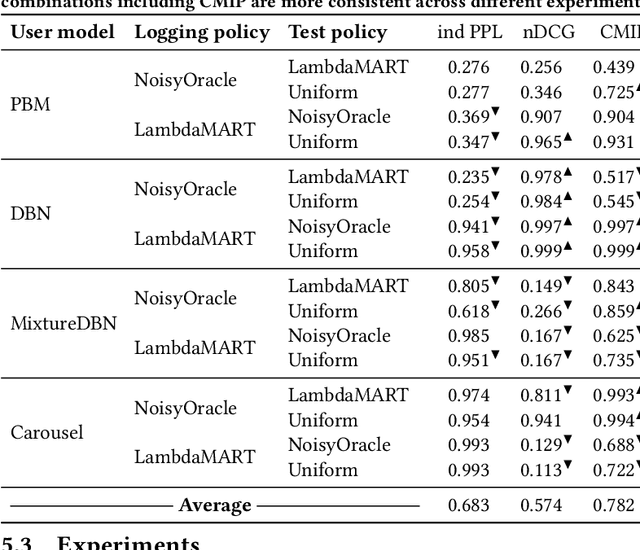
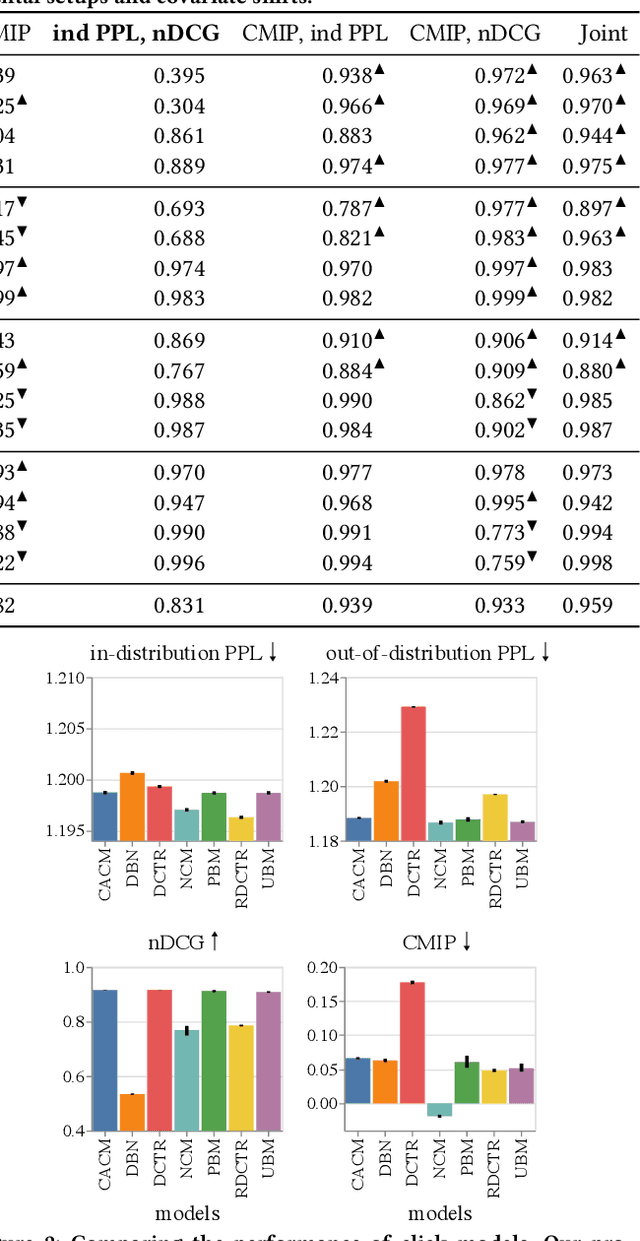
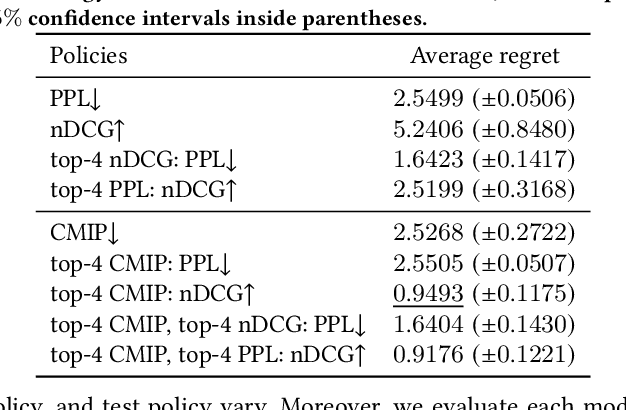
A well-known problem when learning from user clicks are inherent biases prevalent in the data, such as position or trust bias. Click models are a common method for extracting information from user clicks, such as document relevance in web search, or to estimate click biases for downstream applications such as counterfactual learning-to-rank, ad placement, or fair ranking. Recent work shows that the current evaluation practices in the community fail to guarantee that a well-performing click model generalizes well to downstream tasks in which the ranking distribution differs from the training distribution, i.e., under covariate shift. In this work, we propose an evaluation metric based on conditional independence testing to detect a lack of robustness to covariate shift in click models. We introduce the concept of debiasedness and a metric for measuring it. We prove that debiasedness is a necessary condition for recovering unbiased and consistent relevance scores and for the invariance of click prediction under covariate shift. In extensive semi-synthetic experiments, we show that our proposed metric helps to predict the downstream performance of click models under covariate shift and is useful in an off-policy model selection setting.
