 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
RusTitW: Russian Language Text Dataset for Visual Text in-the-Wild Recognition
Mar 29, 2023



Information surrounds people in modern life. Text is a very efficient type of information that people use for communication for centuries. However, automated text-in-the-wild recognition remains a challenging problem. The major limitation for a DL system is the lack of training data. For the competitive performance, training set must contain many samples that replicate the real-world cases. While there are many high-quality datasets for English text recognition; there are no available datasets for Russian language. In this paper, we present a large-scale human-labeled dataset for Russian text recognition in-the-wild. We also publish a synthetic dataset and code to reproduce the generation process
Tempo vs. Pitch: understanding self-supervised tempo estimation
Apr 14, 2023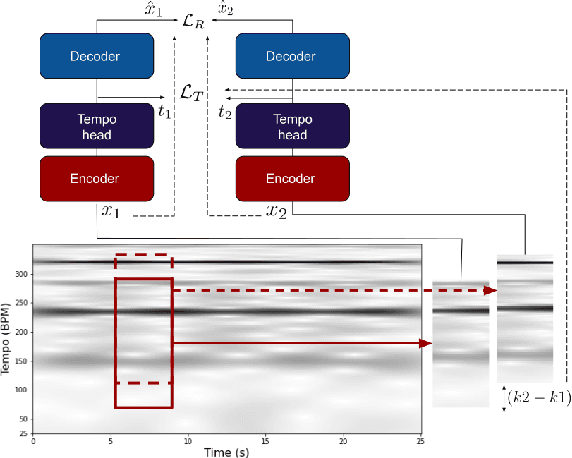
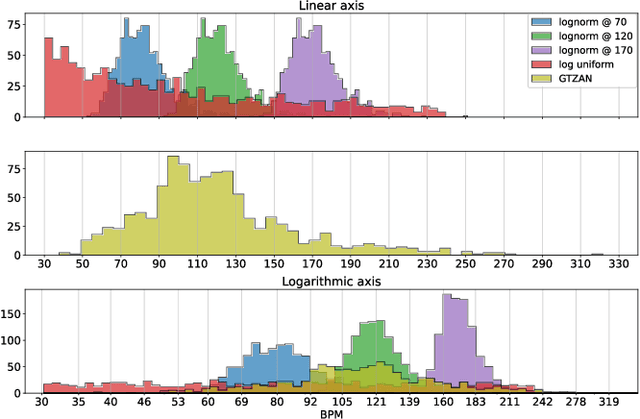
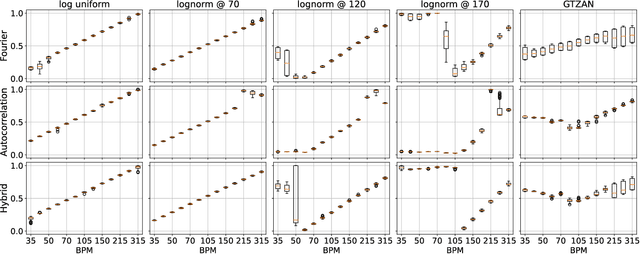
Self-supervision methods learn representations by solving pretext tasks that do not require human-generated labels, alleviating the need for time-consuming annotations. These methods have been applied in computer vision, natural language processing, environmental sound analysis, and recently in music information retrieval, e.g. for pitch estimation. Particularly in the context of music, there are few insights about the fragility of these models regarding different distributions of data, and how they could be mitigated. In this paper, we explore these questions by dissecting a self-supervised model for pitch estimation adapted for tempo estimation via rigorous experimentation with synthetic data. Specifically, we study the relationship between the input representation and data distribution for self-supervised tempo estimation.
