 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Dynamics of Social Networks: Multi-agent Information Fusion, Anticipatory Decision Making and Polling
Dec 26, 2022
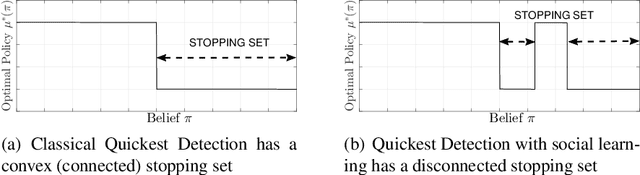
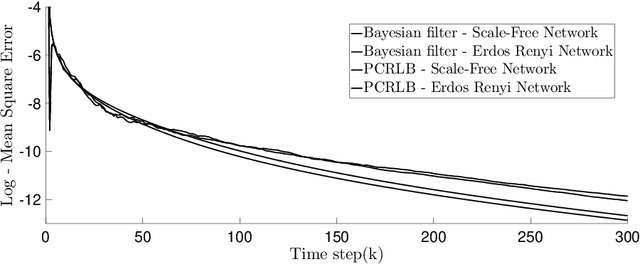
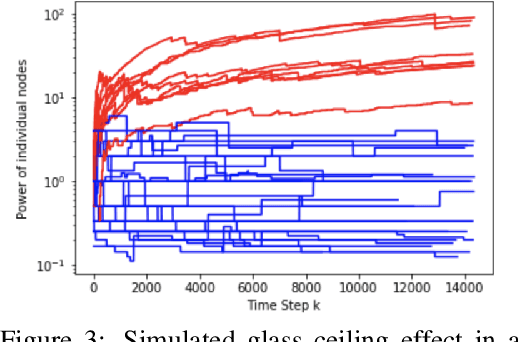
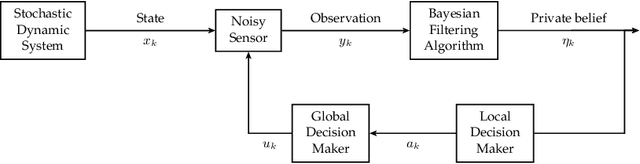
This paper surveys mathematical models, structural results and algorithms in controlled sensing with social learning in social networks. Part 1, namely Bayesian Social Learning with Controlled Sensing addresses the following questions: How does risk averse behavior in social learning affect quickest change detection? How can information fusion be priced? How is the convergence rate of state estimation affected by social learning? The aim is to develop and extend structural results in stochastic control and Bayesian estimation to answer these questions. Such structural results yield fundamental bounds on the optimal performance, give insight into what parameters affect the optimal policies, and yield computationally efficient algorithms. Part 2, namely, Multi-agent Information Fusion with Behavioral Economics Constraints generalizes Part 1. The agents exhibit sophisticated decision making in a behavioral economics sense; namely the agents make anticipatory decisions (thus the decision strategies are time inconsistent and interpreted as subgame Bayesian Nash equilibria). Part 3, namely {\em Interactive Sensing in Large Networks}, addresses the following questions: How to track the degree distribution of an infinite random graph with dynamics (via a stochastic approximation on a Hilbert space)? How can the infected degree distribution of a Markov modulated power law network and its mean field dynamics be tracked via Bayesian filtering given incomplete information obtained by sampling the network? We also briefly discuss how the glass ceiling effect emerges in social networks. Part 4, namely \emph{Efficient Network Polling} deals with polling in large scale social networks. In such networks, only a fraction of nodes can be polled to determine their decisions. Which nodes should be polled to achieve a statistically accurate estimates?