Introducing Construct Theory as a Standard Methodology for Inclusive AI Models
Apr 19, 2023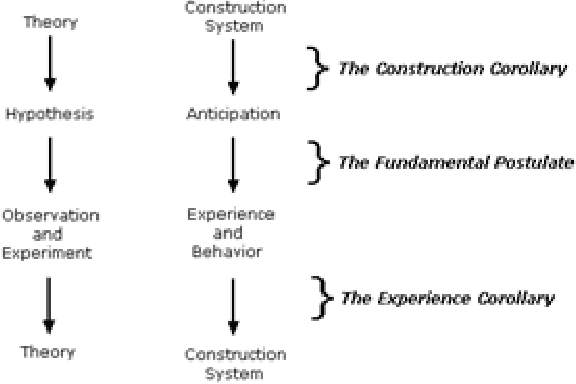

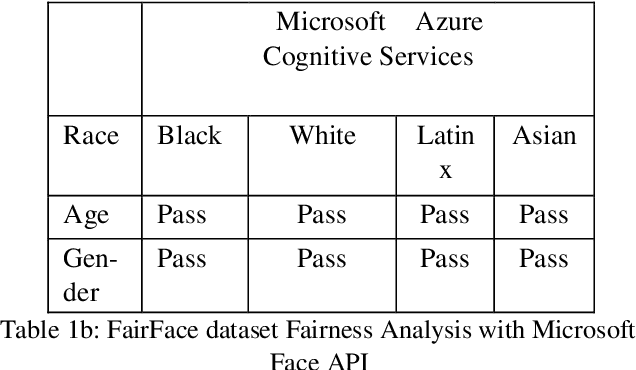
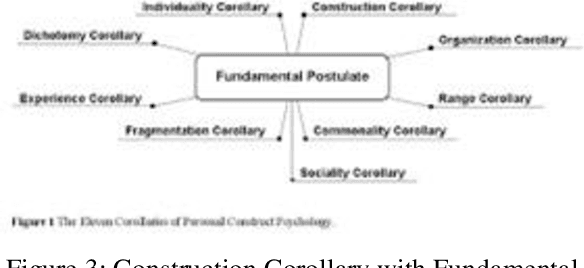
Construct theory in social psychology, developed by George Kelly are mental constructs to predict and anticipate events. Constructs are how humans interpret, curate, predict and validate data; information. AI today is biased because it is trained with a narrow construct as defined by the training data labels. Machine Learning algorithms for facial recognition discriminate against darker skin colors and in the ground breaking research papers (Buolamwini, Joy and Timnit Gebru. Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification. FAT (2018), the inclusion of phenotypic labeling is proposed as a viable solution. In Construct theory, phenotype is just one of the many subelements that make up the construct of a face. In this paper, we present 15 main elements of the construct of face, with 50 subelements and tested Google Cloud Vision API and Microsoft Cognitive Services API using FairFace dataset that currently has data for 7 races, genders and ages, and we retested against FairFace Plus dataset curated by us. Our results show exactly where they have gaps for inclusivity. Based on our experiment results, we propose that validated, inclusive constructs become industry standards for AI ML models going forward.