Semantic Communication with Memory
Mar 22, 2023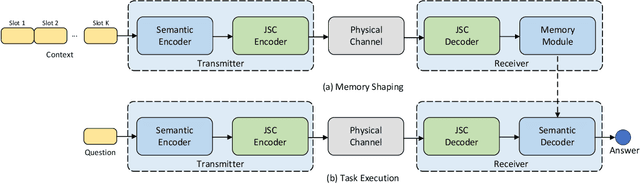
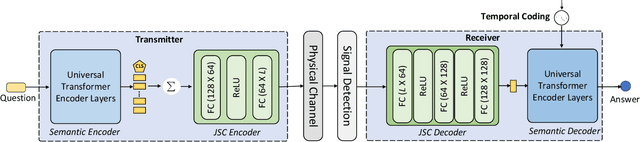
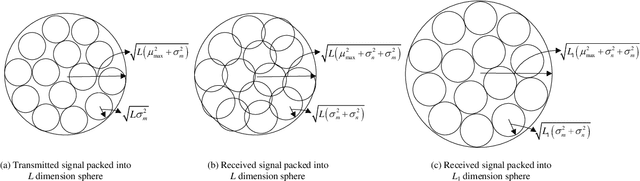
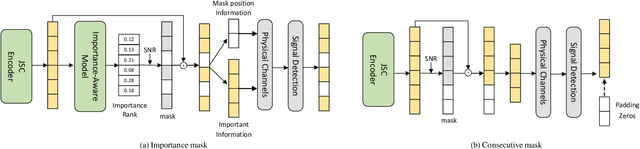
While semantic communication succeeds in efficiently transmitting due to the strong capability to extract the essential semantic information, it is still far from the intelligent or human-like communications. In this paper, we introduce an essential component, memory, into semantic communications to mimic human communications. Particularly, we investigate a deep learning (DL) based semantic communication system with memory, named Mem-DeepSC, by considering the scenario question answer task. We exploit the universal Transformer based transceiver to extract the semantic information and introduce the memory module to process the context information. Moreover, we derive the relationship between the length of semantic signal and the channel noise to validate the possibility of dynamic transmission. Specially, we propose two dynamic transmission methods to enhance the transmission reliability as well as to reduce the communication overhead by masking some unessential elements, which are recognized through training the model with mutual information. Numerical results show that the proposed Mem-DeepSC is superior to benchmarks in terms of answer accuracy and transmission efficiency, i.e., number of transmitted symbols.
Two-Memory Reinforcement Learning
Apr 23, 2023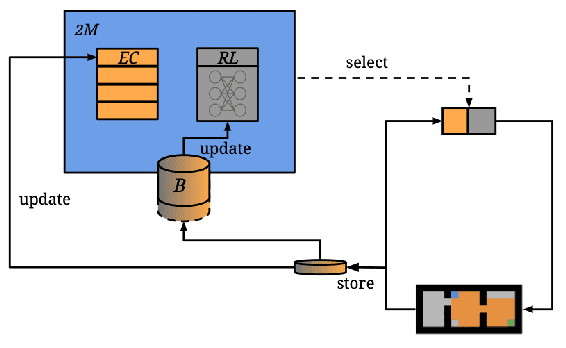
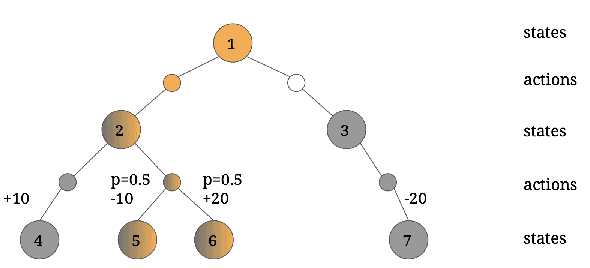

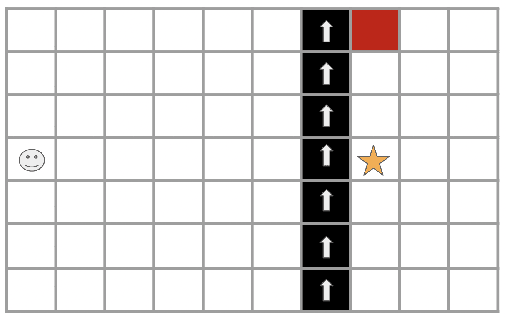
While deep reinforcement learning has shown important empirical success, it tends to learn relatively slow due to slow propagation of rewards information and slow update of parametric neural networks. Non-parametric episodic memory, on the other hand, provides a faster learning alternative that does not require representation learning and uses maximum episodic return as state-action values for action selection. Episodic memory and reinforcement learning both have their own strengths and weaknesses. Notably, humans can leverage multiple memory systems concurrently during learning and benefit from all of them. In this work, we propose a method called Two-Memory reinforcement learning agent (2M) that combines episodic memory and reinforcement learning to distill both of their strengths. The 2M agent exploits the speed of the episodic memory part and the optimality and the generalization capacity of the reinforcement learning part to complement each other. Our experiments demonstrate that the 2M agent is more data efficient and outperforms both pure episodic memory and pure reinforcement learning, as well as a state-of-the-art memory-augmented RL agent. Moreover, the proposed approach provides a general framework that can be used to combine any episodic memory agent with other off-policy reinforcement learning algorithms.
