 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards Automated COVID-19 Presence and Severity Classification
May 15, 2023
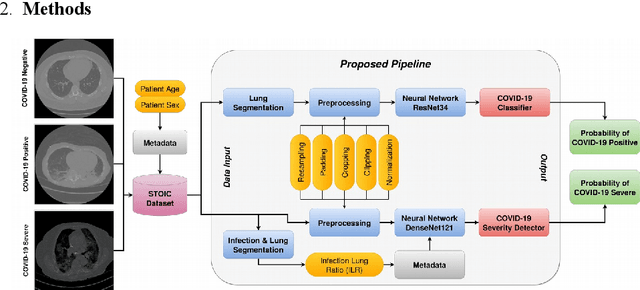
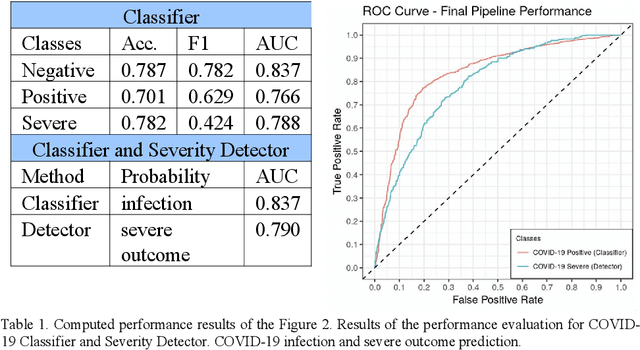
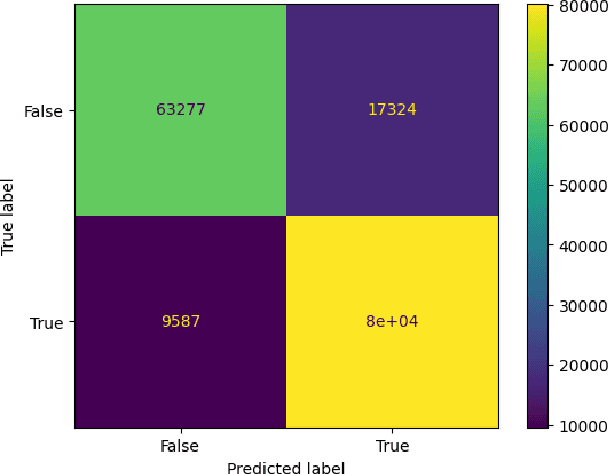
COVID-19 presence classification and severity prediction via (3D) thorax computed tomography scans have become important tasks in recent times. Especially for capacity planning of intensive care units, predicting the future severity of a COVID-19 patient is crucial. The presented approach follows state-of-theart techniques to aid medical professionals in these situations. It comprises an ensemble learning strategy via 5-fold cross-validation that includes transfer learning and combines pre-trained 3D-versions of ResNet34 and DenseNet121 for COVID19 classification and severity prediction respectively. Further, domain-specific preprocessing was applied to optimize model performance. In addition, medical information like the infection-lung-ratio, patient age, and sex were included. The presented model achieves an AUC of 79.0% to predict COVID-19 severity, and 83.7% AUC to classify the presence of an infection, which is comparable with other currently popular methods. This approach is implemented using the AUCMEDI framework and relies on well-known network architectures to ensure robustness and reproducibility.
Text2Gender: A Deep Learning Architecture for Analysis of Blogger's Age and Gender
May 15, 2023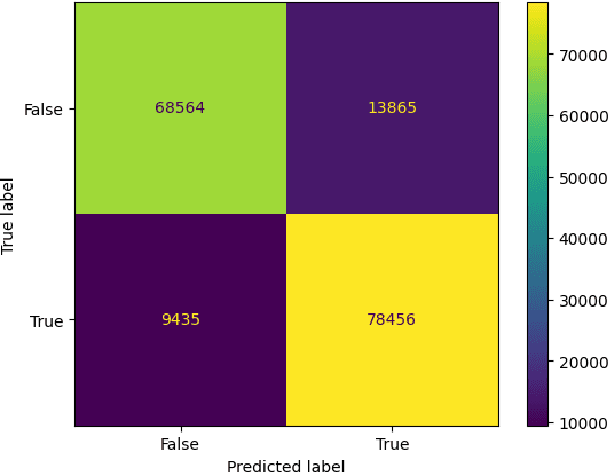
Deep learning techniques have gained a lot of traction in the field of NLP research. The aim of this paper is to predict the age and gender of an individual by inspecting their written text. We propose a supervised BERT-based classification technique in order to predict the age and gender of bloggers. The dataset used contains 681284 rows of data, with the information of the blogger's age, gender, and text of the blog written by them. We compare our algorithm to previous works in the same domain and achieve a better accuracy and F1 score. The accuracy reported for the prediction of age group was 84.2%, while the accuracy for the prediction of gender was 86.32%. This study relies on the raw capabilities of BERT to predict the classes of textual data efficiently. This paper shows promising capability in predicting the demographics of the author with high accuracy and can have wide applicability across multiple domains.