Replicating Complex Dialogue Policy of Humans via Offline Imitation Learning with Supervised Regularization
May 06, 2023
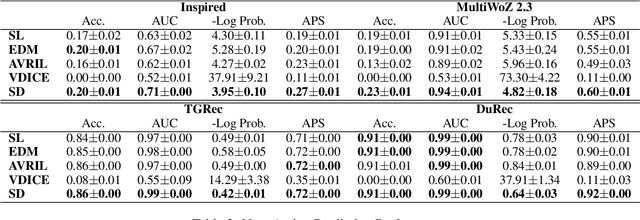
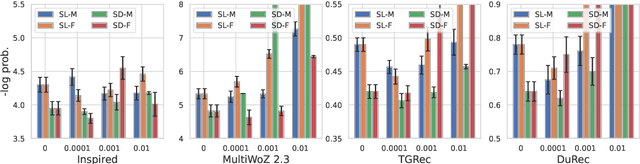
Policy learning (PL) is a module of a task-oriented dialogue system that trains an agent to make actions in each dialogue turn. Imitating human action is a fundamental problem of PL. However, both supervised learning (SL) and reinforcement learning (RL) frameworks cannot imitate humans well. Training RL models require online interactions with user simulators, while simulating complex human policy is hard. Performances of SL-based models are restricted because of the covariate shift problem. Specifically, a dialogue is a sequential decision-making process where slight differences in current utterances and actions will cause significant differences in subsequent utterances. Therefore, the generalize ability of SL models is restricted because statistical characteristics of training and testing dialogue data gradually become different. This study proposed an offline imitation learning model that learns policy from real dialogue datasets and does not require user simulators. It also utilizes state transition information, which alleviates the influence of the covariate shift problem. We introduced a regularization trick to make our model can be effectively optimized. We investigated the performance of our model on four independent public dialogue datasets. The experimental result showed that our model performed better in the action prediction task.
Leveraging Semantic Relationships to Prioritise Indicators of Compromise in Additive Manufacturing Systems
May 06, 2023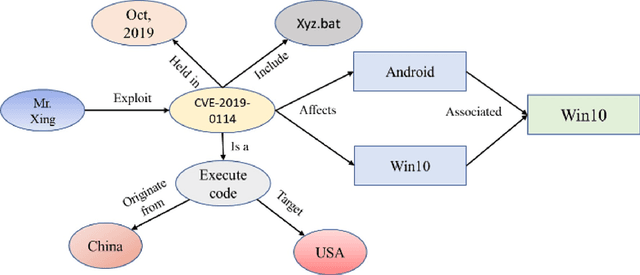

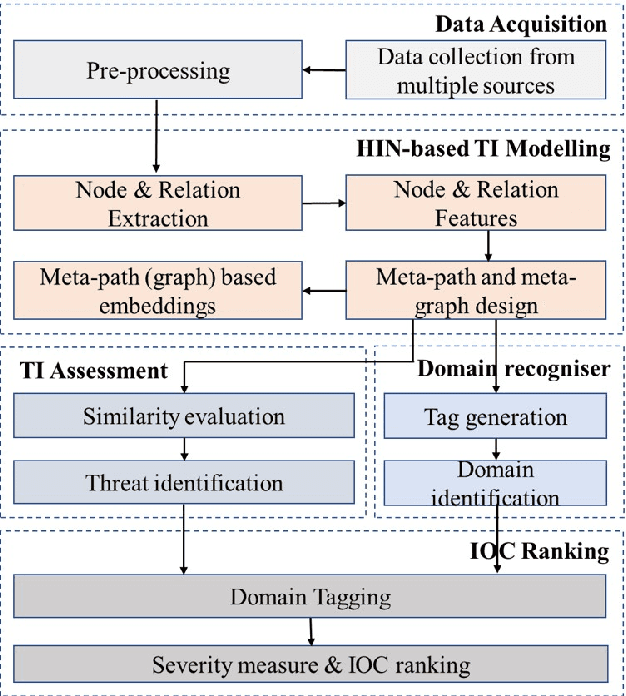
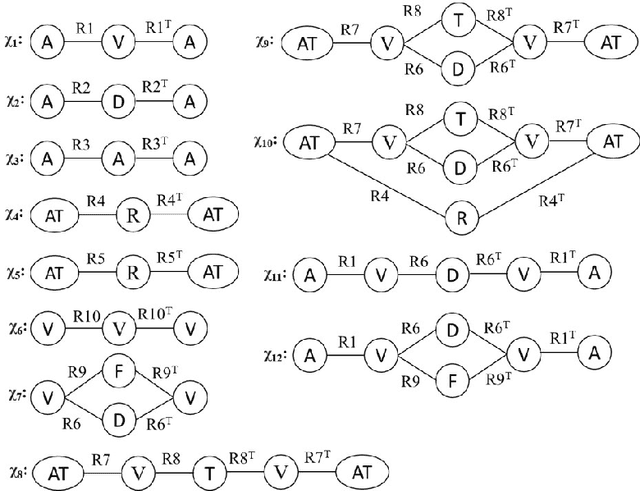
