 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Connected Hidden Neurons (CHNNet): An Artificial Neural Network for Rapid Convergence
May 17, 2023
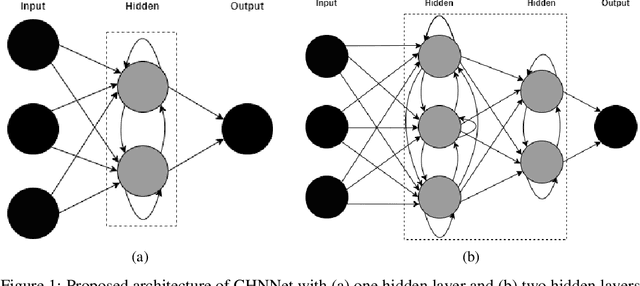
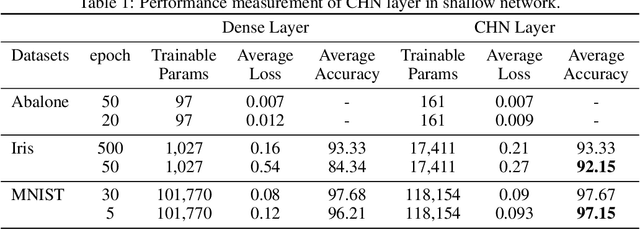
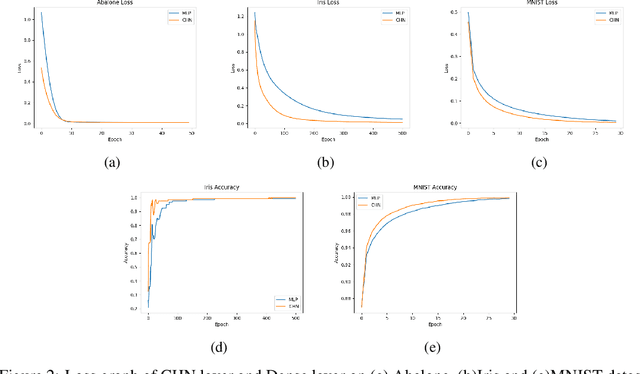
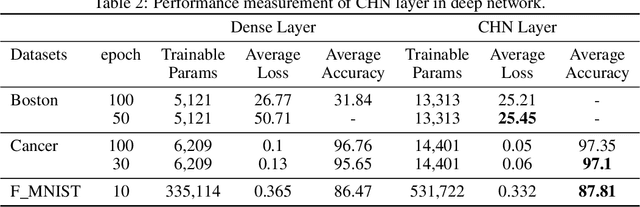
The core purpose of developing artificial neural networks was to mimic the functionalities of biological neural networks. However, unlike biological neural networks, traditional artificial neural networks are often structured hierarchically, which can impede the flow of information between neurons as the neurons in the same layer have no connections between them. Hence, we propose a more robust model of artificial neural networks where the hidden neurons, residing in the same hidden layer, are interconnected, enabling the neurons to learn complex patterns and speeding up the convergence rate. With the experimental study of our proposed model as fully connected layers in shallow and deep networks, we demonstrate that the model results in a significant increase in convergence rate.