Using LLM-assisted Annotation for Corpus Linguistics: A Case Study of Local Grammar Analysis
May 15, 2023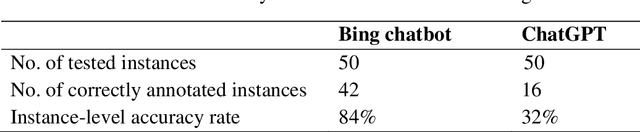

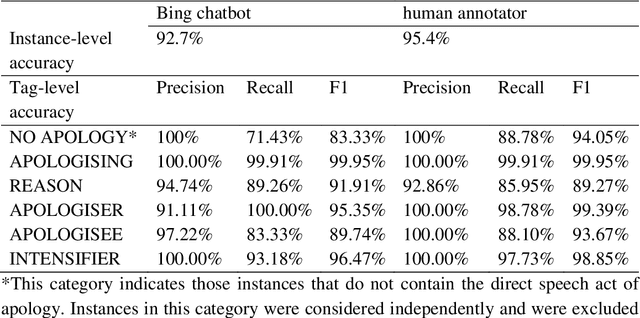
Chatbots based on Large Language Models (LLMs) have shown strong capabilities in language understanding. In this study, we explore the potential of LLMs in assisting corpus-based linguistic studies through automatic annotation of texts with specific categories of linguistic information. Specifically, we examined to what extent LLMs understand the functional elements constituting the speech act of apology from a local grammar perspective, by comparing the performance of ChatGPT (powered by GPT-3.5), Bing chatbot (powered by GPT-4), and a human coder in the annotation task. The results demonstrate that Bing chatbot significantly outperformed ChatGPT in the task. Compared to human annotator, the overall performance of Bing chatbot was slightly less satisfactory. However, it already achieved high F1 scores: 99.95% for the tag of APOLOGISING, 91.91% for REASON, 95.35% for APOLOGISER, 89.74% for APOLOGISEE, and 96.47% for INTENSIFIER. Therefore, we propose that LLM-assisted annotation is a promising automated approach for corpus studies.
Measuring Consistency in Text-based Financial Forecasting Models
May 15, 2023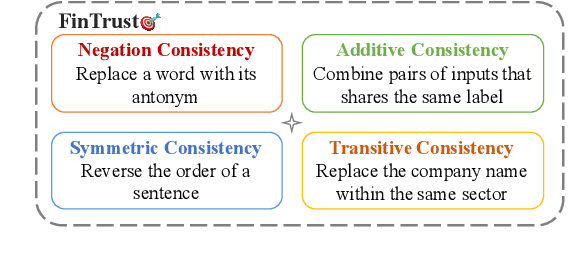
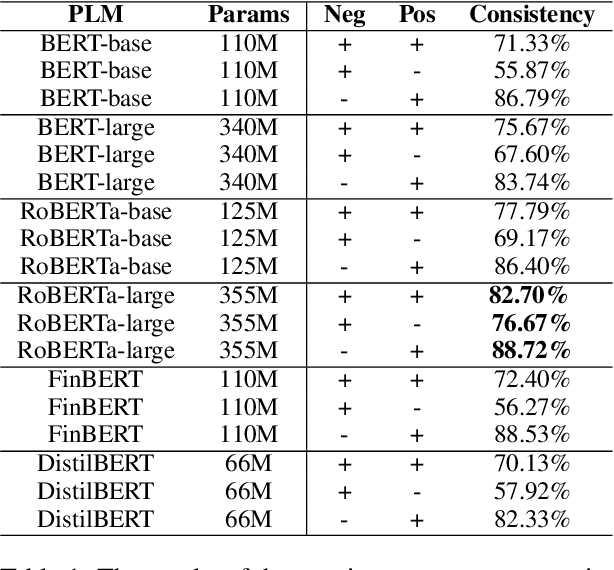

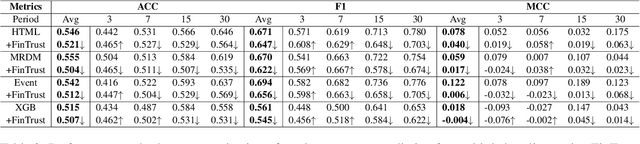
Financial forecasting has been an important and active area of machine learning research, as even the most modest advantage in predictive accuracy can be parlayed into significant financial gains. Recent advances in natural language processing (NLP) bring the opportunity to leverage textual data, such as earnings reports of publicly traded companies, to predict the return rate for an asset. However, when dealing with such a sensitive task, the consistency of models -- their invariance under meaning-preserving alternations in input -- is a crucial