ASM: Adaptive Skinning Model for High-Quality 3D Face Modeling
Apr 19, 2023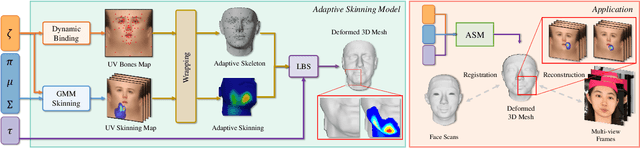
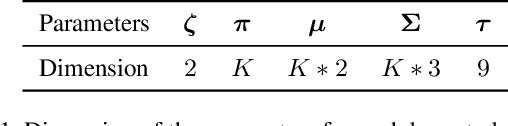
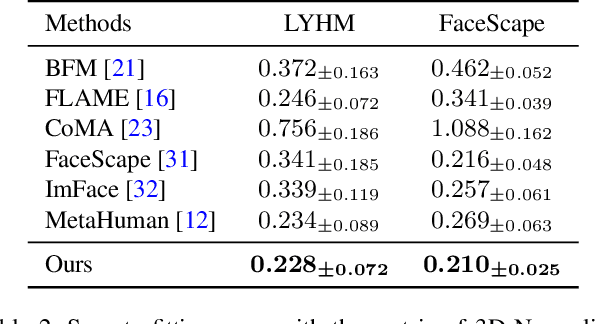
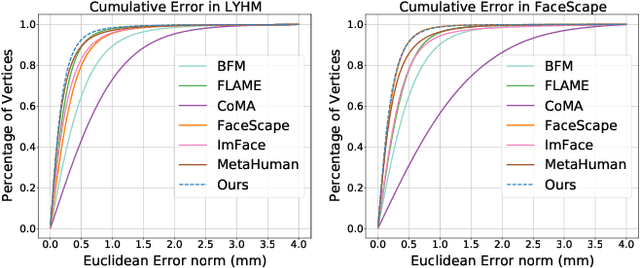
The research fields of parametric face models and 3D face reconstruction have been extensively studied. However, a critical question remains unanswered: how to tailor the face model for specific reconstruction settings. We argue that reconstruction with multi-view uncalibrated images demands a new model with stronger capacity. Our study shifts attention from data-dependent 3D Morphable Models (3DMM) to an understudied human-designed skinning model. We propose Adaptive Skinning Model (ASM), which redefines the skinning model with more compact and fully tunable parameters. With extensive experiments, we demonstrate that ASM achieves significantly improved capacity than 3DMM, with the additional advantage of model size and easy implementation for new topology. We achieve state-of-the-art performance with ASM for multi-view reconstruction on the Florence MICC Coop benchmark. Our quantitative analysis demonstrates the importance of a high-capacity model for fully exploiting abundant information from multi-view input in reconstruction. Furthermore, our model with physical-semantic parameters can be directly utilized for real-world applications, such as in-game avatar creation. As a result, our work opens up new research directions for the parametric face models and facilitates future research on multi-view reconstruction.
Causal Semantic Communication for Digital Twins: A Generalizable Imitation Learning Approach
Apr 25, 2023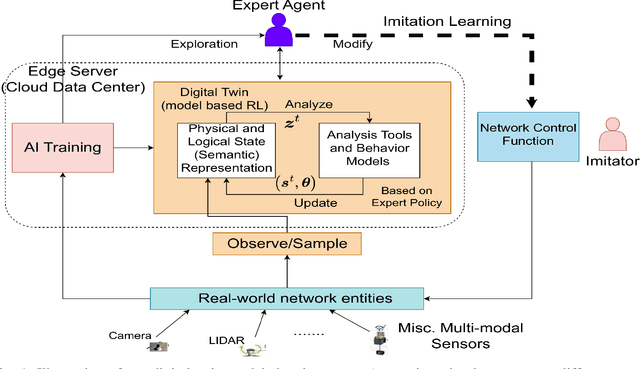
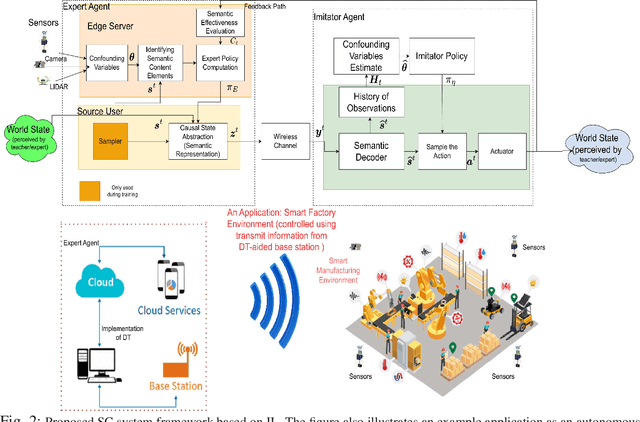
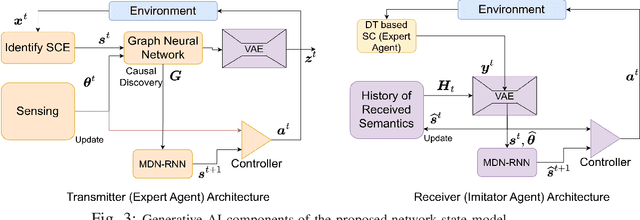
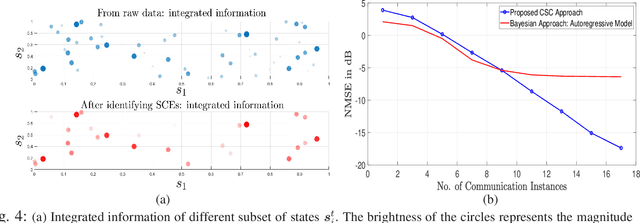
A digital twin (DT) leverages a virtual representation of the physical world, along with communication (e.g., 6G), computing (e.g., edge computing), and artificial intelligence (AI) technologies to enable many connected intelligence services. In order to handle the large amounts of network data based on digital twins (DTs), wireless systems can exploit the paradigm of semantic communication (SC) for facilitating informed decision-making under strict communication constraints by utilizing AI techniques such as causal reasoning. In this paper, a novel framework called causal semantic communication (CSC) is proposed for DT-based wireless systems. The CSC system is posed as an imitation learning (IL) problem, where the transmitter, with access to optimal network control policies using a DT, teaches the receiver using SC over a bandwidth limited wireless channel how to improve its knowledge to perform optimal control actions. The causal structure in the source data is extracted using novel approaches from the framework of deep end-to-end