Mining Themes in Clinical Notes to Identify Phenotypes and to Predict Length of Stay in Patients admitted with Heart Failure
May 30, 2023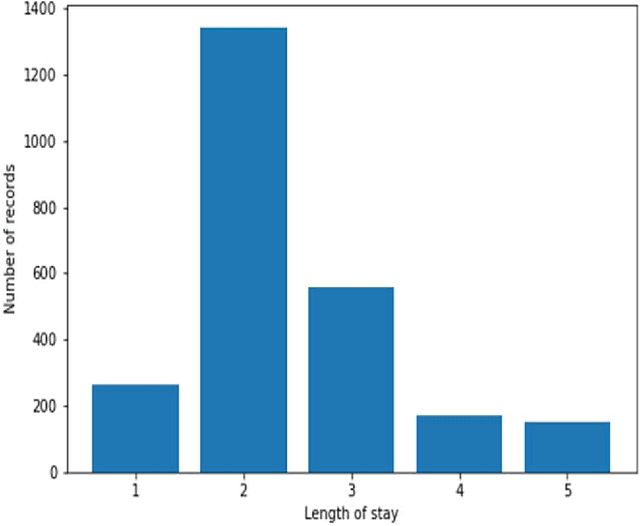
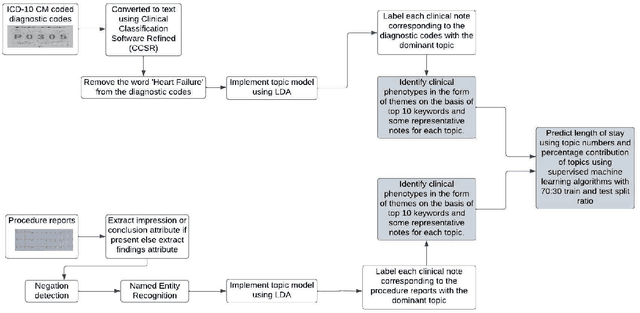

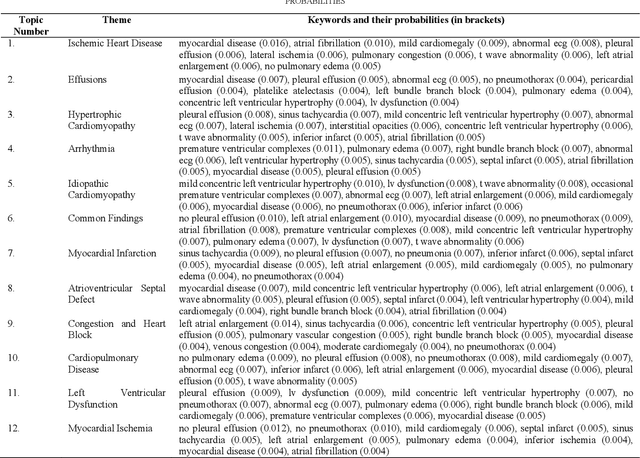
Heart failure is a syndrome which occurs when the heart is not able to pump blood and oxygen to support other organs in the body. Identifying the underlying themes in the diagnostic codes and procedure reports of patients admitted for heart failure could reveal the clinical phenotypes associated with heart failure and to group patients based on their similar characteristics which could also help in predicting patient outcomes like length of stay. These clinical phenotypes usually have a probabilistic latent structure and hence, as there has been no previous work on identifying phenotypes in clinical notes of heart failure patients using a probabilistic framework and to predict length of stay of these patients using data-driven artificial intelligence-based methods, we apply natural language processing technique, topic modeling, to identify the themes present in diagnostic codes and in procedure reports of 1,200 patients admitted for heart failure at the University of Illinois Hospital and Health Sciences System (UI Health). Topic modeling identified twelve themes each in diagnostic codes and procedure reports which revealed information about different phenotypes related to various perspectives about heart failure, to study patients' profiles and to discover new relationships among medical concepts. Each theme had a set of keywords and each clinical note was labeled with two themes - one corresponding to its diagnostic code and the other corresponding to its procedure reports along with their percentage contribution. We used these themes and their percentage contribution to predict length of stay. We found that the themes discovered in diagnostic codes and procedure reports using topic modeling together were able to predict length of stay of the patients with an accuracy of 61.1% and an Area under the Receiver Operating Characteristic Curve (ROC AUC) value of 0.828.