property for building user trust. Despite this, current financial forecasting methods do not consider consistency. To address this problem, we propose FinTrust, an evaluation tool that assesses logical consistency in financial text. Using FinTrust, we show that the consistency of state-of-the-art NLP models for financial forecasting is poor. Our analysis of the performance degradation caused by meaning-preserving alternations suggests that current text-based methods are not suitable for robustly predicting market information. All resources are available on GitHub.
CSP: Self-Supervised Contrastive Spatial Pre-Training for Geospatial-Visual Representations
May 01, 2023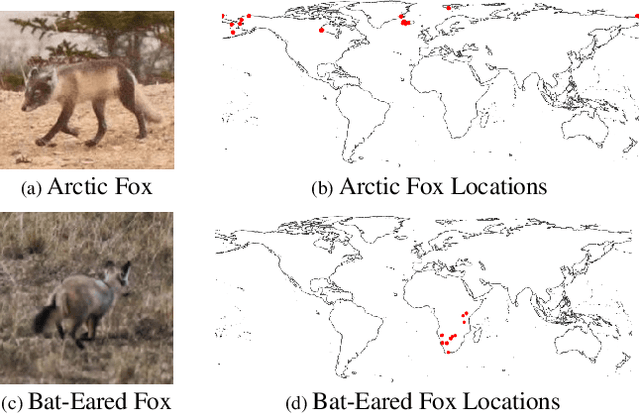
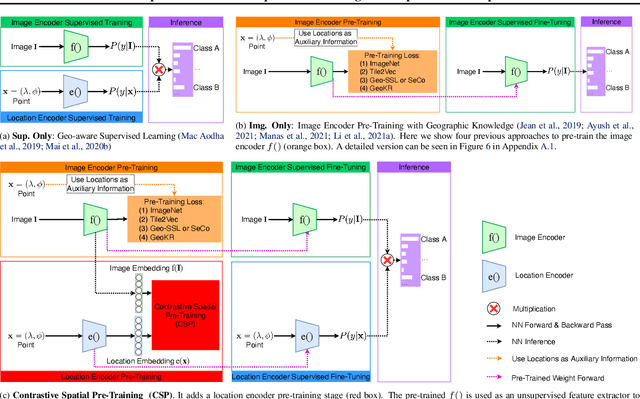
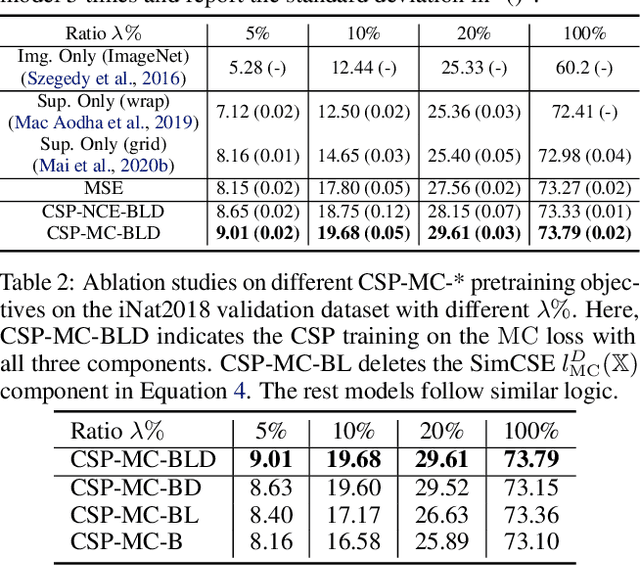

Geo-tagged images are publicly available in large quantities, whereas labels such as object classes are rather scarce and expensive to collect. Meanwhile, contrastive learning has achieved tremendous success in various natural image and language tasks with limited labeled data. However, existing methods fail to fully leverage geospatial information, which can be paramount to distinguishing objects that are visually similar. To directly leverage the abundant geospatial information associated with images in pre-training, fine-tuning, and inference stages, we present Contrastive Spatial Pre-Training (CSP), a self-supervised learning framework for geo-tagged images. We use a dual-encoder to separately encode the images and their corresponding geo-locations, and use contrastive objectives to learn effective location representations from images, which can be transferred to downstream supervised tasks such as image classification. Experiments show that CSP can improve model performance on both iNat2018 and fMoW datasets. Especially, on iNat2018, CSP significantly boosts the model performance with 10-34% relative improvement with various labeled training data sampling ratios.