Additive manufacturing (AM) offers numerous benefits, such as manufacturing complex and customised designs quickly and cost-effectively, reducing material waste, and enabling on-demand production. However, several security challenges are associated with AM, making it increasingly attractive to attackers ranging from individual hackers to organised criminal gangs and nation-state actors. This paper addresses the cyber risk in AM to attackers by proposing a novel semantic-based threat prioritisation system for identifying, extracting and ranking indicators of compromise (IOC). The system leverages the heterogeneous information networks (HINs) that automatically extract high-level IOCs from multi-source threat text and identifies semantic relations among the IOCs. It models IOCs with a HIN comprising different meta-paths and meta-graphs to depict semantic relations among diverse IOCs. We introduce a domain-specific recogniser that identifies IOCs in three domains: organisation-specific, regional source-specific, and regional target-specific. A threat assessment uses similarity measures based on meta-paths and meta-graphs to assess semantic relations among IOCs. It prioritises IOCs by measuring their severity based on the frequency of attacks, IOC lifetime, and exploited vulnerabilities in each domain.
PCRLv2: A Unified Visual Information Preservation Framework for Self-supervised Pre-training in Medical Image Analysis
Jan 02, 2023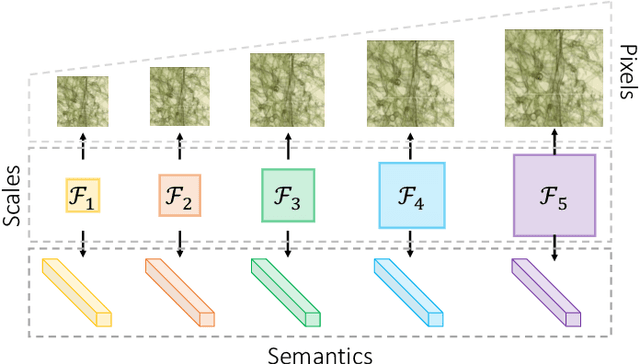
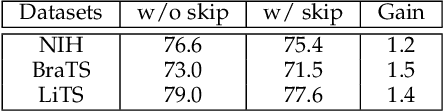
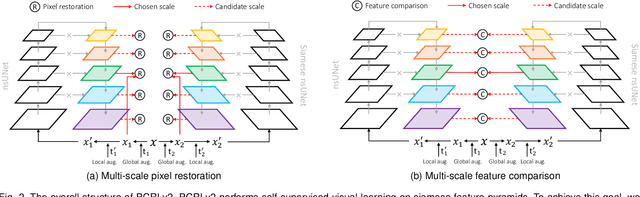
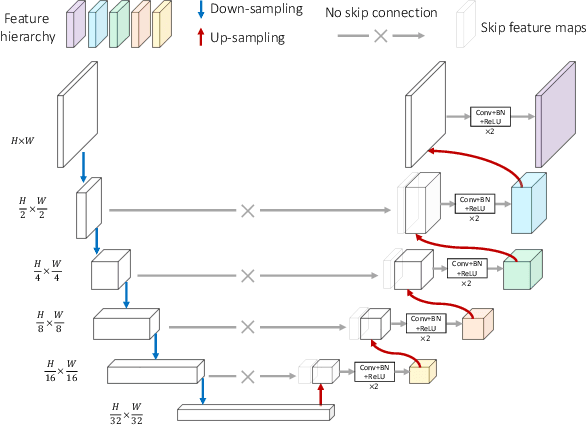
Recent advances in self-supervised learning (SSL) in computer vision are primarily comparative, whose goal is to preserve invariant and discriminative semantics in latent representations by comparing siamese image views. However, the preserved high-level semantics do not contain enough local information, which is vital in medical image analysis (e.g., image-based diagnosis and tumor segmentation). To mitigate the locality problem of comparative SSL, we propose to incorporate the task of pixel restoration for explicitly encoding more pixel-level information into high-level semantics. We also address the preservation of scale information, a powerful