PanoGen: Text-Conditioned Panoramic Environment Generation for Vision-and-Language Navigation
May 30, 2023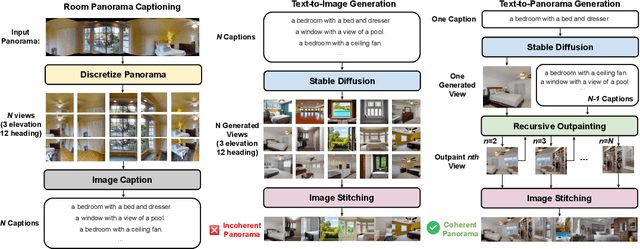
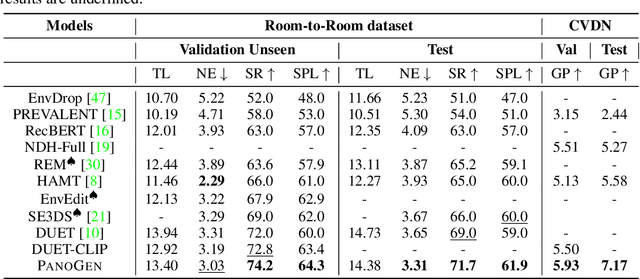
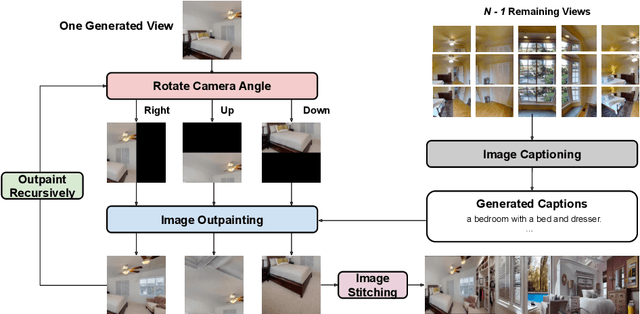
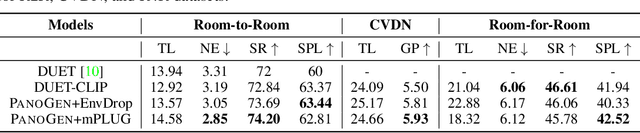
Vision-and-Language Navigation (VLN) requires the agent to follow language instructions to navigate through 3D environments. One main challenge in VLN is the limited availability of photorealistic training environments, which makes it hard to generalize to new and unseen environments. To address this problem, we propose PanoGen, a generation method that can potentially create an infinite number of diverse panoramic environments conditioned on text. Specifically, we collect room descriptions by captioning the room images in existing Matterport3D environments, and leverage a state-of-the-art text-to-image diffusion model to generate the new panoramic environments. We use recursive outpainting over the generated images to create consistent 360-degree panorama views. Our new panoramic environments share similar semantic information with the original environments by conditioning on text descriptions, which ensures the co-occurrence of objects in the panorama follows human intuition, and creates enough diversity in room appearance and layout with image outpainting. Lastly, we explore two ways of utilizing PanoGen in VLN pre-training and fine-tuning. We generate instructions for paths in our PanoGen environments with a speaker built on a pre-trained vision-and-language model for VLN pre-training, and augment the visual observation with our panoramic environments during agents' fine-tuning to avoid overfitting to seen environments. Empirically, learning with our PanoGen environments achieves the new state-of-the-art on the Room-to-Room, Room-for-Room, and CVDN datasets. Pre-training with our PanoGen speaker data is especially effective for CVDN, which has under-specified instructions and needs commonsense knowledge. Lastly, we show that the agent can benefit from training with more generated panoramic environments, suggesting promising results for scaling up the PanoGen environments.
Self-aware and Cross-sample Prototypical Learning for Semi-supervised Medical Image Segmentation
May 25, 2023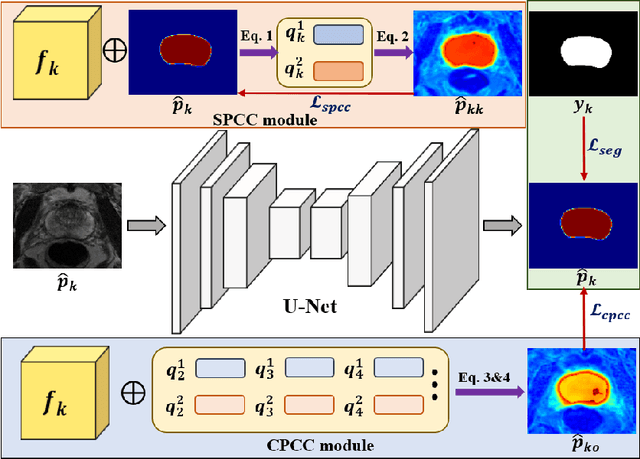
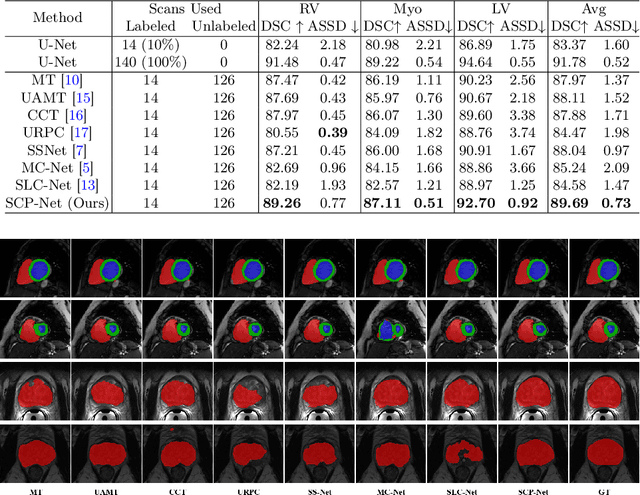