LLM-Pruner: On the Structural Pruning of Large Language Models
May 19, 2023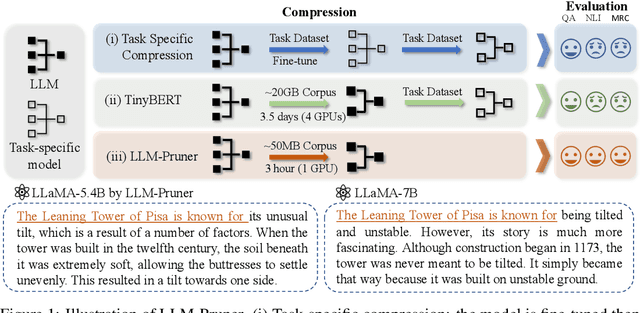
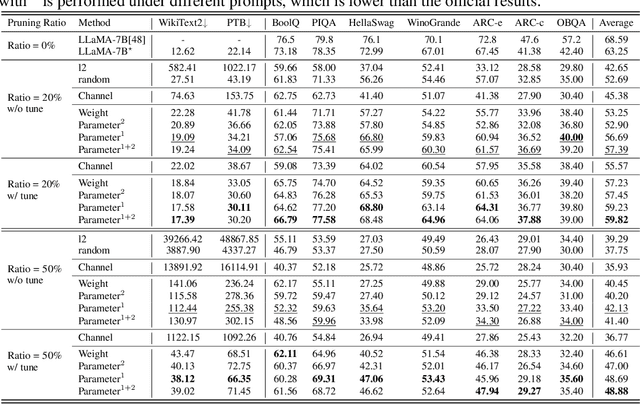
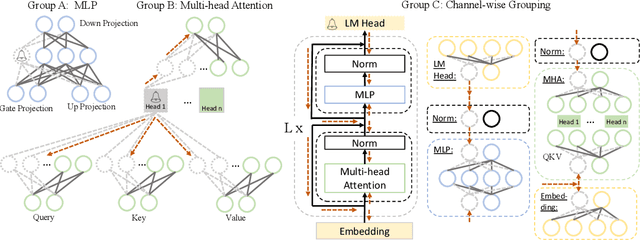
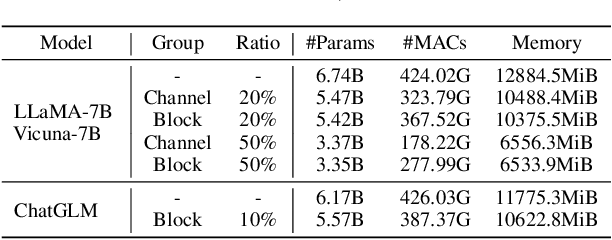
Large language models (LLMs) have shown remarkable capabilities in language understanding and generation. However, such impressive capability typically comes with a substantial model size, which presents significant challenges in both the deployment, inference, and training stages. With LLM being a general-purpose task solver, we explore its compression in a task-agnostic manner, which aims to preserve the multi-task solving and language generation ability of the original LLM. One challenge to achieving this is the enormous size of the training corpus of LLM, which makes both data transfer and model post-training over-burdensome. Thus, we tackle the compression of LLMs within the bound of two constraints: being task-agnostic and minimizing the reliance on the original training dataset. Our method, named LLM-Pruner, adopts structural pruning that selectively removes non-critical coupled structures based on gradient information, maximally preserving the majority of the LLM's functionality. To this end, the performance of pruned models can be efficiently recovered through tuning techniques, LoRA, in merely 3 hours, requiring only 50K data. We validate the LLM-Pruner on three LLMs, including LLaMA, Vicuna, and ChatGLM, and demonstrate that the compressed models still exhibit satisfactory capabilities in zero-shot classification and generation. The code is available at: https://github.com/horseee/LLM-Pruner
Towards Achieving Near-optimal Utility for Privacy-Preserving Federated Learning via Data Generation and Parameter Distortion
May 19, 2023
Federated learning (FL) enables participating parties to collaboratively build a global model with boosted utility without disclosing private data information. Appropriate protection mechanisms have to be adopted to fulfill the requirements in preserving \textit{privacy} and maintaining high model \textit{utility}. The nature of the widely-adopted protection