tool in aiding image understanding but has not drawn much attention in SSL. The resulting framework can be formulated as a multi-task optimization problem on the feature pyramid. Specifically, we conduct multi-scale pixel restoration and siamese feature comparison in the pyramid. In addition, we propose non-skip U-Net to build the feature pyramid and develop sub-crop to replace multi-crop in 3D medical imaging. The proposed unified SSL framework (PCRLv2) surpasses its self-supervised counterparts on various tasks, including brain tumor segmentation (BraTS 2018), chest pathology identification (ChestX-ray, CheXpert), pulmonary nodule detection (LUNA), and abdominal organ segmentation (LiTS), sometimes outperforming them by large margins with limited annotations.
LESS-VFL: Communication-Efficient Feature Selection for Vertical Federated Learning
May 03, 2023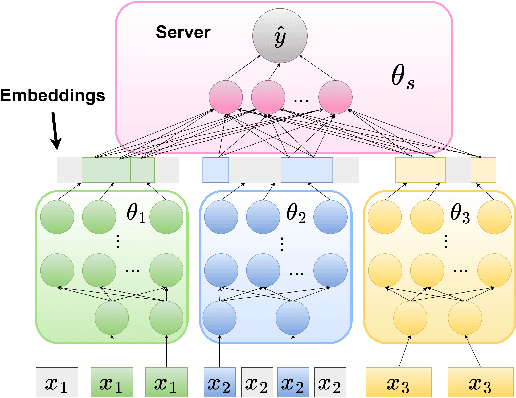
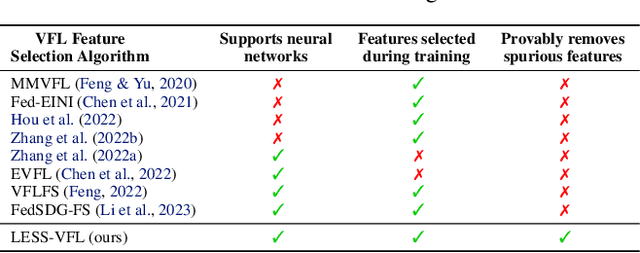
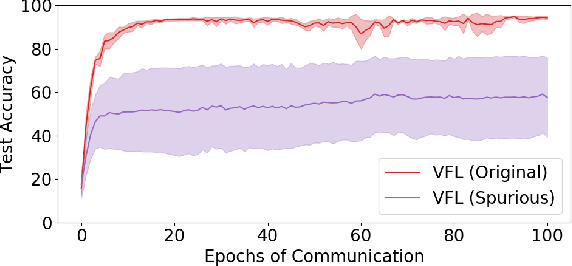
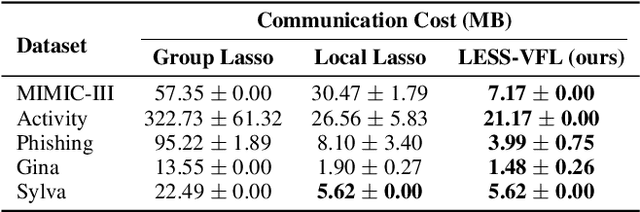
We propose LESS-VFL, a communication-efficient feature selection method for distributed systems with vertically partitioned data. We consider a system of a server and several parties with local datasets that share a sample ID space but have different feature sets. The parties wish to collaboratively train a model for a prediction task. As part of the training, the parties wish to remove unimportant features in the system to improve generalization, efficiency, and explainability. In LESS-VFL, after a short pre-training period, the server optimizes its part of the global model to determine the relevant outputs from party models. This information is shared with the parties to then allow local feature selection without communication. We analytically prove that LESS-VFL removes spurious features from model training. We provide extensive empirical evidence that LESS-VFL can achieve high accuracy and remove spurious features at a fraction of the communication cost of other feature selection approaches.