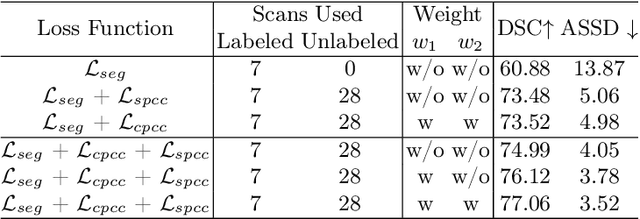
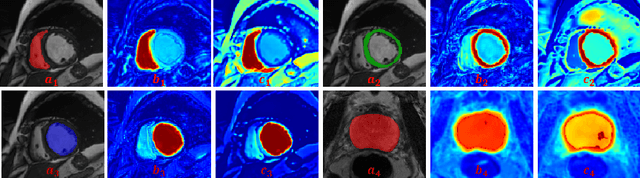
Consistency learning plays a crucial role in semi-supervised medical image segmentation as it enables the effective utilization of limited annotated data while leveraging the abundance of unannotated data. The effectiveness and efficiency of consistency learning are challenged by prediction diversity and training stability, which are often overlooked by existing studies. Meanwhile, the limited quantity of labeled data for training often proves inadequate for formulating intra-class compactness and inter-class discrepancy of pseudo labels. To address these issues, we propose a self-aware and cross-sample prototypical learning method (SCP-Net) to enhance the diversity of prediction in consistency learning by utilizing a broader range of semantic information derived from multiple inputs. Furthermore, we introduce a self-aware consistency learning method that exploits unlabeled data to improve the compactness of pseudo labels within each class. Moreover, a dual loss re-weighting method is integrated into the cross-sample prototypical consistency learning method to improve the reliability and stability of our model. Extensive experiments on ACDC dataset and PROMISE12 dataset validate that SCP-Net outperforms other state-of-the-art semi-supervised segmentation methods and achieves significant performance gains compared to the limited supervised training. Our code will come soon.
Do Models Really Learn to Follow Instructions? An Empirical Study of Instruction Tuning
May 25, 2023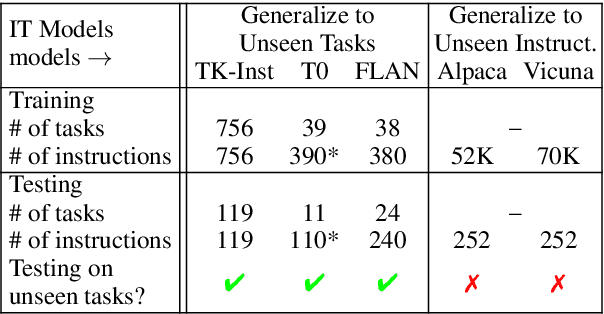
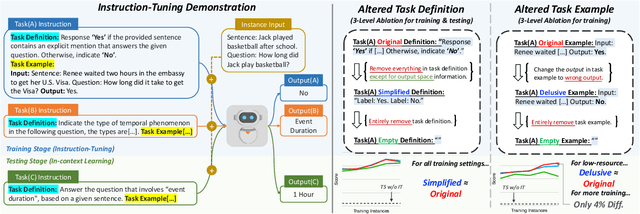
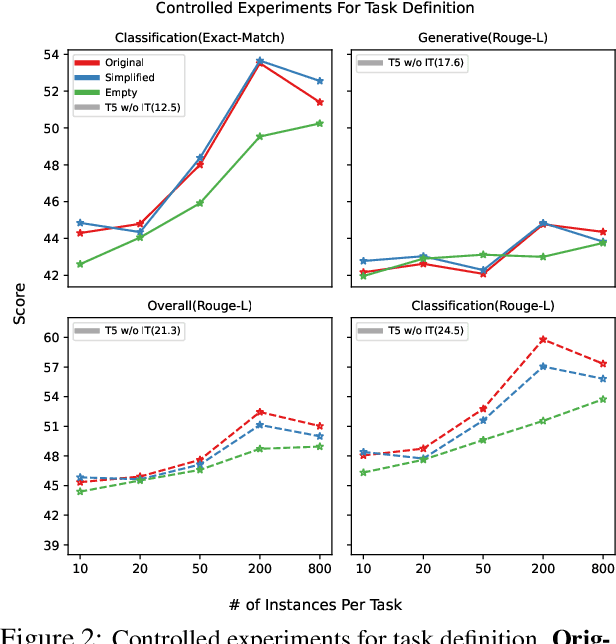
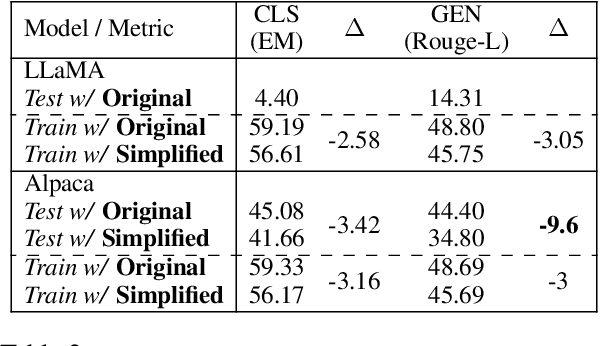
Recent works on instruction tuning (IT) have achieved great performance with zero-shot generalizability to unseen tasks. With additional context (e.g., task definition, examples) provided to models for fine-tuning, they achieved much higher performance than untuned models. Despite impressive performance gains, what models learn from IT remains understudied. In this work, we analyze how models utilize instructions during IT by comparing model training with altered vs. original instructions. Specifically, we create simplified task definitions by removing all semantic components and only leaving the output space information, and delusive examples that contain