mechanisms including \textit{Randomization Mechanism} and \textit{Compression Mechanism} is to protect privacy via distorting model parameter. We measure the utility via the gap between the original model parameter and the distorted model parameter. We want to identify under what general conditions privacy-preserving federated learning can achieve near-optimal utility via data generation and parameter distortion. To provide an avenue for achieving near-optimal utility, we present an upper bound for utility loss, which is measured using two main terms called variance-reduction and model parameter discrepancy separately. Our analysis inspires the design of appropriate protection parameters for the protection mechanisms to achieve near-optimal utility and meet the privacy requirements simultaneously. The main techniques for the protection mechanism include parameter distortion and data generation, which are generic and can be applied extensively. Furthermore, we provide an upper bound for the trade-off between privacy and utility, which together with the lower bound illustrated in NFL form the conditions for achieving optimal trade-off.
How Does Generative Retrieval Scale to Millions of Passages?
May 19, 2023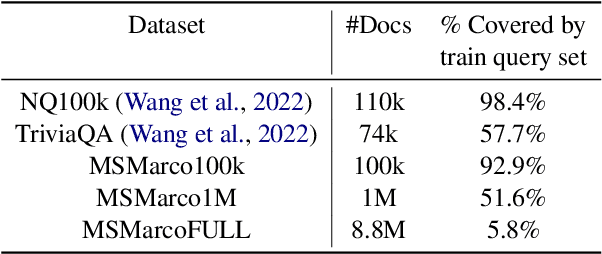
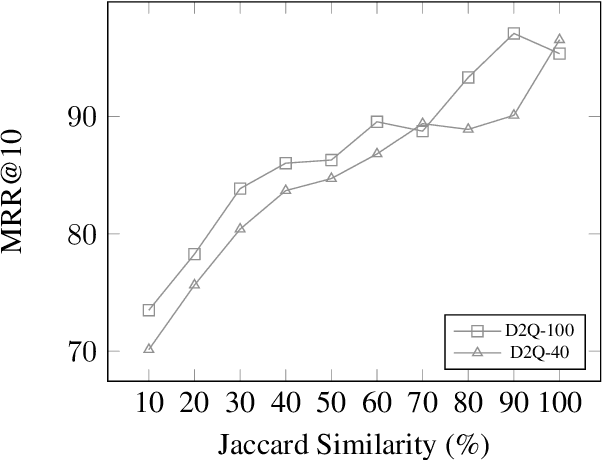
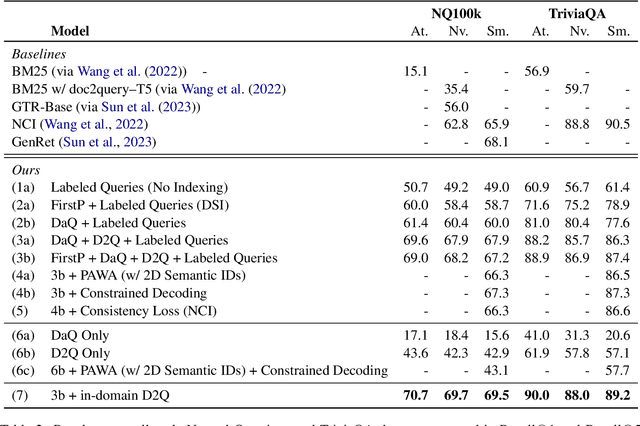
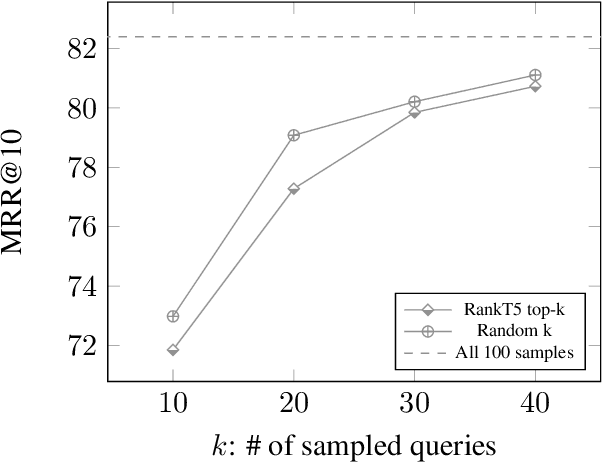
Popularized by the Differentiable Search Index, the emerging paradigm of generative retrieval re-frames the classic information retrieval problem into a sequence-to-sequence modeling task, forgoing external indices and encoding an entire document corpus within a single Transformer. Although many different approaches have been proposed to improve the effectiveness of generative retrieval, they have only been evaluated on document corpora on the order of 100k in size. We conduct the first empirical study of generative retrieval techniques across various corpus scales, ultimately scaling up to the entire MS MARCO passage ranking task with a corpus of 8.8M passages and evaluating model sizes up to 11B parameters. We uncover several findings about scaling generative retrieval