A New Non-Negative Matrix Factorization Approach for Blind Source Separation of Cardiovascular and Respiratory Sound Based on the Periodicity of Heart and Lung Function
May 03, 2023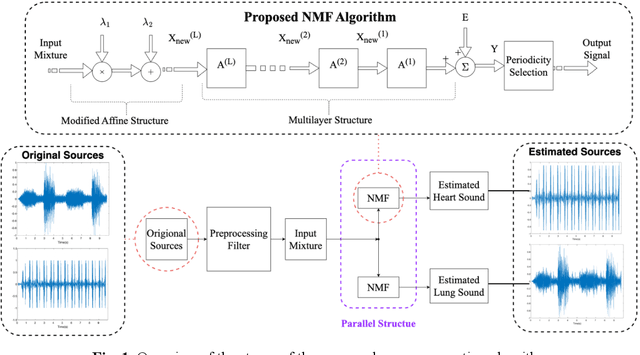
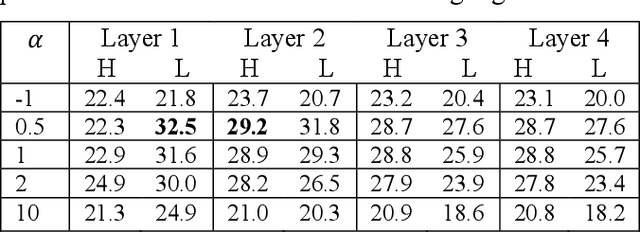
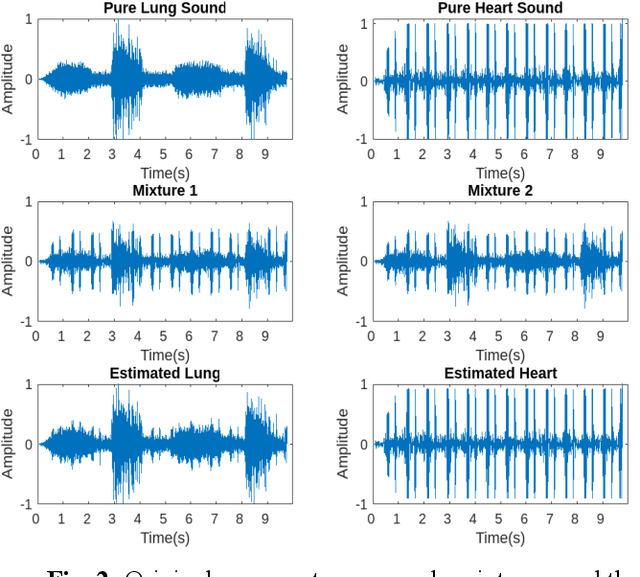
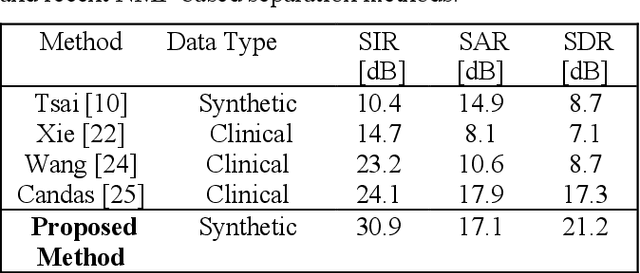
Auscultation provides a rich diversity of information to diagnose cardiovascular and respiratory diseases. However, sound auscultation is challenging due to noise. In this study, a modified version of the affine non-negative matrix factorization (NMF) approach is proposed to blindly separate lung and heart sounds recorded by a digital stethoscope. This method applies a novel NMF algorithm, which embodies a parallel structure of multilayer units on the input signal, to find a proper estimation of source signals. Another key innovation is the use of the periodic property of the signals which improves accuracy compared to previous works. The method is tested on 100 cases. Each case consists of two synthesized mixtures of real measurements. The effect of different parameters is discussed, and the results are compared to other current methods. Results demonstrate improvements in the source-to-distortion ratio (SDR), source-to-interference ratio (SIR), and source-to-artifacts ratio (SAR) of heart and lung sounds, respectively.