causal inference, thereby enabling the creation of a semantic representation that is causally invariant, which in turn helps generalize the learned knowledge of the system to unseen scenarios. The CSC decoder at the receiver is designed to extract and estimate semantic information while ensuring high semantic reliability. The receiver control policies, semantic decoder, and causal inference are formulated as a bi-level optimization problem within a variational inference framework. This problem is solved using a novel concept called network state models, inspired from world models in generative AI, that faithfully represents the environment dynamics leading to data generation. Simulation results demonstrate that the proposed CSC system outperforms state-of-the-art SC systems by achieving better semantic reliability and reduced semantic representation.
On the Generalization of Learned Structured Representations
Apr 25, 2023
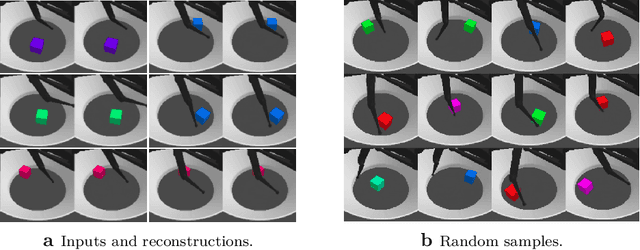
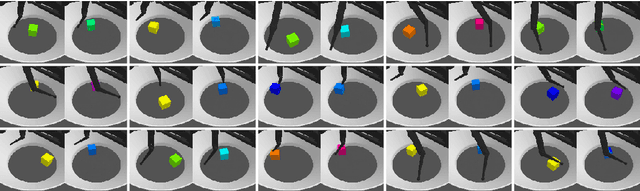
Despite tremendous progress over the past decade, deep learning methods generally fall short of human-level systematic generalization. It has been argued that explicitly capturing the underlying structure of data should allow connectionist systems to generalize in a more predictable and systematic manner. Indeed, evidence in humans suggests that interpreting the world in terms of symbol-like compositional entities may be crucial for intelligent behavior and high-level reasoning. Another common limitation of deep learning systems is that they require large amounts of training data, which can be expensive to obtain. In representation learning, large datasets are leveraged to learn generic data representations that may be useful for efficient learning of arbitrary downstream tasks. This thesis is about structured representation learning. We study methods that learn, with little or no supervision, representations of unstructured data that capture its hidden structure. In the first part of the thesis, we focus on representations that disentangle the explanatory factors of variation of the data. We scale up disentangled representation learning to a novel robotic dataset, and perform a systematic large-scale study on the role of pretrained representations for out-of-distribution generalization in downstream robotic tasks. The second part of this thesis focuses on object-centric representations, which capture the compositional structure of the input in terms of symbol-like entities, such as objects in visual scenes. Object-centric learning methods learn to form meaningful entities from unstructured input, enabling symbolic information processing on a connectionist substrate. In this study, we train a selection of methods on several common datasets, and investigate their usefulness for downstream tasks and their ability to generalize out of distribution.