incorrect input-output mapping. Our experiments show that models trained on simplified task definition or delusive examples can achieve comparable performance to the ones trained on the original instructions and examples. Furthermore, we introduce a random baseline to perform zeroshot classification tasks, and find it achieves similar performance (42.6% exact-match) as IT does (43% exact-match) in low resource setting, while both methods outperform naive T5 significantly (30% per exact-match). Our analysis provides evidence that the impressive performance gain of current IT models can come from picking up superficial patterns, such as learning the output format and guessing. Our study highlights the urgent need for more reliable IT methods and evaluation.
Using LLM-assisted Annotation for Corpus Linguistics: A Case Study of Local Grammar Analysis
May 25, 2023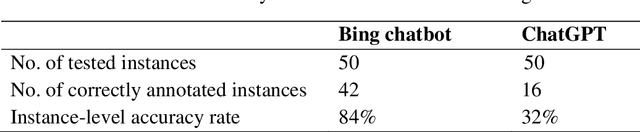

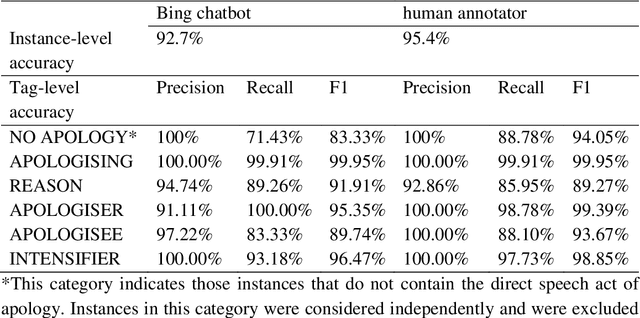
Chatbots based on Large Language Models (LLMs) have shown strong capabilities in language understanding. In this study, we explore the potential of LLMs in assisting corpus-based linguistic studies through automatic annotation of texts with specific categories of linguistic information. Specifically, we examined to what extent LLMs understand the functional elements constituting the speech act of apology from a local grammar perspective, by comparing the performance of ChatGPT (powered by GPT-3.5), the Bing chatbot (powered by GPT-4), and a human coder in the annotation task. The results demonstrate that the Bing chatbot significantly outperformed ChatGPT in the task. Compared to human annotator, the overall performance of the Bing chatbot was slightly less satisfactory. However, it already achieved high F1 scores: 99.95% for the tag of APOLOGISING, 91.91% for REASON, 95.35% for APOLOGISER, 89.74% for APOLOGISEE, and 96.47% for INTENSIFIER. This suggests that it is feasible to use LLM-assisted annotation for local grammar analysis, together with human intervention on tags that are less accurately recognized by machine. We strongly advocate conducting future studies to evaluate the performance of LLMs in annotating other linguistic phenomena. These studies have the potential to offer valuable insights into the advancement of theories developed in corpus linguistics, as well into the linguistic capabilities of LLMs..