Biological Hotspot Mapping in Coral Reefs with Robotic Visual Surveys
May 03, 2023
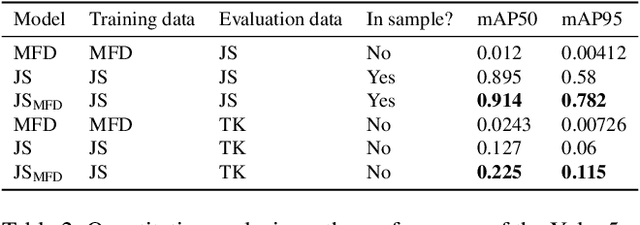

Coral reefs are fast-changing and complex ecosystems that are crucial to monitor and study. Biological hotspot detection can help coral reef managers prioritize limited resources for monitoring and intervention tasks. Here, we explore the use of autonomous underwater vehicles (AUVs) with cameras, coupled with visual detectors and photogrammetry, to map and identify these hotspots. This approach can provide high spatial resolution information in fast feedback cycles. To the best of our knowledge, we present one of the first attempts at using an AUV to gather visually-observed, fine-grain biological hotspot maps in concert with topography of a coral reefs. Our hotspot maps correlate with rugosity, an established proxy metric for coral reef biodiversity and abundance, as well as with our visual inspections of the 3D reconstruction. We also investigate issues of scaling this approach when applied to new reefs by using these visual detectors pre-trained on large public datasets.
Decentralised Active Perception in Continuous Action Spaces for the Coordinated Escort Problem
May 03, 2023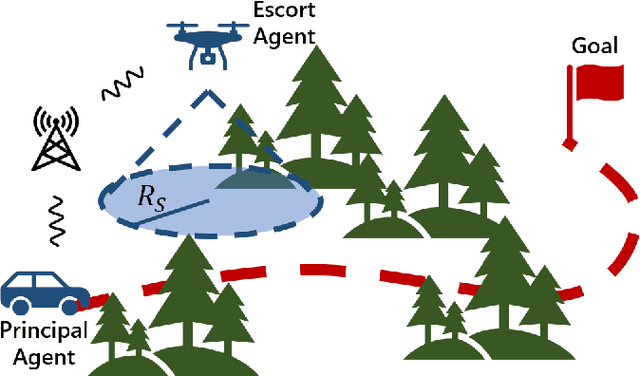