Query-specific Variable Depth Pooling via Query Performance Prediction towards Reducing Relevance Assessment Effort
Apr 23, 2023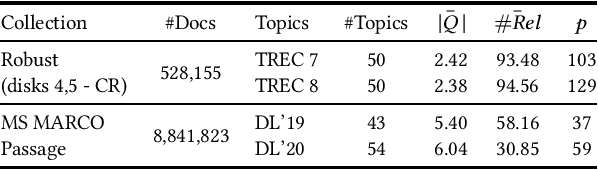
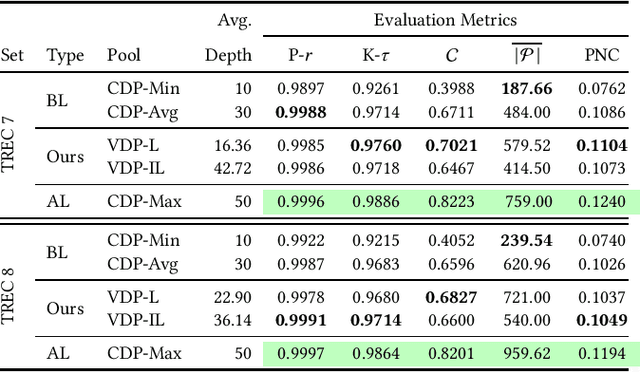
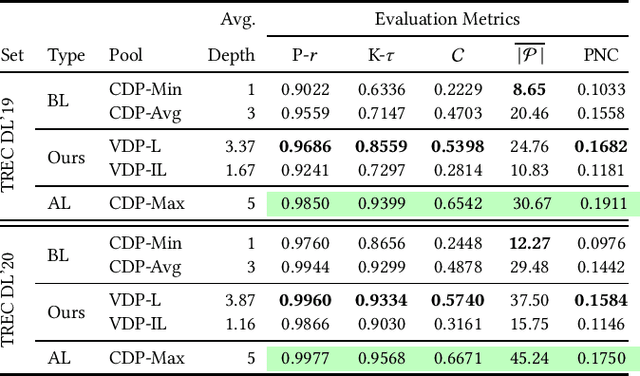
Due to the massive size of test collections, a standard practice in IR evaluation is to construct a 'pool' of candidate relevant documents comprised of the top-k documents retrieved by a wide range of different retrieval systems - a process called depth-k pooling. A standard practice is to set the depth (k) to a constant value for each query constituting the benchmark set. However, in this paper we argue that the annotation effort can be substantially reduced if the depth of the pool is made a variable quantity for each query, the rationale being that the number of documents relevant to the information need can widely vary across queries. Our hypothesis is that a lower depth for the former class of queries and a higher depth for the latter can potentially reduce the annotation effort without a significant change in retrieval effectiveness evaluation. We make use of standard query performance prediction (QPP) techniques to estimate the number of potentially relevant documents for each query, which is then used to determine the depth of the pool. Our experiments conducted on standard test collections demonstrate that this proposed method of employing query-specific variable depths is able to adequately reflect the relative effectiveness of IR systems with a substantially smaller annotation effort.
Sampling-based Path Planning Algorithms: A Survey
Apr 23, 2023

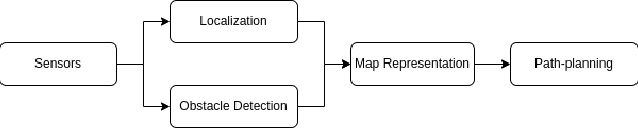

Path planning is a classic problem for autonomous robots. To ensure safe and efficient point-to-point navigation an appropriate algorithm should be chosen keeping the robot's dimensions and its classification in mind. Autonomous robots use path-planning algorithms to safely navigate a dynamic, dense, and unknown environment. A few metrics for path planning algorithms to be taken into account are safety, efficiency, lowest-cost path generation, and obstacle avoidance. Before path planning can take place we need map representation which can be discretized or open configuration space. Discretized configuration space provides node/connectivity information from one point to another. While in open/free configuration space it is up to the algorithm to create a list of nodes and then find a feasible path. Both types of maps are populated by obstacle positions using perception obstacle detection techniques to represent current obstacles from the perspective of the robot. For open configuration spaces, sampling-based planning algorithms are used. This paper aims to explore various types of Sampling-based path-planning algorithms such as Probabilistic RoadMap (PRM), and Rapidly-exploring Random Trees (RRT). These two algorithms also have optimized versions - PRM* and RRT* and this paper discusses how that optimization is achieved and is beneficial.