PEARL: Preprocessing Enhanced Adversarial Robust Learning of Image Deraining for Semantic Segmentation
May 25, 2023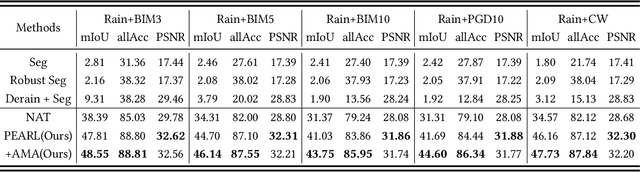
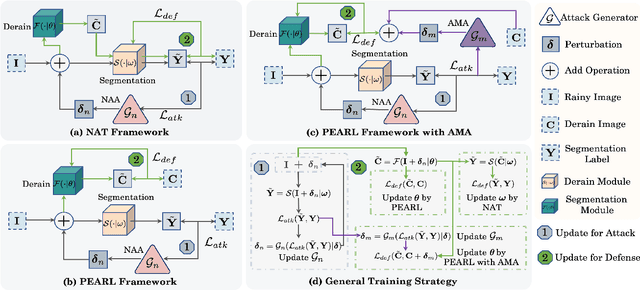
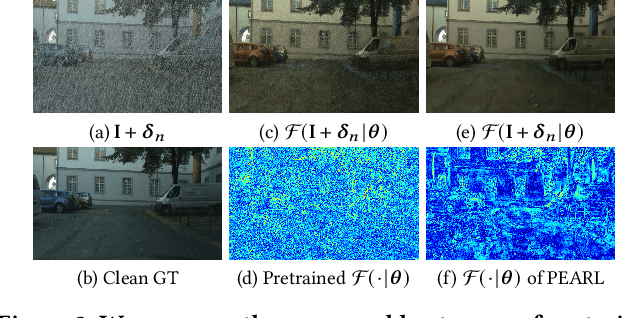
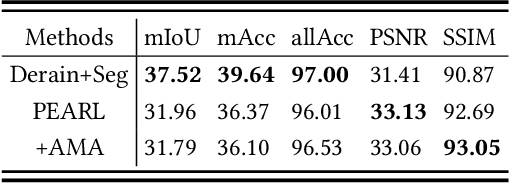
In light of the significant progress made in the development and application of semantic segmentation tasks, there has been increasing attention towards improving the robustness of segmentation models against natural degradation factors (e.g., rain streaks) or artificially attack factors (e.g., adversarial attack). Whereas, most existing methods are designed to address a single degradation factor and are tailored to specific application scenarios. In this work, we present the first attempt to improve the robustness of semantic segmentation tasks by simultaneously handling different types of degradation factors. Specifically, we introduce the Preprocessing Enhanced Adversarial Robust Learning (PEARL) framework based on the analysis of our proposed Naive Adversarial Training (NAT) framework. Our approach effectively handles both rain streaks and adversarial perturbation by transferring the robustness of the segmentation model to the image derain model. Furthermore, as opposed to the commonly used Negative Adversarial Attack (NAA), we design the Auxiliary Mirror Attack (AMA) to introduce positive information prior to the training of the PEARL framework, which improves defense capability and segmentation performance. Our extensive experiments and ablation studies based on different derain methods and segmentation models have demonstrated the significant performance improvement of PEARL with AMA in defense against various adversarial attacks and rain streaks while maintaining high generalization performance across different datasets.