Multi-granulariy Time-based Transformer for Knowledge Tracing
Apr 11, 2023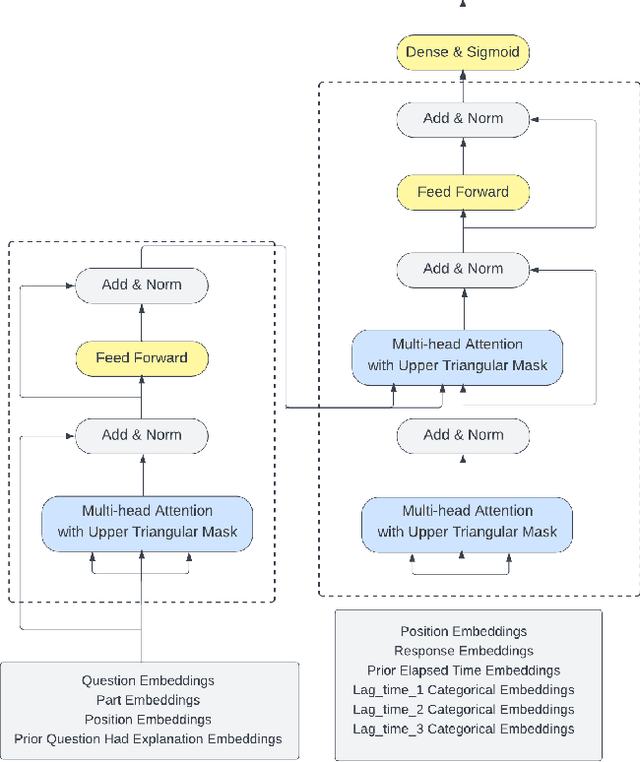

In this paper, we present a transformer architecture for predicting student performance on standardized tests. Specifically, we leverage students historical data, including their past test scores, study habits, and other relevant information, to create a personalized model for each student. We then use these models to predict their future performance on a given test. Applying this model to the RIIID dataset, we demonstrate that using multiple granularities for temporal features as the decoder input significantly improve model performance. Our results also show the effectiveness of our approach, with substantial improvements over the LightGBM method. Our work contributes to the growing field of AI in education, providing a scalable and accurate tool for predicting student outcomes.
An ontology-aided, natural language-based approach for multi-constraint BIM model querying
Mar 27, 2023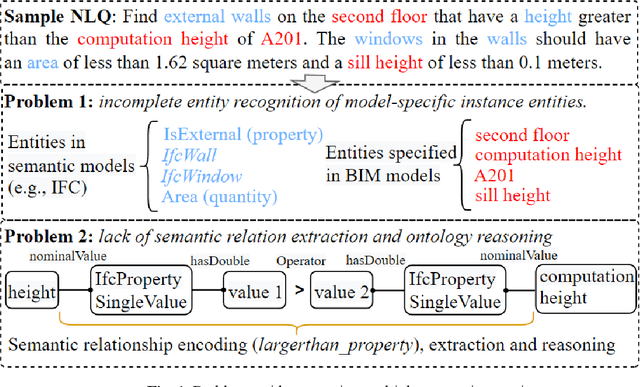
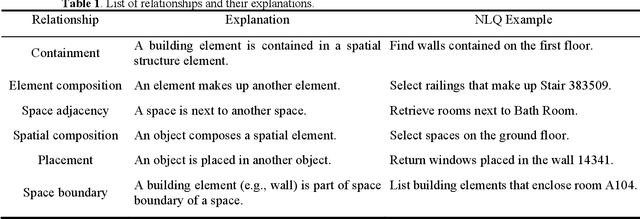
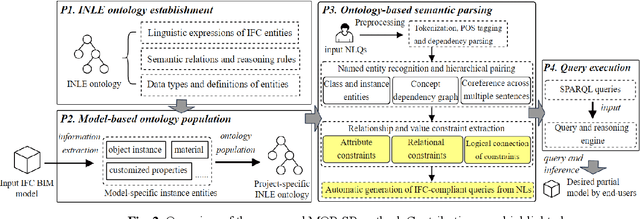
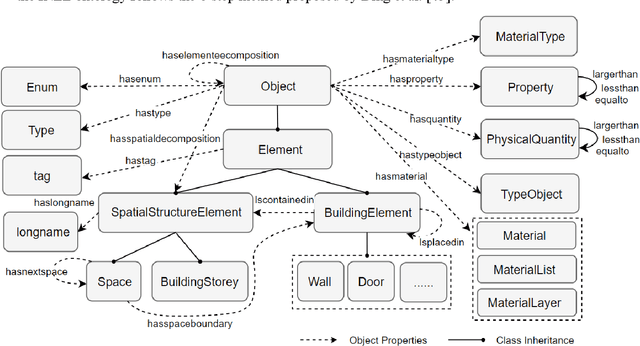
Being able to efficiently retrieve the required building information is critical for construction project stakeholders to carry out their engineering and management activities. Natural language interface (NLI) systems are emerging as a time and cost-effective way to query Building Information Models (BIMs). However, the existing methods cannot logically combine different constraints to perform fine-grained queries, dampening the usability of natural language (NL)-based BIM queries. This paper presents a novel ontology-aided semantic parser to automatically map natural language queries (NLQs) that contain different attribute and relational constraints into computer-readable codes for querying complex BIM models. First, a modular ontology was