GamutMLP: A Lightweight MLP for Color Loss Recovery
Apr 23, 2023
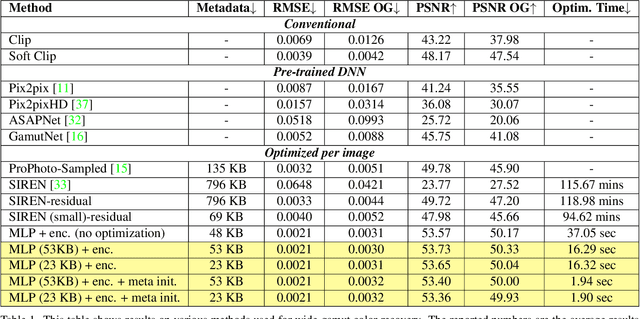
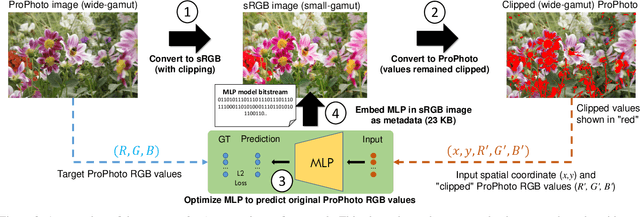
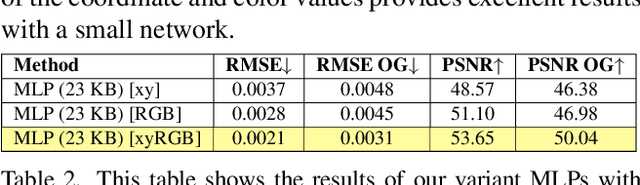
Cameras and image-editing software often process images in the wide-gamut ProPhoto color space, encompassing 90% of all visible colors. However, when images are encoded for sharing, this color-rich representation is transformed and clipped to fit within the small-gamut standard RGB (sRGB) color space, representing only 30% of visible colors. Recovering the lost color information is challenging due to the clipping procedure. Inspired by neural implicit representations for 2D images, we propose a method that optimizes a lightweight multi-layer-perceptron (MLP) model during the gamut reduction step to predict the clipped values. GamutMLP takes approximately 2 seconds to optimize and requires only 23 KB of storage. The small memory footprint allows our GamutMLP model to be saved as metadata in the sRGB image -- the model can be extracted when needed to restore wide-gamut color values. We demonstrate the effectiveness of our approach for color recovery and compare it with alternative strategies, including pre-trained DNN-based gamut expansion networks and other implicit neural representation methods. As part of this effort, we introduce a new color gamut dataset of 2200 wide-gamut/small-gamut images for training and testing. Our code and dataset can be found on the project website: https://gamut-mlp.github.io.
cTBL: Augmenting Large Language Models for Conversational Tables
Mar 22, 2023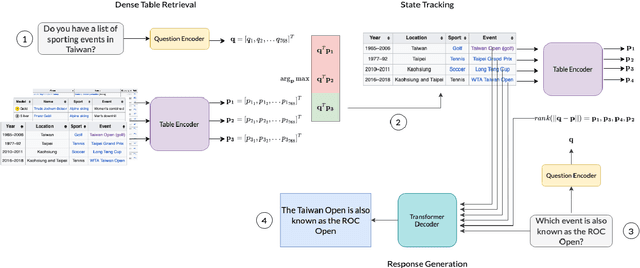
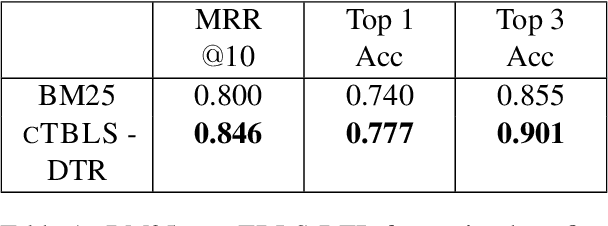

An open challenge in multimodal conversational AI requires augmenting large language models with information from textual and non-textual sources for multi-turn dialogue. To address this problem, this paper introduces Conversational Tables (cTBL), a three-step encoder-decoder approach to retrieve tabular information and generate dialogue responses grounded on the retrieved information. cTBL uses Transformer encoder embeddings for Dense Table Retrieval and obtains up to 5% relative improvement in Top-1 and Top-3 accuracy over sparse retrieval on the HyrbiDialogue dataset. Additionally, cTBL performs tabular knowledge retrieval using both encoder and decoder models, resulting in up to 46% relative improvement in ROUGE scores and better human evaluation for response generation on HyrbiDialogue.