ProSpect: Expanded Conditioning for the Personalization of Attribute-aware Image Generation
May 25, 2023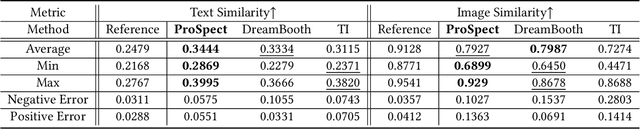
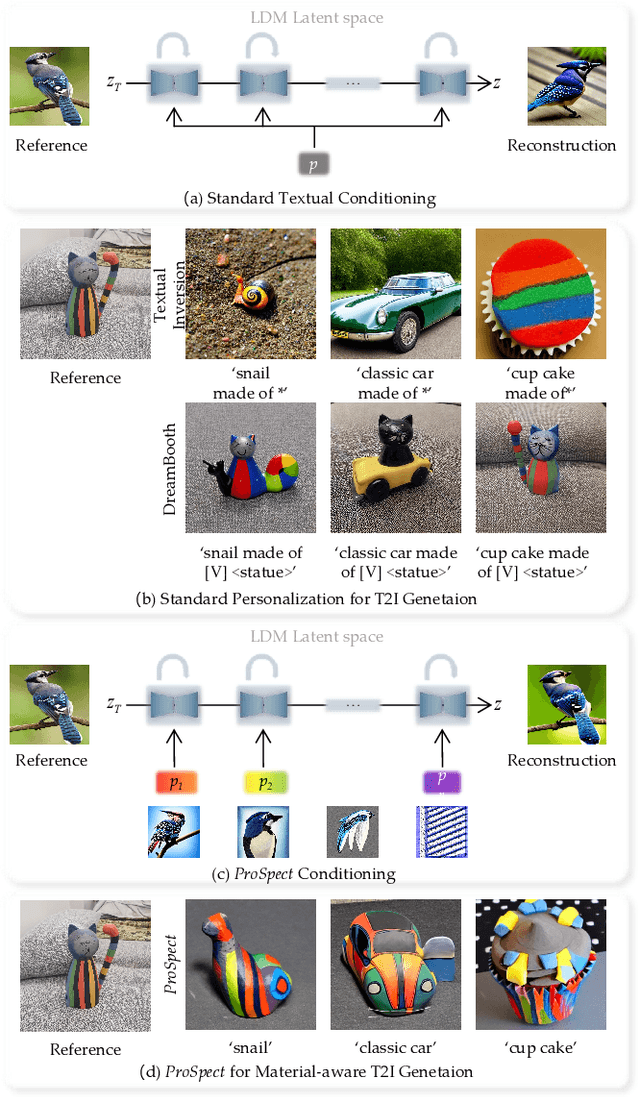

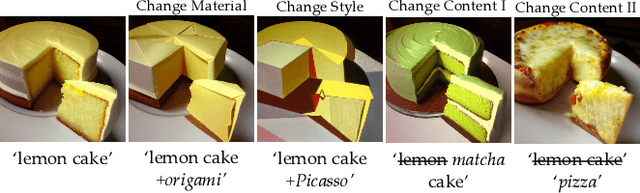
Personalizing generative models offers a way to guide image generation with user-provided references. Current personalization methods can invert an object or concept into the textual conditioning space and compose new natural sentences for text-to-image diffusion models. However, representing and editing specific visual attributes like material, style, layout, etc. remains a challenge, leading to a lack of disentanglement and editability. To address this, we propose a novel approach that leverages the step-by-step generation process of diffusion models, which generate images from low- to high-frequency information, providing a new perspective on representing, generating, and editing images. We develop Prompt Spectrum Space P*, an expanded textual conditioning space, and a new image representation method called ProSpect. ProSpect represents an image as a collection of inverted textual token embeddings encoded from per-stage prompts, where each prompt corresponds to a specific generation stage (i.e., a group of consecutive steps) of the diffusion model. Experimental results demonstrate that P* and ProSpect offer stronger disentanglement and controllability compared to existing methods. We apply ProSpect in various personalized attribute-aware image generation applications, such as image/text-guided material/style/layout transfer/editing, achieving previously unattainable results with a single image input without fine-tuning the diffusion models.