developed to represent NL expressions of Industry Foundation Classes (IFC) concepts and relationships, and was then populated with entities from target BIM models to assimilate project-specific information. Hereafter, the ontology-aided semantic parser progressively extracts concepts, relationships, and value restrictions from NLQs to fully identify constraint conditions, resulting in standard SPARQL queries with reasoning rules to successfully retrieve IFC-based BIM models. The approach was evaluated based on 225 NLQs collected from BIM users, with a 91% accuracy rate. Finally, a case study about the design-checking of a real-world residential building demonstrates the practical value of the proposed approach in the construction industry.
DNeRV: Modeling Inherent Dynamics via Difference Neural Representation for Videos
Apr 13, 2023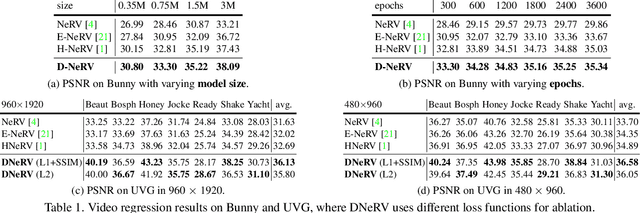

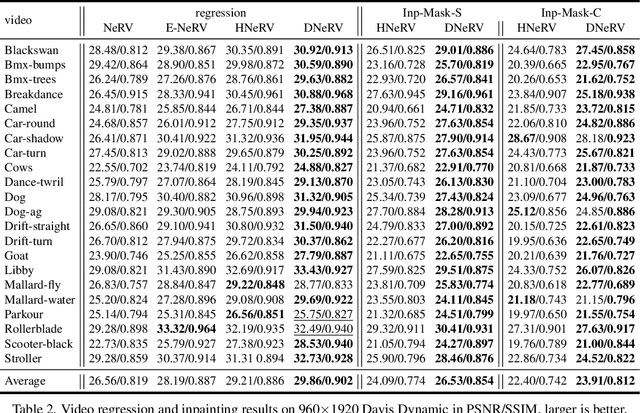
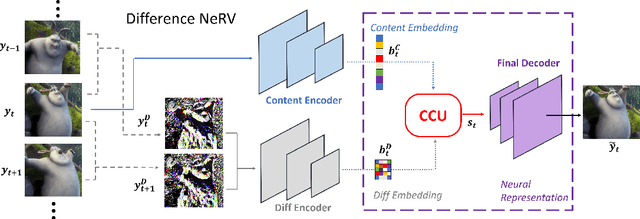
Existing implicit neural representation (INR) methods do not fully exploit spatiotemporal redundancies in videos. Index-based INRs ignore the content-specific spatial features and hybrid INRs ignore the contextual dependency on adjacent frames, leading to poor modeling capability for scenes with large motion or dynamics. We analyze this limitation from the perspective of function fitting and reveal the importance of frame difference. To use explicit motion information, we propose Difference Neural Representation for Videos (DNeRV), which consists of two streams for content and frame difference. We also introduce a collaborative content unit for effective feature fusion. We test DNeRV for video compression, inpainting, and interpolation. DNeRV achieves competitive results against the state-of-the-art neural compression approaches and outperforms existing implicit methods on downstream inpainting and interpolation for $960 \times 1920$ videos.