Optimal Semantic-aware Sampling and Transmission in Energy Harvesting Systems Through the AoII
Apr 03, 2023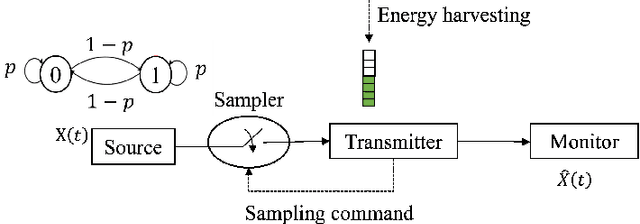
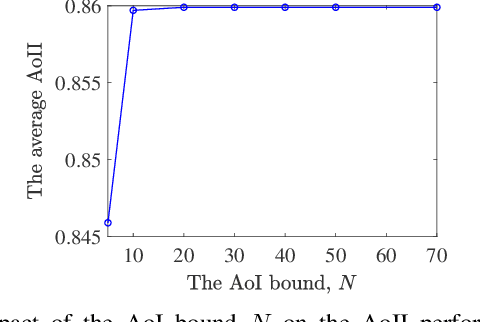
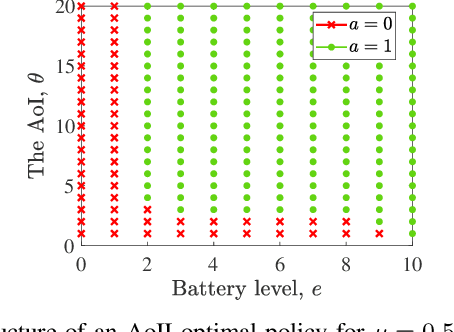
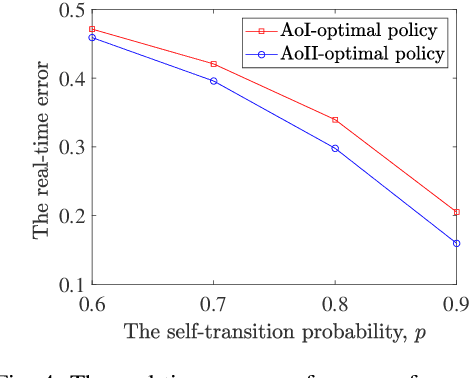
We study a real-time tracking problem in an energy harvesting status update system with a Markov source under both sampling and transmission costs. The problem's primary challenge stems from the non-observability of the source due to the sampling cost. By using the age of incorrect information (AoII) as a semantic-aware performance metric, our main goal is to find an optimal policy that minimizes the time average AoII subject to an energy-causality constraint. To this end, a stochastic optimization problem is formulated and solved by modeling it as a partially observable Markov decision process. More specifically, to solve the problem, we use the notion of belief state and by characterizing the belief space, we cast the main problem as an MDP whose cost function is a non-linear function of the age of information (AoI) and solve it via relative value iteration. Simulation results show the effectiveness of the derived policy, with a double-threshold structure on the battery levels and AoI.