to millions of passages; notably, the central importance of using synthetic queries as document representations during indexing, the ineffectiveness of existing proposed architecture modifications when accounting for compute cost, and the limits of naively scaling model parameters with respect to retrieval performance. While we find that generative retrieval is competitive with state-of-the-art dual encoders on small corpora, scaling to millions of passages remains an important and unsolved challenge. We believe these findings will be valuable for the community to clarify the current state of generative retrieval, highlight the unique challenges, and inspire new research directions.
Q-malizing flow and infinitesimal density ratio estimation
May 19, 2023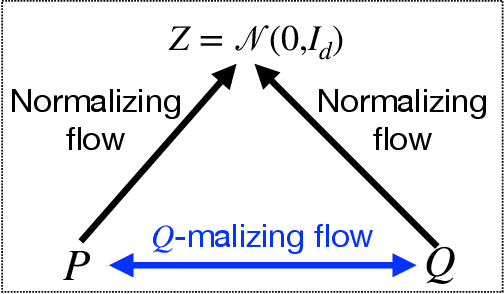

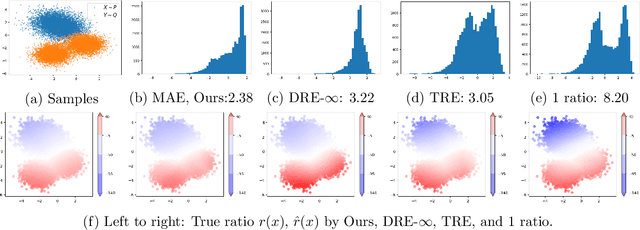
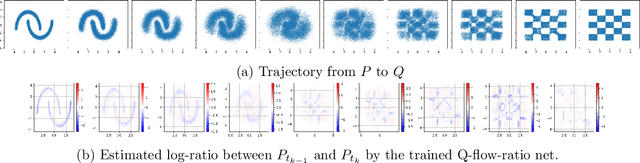
Continuous normalizing flows are widely used in generative tasks, where a flow network transports from a data distribution $P$ to a normal distribution. A flow model that can transport from $P$ to an arbitrary $Q$, where both $P$ and $Q$ are accessible via finite samples, would be of various application interests, particularly in the recently developed telescoping density ratio estimation (DRE) which calls for the construction of intermediate densities to bridge between $P$ and $Q$. In this work, we propose such a ``Q-malizing flow'' by a neural-ODE model which is trained to transport invertibly from $P$ to $Q$ (and vice versa) from empirical samples and is regularized by minimizing the transport cost. The trained flow model allows us to perform infinitesimal DRE along the time-parametrized $\log$-density by training an additional continuous-time flow network using classification loss, which estimates the time-partial derivative of the $\log$-density. Integrating the time-score network along time provides a telescopic DRE between $P$ and $Q$ that is more stable than a one-step DRE. The effectiveness of the proposed model is empirically demonstrated on mutual information estimation from high-dimensional data and energy-based generative models of image data.