Incomplete Multimodal Learning for Complex Brain Disorders Prediction
May 25, 2023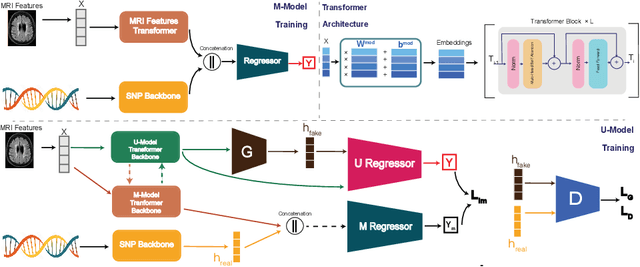

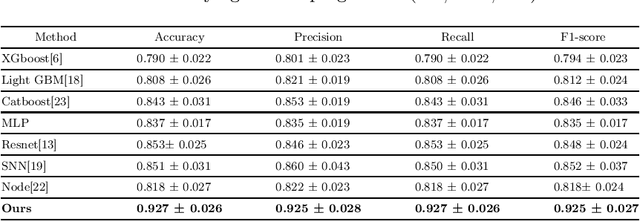

Recent advancements in the acquisition of various brain data sources have created new opportunities for integrating multimodal brain data to assist in early detection of complex brain disorders. However, current data integration approaches typically need a complete set of biomedical data modalities, which may not always be feasible, as some modalities are only available in large-scale research cohorts and are prohibitive to collect in routine clinical practice. Especially in studies of brain diseases, research cohorts may include both neuroimaging data and genetic data, but for practical clinical diagnosis, we often need to make disease predictions only based on neuroimages. As a result, it is desired to design machine learning models which can use all available data (different data could provide complementary information) during training but conduct inference using only the most common data modality. We propose a new incomplete multimodal data integration approach that employs transformers and generative adversarial networks to effectively exploit auxiliary modalities available during training in order to improve the performance of a unimodal model at inference. We apply our new method to predict cognitive degeneration and disease outcomes using the multimodal imaging genetic data from Alzheimer's Disease Neuroimaging Initiative (ADNI) cohort. Experimental results demonstrate that our approach outperforms the related machine learning and deep learning methods by a significant margin.
A Task-guided, Implicitly-searched and Meta-initialized Deep Model for Image Fusion
May 25, 2023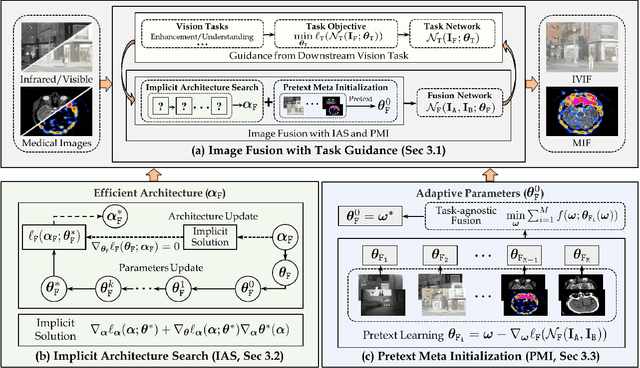



Image fusion plays a key role in a variety of multi-sensor-based vision systems, especially for enhancing visual quality and/or extracting aggregated features for perception. However, most existing methods just consider image fusion as an individual task, thus ignoring its underlying relationship with these downstream vision problems. Furthermore, designing proper fusion architectures often requires huge engineering labor. It also lacks mechanisms to improve the flexibility and generalization ability of current fusion approaches. To mitigate these issues, we establish a Task-guided, Implicit-searched and Meta-initialized (TIM) deep model to address the image fusion problem in a challenging real-world scenario. Specifically, we first propose a constrained strategy to incorporate information from downstream tasks to guide the unsupervised learning process of image fusion. Within this framework, we then design an implicit search scheme to automatically discover compact architectures for our fusion model with high efficiency. In addition, a pretext meta initialization technique is introduced to leverage divergence fusion data to support fast adaptation for different kinds of image fusion tasks. Qualitative and quantitative experimental results on different categories of image fusion problems and related downstream tasks (e.g., visual enhancement and semantic understanding) substantiate the flexibility and effectiveness of our TIM. The source code will be available at https://github.com/LiuZhu-CV/TIMFusion.