Focalized Contrastive View-invariant Learning for Self-supervised Skeleton-based Action Recognition
Apr 03, 2023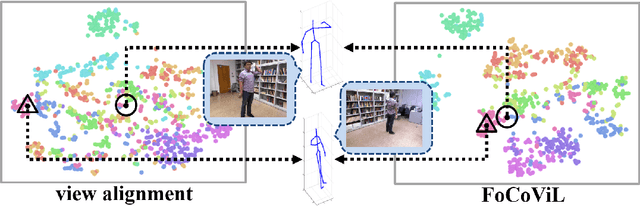
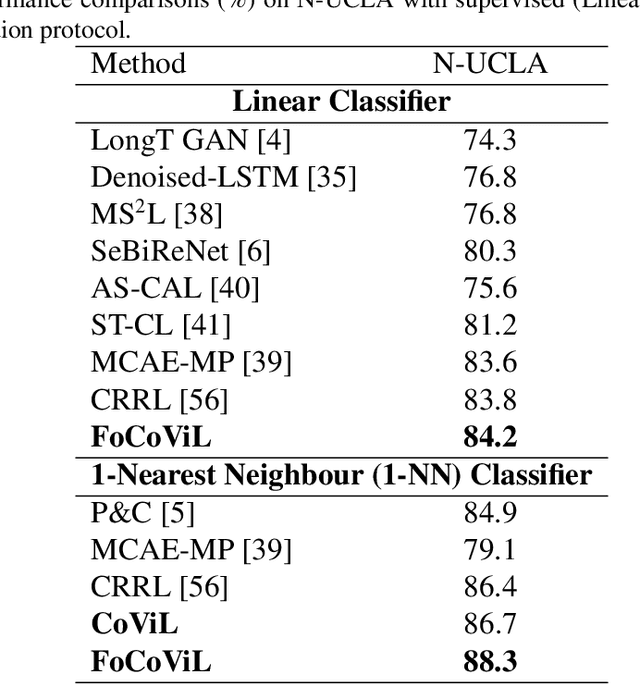
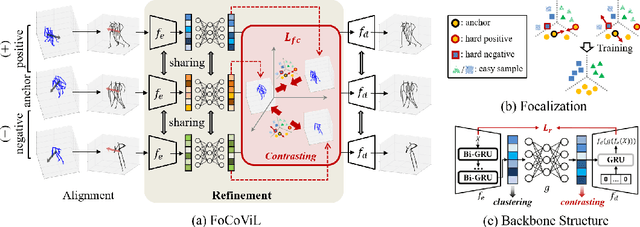
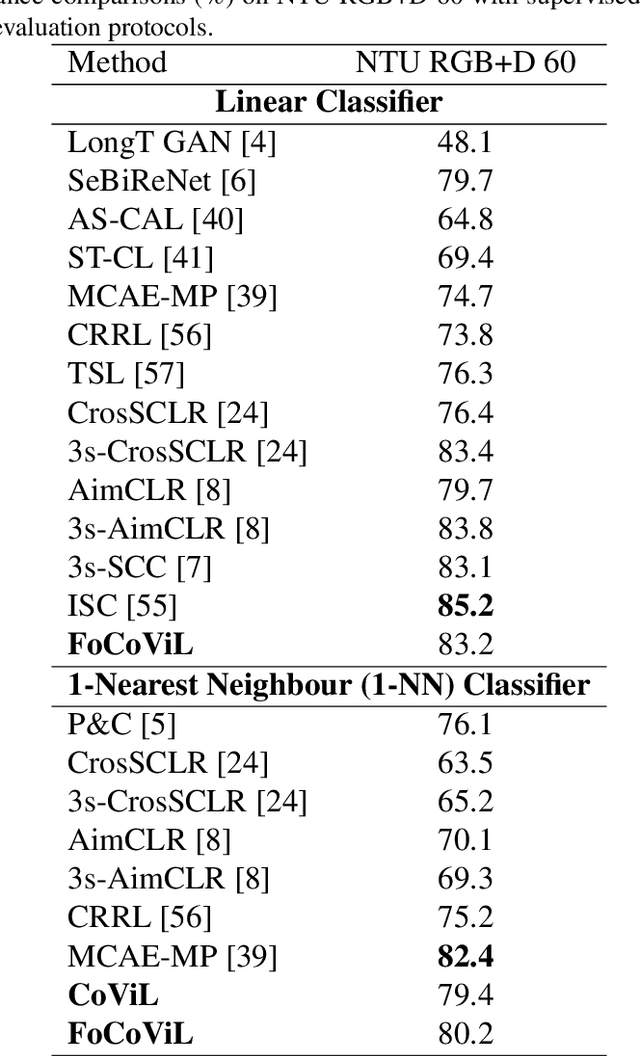
Learning view-invariant representation is a key to improving feature discrimination power for skeleton-based action recognition. Existing approaches cannot effectively remove the impact of viewpoint due to the implicit view-dependent representations. In this work, we propose a self-supervised framework called Focalized Contrastive View-invariant Learning (FoCoViL), which significantly suppresses the view-specific information on the representation space where the viewpoints are coarsely aligned. By maximizing mutual information with an effective contrastive loss between multi-view sample pairs, FoCoViL associates actions with common view-invariant properties and simultaneously separates the dissimilar ones. We further propose an adaptive focalization method based on pairwise similarity to enhance contrastive learning for a clearer cluster boundary in the learned space. Different from many existing self-supervised representation learning work that rely heavily on supervised classifiers, FoCoViL performs well on both unsupervised and supervised classifiers with superior recognition performance. Extensive experiments also show that the proposed contrastive-based focalization generates a more discriminative latent representation.