Direction Specific Ambisonics Source Separation with End-To-End Deep Learning
May 19, 2023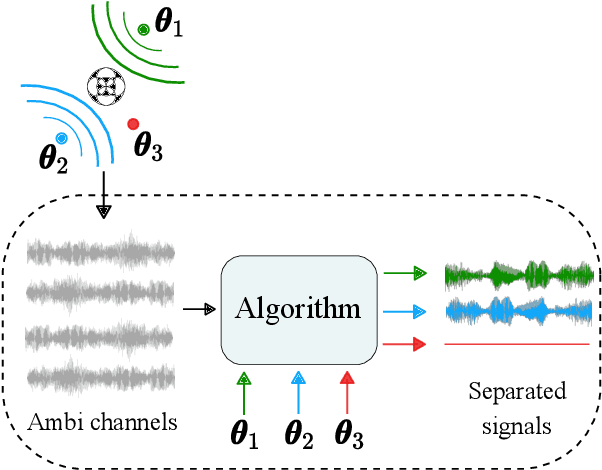
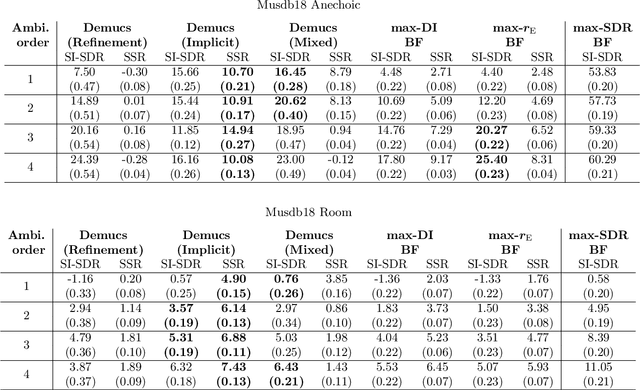
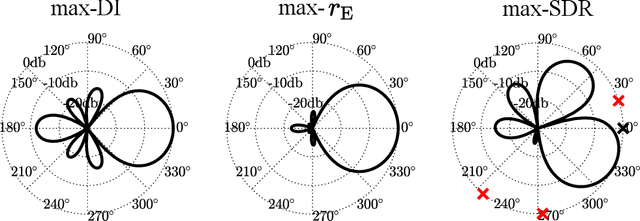
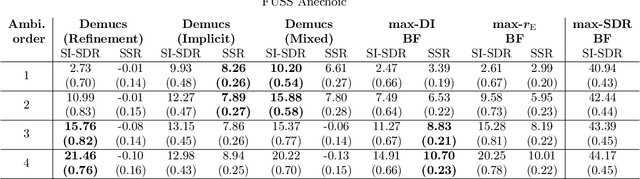
Ambisonics is a scene-based spatial audio format that has several useful features compared to object-based formats, such as efficient whole scene rotation and versatility. However, it does not provide direct access to the individual source signals, so that these have to be separated from the mixture when required. Typically, this is done with linear spherical harmonics (SH) beamforming. In this paper, we explore deep-learning-based source separation on static Ambisonics mixtures. In contrast to most source separation approaches, which separate a fixed number of sources of specific sound types, we focus on separating arbitrary sound from specific directions. Specifically, we propose three operating modes that combine a source separation neural network with SH beamforming: refinement, implicit, and mixed mode. We show that a neural network can implicitly associate conditioning directions with the spatial information contained in the Ambisonics scene to extract specific sources. We evaluate the performance of the three proposed approaches and compare them to SH beamforming on musical mixtures generated with the musdb18 dataset, as well as with mixtures generated with the FUSS dataset for universal source separation, under both anechoic and room conditions. Results show that the proposed approaches offer improved separation performance and spatial selectivity compared to conventional SH beamforming.