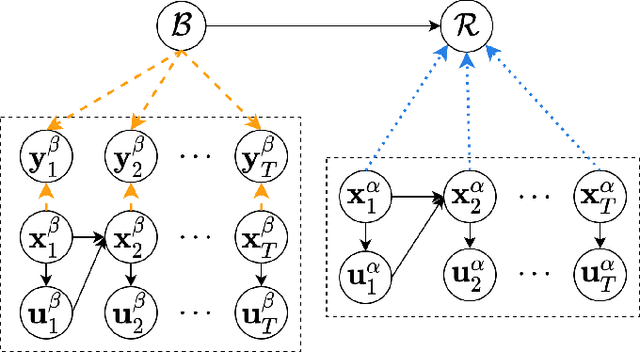
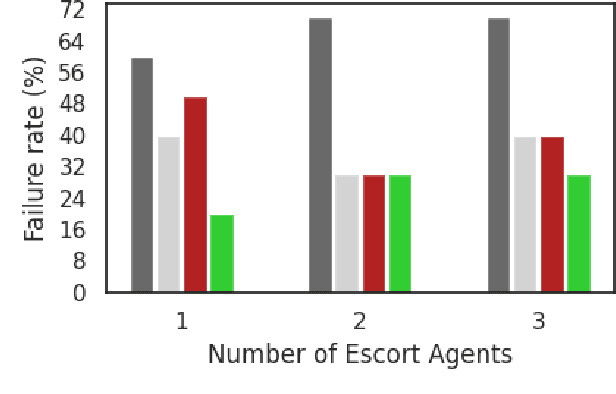
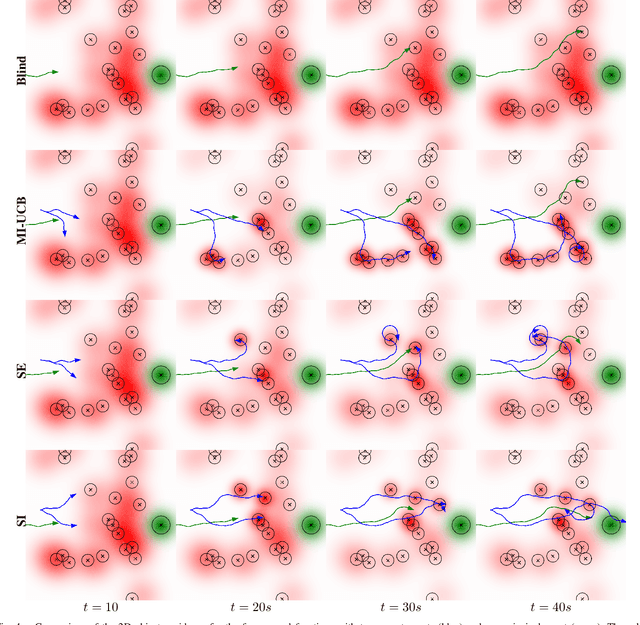
We consider the coordinated escort problem, where a decentralised team of supporting robots implicitly assist the mission of higher-value principal robots. The defining challenge is how to evaluate the effect of supporting robots' actions on the principal robots' mission. To capture this effect, we define two novel auxiliary reward functions for supporting robots called satisfaction improvement and satisfaction entropy, which computes the improvement in probability of mission success, or the uncertainty thereof. Given these reward functions, we coordinate the entire team of principal and supporting robots using decentralised cross entropy method (Dec-CEM), a new extension of CEM to multi-agent systems based on the product distribution approximation. In a simulated object avoidance scenario, our planning framework demonstrates up to two-fold improvement in task satisfaction against conventional decoupled information gathering.The significance of our results is to introduce a new family of algorithmic problems that will enable important new practical applications of heterogeneous multi-robot systems.
Asymmetric quantum decision-making
May 03, 2023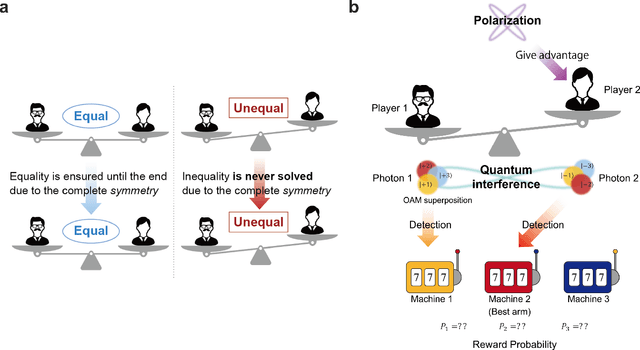
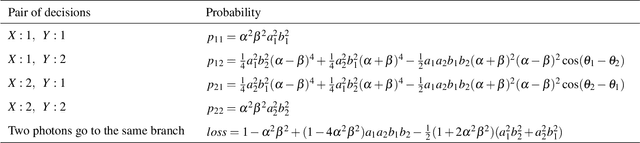
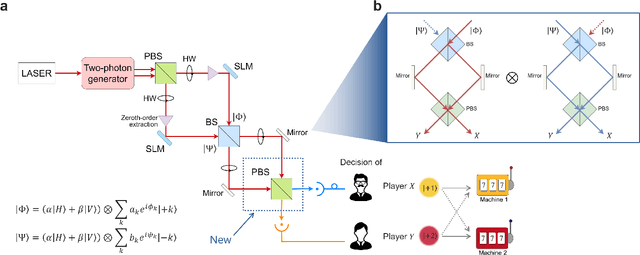

Collective decision-making is crucial to information and communication systems. Decision conflicts among agents hinder the maximization of potential utilities of the entire system. Quantum processes can realize conflict-free joint decisions among two agents using the entanglement of photons or quantum interference of orbital angular momentum (OAM). However, previous studies have always presented symmetric resultant joint decisions. Although this property helps maintain and preserve equality, it cannot resolve disparities. Global challenges, such as ethics and equity, are recognized in the field of responsible artificial intelligence as responsible research and innovation paradigm. Thus, decision-making systems must not only preserve existing equality but also tackle disparities. This study theoretically and numerically investigates asymmetric collective decision-making using quantum interference of photons carrying OAM or entangled photons. Although asymmetry is successfully realized, a photon loss is inevitable in the proposed models. The available range of asymmetry and method for obtaining the desired degree of asymmetry are analytically formulated.
Diverse and Vivid Sound Generation from Text Descriptions
May 03, 2023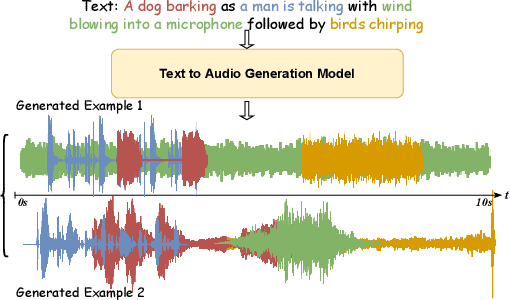
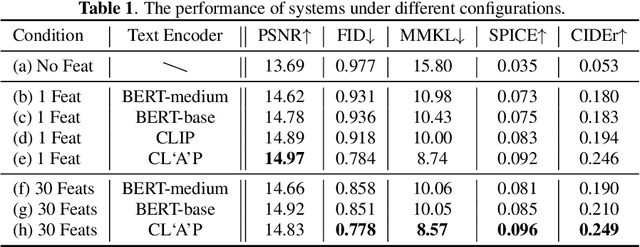
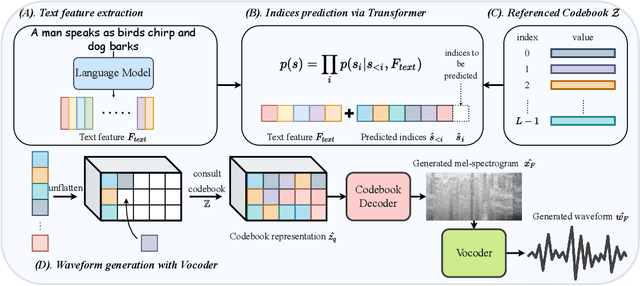

Previous audio generation mainly focuses on specified sound classes such as speech or music, whose form and content are greatly restricted. In this paper, we go beyond specific audio generation by using natural language description as a clue to generate broad sounds. Unlike visual information, a text description is concise by its nature but has rich hidden meanings beneath, which poses a higher possibility and complexity on the audio to be generated. A Variation-Quantized GAN is used to train a codebook learning discrete representations of spectrograms. For a given text description, its pre-trained embedding is fed to a Transformer to sample codebook indices to decode a spectrogram to be further transformed into waveform by a melgan vocoder. The generated waveform has high quality and fidelity while excellently corresponding to the given text. Experiments show that our proposed method is capable of generating natural, vivid audios, achieving superb quantitative and qualitative results.